はじめに
大学の情報理論の講義で、分節可能符号について学びました。
分節可能符号であるかどうかは、判別アルゴリズムを使って判断できます。その判別アルゴリズムをRubyで実装してみました。
ちなみにこのアルゴリズムは、Sardinas-Patterson Algorithmというものだそうです。
分節可能符号とは
分節可能な符号のことで、ある符号が与えられた時、その符号が1通りの復号しかできない符号のことです。2通り以上に復号できるものは分節可能符号ではありません。
たとえば、符号語系列1100101111010があったとします。これを復号するために以下の符号が与えられています。
{a, b, c, d} = {00, 10, 11, 110}
これは、たとえば符号が00だった場合、復号するとaになることを表しています。
では、1100101111010を復号するとどのようになるでしょうか?
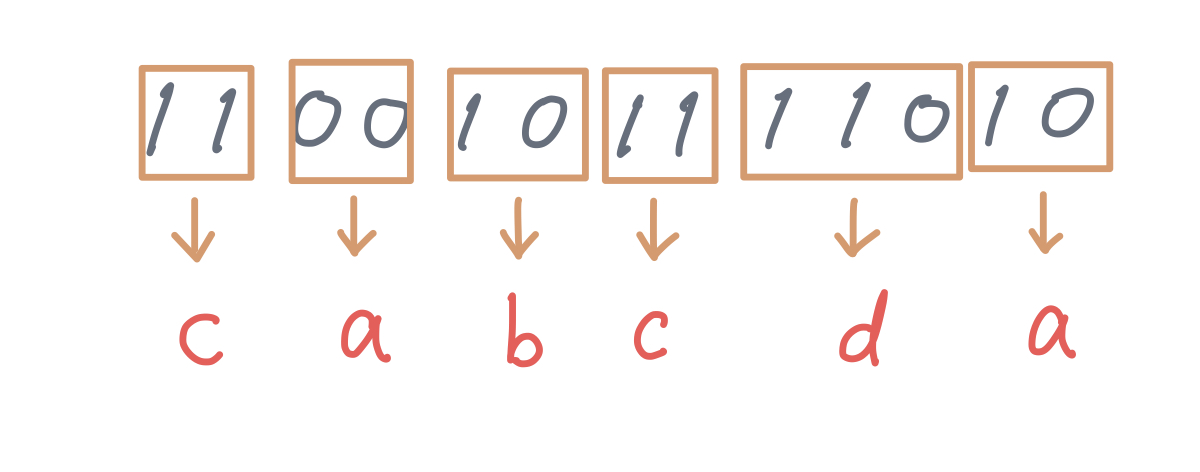
答えは、cabcdaの1通りのみです。すなわち、この符号は分節可能符号であると言えます。
分節可能符号判別アルゴリズムとは
分節可能符号であるかどうかは、1つでも2通りに復号されるような例を見つければわかります。その符号は分節可能符号ではないことがわかるからです。しかし、そのような例を見つけるにはすべての符号語の組み合わせについてチェックしなければなりません。これは不可能です。
簡単に判別できるようにしたのが分節可能符号の判別アルゴリズムです。
符号 C があります。
- 集合 S[0] を
S[0] = Cとします。 - 集合 S[1] は、
S[1] = S[0]とS[0]自身の差分 - 集合 S[2] は、
S[2] = S1 または(和集合) S[0]とS[1]の差分 - 集合 S[3] は、
S[3] = S2 または(和集合) S[0]とS[2]の差分
:
: - 集合 S[n+1] と集合 S[n] が等しくなるまで繰り返します。
- 集合 S[n+1] に集合 S[0] の要素が1つも含まれていなければ、C は分節可能符号です。1つでも含まれていれば、分節可能符号ではありません。
※「差分」とは
2つの系列 a, b において、a が b の語頭になっているとき、系列 b から語頭 a の部分を取り除いた系列を差分という. (近代科学社, はじめての情報理論 P.63より)
つまり、ある符号がほかの符号の語頭になっている時、その語頭の部分以外の系列のことです。
たとえば、S[0] = {0, 00, 01, 001, 11, 110}が与えられている時、S[0] と S[0] 自身の差分は以下のようになります。
0が{00, 01, 001}の語頭になっています。{00, 01, 001}から語頭の0を取り除くと{0, 1, 01}になります。
また、11も110の語頭になっています。110から語頭の11を取り除くと0になります。
差分である{0, 1, 01, 0}の中で、重複したものは取り除きます。よって、S[0] と S[0] 自身の差分は、{0, 1, 01}となり、S[1] = {0, 1, 01}になります。
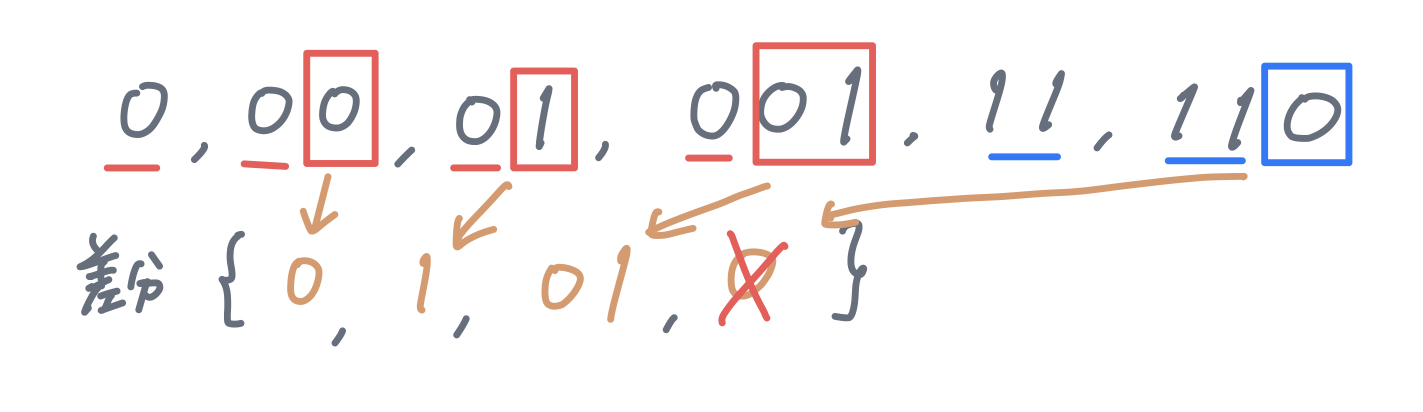
実践
では、実際に判別アルゴリズムを使って分節可能符号かどうか確かめてみましょう。
最初の例、{a, b, c, d} = {00, 10, 11, 110}を使ってみます。これは、分節可能符号でした。判別アルゴリズムを使って確かめると次のようになります。
S[0] = {00, 10, 11, 110}-
S[1] = {0}<-- S[0] と S[0] 自身の差分は{0}です。 -
S[2] = S[1] | S[0] と S[1] の差分={0} | {0}={0}
S[0] と S[1] の差分は{0}です。和集合(|)は{0}となります。
