tl;dr
-
Python(CPython)にはGILという機能があり、マルチスレッドによる並列処理が制限されています。そのため並列処理はマルチプロセスによって実施する必要があります。 - プロセスはプログラムの実行、リソースの要求単位であり、スレッドはプロセス内の処理の単位。基本的にはオペレーティングシステムがCPUスケジュラによって、プログラムをプロセス単位にスケジュールし、仮想CPUを割り当てます。
- 並行処理と並列処理は別物であり、並列処理を行う場合は、排他制御やデッドロックを回避する仕組みなどが必要です。並行処理が各プロセスをスケジュリングされた順に行うのに対し、並列処理は同時に処理を行うためです。
Agenda
- はじめに - Pythonコード実行の流れ
- 背景
- プロセス、スレッドって何?
- CPUスケジュリングとは
- 並行処理 != 並列処理
- Pythonでの並列処理
- 実際のコード
- コードテスト例
- 五目並べのコードにおける並列処理
はじめに - Pythonコード実行の流れ
まずPythonコードがそもそもどのようにCPUで実行されるかの流れをまとめました。本記事ではプロセス、スレッドに焦点を当てているため、以下本文では4~5について記載しています。
- ソースコードの解析: Pythonのソースコードが構文解析されます。
- バイトコードの生成: 構文解析が成功すると、Pythonはバイトコードと呼ばれる中間言語にソースコードをコンパイルします。この場合、バイトコードとは、Pythonの仮想マシン(
CPythonの場合はPython VM)が理解できる言語であり、JavaやCのコンパイルとは別物となります。 - Python VMによる実行: 生成されたバイトコードが仮想マシンにて実行されます。仮想マシンは、実際の物理マシン上で動作するインタープリタであり、バイトコードを取得して機械語に変換し、その命令を実行します。
- プロセスのスケジューリング: オペレーティングシステムは、実行するプログラムをプロセスとしてスケジュールします。各プロセスは独自のメモリ空間とリソースを割り当てられます。
- スレッドの実行: スレッドごとにリソース(CPU, メモリ)が割り当てられ、実行されます。多くのプログラムではマルチスレッドにより1つのプロセス内で複数のスレッドが同時に実行されますが、
Python(CPython)ではGIL(global interpreter lock)により各プロセスで同時に実行されるスレッドは一つとなります。
背景
学習のため、五目並べを作っているのですが、CPUのロジックをMiniMaxで作成するにあたり、実行時間が長くなってしまうという問題にぶつかりました。忙しい現代人は一手に30秒かかるCPUと遊びたいとは思わないため、ゲーム性を担保するために、CPUの思考時間は3〜5秒に抑えたいというのが要件です。そのため、MiniMax法を用いて、考えられる手の先読みを行い、打ち手を評価するという部分を並列化して実行時間短縮ができないかを試しました。
Minimax法とは
ミニマックス法(ミニマックスほう、英: minimax)またはミニマックス探索とは、想定される最大の損害が最小になるように決断を行う戦略のこと。将棋、チェス、リバーシなどといった二人零和有限確定完全情報ゲームをコンピュータに思考させるためのアルゴリズムとしても用いられるが、元々はフォン・ノイマンが中心となって数学的に理論化されたゲーム理論において、打ち手を決定する際に適用されるルールの一つ。
https://ja.wikipedia.org/wiki/%E3%83%9F%E3%83%8B%E3%83%9E%E3%83%83%E3%82%AF%E3%82%B9%E6%B3%95
プロセス、スレッドって何?
