はじめに
どうも、お久しぶりです。
検索エンジンが気になったので、調べたけど、挫折した人です。
この記事では、そんな検索エンジンを調べたときに知った
「word2vecを使った類義語検索」
について紹介します。
この記事では、wikipediaの文章を使ってコーパスを作っていきます。
開発環境
Windows11
python: 3.10
gensim: 4.1.2
Gensimのバージョンを確認してね
見ていた資料とバージョンが違って、挫折しかけたから、気をつけて
wikiページの取得
まず、wikipediaのページ全てのデータを取得していきます。
これには、面倒なスクレイピングを使うのではなく、便利な圧縮ファイルがあるので、それをダウンロードします。
ふつうにwebサイトからダウンロードしてもいいのですが、~~なんかカッコイイので、~~curlでダウンロードします。
curl https://dumps.wikimedia.org/jawiki/latest/jawiki-latest-pages-articles.xml.bz2 -o jawiki-latest-pages-articles.xml.bz2
記事執筆時には3.8GBくらいあって、自分のPC/ネット環境だと、2時間くらいかかりました。
wiki圧縮ファイルの解凍
ダウンロードしたファイルは、圧縮ファイルです。
これは、普通にCLIコマンドで解凍してもいいのですが、それじゃつまらないので、「WikiExtractor」という、そこそこ有名な解凍ライブラリを使用します。
pip install wikiextractor
これでインストール完了
圧縮ファイルをダウンロードしたディレクトリで以下のコマンドを叩くと、解凍が始まります。
python -m wikiextractor.WikiExtractor jawiki-latest-pages-articles.xml.bz2
> python -m wikiextractor.WikiExtractor jawiki-latest-pages-articles.xml.bz2
INFO: Preprocessing 'jawiki-latest-pages-articles.xml.bz2' to collect template definitions: this may take some time.
INFO: Preprocessed 100000 pages
INFO: Preprocessed 200000 pages
INFO: Preprocessed 300000 pages
INFO: Preprocessed 400000 pages
INFO: Preprocessed 500000 pages
INFO: Preprocessed 600000 pages
INFO: Preprocessed 700000 pages
INFO: Preprocessed 800000 pages
INFO: Preprocessed 900000 pages
INFO: Preprocessed 1000000 pages
INFO: Preprocessed 1100000 pages
INFO: Preprocessed 1200000 pages
INFO: Preprocessed 1300000 pages
INFO: Preprocessed 1400000 pages
INFO: Preprocessed 1500000 pages
INFO: Preprocessed 1600000 pages
INFO: Preprocessed 1700000 pages
INFO: Preprocessed 1800000 pages
INFO: Preprocessed 1900000 pages
INFO: Preprocessed 2000000 pages
INFO: Preprocessed 2100000 pages
INFO: Preprocessed 2200000 pages
INFO: Preprocessed 2300000 pages
INFO: Preprocessed 2400000 pages
INFO: Preprocessed 2500000 pages
INFO: Preprocessed 2600000 pages
INFO: Loaded 94413 templates in 765.2s
INFO: Starting page extraction from jawiki-latest-pages-articles.xml.bz2.
