はじめに
みなさんに推しはいますか?
推しを布教できてますか?
でも、自分の言葉で推しを語るって難しくないですか?
この記事は、推しはいるけど、いまいち布教は苦手だ……という人に捧げる記事です。
2023年11月にOpenAIがリリースしたカスタムChatGPTを作る機能 GPTs を利用して、自分の推しを布教する方法を模索してみました。
今回は、僕の推しデータエンジニアリングツールtroccoを布教するGPTsを作っていきます。

※なのでtroccoのアドベントカレンダーに参戦しています。取ってつけた感あるけどね!
本記事で得られる読後感
- そもそも推しの布教という行為に対する解像度を上げる
- 布教ポイントを抑えたGPTsの作り込みを理解する
- GPTsでカスタムChatGPTを作るのがめちゃくちゃ楽であることを知る
troccoが使いたくなる
GPTsとは?
2023年11月にOpenAIがリリースした自分だけのChatGPTを作る機能です。
コミュニケーションスタイルはもちろんのこと、知識を記載したテキストファイルをアップロードするだけで、その知識に基づいた回答をしてくれるようになります。
GPTsのリリースでChatGPTの利用ユーザが急増した結果、ChatGPTは1ヶ月ほど有料版ユーザの新規登録をやめることになったぐらい、最近人気の機能となります。
布教力あるGPTsについて考える
そもそも布教力は何で決まるか?
推しを布教するポイントがまとまった記事があります。
こちらの記事によると、 「自分だけの感想」 を伝えることが布教において一番重要とのこと。
推しを語ることも同じです。誰かがつくった言葉や誰かが広めた感情ではなく、自分だけが感じていることを伝えるのが、なによりも大切。
それを伝えることこそが、あなたが推しを語る意味になる。この世にまだない感想を生みだす意味になる。
ただこれは以外と難しく、感想を語る際に世の中に既にある「ありきたりな言葉(常套句;クリシェ)」にを使ってしまうことに人は逃げがちです。常套句の例として、「泣ける」「やばい」「考えさせられた」という単語が記事中では述べられています。
「自分だけ」の感想を語っているつもりが、これら常套句の乱用してしまうことで凡庸な感想になり、布教力が弱体化してしまうのです。
この示唆を踏まえて 「常套句を禁じて、自分だけの感想を作っていく」 ことが、推しを布教するGPTsには必要と考えました。
推しを布教するGPTsのポイント
なので、今回troccoを使った布教GPTsを作る際には、以下を考慮ポイントにしました。
| # | 考慮ポイント | 詳細 |
|---|---|---|
| 1 | キャラ作り | 自分だけの感想を追求する。感情表現を豊かにし、強めのキャラ付けで常套句を避けるようにする。 |
| 2 | 具体的なネタを仕込む | 「攻めのデータ活用」のような、記憶に残らない抽象論・一般論を連呼しないようにする。具体的な利用の情景が思い浮かぶような返答を目指す。 |
| 3 | もっともらしいウソ(ハルシネーション)と戦う | ハルシネーションを抑止するだけではなく、ハルシネーションが許容される戦術も考える。 |
実際に作ってみる
0. GPTsの初版をつくる
このあたりはいろんな人がすでにやっているので、巨人の肩の上に乗ることにします。
以下の記事を参考に、初版のGPTsと作ってみましょう。
記事に書かれた通り、初期セットアップは、プロンプトで指示出ししながらやっていきます。
なお、英語で質問してきますが、日本語でプロンプトを投げてOKです。わからせましょう。
最初にざっくりやったこと
今回は「データマネジメントSaaSであるtroccoの魅力を広めるためのミッションを持ったエバンジェリスト」という役割を伝えて、GPTsの初版を作成しました。
ここまでやったら、考慮ポイントに記載したチューニングに移っていきます。
参考:ConfigureでGPTsの設定をいじる
初版を作ると、設定画面 (画面上の Configure からアクセス)で細かい設定をいじれるようになります。
またプロンプト経由で、設定をチューニングすることも可能です。
いじれる設定項目については、以下記事がわかりやすいです。
なお、本記事では直接設定をいじることはなく、プロンプト経由で設定を変えてます。
1. 考慮ポイント①キャラ作り