プロセスとは:
実行中のプログラム、もしくはリソースの要求単位
スレッドとは:
プロセスにおける処理、実行単位
上記だけだとよくわからないためもう少し踏み込んでみました。まずプロセスとは実行中のプログラムということですが、プログラムはOSによって実行されます。そのためまずはOSとは何か、どのようにプログラムを実行するのかということについて調べました。
OSとは
コンピュータの内部動作を調整し、外部とコミュニケーションを管理するソフトウェアパッケージ。PCの電源を入れた時に立ち上がるbootingはオペレーティングシステムを立ち上げており、内部動作としてはROM(read only memory)に格納されたboot Loaderが起動し、オペレーティングシステムがメモリ上にコピーされ、実行される。
構成要素
OSはユーザーインターフェースとカーネルからなる。特に一般に広く使われているキーボードやモニターを使ってOSとやりとりするシステムはGUI(graphical user interface)と呼ばれている。
カーネルはOSの内部部分であり、コンピュータの動作に対して基本的なソフトウェアが含まれる。ファイル記録を管理するファイルマネージャーやデバイスドライバ、メモリを管理するメモリマネージャーが代表的なものである。プログラム実行に際しては、カーネル内のCPUスケジュラ(ディスパッチャ)が大きな役割を果たす。
プログラム実行における役割
ではプログラムの実行においてOSは何のために存在するのか?
ハードウェア資源であるCPUやメモリ、基本的なモジュールを必要なだけ仮想的に作り出し、使いやすい形で各プロセスに提供します。(2023年8月追記: 仮想化という単語はVMなどを想起させるため、マッピングという呼び方の方が良いかもしれません)
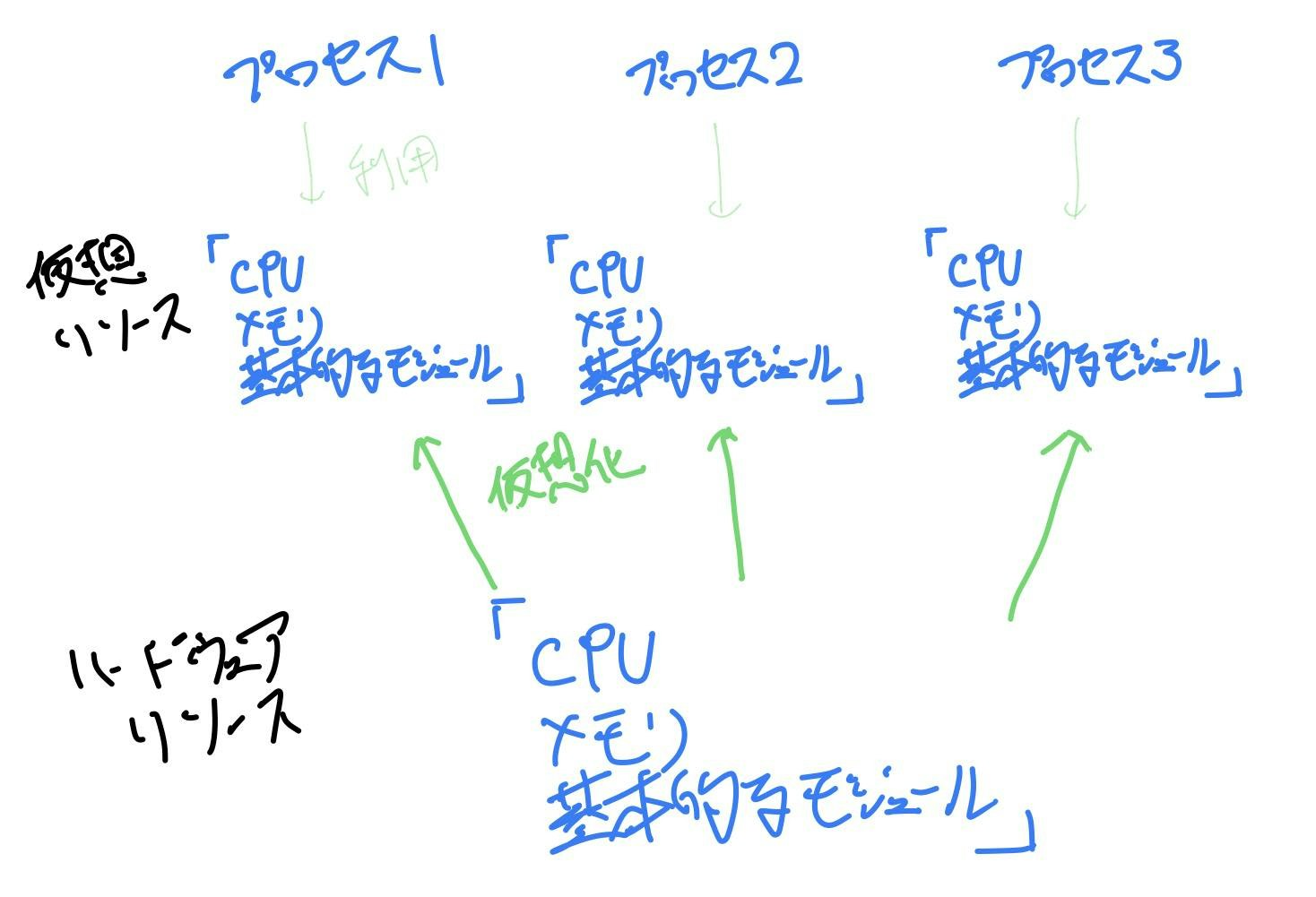
つまり、OSとは様々なソフトウェア、プログラム、アプリケーションを実行する上で土台となるシステムソフトウェアであり、実行に際してはハードウェアリソースを仮想化によって必要なだけ各実行対象(プロセス)に割り振り、実行を行う。ということになります。
(2023年8月追記) 補足として、リソースの仮想化(マッピング)はそれぞれ以下となっています。
- CPU: 後述のCPUスケジュリングによってCPUリソースを各プロセスにて利用します。
- メモリ: メモリマネージャ管理のもと、メモリ領域が割り当てられます。持っているメモリ領域を超えたメモリリソースが必要な場合は、ページングと呼ばれる方法によってハードディスク領域を使いながら、必要な部分だけを都度、メモリ領域に持ってくることで擬似的にメモリ領域を確保します。
CPUスケジュリングとは
では次に、プロセスがOSによって実行される際の挙動はどうなっているのでしょうか?基本的にはプロセスは以下の3つの状態を移行します。
- running: CPUが割り当てられ、実行中
- ready: CPUを確保すれば実行できる状態、CPU割り当て待ち
- wait: CPU割り当て以外を待っている状態(例:何らかのI/O完了を待っている)
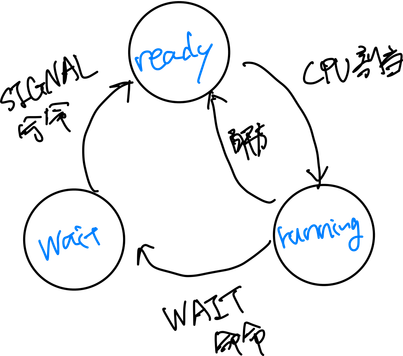
プロセスの状態の移行イメージは上記になります。ただ実際には複数のプロセスが存在するため、以下のように、プロセスの順番待ちが発生します。ここで各プロセスの状態、割り当てられたメモリ領域、優先順位などはメインメモリ内のプロセステーブルにプロセスごとに保存されます。

ここで、どのようにプロセス状態を切り替えて実行していくか、の方針がCPUスケジュリングになります。CPUスケジュリングの詳細は省略しますが、基本的には応答時間とスループットが最大効率になるように考えられており、適宜実行プロセスを切り替えながら全体の実行を進めています。この切り替えを コンテキストスイッチング(context switching) と呼びます。