こんなログが出たとなと思った次の瞬間、、、
Traceback (most recent call last):
File "C:\Python310\lib\runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "C:\Python310\lib\runpy.py", line 86, in _run_code
exec(code, run_globals)
File "C:\Python310\lib\site-packages\wikiextractor\WikiExtractor.py", line 645, in <module>
main()
File "C:\Python310\lib\site-packages\wikiextractor\WikiExtractor.py", line 640, in main
process_dump(input_file, args.templates, output_path, file_size,
File "C:\Python310\lib\site-packages\wikiextractor\WikiExtractor.py", line 359, in process_dump
Process = get_context("fork").Process
File "C:\Python310\lib\multiprocessing\context.py", line 239, in get_context
return super().get_context(method)
File "C:\Python310\lib\multiprocessing\context.py", line 193, in get_context
raise ValueError('cannot find context for %r' % method) from None
ValueError: cannot find context for 'fork'
はい、エラーが来ました。
出てきたものを見る感じ、ライブラリエラーなので、wikiextractorを最新版にします。
pip install git+https://github.com/prokotg/wikiextractor
Githubから直接インストールすると、最新版がインストールできます。
これで、インストールができたので、もう一度解凍コマンドを実行します。
python -m wikiextractor.WikiExtractor jawiki-latest-pages-articles.xml.bz2
今回はうまくいきました。
多分、このコマンドを実行したディレクトリにtextフォルダーができて、中に大量のwikiデータが入ってると思います。
中身を見てみたい場合は、ファイルをメモ帳やエディターで開くと、中身が見れます。
wikiをまとめる
これには、コマンドが複数ありますが、今回は一番単純は"cat"を使ったコマンドを使用します。
cat text/*/* > wiki.txt
これで、ファイルを一つにまとめることができました。
ネタバレ:こいつが原因だった。
wiki文章の整形
wikiファイルたちの中身を見た人は気づいたかもしれませんが、wikiファイルは、
<doc></doc>
で囲まれています。
これは、wikiコーパスの精度を落とす可能性があるので、消します。
あと、wiki特有の、読み仮名をカッコで囲むやつも、精度を落とす可能性があるので、消します。
sed -e 's/<[^>]*>//g' ./wiki.txt > ./wiki_notag.txt
sed -i -e 's/(/(/g' ./wiki_notag.txt && sed -i -e 's/)/)/g' ./wiki_notag.txt
sed -i -e 's/([^)]*)//g' ./wiki_notag.txt
sed -i -e 's/ //g' ./wiki_notag.txt && sed -i -e '/^$/d' ./wiki_notag.txt
これら、四つのコマンドを使うことで、いらないものが削除されました。
ネタバレ:こいつも原因だった。
MeCabでWakati
word2vecのコーパスを作る上で、分かち書きは必ず(?)行わなければなりません。
日本語の分かち書きに使えるライブラリで一番有名で人気があるのがMeCabです。
MeCabインストール
MeCabは、以下のurlからインストールできます。
インストーラーを起動して、ポチポチすると、このような画面になったと思います。
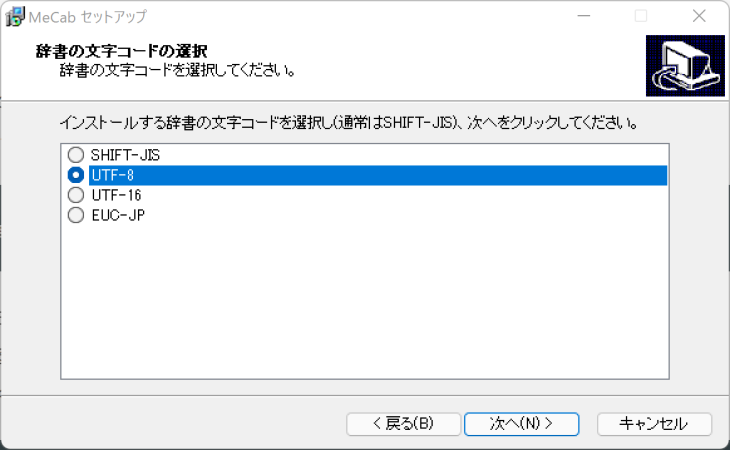
ここでは、SHIFT-JISを選択します。
理由は簡単で、SHIFT-JISだと、コンソール上で文字化けしないからです。
詳しい理由はggってくれ
すもももももももものうち
すもももももももものうち 險伜捷,荳闊ャ,*,*,*,*,*
EOS
今日は晴天なり
今日は晴 險伜捷,荳闊ャ,*,*,*,*,*
V 蜷崎ゥ・蝗コ譛牙錐隧・邨・ケ・*,*,*,*
險伜捷,荳闊ャ,*,*,*,*,*
ネ 蜷崎ゥ・蝗コ譛牙錐隧・邨・ケ・*,*,*,*
險伜捷,荳闊ャ,*,*,*,*,*
EOS
すもももももももものうち
すもも 名詞,一般,*,*,*,*,すもも,スモモ,スモモ
も 助詞,係助詞,*,*,*,*,も,モ,モ
もも 名詞,一般,*,*,*,*,もも,モモ,モモ
も 助詞,係助詞,*,*,*,*,も,モ,モ
もも 名詞,一般,*,*,*,*,もも,モモ,モモ
の 助詞,連体化,*,*,*,*,の,ノ,ノ
うち 名詞,非自立,副詞可能,*,*,*,うち,ウチ,ウチ
EOS
今日は晴天なり
今日 名詞,副詞可能,*,*,*,*,今日,キョウ,キョー
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
晴天 名詞,一般,*,*,*,*,晴天,セイテン,セイテン
なり 助動詞,*,*,*,文語・ナリ,基本形,なり,ナリ,ナリ
EOS
MeCabで分かち書きをする
mecab -Owakati wiki_notag.txt -o wiki_wakati.txt
このコマンドを叩くだけで、分かち書きができます。
途中、こんな文字が出てきた人がいるかもしれません。
開発に影響を与えるタイプでは無いので、大丈夫です。(多分...)