ここで、S[2] == S[1] になったので、繰り返しは終了です。
S[2] = {0}は、S[0] の要素に含まれていません。
よって、{a, b, c, d} = {00, 10, 11, 110}は分節可能符号であることが、判別アルゴリズムを使って確かめることができました。
Rubyで実装
前置きが長くなりましたが、いよいよRubyで実装していきます。
はじめ集合Setを使おうと思ったのですが、差分を考えなければいけない点でArrayを使うことにしました。もっといい書き方があるのではないかと思ってます...💦
2つの集合から差分を求めるメソッドを実装
毎回、2つの集合の差分を求めなければなりません。
1回目は S[0] と S[0] 自身、2回目は S[0] と S[1]、3回目は S[0] と S[2]...というように繰り返すので、メソッドにしました。
1つ目の集合を a、2つ目の集合を b とします。どちらも配列です。
また、差分の際に、00なども認識しなければならないので、要素は数値ではなく文字列です。
例) a = ["00", "10", "11", "110"]
def difference(a, b)
diff = Array.new # 差分をpushするArray
for i in 0...a.size
for j in 0...b.size
# 文字列のサイズが大きい方をmax, 小さい方をminとする
if a[i].size >= b[j].size
max = a[i]
min = b[j]
else
max = b[j]
min = a[i]
end
# 文字列maxの中に文字列minがあり、その始めの位置が0番目のとき
# count:文字列を右から数えるのでマイナス(1番左の文字=>max[-1])
# 左から1文字ずつ確認
# 文字列maxと、文字列minの同じ位置の文字が一致していたらcount+=1(countは右にずれていく)
# 文字列maxと文字列minが初めて等しくなくなったとき、
# maxのそれ以降の文字列をdiffにpush(minとの差異)
if max.index(min) == 0
count = -max.size
for k in 0...max.size
if max[k] == min[k]
count += 1
else
diff << max[count..-1]
end
end
end
end
end
# 差異が入った配列を返す(重複は除く)
return diff.uniq
end
内容はコメントアウトしている通りです。
わかりにくいですが、要素同士をすべて比べています。
要素は文字列なので、長さが大きい方をmaxとし、小さい方をminとします。なぜこの作業が必要かというと、そのあとにmax.index(min)をするからです。
たとえば00と0の差分を求めたいとします。実際の差分は0になります。
max == "00"、min == "0"とすると、max の中に min があると判定できるのでこれはOKです。
しかし、max と min が反対だと、max == "0"、min == "00"で、max.index(min)(0のなかに00はない)となり、差分がnilになってしまいます。
よって、大きい方のなかに小さい方があるかというようにしています。
if max.index(min) == 0は、一致する要素の始まりのインデックスが0であるかどうかの判断になります。インデックスが0だと、語頭が一致していることになり、そのあと一致しない部分があればそれが差分になります。
count変数は、文字列の右側から数えるようにしました。理由は、差分をmax[count..-1]と表したいからです。[-1]は文字列の一番右端を表します。countは最初、文字列の左端を示していて、maxとminの文字が等しければ1つ右にずれます。等しくなくなった地点から右端までが差分となるので、上のような記述になるわけです。