また各プロセスにCPUが割り当てされて実行されていくと、大局的には各プロセスが自分専用のCPUを有しているかのように見ることができます。このとき各プロセスに割り当てされているように見えるCPUを仮想CPUと呼びます。CPUスケジュリングはハードウェアに一番近いレベルの仮想化であるため、これより上のレベルではCPUの割り当て、解放ではなくプロセスによる議論が可能になります。
おさらい - プロセスとスレッド
前置きが長くなりましたが、改めておさらいすると以下となります。
プロセスとは:
実行中のプログラム、もしくはリソースの要求単位
スレッドとは:
プロセスにおける処理、実行単位
プロセスには仮想CPUが割り当てられますが、実際にはスレッドという単位で実行されます。プロセスでは割り当てられたリソースがプロセスごとに独立しているため、プロセスをまたいでメモリを参照しようとすると時間がかかってしまいます。単一の空間内のリソースを共有しながら複数の処理を行なうほうが、ロジックの実装のしやすさやメモリ効率の面で優れている場合があります。それを可能にするのがスレッドです。スレッドはプロセス内に複数存在することができ、プロセスに割り当てされたリソースを共同で使用し、実際の処理を行なっていきます。
(2023年8月追記)曖昧な表現が多いため書き直しました。
オペレーティングシステムはCPUスケジューリングを通じてCPUリソースをプロセスやスレッドに割り当てます。各プロセスは独立したメモリアドレス空間を持っています。これに対し、スレッドは軽量な実行単位として導入され、同じプロセス内ではスレッド間においてのリソース共有と効率的なコンテキストスイッチを可能にしています。そのためスレッドを利用することにより高速なタスクの切り替えや効率的な並列処理が可能となりますが、後述するデッドロックや排他制御などが必要となるため、複雑性も増す可能性があります。

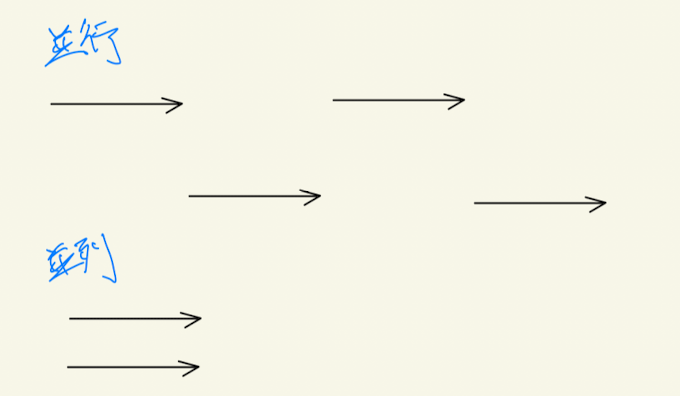
並行(concurrent)と並列(parallel)
ここまでスレッド、プロセスとは何か?どのように実行されるのか?を学んできましたが、次にCPUの利用方法についてです。CPUスケジュラによって、仮想CPUの処理は適宜切り替えられていきますが、基本的には並行処理 (concurrent)となります。時間やイベントによって複数タスクを適宜切り替えて処理を行なっていきます。一方で並列処理 (parallel)とは同時に複数の処理を同時に実行、処理することを言います。
これだけ見ると並列処理の方が優れているように見えますが、実際には処理内ではCPUを使う以外の待ち時間が発生します。(例:入力待ち)このとき、並行処理において、1つのタスクが入力待ちをしている間に、違うタスクを並行して実行する。などを行えば、並行処理で十分効率的に処理を行うことができます。また並列処理を行う際には、同じリソースに同時にアクセス、編集をするなどしてデータを壊さないように排他制御などが必要になることが多いため、コードとしては複雑になっていきます。
ざっくりいうと、以下となります。
CPUバウンドの処理(数値計算など) > 並列処理による時間短縮が可能
I/Oバウンドの処理(CPUを使わない待ち時間が想定される処理) > 並行処理で十分
Pythonでの並列処理
それではようやくPythonにおける並列処理についてです。まず前提として、Pythonは並列処理に向いていない言語であるということを理解します。Pythonでは最も広く使用されているインタプリタCPythonにはGIL(Global Interpreter Lock)と呼ばれる機構が備わっています。これはざっくりいうと一度に1スレッドしか実行できない保護制御の仕組みです。GILは*デッドロックを防ぎ、パフォーマンスの*オーバーヘッドを発生を抑制させますが、処理がシングルスレッドになるというパフォーマンス上の欠点もあります。