input-buffer overflow. The line is split. use -b #SIZE option.
Gensim君
Gensimというのは、超簡単に言うと、AIを作る用のライブラリ郡です。
正直、よく理解してない
インストールしていきます。
Gensimのインストール
超簡単、pip installすればいいだけ!
pip install -U gensim
まぁ、ここでエラーが出てくるんすけどね(笑)
"C:\Program Files\Microsoft Visual Studio\2022\Community\VC\Tools\MSVC\14.30.30705\bin\HostX86\x64\cl.exe" /c /nologo /O2 /W3 /GL /DNDEBUG /MD -IC:\Python310\include -IC:\Python310\Include -IC:\Python310\lib\site-packages\numpy\core\include "-IC:\Program Files\Microsoft Visual Studio\2022\Community\VC\Tools\MSVC\14.30.30705\include" "-IC:\Program Files (x86)\Windows Kits\NETFXSDK\4.8\include\um" /Tcgensim/models/word2vec_inner.c /Fobuild\temp.win-amd64-3.10\Release\gensim/models/word2vec_inner.obj
word2vec_inner.c
C:\Python310\include\pyconfig.h(59): fatal error C1083: include ファイルを開けません。'io.h':No such file or directory
error: command 'C:\\Program Files\\Microsoft Visual Studio\\2022\\Community\\VC\\Tools\\MSVC\\14.30.30705\\bin\\HostX86\\x64\\cl.exe' failed with exit code 2
----------------------------------------
ERROR: Command errored out with exit status 1: 'C:\Python310\python.exe' -u -c 'import io, os, sys, setuptools, tokenize; sys.argv[0] = '"'"'C:\\Users\\Zect\\AppData\\Local\\Temp\\pip-install-hkqqlyre\\gensim_915fa383964a4ff896ebe797b6f105c2\\setup.py'"'"'; __file__='"'"'C:\\Users\\Zect\\AppData\\Local\\Temp\\pip-install-hkqqlyre\\gensim_915fa383964a4ff896ebe797b6f105c2\\setup.py'"'"';f = getattr(tokenize, '"'"'open'"'"', open)(__file__) if os.path.exists(__file__) else io.StringIO('"'"'from setuptools import setup; setup()'"'"');code = f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' install --record 'C:\Users\Zect\AppData\Local\Temp\pip-record-6v3t2lvi\install-record.txt' --single-version-externally-managed --user --prefix= --compile --install-headers 'C:\Users\Zect\AppData\Roaming\Python\Python310\Include\gensim' Check the logs for full command output.
ログが超長いので、最後の数行だけ載せました。
これを見るに、Visual StudioのBuild Toolsである、MSVC Ver.14.30.30705を開こうとしているみたいです。
なので、Visual StudioのBuild ToolsからMSVC Ver.14をインストールします。
画像を持ってくる
ベクトルの作成
from gensim.models import word2vec
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
sentences = word2vec.Text8Corpus('./wiki_wakati.txt')
model = word2vec.Word2Vec(sentences, vector_size=200, min_count=20, window=15)
model.wv.save_word2vec_format("./wiki.model", binary=True)
こんな感じ
このコードを実行してあげることで、wikiコーパス(モデル)の作成が行われます。
- vector_size: ベクトルの次元数
- min_count: 出てきた回数がn回以下の場合は使用しない
- window: 単語間の最大距離
引数に関しては、ここを参照
モデルを使った単語の類似検索
よし、じゃぁ、モデルを試しに使ってみよう!
from gensim.models import KeyedVectors
wv = KeyedVectors.load_word2vec_format('wiki.model', binary=True)
results = wv.most_similar(positive='日本')
for result in results:
print(result)
検索する文字は、もちろん日本!!!