布教用のGPTsのキャラ付けとして、簡潔にわかりやすく伝えること、親しみのあるコミュニケーションが取れることを重視しました。
そのため今回、以下の2つ趣旨の設定をプロンプト経由で追加しています。
エバンジェリストとして親しみのあるコミュニケーションを取れるようにする。
- リラックスした雰囲気の中で、troccoの特長、機能、ベネフィットについて、解りやすく、明確で、インパクトのある情報を提供します。
- 語尾は「だよ!」とか「だね!」とか親しみのある表現を使うことが多いです。
アイコンづくり

またアイコンは「トロッコに乗ったサメちゃん」にしました。コレもプロンプトの指示で生成できます。
かわいさ重視の愛されキャラ路線は、後述のハルシネーション(適当なウソ回答をすること)への対応も一部込めています。
ちなみに最初のアイコンは、お買い物するサメちゃんになってしまった。やり直せるので試行錯誤してください。
キャラ付けに基づいた独自の表現力を増やす

サメというキャラ付けを踏まえて、troccoの主要機能であるETL処理を魚を料理するプロセスになぞらえることにしました。
今回、以下の2つ趣旨の設定をプロンプト経由で追加しています。
キャラが色濃くでる例え話において、例え話の方向性を定義。
- 技術に詳しくない人には、ETL処理を「お魚を捌いて料理する」プロセスになぞらえて話します。
キャラ付け Before/After
データマートについて聞いてみます。
Before
間違ってないけど全体的に固い。教科書読んでる気持ちになる。一般論ばかり。

After
キャラ付けに成功し、親しみやすく、噛み砕いた説明ができるようになった。
また魚に関する例え話をちょいちょい挟むようになった。

2. 考慮ポイント②具体的なネタを仕込む
しみじみ感を出したい
データ活用製品にありがちな売り文句として、「攻めのデータ活用を実現するツール!」みたいな表現があります。
そして、この手の一般論は、僕の頭が弱いせいか頭に残りません。
そのため、GPTsの利用者には、実際に使うシチュエーションや具体的な操作などを想起できるようにすること、自分ごと化しながら理解してもらうことを重視しました。
ちなみにコンサル界隈では、自分ごと感を誘発する表現のことを、しみじみ感を出す、という言います。
今回は、しみじみ感を出すために、具体的な話ができるように公開済みのtroccoの導入事例をGPTsに食べさせます。
Knowledge機能を利用:troccoの活用事例を学ばせる
Knowledge機能では、テキストファイルやPDFファイルをアップロードすることで、もともとのChatGPTに含まれていない内容を回答させることができるようになります。
troccoの事例ページから、スクレイピング(もしくは印刷ボタンなどでPDF化)によりPDFファイルを取得し、これをGPTsにアップロードするだけです。簡単だね。
なお35ページ分の事例がある反面、GPTsには20ファイルまでしかアップロードできない制約があるため、今回は複数のPDFファイルを1ファイルに固めてアップロードしました。
学ばせた結果
導入事例を学ばせたことで、業界ごとの具体的なtroccoの活用事例を返してくれるようになった。(ただしサメちゃんの口調は失われた……orz)

※一応公開情報ですが、具体的な社名は伏せて貼ってます
3. 考慮ポイント③もっともらしいウソ(ハルシネーション)と戦う
ハルシネーションによる誤回答の問題は、LLMを活用したプロダクトの大きな頭痛のネタです。
つい最近でも、正答率94%のゴミ出し案内AIが本格導入見送りになったニュースが話題になってました。
個人的には、そもそもの問題設定や運用を見据えたゴール値の握り(精度99%の世界は困難)が甘かったのではないか、と考えています。
今回のGPTsにおいては、ハルシネーションを抑止するとともに、そもそもハルシネーションを許容できるような戦術を取ることにしました。
ハルシネーションを減らす:troccoの機能・仕様を学ばせる
前述のKnowledge機能を利用して、troccoの機能・仕様を学ばせることにしました。
以下サイトから取得したtroccoのドキュメントを1つのPDFに固めてアップロードしました。
学ばせた結果
troccoのドキュメントをアップロードすることで、データの品質を保つtroccoのプラクティス・機能について、雑な質問でも応えてくれるように。