では具体的にどうするかというと、並列処理を行いたい場合はマルチプロセスによって処理を行います。Pythonのインタプリタはプロセスごとに独立しているため、プロセスを分けることによりGILを起こさず、並列処理が可能となります。実際のコードは標準モジュールであるconcurrent.futuresを使って書いていきます。
プロセスを分ける際、UNIXではforkと呼ばれる方法があるが、Windows, MacOSでは新規にプロセスを作成し、pickle, unpickleにて関数をコピーして新しいプロセスとします。そのため、pickleできない場合は、そもそもマルチプロセスによる並列処理ができないということになります。
インタプリタ(interpreter)
Pythonは書いたコードがそのまま実行されるわけではなく、バイトコードにコンパイルされた後、そのバイトコードをインタプリタが実行するインタプリタ言語です。対照的に、実行前に実行ファイルにコンパイルする言語をコンパイラ言語(Java, C++ etc,)と呼びます。CPythonはPythonコードをC言語に変換するインタプリタであり、最も広く使用されています。
デッドロック(dead lock)
2つ以上のプロセスが、それぞれ異なるプロセスに割り付けられた資源待ち状態となり、処理が止まってしまう現象。発生する代表例としては以下2つになります。
- 2つ以上のプロセスがお互いに、他者が所有しているアクセス権を待つことで処理が停止
- あるプロセスから新しいプロセスを生成した際に(UNIXでいうfork)プロセステーブルが満杯だと、1) スケジューラが新しいプロセスを登録できない, 2) プロセス完了の前に新しいプロセスを生成しないといけない状態、としてデッドロックとなります。
解決方法として、一度割り当てたリソースを強制的に取り上げたり、共有リソースに対してインターフェースを置くことで回避、解消する方法があります。
オーバーヘッド(over head)
ある作業やタスクを達成するための非生産的または非効率的な処理。代表的なものに時間オーバーヘッド、空間オーバーヘッドなどがあります。GILにおいては、シングルスレッドにすることにより、タスクの切り替え(コンテクストスイッチ)時間などを軽減するという意味合いが大きいかと思います。
排他制御(mutual exclusion)
先述のようにスレッドは同一メモリ空間を共有して処理を行うため、もし複数スレッドが同一プロセス内にあるときは、同じデータを複数のスレッドが同時に書き換えることを防ぐ必要があります。これは排他制御と呼ばれ、一例としてはセマフォアと呼ばれる割り込み可能、禁止フラグを用いて、一度に1つしか実行できないクリティカル領域にて複数のプロセスやスレッドが実行されることを防いでいます。これは並列処理の際にも同様となります。
concurrent.futuresについて
ここでは公式referenceのコードにそって、具体的にコードが何をしているかを解説します。
https://docs.python.org/3/library/concurrent.futures.html?highlight=concurent#concurrent.futures.Future
# ThreadPoolExecutor Exampl
import concurrent.futures
import urllib.request
URLS = ['http://www.foxnews.com/',
'http://www.cnn.com/',
'http://europe.wsj.com/',
