はじめに
ウマ娘にドハマリした友人の影響で今年から競馬を始めてみました。初心者ながらに予想をしていると、他の人の意見が気になって自分の予想に自信がもてません。ならいっそのこと、みんなの予想に乗っかって馬買えば当たるんじゃね?と思い、Twitterから予想を集めてオリジナルの人気順を作るプログラムをPythonで書きました。
プログラムの内容
- netkeibaにある出馬表のページから、指定したレースの馬名をスクレイピングする
- 取得した馬名からTwitterAPIを用いて、ツイートをしている数をカウント
- 結果に出力(パラメータ指定でCSV出力も可能)
馬名のスクレイピングですが、JRAのサイトは最新レースの出馬表ページは取得するのにPOST処理が必要だったに対し、netkeibaはレースIDをクエリ文字列でGETすれば取得できたので、かんたんな方を採用しました。
また、カウント対象ツイートですが、前日に予想を投稿することを考慮し、過去2日分にしています。(パラメータで変更可能)
使用ライブラリ(抜粋)
- pandas
- 取得結果をDataFrameで管理するため使用
- DataFrameからCSV出力できるのでめっちゃ便利
- requests
- HTTP通信用のPythonのライブラリ
- netkeibaからHTML取得や、TwitterAPIを利用するために使用
- BeautifulSoup4
- ご存知HTML解析ライブラリ
- netkeibaから馬名取得用
- 間違えて4がついてないやつをpipで入れようとしてエラーになるのはあるある
取得するツイートについて
Twitterで検索する際、馬名が含まれているツイートだけだと、「【馬名】は危ない」とかネガティブなツイートであったり、他の意味で使われている馬名(例:カラテ、キセキなど)だったりすると正しく結果が取得できない可能性があります。
そのため、予想印+馬名(例:◎コントレイル)のカウントも取得するようにしました。
予想印は以下のとおりです。
| 予想印 | 意味 |
|---|---|
| ◎ | 本命:1番勝ちそう |
| ○ | 対抗:2番目ぐらいに勝ちそう |
| ▲ | 単穴:3番目ぐらいに勝ちそう |
| △ | 連下:1着は難しいかもだけど2 or 3着なら入ってくれそう |
| ☆ | 穴:人気薄いけどもしかしたら1着になっちゃうかも |
例えば、この前引退した「コントレイル」が本命の場合、◎コントレイルとなります。
なお、穴(☆)は、人によって表記が異なるので、以下の3つを対象にしています。
- ☆
- ★
- ❌(記号の☓はなぜかTwitterクエリが誤作動を起こすので除外)
※☓は穴以外にも連下(△)以下の評価につけることがあるなど、諸説あるみたいです。
ソースコード
import sys
import argparse
import pandas as pd
import requests
from bs4 import BeautifulSoup
from datetime import datetime, date, timedelta
import urllib.parse
import json
# Constants
URL = 'https://race.netkeiba.com/race/shutuba.html?race_id={0}&rf=race_list'
API_SEARCH_URL = 'https://api.twitter.com/2/tweets/search/recent?query={}&tweet.fields={}&max_results={}&start_time={}'
API_TWEET_COUNTS_URL = 'https://api.twitter.com/2/tweets/counts/recent?query={}&start_time={}&granularity=day'
# Twitter Token
BEARER_TOKEN = 'ここにTwitterAPITOKENをいれます'
# Twitter Api Condition
TWEET_FIELDS = "author_id,id,text,created_at"
MAX_RESULTS = 100
def main(race_id='', days=2, csv=''):
# input
if not race_id:
race_id = input("netkeibaレースページの「race_id=」以降の数字を入力してください。(未入力の場合は函館記念=202102010611)")
if not race_id:
race_id = '202102010611'
url = URL.format(race_id)
horse_data = get_horse_data(url)
if horse_data.empty:
print('Error: race_idに一致するレースが存在しませんでした。', file=sys.stderr)
sys.exit(1)
result_data = analyze_tweet(horse_data, days, True)
if csv:
result_data.to_csv(csv, index=False)
print(result_data)
# netkeibaから馬名を取得
def get_horse_data(url: str) -> pd.DataFrame:
columns = ['場所', '馬番', '馬名']
html = requests.get(url)
soup = BeautifulSoup(html.content, "html.parser")
df_rows = []
area = soup.find('div', class_='RaceData02').findAll('span')[1].get_text()
print(area)
for row_horse in soup.findAll('tr', class_='HorseList'):
horse_num = row_horse.findAll('td')[1].get_text()
horse_name = row_horse.find('span', class_='HorseName').find('a').get_text()