Traceback (most recent call last):
File "C:\wikivectest.py", line 4, in <module>
results = wv.most_similar(positive='日本')
File "C:\gensim\keyedvectors.py", line 773, in most_similar
mean.append(weight * self.get_vector(key, norm=True))
File "C:\gensim\keyedvectors.py", line 438, in get_vector
index = self.get_index(key)
File "C:\gensim\keyedvectors.py", line 412, in get_index
raise KeyError(f"Key '{key}' not present")
KeyError: "Key '日本' not present"
あれ???
'日本'という言葉がモデル内に存在しないと言われてしまいました、、
なぜだ?
いろいろ試してみたところ、アルファベットでの検索には対応しているみたいです。
てことで、'Japan'で検索しました
from gensim.models import KeyedVectors
wv = KeyedVectors.load_word2vec_format('wiki.model', binary=True)
- results = wv.most_similar(positive='日本')
+ results = wv.most_similar(positive='Japan')
for result in results:
print(result)
('etc', 0.5311076641082764)
('や', 0.4949520230293274)
('縲舌', 0.4680085778236389)
('縺娯', 0.46634429693222046)
('YuyaKiuchi', 0.4642036259174347)
('笳', 0.4613495171070099)
('笳上', 0.460459440946579)
('縲職', 0.4527381658554077)
('..', 0.45070236921310425)
('nGene', 0.45022666454315186)
おやおや
やはり、バイナリ文字が混じってたみたいですね。
この文字は、CLIで作業するとき、win上でよく出てくる文字です。
文字コードの処理をしなかったり、CLIコマンドでファイルを処理したりすると、よく出てきます。
(個人差があります。)
こいつ、どうやって解消しよう、、、
CLIコマンドの作業をPythonで書く
それらしき文献が一切なかったので、最初から実行し、出力されるファイルを途中で無理やり開いて中身を見た結果、
wikiデータを一つにまとめるコマンド
cat text/*/* > wiki.txt
が悪さをしていたみたいです。
なので、ファイルをまとめるコードをPythonで記述します。
import glob
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
logger = logging.getLogger(__name__)
AllData = ''
Folders = glob.glob('text\*')
for FolderName in Folders:
files = glob.glob(f"{FolderName}\*")
for file in files:
f = open(file, 'r', encoding='UTF-8')
data = f.read()
AllData += data + '\n'
logger.info(file)
wf = open(f'data/wiki_data_{FolderName[5:7]}.txt', 'w', encoding='UTF-8')
wf.write(AllData)
wf.close
wf = open('wiki_data.txt', 'w', encoding='UTF-8')
wf.write(AllData)
wf.close()
これで、ファイルを一つにまとめて、「wiki_data.txt」というファイルで書き出すことができるようになりました。
解説をすると、
glob.glob('text\*')
で、textディレクトリ内のフォルダを取得します。
「フォルダを取得」といっても、wikiextractorから出力されたものからなにか編集していた場合は若干不具合が生じるかもしれません。
このデータはlist型で取得できるので、forで回しました。
そして、回ってきたフォルダの中身を検索します。
files = glob.glob(f"{FolderName}\*")
これで、「text/${FolderName}/*」が取得できました。
ファイルの中身を読む方法は、
f = open("<ファイル名>", 'r', encoding='UTF-8')
f.read()
これでできます。
open()のパラメーターの
1つ目は、ファイル名
2つ目は、モード;ここでは、読み込むだけなので、'r'を選択;書き込むとき/ファイル新規作成は'w'にする
3つ目は、文字コードの指定;UTF-8じゃないとバイナリが交じるので、UTF-8にします。
で、ここで読み込んだデータを最初に用意した変数に「+=」しました。
その次に、途中で処理が中断して、やりくりしたデータが全部飛んだときの対策に、1フォルダ読み込み終わったら、それまでのデータを書き出すことをします。
wf = open(f'data/wiki_data_{FolderName[5:7]}.txt', 'w', encoding='UTF-8')
wf.write(AllData)
このコードを実行する前に、dataフォルダが存在することを確認してください。
もし、dataディレクトリが存在しない場合は、エラーを吐きます。
ここではファイルの新規作成を行うので、2つ目のパラメーターは'w'にします。
これで解説は以上
なんかわからないところがあったら、ggるか、コメ欄に書いといて
PythonのMeCabでWakati
さて、wiki文章を一つのファイルにまとめることができたから、ここからは分かち書きをしていくよ!