'http://www.bbc.co.uk/',
'http://nonexistant-subdomain.python.org/']
# Retrieve a single page and report the URL and contents
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout=timeout) as conn:
return conn.read()
# We can use a with statement to ensure threads are cleaned up promptly
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
# Start the load operations and mark each future with its URL
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print('%r generated an exception: %s' % (url, exc))
else:
print('%r page is %d bytes' % (url, len(data)))
このコードが何を実施しているかは、おおまかに以下の順となります。load_urlについては省きます。
- ThreadPoolExecutor のインスタンスを作成: concurrent.futures.ThreadPoolExecutor を使用して、指定した数のスレッドを持つスレッドプールを作成します。指定しない場合、ver.3.8では
min(32, os.cpu_count() + 4)のスレッドがDefaultとなります。 - 非同期タスクの実行:
executor.submitにより関数とその引数を指定して非同期タスクをスケジュールします。このメソッドは、Future オブジェクトを返します。 - Future オブジェクトをdictionaryに格納: 実行されるタスクのFuture オブジェクトと関連するソースを辞書に格納します。
- as_completed メソッドを使用して結果を取得: concurrent.futures.as_completed メソッドを使用して、タスクが完了する順に結果を取得します。これはブロッキング操作のため、結果が利用可能になるまで現在のスレッドまたはプロセスの実行を一時停止します。
- 結果の取得とエラーの処理: future.result() メソッドを使用して結果を取得します。例外が発生した場合は、例外処理が返ってくるためtry-exceptを利用しています。
コードによるテスト
実行スピードテスト
以下の内容にて処理を書いて、処理時間を計測するテストを実施しました。実際のコードは後述しています。
- IO boundな処理において、シングルスレッドとマルチスレッド、マルチプロセスによる時間差を計測
予測:マルチスレッドは時間効率が上がる一方で、I/Oの待ち時間によりマルチプロセスのスピードはシングルスレッドと大して変わらないのではないか - CPU boundな処理において、シングルスレッドとマルチスレッド、マルチプロセスによる時間差を計測
予測:CPU boundな処理では、マルチプロセスによる短縮が可能な一方で、マルチスレッドではGILにより効率は上がらない
結果
それぞれ5回施行したところ、各処理の実行時間は以下となりました。
test 1: IO boundな処理において、シングルスレッドとマルチスレッド、マルチプロセスによる時間差
IO bound taken time in single thread 21.0732