df_cols = [area, horse_num, horse_name]
df_rows.append(df_cols)
return pd.DataFrame(df_rows, columns=columns)
# Twitterクエリを生成して、ツイート数を取得
def analyze_tweet(horse_data: pd.DataFrame, days: int, area=False) -> pd.DataFrame:
today = date.today()
yesterday = today - timedelta(days=days)
lst_mark = ['全ツイート数', '◎', '○', '▲', '△', '☆']
ana = ['❌', '★', '☆']
for mark in lst_mark:
horse_data[mark] = 0
horse_data['◎-△ツイート合計'] = 0
for index, row in horse_data.iterrows():
print(row['馬名'])
cnt_mark = 0
# クエリ生成
for mark in lst_mark:
if mark == '全ツイート数':
horse = '"{}"'.format(row['馬名'])
elif mark == '☆':
horse = ' OR '.join(['"{}"'.format(m + row['馬名']) for m in ana])
else:
horse = '"{}"'.format(mark + row['馬名'])
if area:
horse = '({0}) "{1}"'.format(horse, row['場所'])
# 検索条件
lst_query_condition = [
horse,
'-is:retweet',
'-is:reply',
'-is:quote',
]
query = ' '.join(lst_query_condition)
# ツイート数取得
count_data = _count_tweet(urllib.parse.quote(query), yesterday)
total_count = int(count_data["meta"]["total_tweet_count"])
horse_data.at[index, mark] = total_count
if mark not in ['全ツイート数', '×']:
cnt_mark = cnt_mark + total_count
horse_data.at[index, '◎-△ツイート合計'] = cnt_mark
return horse_data
def _count_tweet(query, start_time):
url = _create_tweet_count_url(query, start_time)
headers = _create_headers()
json_response = _connect_to_endpoint(url, headers)
return json_response
def _create_tweet_count_url(query, start_time):
url = API_TWEET_COUNTS_URL.format(
query,
datetime.strftime(start_time, '%Y-%m-%dT%H:%M:%SZ'),
)
return url
def _create_headers():
headers = {"Authorization": "Bearer {}".format(BEARER_TOKEN)}
return headers
def _connect_to_endpoint(url, headers):
response = requests.request("GET", url, headers=headers)
if response.status_code != 200:
raise Exception(response.status_code, response.text)
return response.json()
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='netkeibaのレース情報から馬名を取得し、それぞれどのぐらいTwitterでツイートされているか解析します。')
parser.add_argument('--race_id', help='netkeibaレース情報のrace_id')
parser.add_argument('-d', '--days', help='過去○日までのツイートから解析します', type=int, default=2)
parser.add_argument('--csv', help='ファイル名を指定すると、CSV出力されます')
args = parser.parse_args()
main(args.race_id, args.days, args.csv)
出力結果
2021年12月5日に行われたチャンピオンズカップ(GI)の際、直前に実行した結果が以下になります。
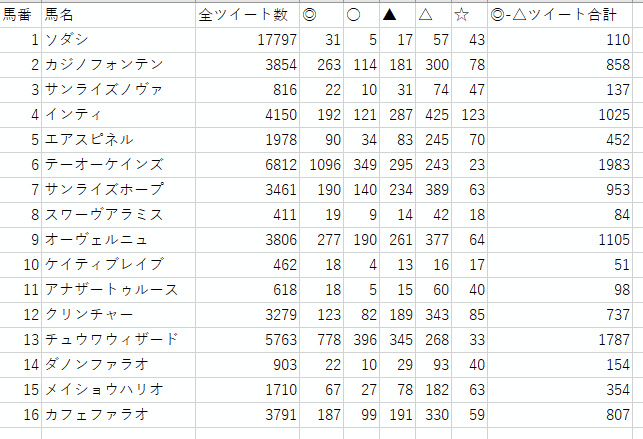
なお、「全ツイート数」は馬名を含めたツイート数、「◎-△ツイート合計」は☆(穴)以外の予想印列の合計を表しています。
ここで注目すべきなのは1番のソダシです。アイドル馬だけあって、馬名を含めたツイート数(全ツイート数列)ではダントツなのに対し、予想印を含めたツイートはあまりついていません。実際のレース結果でもソダシは12着に沈んでいます。
感想
穴馬が上位に来るような結果を予想していたのですが、正直いうとチャンピオンズカップのソダシみたいな例は稀で、重賞だとほとんど単勝人気が強い馬が出てきていることが多かったです。
ただ、「◎-△ツイート合計」で並び替えをしたとき、単勝人気では4,5位の馬が下の方に行き、6~8位あたりの馬が上がってくることはよく見られたので、「あと1頭削りたい」とか、「少しオッズ高めを狙いたいからあと1頭選びたい」などシチュエーションには使えるかなと思います。
本日は阪神ジュベナイルフィリーズが開催されます!みなさんの参考資料の一つになれたら幸いです。(このプログラムを使って外れた場合でも責任は負いませんのご了承ください)