mecab -Owakati wiki_notag.txt -o wiki_wakati.txt
ここでは、このコマンドは使いません
これもPythonで書いていきます。
import glob
import MeCab
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
logger = logging.getLogger(__name__)
tagger = MeCab.Tagger("-Owakati")
file = 'wiki_data.txt'
f = open(file, 'r', encoding='UTF-8')
data = f.read()
wakatiData = tagger.parse(data)
wf = open('wiki_data_wakati.txt', 'w', encoding='UTF-8')
wf.write(AllData)
wf.close()
これでできました。
解説
tagger = MeCab.Tagger("-Owakati")
こいつで、「私、ワカチ宣言」します。
このtaggerというのは、こういう風にしてあげると、watati書きしてくれます。
tagger.parse('すもももももももものうち')
# すもも も もも も もも の うち
さっきのコードと違うのは、処理がアホほど遅いことです。
ここでは「wiki_data.txt」を読み込んでるので、しょうがないです。
実行したら、待ちます。
......一時間後
[実行終了]
エクスプローラーを見る
「あれ??ファイルがない。。。」
もう一度実行
......一時間後
[実行終了]
「やっぱ、ファイルが無い!」
データが大きすぎると、wakatiできない問題
もう、こいつはどうしようもない。
ここでは、wiki文章をまとめるときに使ったコードの途中にwakati書きすることにして、対応した。
コードはこんな感じ
import glob
import MeCab
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
logger = logging.getLogger(__name__)
tagger = MeCab.Tagger("-Owakati")
AllData = ''
Folders = glob.glob('text\*')
for FolderName in Folders:
files = glob.glob(f"{FolderName}\*")
for file in files:
f = open(file, 'r', encoding='UTF-8')
data = f.read()
- AllData += data + '\n'
+ wakatiData = tagger.parse(data)
+ AllData += wakatiData + '\n'
logger.info(file)
- wf = open(f'data/wiki_data_{FolderName[5:7]}.txt', 'w', encoding='UTF-8')
+ wf = open(f'wakati/wiki_data_{FolderName[5:7]}.txt', 'w', encoding='UTF-8')
wf.write(AllData)
wf.close
wf = open('wiki_data_wakati.txt', 'w', encoding='UTF-8')
wf.write(AllData)
wf.close()
解説は、、、
いらないかな
全部、前に説明したことだし
2つのコードを一つにまとめた、みたいなところあるから、解説いらないよね
この記事の主役は我々だ!
やっとword2vecの出番です。
from gensim.models import word2vec
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
sentences = word2vec.Text8Corpus('./wiki_wakati_w.txt')
model = word2vec.Word2Vec(sentences, vector_size=200, min_count=20, window=15, workers=10)
model.wv.save_word2vec_format("./wiki.model", binary=True)
はい。
出番終了です()
解説
上で使ったコードに加え、一つ引数を足しました。
"workers"
ですね。
これは、処理を早くすることができる引数です。
ご利用は計画的に
ちなみに、ここでこの引数が出てきたのは、ちょうどこの時期にハイエンドが届いて、処理が早くなったから(自慢)
単語検索
これで、モデルの作成が終了したので、遊んでいきましょう!
from gensim.models import KeyedVectors
wv = KeyedVectors.load_word2vec_format('wiki_data.model', binary=True)
results = wv.most_similar(positive=input('単語を入力\n>>> '))
for result in results:
print(result)
解説の必要は無いですかね。
オタクたるもの、まずは推しから検索すべし!