IO bound taken time in multi-threading 20.3816
IO bound taken time in multi-processing 24.6216
これは想定通りの結果といえます。マルチスレッドにて実行しても、GILにより一度に実行されるスレッドは一つとなるため、あまり時間短縮につながっていません。マルチプロセスが一番時間がかかっていますが、プロセスの生成などに追加の時間を要していることが考えられます。
test 2: CPU boundな処理において、シングルスレッドとマルチスレッド、マルチプロセスによる時間差
CPU bound taken time in single thread 7.1408
CPU bound taken time in multi-threading 5.9268
CPU bound taken time in multi-processing 6.0286
予測と異なり、マルチプロセスでの処理が遅くなりました。これはプロセス間通信やオーバーヘッドによる時間が、並列処理による処理時間の短縮を上回っていると想定し、処理をより時間がかかるものに変更して再度テストしてみました。(コードにおけるN2を使用)
additional test: CPU boundな処理において、シングルスレッドとマルチスレッド、マルチプロセスによる時間差
CPU bound taken time in single thread 41.6768
CPU bound taken time in multi-threading 36.339
CPU bound taken time in multi-processing 42.1404
しかしやはりマルチスレッドによる実行が最も早いという結果となりました。ただ最も早い方法においても、シングルスレッドにて実行するのに対し10%程度しか変わっていません。 これはやはりGILにより、マルチスレッドが制限を受けているためと思われます。以下に追記したテストにより、上記テストが検証不足であったことが判明しています。
2023年8月追加テスト: CPU boundな処理をアップデートし再テスト
レビューをしてもらったところ、当初テストに使用していたコードがCPU boundではないのではないかという指摘をもらいました。int型の足し算、引き算、掛け算だとコンパイル時に効率化のために計算式が略されている可能性があるということです。(i += 1 * 2 + 3 + 4 + 5 - 6 が i += 8 へと自動的に変更されている可能性)
そのため、コードをfloat型にして再度テストをしました。併せて使用しているprocess, threadをprintして計測をわかりやすくしています。
# previous cpu_bound code
# def cpu_bound(n):
# pid = os.getpid()
# thread_id = threading.get_ident()
# print(f"PID: {pid}, TID: {thread_id}, N: {n}")
# i = 0
# while i < n:
# # i + 1
# i += 1 * 2 + 3 + 4 + 5 - 6
# print(f"PID: {pid} completed!")
# return
def cpu_bound(n):
pid = os.getpid()
thread_id = threading.get_ident()
print(f"PID: {pid}, TID: {thread_id}, N: {n}")
i = 0
r = 0.0
while i < n:
i += 1
r += 1.0 * 2.0 + 3.0 + 4.0 + 5.0 - 6.0
print(f"PID: {pid} completed!")