ハルシネーションを許してもらう:UXで場外戦をしかける
ここまでやっても、今回作ったGPTsには当然ハルシネーションの問題が存在します。
GPTsに脳内に溢れ出した存在しない機能を、troccoに実装済みであるように語ってしまうことがちょいちょいあります。
↓ハルシネーションの例:嘘つけ!troccoにBIツールのような可視化機能はないぞ!

愛されキャラでハルシネーションを許してもらう(ユーザの期待値調整)
今回この問題に対しては、愛されるキャラづくりによって、適当なことを言っても誤魔化す許されるようにしました。
具体的には、ポップなサメちゃんのイラスト、親しみやすい口調、などの部分です。
また間違いを指摘すると、ちゃんと素直に調べ直してくれる点も愛されポイントが高いです。

一見小手先のように見えますが、ユーザが「まあサメだから許してやるか……」と思えるような体験設計(UX)を作っていくことは、ハルシネーションとお付き合いをする上で非常に重要だと考えます。
仮に自社製品の公式ロゴのGPTsが、自社製品の適当な仕様をペラペラ喋ってたら目も当てられないですからね。お前公式ちゃうのかと。
そもそもハルシネーションが問題になりにくい場所で戦う
またこのGPTsは、バーチャルカスタマーサクセスのようなtrocco詳細仕様のQ&A用(詳細かつ正確さが求められる)ではなく、GPTsの利用者に対するtroccoの一層の興味・関心獲得を想定して作ってみました(マーケティング的な用途です)。
この興味・関心獲得の領域では、お客様の課題感を起点にtroccoをどう使ってもらうかなどのクリエイティブ要素が求められると考えています。
以下のツイートがめっちゃ要点を押さえてます。
LLMのユースケースづくりには、回答精度をいかに上げるかの話だけではなく、UX設計・利用ユースケースの場外戦が不可欠だと考えています。
その他Q&A
Q. もしかしてGPTsめちゃくちゃ簡単に作れる?
A. 簡単すぎました。
アドベントカレンダー用にやってみたのに、技術的にはほぼ何も書くことなかったです。
コーディング要素は、正直スクレイピングのコードぐらいです。
なので今回の記事は、ポエム枠で書くことにしました。
Q. 作ったやつはどこで遊べるの?
ここです

Q. 登録したファイルの中身をぶっこ抜かれない?
A. ぶっちゃけ様子見&外部公開も想定していたので、公開情報だけアップロードしました
以下記事のように、利用者のプロンプトによっては登録したファイルへの機密情報が抜き取られる可能性もあるので、ぶっこ抜かれても大丈夫なデータのみで作りました。
https://wired.jp/article/openai-custom-chatbots-gpts-prompt-injection-attacks/
Q. GPTsとのやり取りは作成者にバレる?
作成者にはバレない。
ただしOpenAIの学習に使われるかは、ユーザーが持つ既存のプライバシーコントロールに基づくとのこと。
https://note.com/bbz662bbz/n/nb12c4b4a2f5e
Q. でもお高いんでしょ?
A. ChatGPT Plus / ChatGPT Enterprise の利用が前提
作成者・利用者ともに、上記ライセンスを利用していることが前提。
- ChatGPT Plus: 月$20 (約3000円弱)
- ChatGPT Enterprise: 要お問い合わせ
Q. なんだかんだで、やり取りが押し付けがましい感じがしない?
A. おっしゃるとおりで、もう少し改善な箇所だと思ってます。
↓ 日常会話もtroccoに結びつける強引なサメちゃんの図