> python wikivectest.py
単語を入力
>>> 初音
('ミク', 0.814029335975647)
('VOCALOID', 0.6854016184806824)
('KAITO', 0.6704154014587402)
('ボーカロイド', 0.6387607455253601)
('MEIKO', 0.6119569540023804)
('クリプトン・フューチャー・メディア', 0.5945071578025818)
('Megpoid', 0.57939213514328)
('TUNES', 0.5519722104072571)
('GUMI', 0.5508669018745422)
('EXIT', 0.5456638932228088)
すげーーーーーーー!!!
まさか、ここでCryptonが出てくるとは思いませんでした。
それも、コサイン類似度0.594!
結構近いですよ
一番上に「ミク」がいるので、「ミク」を検索してみましょう
> python wikivectest.py
単語を入力
>>> ミク
('初音', 0.8140293955802917)
('VOCALOID', 0.7328931093215942)
('KAITO', 0.6994694471359253)
('ボーカロイド', 0.688727617263794)
('MEIKO', 0.6449904441833496)
('Megpoid', 0.6289090514183044)
('クリプトン・フューチャー・メディア', 0.6288353204727173)
('はつね', 0.6032723784446716)
('TUNES', 0.5871540904045105)
('GUMI', 0.5743457674980164)
こんどは、ひらがな「はつね」がいますね
> python wikivectest.py
単語を入力
>>> はつね
('フィーチャリング・', 0.6516125798225403)
('ミク', 0.6032723188400269)
('エグジット・チューンズ・プレゼンツ', 0.5987372398376465)
('初音', 0.5109699964523315)
('にじ', 0.500720202922821)
('はなみ', 0.46432074904441833)
('ぎざか', 0.4537661075592041)
('シーディー', 0.45156562328338623)
('フォーティーシックス', 0.4501747488975525)
('こいする', 0.4432184100151062)
まさかの、「こいする」
知ってる人は知ってると思いますが、知らない人のために解説すると、
「恋するVoc@loid」という楽曲がありまして、その曲のタイトルの一部が出てくるとは思ってもいませんでした。
おや?
「にじ」
がある。。。
やっぱねぇ、
「にじ」
と言ったら、アレしか無いでしょ
そう!
> python wikivectest.py
単語を入力
>>> にじ
('さんじ', 0.7964274287223816)
('きゅうじ', 0.7316185235977173)
('よじ', 0.7172978520393372)
('かんじ', 0.7107529044151306)
('かせん', 0.7078416347503662)
('とうせん', 0.7055351138114929)
('てんし', 0.7030456066131592)
('じじ', 0.7001359462738037)
('げんじ', 0.695505678653717)
('えんか', 0.6890977621078491)
にじ さんじ
文字同士の関連度を調べる
竹島って、どこの国のものなんでしょう()
このモデルを使って調べてみましょう!(炎上案件)
from gensim.models import KeyedVectors
wv = KeyedVectors.load_word2vec_format('wiki_data.model', binary=True)
kr = wv.similarity('竹島', '韓国')
jp = wv.similarity('竹島', '日本')
nk = wv.similarity('竹島', '北朝鮮')
cn = wv.similarity('竹島', '中国')
print(f'''\
韓国 と竹島の類似度 : {kr}
日本 と竹島の類似度 : {jp}
北朝鮮と竹島の類似度 : {nk}
中国 と竹島の類似度 : {cn}\
''')
さぁ、どの国が一番数値が高かったと思いますか?
韓国 と竹島の類似度 : 0.41579458117485046
日本 と竹島の類似度 : 0.18454104661941528
北朝鮮と竹島の類似度 : 0.3764462172985077
中国 と竹島の類似度 : 0.25470954179763794
おや、誰か来たようだ
なんか、途中で問題がおきたら、コメントか、TwitterのDMで教えてくれ
じゃぁ、次の記事で会おう!
ノシ