return
結果:
当初の想定通り、マルチプロセスが一番早いという結果になりました。以下にConsoleの表示を記載しますが、マルチスレッド、マルチプロセスにてそれぞれ想定したように、複数のスレッド、複数のプロセスが使用されているのがわかります。
CPU bound taken time in single thread: 204.591
CPU bound taken time in multi-threading: 138.697
CPU bound taken time in multi-processing: 41.299
PID: 36930, TID: 8437211264, N: 1000000000
PID: 36930 completed!
PID: 36930, TID: 8437211264, N: 1000000000
PID: 36930 completed!
PID: 36930, TID: 8437211264, N: 1000000000
PID: 36930 completed!
PID: 36930, TID: 8437211264, N: 1000000000
PID: 36930 completed!
PID: 36930, TID: 8437211264, N: 1000000000
PID: 36930 completed!
PID: 36930, TID: 8437211264, N: 1000000000
PID: 36930 completed!
CPU bound taken time in single thread: 204.591
PID: 36930, TID: 6145044480, N: 1000000000
PID: 36930, TID: 6161870848, N: 1000000000
PID: 36930, TID: 6178697216, N: 1000000000
PID: 36930, TID: 6212349952, N: 1000000000
PID: 36930, TID: 6195523584, N: 1000000000
PID: 36930, TID: 6229176320, N: 1000000000
PID: 36930 completed!
PID: 36930 completed!
PID: 36930 completed!
PID: 36930 completed!
PID: 36930 completed!
PID: 36930 completed!
CPU bound taken time in multi-threading: 138.697
PID: 38026, TID: 8437211264, N: 1000000000
PID: 38023, TID: 8437211264, N: 1000000000
PID: 38027, TID: 8437211264, N: 1000000000
PID: 38025, TID: 8437211264, N: 1000000000
PID: 38024, TID: 8437211264, N: 1000000000
PID: 38028, TID: 8437211264, N: 1000000000
PID: 38026 completed!
PID: 38023 completed!
PID: 38027 completed!
PID: 38024 completed!
PID: 38028 completed!
PID: 38025 completed!
CPU bound taken time in multi-processing: 41.299
テストコード (2023年8月 先述の新しいテストを追加したコードにアップデート)
import time
import concurrent.futures
import os
import threading
# io bound code
TEXT = "test" * 700000000
FILENAME = [
"1.txt",
"2.txt",
"3.txt",
"4.txt",
"5.txt",
]
def read_and_write_large_file(filename):
with open(filename, "w+") as f:
f.write(TEXT)
f.seek(0)
f.read()
os.remove(filename)
return
# cpu bound code
N1 = [
11222373,
11234558,
1142324527,
11552328,
1145423797,
]
# added for additional test
N2 = [
112223730,
112345580,
1142324527,
115523280,
11454237970,
]
# added on AUg 2023
N = [
1_000_000_000,
1_000_000_000,
1_000_000_000,
1_000_000_000,
1_000_000_000,
1_000_000_000,
]
# previous cpu_bound function
# def cpu_bound(n):
# i = 0
# while i < n:
# # i + 1
# i += 1 * 2 + 3 + 4 + 5 - 6
# return
def cpu_bound(n):
pid = os.getpid()
thread_id = threading.get_ident()
print(f"PID: {pid}, TID: {thread_id}, N: {n}")
i = 0
r = 0.0
while i < n:
i += 1
r += 1.0 * 2.0 + 3.0 + 4.0 + 5.0 - 6.0
print(f"PID: {pid} completed!")
