データの読み込み(CSVファイル)
import pandas as pd
file = pd.read_csv("FileName.csv")
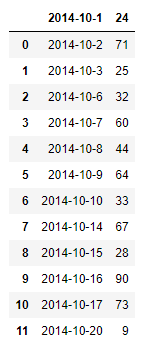
*データが列の名前に組み込まれたとき*
file = pd.read_csv("FileName.csv",header=None)
使えそうな関数とか
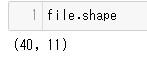
shape
データ行列の形を知ることができる
*shapeは関数じゃないから.shape()としない(アトリビュート?とかいうやつっぽい)*
head()
先頭から5行を取得
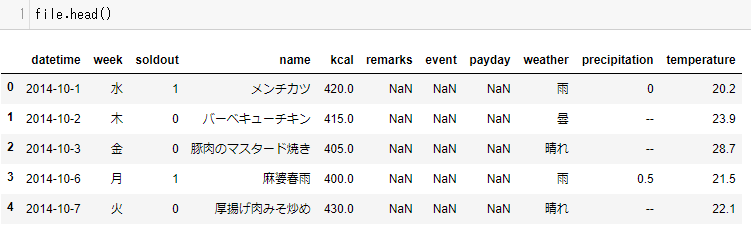
*引数に数字を入れることで表示される行数を指定できる*
先頭から7行取得
tail()
末尾から5行を取得

*引数に数字を入れることで表示される行数を指定できる*
末尾から7行取得

describe()
基本統計量の確認ができる
info()
カラムごとの情報を確認できる
mean()
test["A"].mean()
こんな感じで記述してカラムAの要素の平均値が出せる
median()
test["A"].median()
こんな感じで記述してカラムAの要素の中央値が出せる
sort_values(by="XXX"):昇順
test[test["おすし"]=="まぐろ"].sort_values(by="金額")
こんな感じで書くと、データフレームtestの"おすし"カラム中の"まぐろ"要素を抜き出して、"金額"で昇順ソートする
sort_values(by="XXX",ascending=False):降順
test[test["おすし"]=="まぐろ"].sort_values(by="金額")
こんな感じで書くと、データフレームtestの"おすし"カラム中の"まぐろ"要素を抜き出して、"金額"で降順ソートする