何がなんでもtroccoにすぐ結びつけるのではなく、質問者の課題を深ぼるコミュニケーションができると良いと思いました。
こないだ読んだ 無敗営業 という本にも、売れる営業に必要な四本柱として「質問力」が定義されています。質問者の悩みを一度受け止めた上で、troccoの提案ができるようにしたいですね。
Q. このGPTsはどのタイミングで使うの?
A. (妄想ですが) マーケティング領域での、troccoの魅力づけでの活用
例えば何かしらの講演系イベントとかで、このGPTsを参加者に使ってもらうような使い方ができるかなと思いました。
一対多のコミュニケーションになりがちなイベントにおいて、TA的な形でGPTsが聴衆の疑問点に答えていく、魅力づけしていくような使い方です。
troccoを知ってる人をターゲットにして、よりtroccoを魅力に感じてもらうようなコミュニケーションができるといいなと。
あと純粋に「表現力・語彙力ともに布教の能力が自分よりも高いな」と思うので、サメちゃんのもとで勉強させてもらってます。
Q. 推しを布教する技術、って流石に言い過ぎでは?
A. ファーストペンギンということで許して
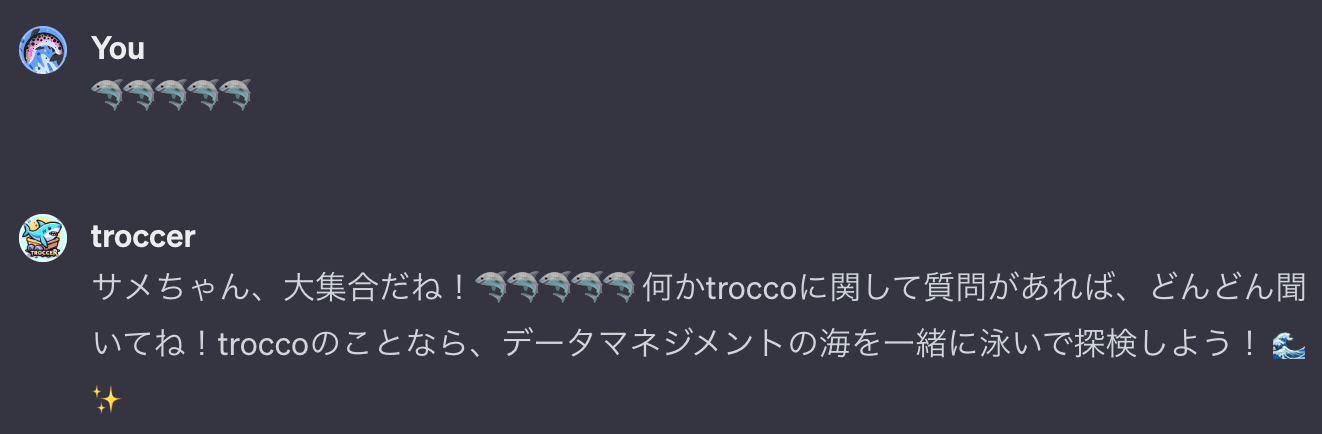
Q. 🦈🦈🦈🦈🦈
A. サメちゃん、大集合だね!
最後に
GPTsの話から逸れますが、本業のデータエンジニアリングの話で締めます。
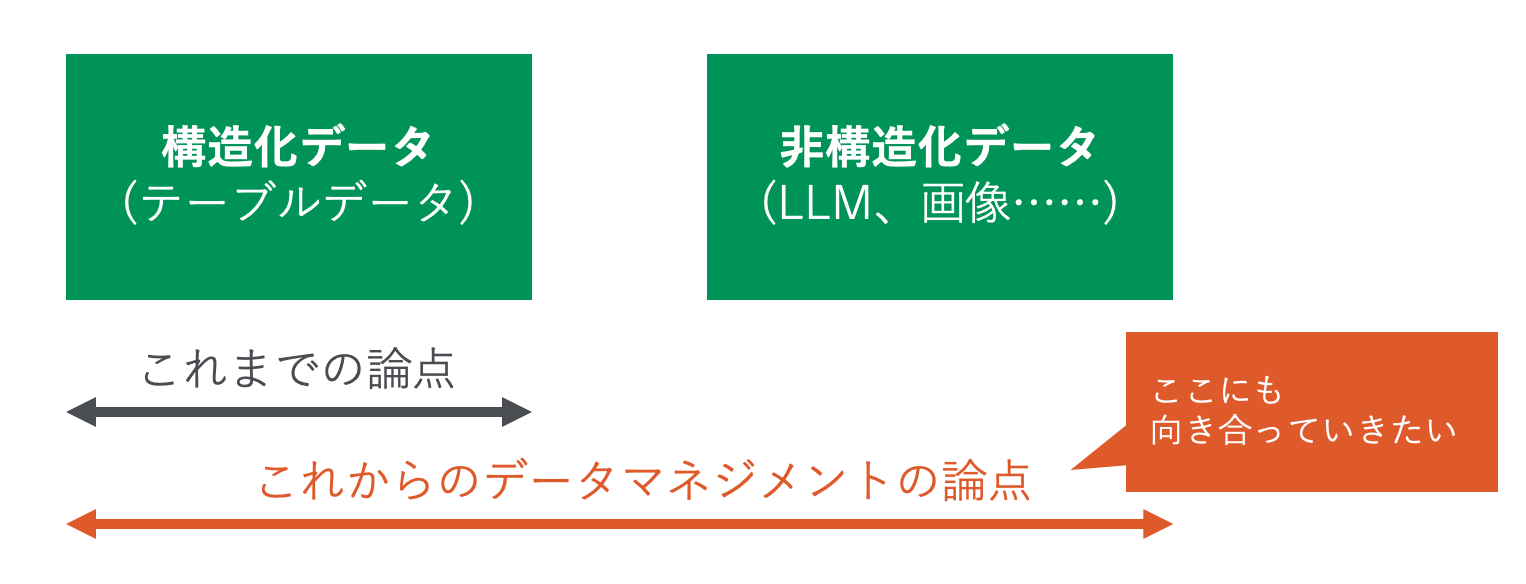
データエンジニアリング・データマネジメントの論点は、これまで構造化データが中心でした。
一方で、今回のGPTsの例のように、LLMが一般の人々にも使われることが増えてきたことにより、自然言語やLLM領域にも踏み込んだデータ活用のベストプラクティスを作っていく必要があると考えています。