return
def compare_IO_bound():
# single thread x io_bound
start = time.time()
for _filename in FILENAME:
read_and_write_large_file(_filename)
end = time.time()
print(f'IO bound taken time in single thread: {(end - start):.3f}')
# multi thread x io_bound
start = time.time()
with concurrent.futures.ThreadPoolExecutor() as executor:
result = list(executor.map(read_and_write_large_file, FILENAME))
end = time.time()
print(f'IO bound taken time in multi-threading: {(end - start):.3f}')
# multi process x io_bound
start = time.time()
with concurrent.futures.ProcessPoolExecutor() as executor:
result = list(executor.map(read_and_write_large_file, FILENAME))
end = time.time()
#print(f"CPU counts: {os.cpu_count()}")
print(f'IO bound taken time in multi-processing: {(end - start):.3f}')
def compare_cpu_bound():
# single thread x cpu_bound
start = time.time()
for n in N:
cpu_bound(n)
end = time.time()
print(f'CPU bound taken time in single thread: {(end - start):.3f}')
# multi thread x cpu_bound
start = time.time()
with concurrent.futures.ThreadPoolExecutor() as executor:
for number in N:
executor.submit(cpu_bound, number)
end = time.time()
print(f'CPU bound taken time in multi-threading: {(end - start):.3f}')
# multi process x cpu_bound
start = time.time()
with concurrent.futures.ProcessPoolExecutor() as executor:
for number in N:
executor.submit(cpu_bound, number)
end = time.time()
print(f'CPU bound taken time in multi-processing: {(end - start):.3f}')
def main():
compare_cpu_bound()
if __name__ == '__main__':
main()
五目並べのコードにおける並列処理
実際の五目並べのMinimaxにおいて、マルチスレッド、マルチプロセスを入れて実行してみました。上記テストにおいてはマルチスレッドの方が速いスピードとなりましたが、Minimaxにおいては効率化には繋がりませんでした。現状、計算時間短縮の工夫として 1)評価が高くなりそうな探索範囲から順に探索する、2)α-β枝刈りによる探索ストップ、の組み合わせを行っていますが、マルチスレッドを導入した場合、CPUリソースを分割して同時に探索を行うため、1), 2) の工夫が十分に働かないためと考えられます。
一方でマルチプロセスを導入したところ、導入前と比較して効率化が見られました。コードは省略しますが、CPUがお互いにMinimaxにて手を進めていき、20手で決着がつきました。最後の太字が探索にかかった合計秒数です。マルチプロセスを導入することにより、約80%のスピードアップを達成することができました!一方で、盤面が進むと一手に1分近くかかるようになり、ゲームとしてはまだまだ改善の余地があると思います。さらなる改善に向けて開発を進めていければと思います。
| SIngle Process | Multi Process | Single - Multi |
|---|---|---|
| 0.1052699089 | 0.1052360535 | 0.00003385543823 |
| 10.18833518 | 1.980844736 | 8.207490444 |
| 52.93386102 | 9.544928074 | 43.38893294 |
| 76.88481808 | 14.30689383 | 62.57792425 |
| 156.0866401 | 26.96754313 | 129.119097 |
| 103.9936609 | 20.47846699 | 83.51519394 |
| 227.9320452 | 41.51084685 | 186.4211984 |
| 158.290081 | 27.52013707 | 130.769944 |
| 259.9909561 | 44.86364317 | 215.1273129 |
| 170.9293549 | 31.19464874 | 139.7347062 |
| 195.576371 | 35.92622995 | 159.650141 |
| 305.1763432 | 53.20937395 | 251.9669693 |
| 312.5177882 | 54.77321815 | 257.74457 |
| 138.6956177 | 24.29303813 | 114.4025795 |
| 305.1252859 | 53.22223878 | 251.9030471 |
| 124.1425471 | 21.524158 | 102.6183891 |
| 226.930228 | 39.16670585 | 187.7635221 |
| 173.5466349 | 30.34393287 | 143.202702 |
| 0.8578002453 | 0.4015629292 | 0.4562373161 |
| 2999.903639 | 531.3336473 | 2468.569991 |
参考資料
入門コンピュータ科学 (ASCII DWANGO)
オペレーションシステム (岩波講座 ソフトウェア科学 6)