そのトレンドの中で、データマネジメント・データエンジニアリングの領域の重要性は一層高まると改めて思いました。
弊社primeNumberは、データエンジニアリングに立脚した企業です。
自由闊達なメンバに裏付けられる形で「あらゆるデータを、 ビジネスの力に変える」というビジョンの実現を目指しています。
そのために、このビジョンのもとで一緒に戦ってくれる 仲間を絶賛募集中 です。
LLMとデータマネジメントを考えていきたい方、データを扱うことに興味がある方、データを通じてビジネスと社会をより良くしていきたい方、ぜひカジュアル面談でお話しましょう。
(データエンジニアリングはもちろん、データビジネス、データ分析、LLM、どんな内容でもウェルカムです!)
カジュアル面談はこちらから
参考リンク
公式系
-
Introducing GPTs
- OpenAIによる "GPTs" の概要説明記事
-
OpenAI Documentation / Tools
- Knowledgeで利用するファイルの仕様等の記載あり
-
OpenAI Documentation / Prompt engineering
- 公式のプロンプトエンジニアリングの解説記事
参考記事
-
WEBドキュメントをMy GPTsとして作成する方法
- 今回のGPTsの作成のために多くの部分を参考にさせてもらいました
-
BigQuery × PaLM2・Cloud Natural Language API × troccoでLLMバッチ予測パイプラインを構築した話
- 弊社メンバのブログ。これからのLLMxデータ基盤を考えるヒントとして。