差分はdiffという配列に push していき、最後に重複を除いてから return します。
入出力とループ
では、差分を求める以外の部分を実装していきます。
まず標準入力で符号を受け取り、S[1] を求めます。その後、S[n] == S[n-1]になるまで繰り返します。
puts "間に半角スペースを入れて符号を入力してください"
ar = gets.chomp.split # 標準入力(S[0])
# 同じ符号が含まれていないか?
unless ar.uniq.size == ar.size
puts "正則な符号ではない。よって分節可能符号でもない"
exit
end
s1 = difference(ar, ar) # S[1]
s2 = Array.new
puts "S[1] = {#{s1.join(",")}}" # s[0]とs[0]自身の差分を出力(s[1])
count = 1
loop do
s2 = s1 | difference(ar, s1) # S[n] = S[n-1] | (S[0]とS[n-1]の差分)
count += 1
puts "S[#{count}] = {#{s2.join(",")}}" # s[n]を出力
s2 == s1 ? break : s1 = s2 # S[n] == S[n-1]でループ終了, 違ったらS[n-1]をS[n]にする
end
# ハッシュのキーを差分にする
# S[n](=s2)のキーがS[0](=ar)にも存在したらX
print "S[#{count}]はS[0]の要素に"
s2.tally.each do |key, value|
if ar.tally.key?(key)
puts "含まれるので、分節可能符号ではない。"
exit
end
end
puts "含まれないので、分節可能符号である。"
if s1.size == 0 && count == 2
puts "また、語頭符号でもある。"
end
正則な符号でないというのは、同じ符号が存在している符号ということです。
例)
{0, 0, 1, 1} => 正則な符号でない
{00, 0, 11, 1} => 正則な符号
語頭符号というのは、符号がほかの符号の語頭に1つもない符号のことです。
例)
{00, 01, 11, 100, 101} => 語頭符号
{00, 01, 11, 001, 011} => 語頭符号でない(001は00から始まる。また011は01から始まる)
入出力の例
以下の5パターンを試していきます。標準入力ではなく、ファイル入力やコマンドライン引数でファイルから入力など用途に合わせてコードも変えた方がいいと感じました。
(私の場合は、講義の課題でこの符号は分節可能符号か、といった問題が出るので標準入力にしました)
{0, 0, 1, 1}{0, 10, 110, 1110, 11110}{00, 01, 11, 001, 011}{1, 10, 100, 1000, 10000}{01, 11, 0110, 1011}
1.{0, 0, 1, 1}
$ 間に半角スペースを入れて符号を入力してください
$ 0 0 1 1
$ 正則な符号ではない。よって分節可能符号でもない
2.{0, 10, 110, 1110, 11110}
$ 間に半角スペースを入れて符号を入力してください
$ 0 10 110 1110 11110
$ S[1] = {}
$ S[2] = {}
$ S[2]はS[0]の要素に含まれないので、分節可能符号である。
$ また、語頭符号でもある。
3.{00, 01, 11, 001, 011}
$ 間に半角スペースを入れて符号を入力してください
$ 00 01 11 001 011
$ S[1] = {1}
$ S[2] = {1}
$ S[2]はS[0]の要素に含まれないので、分節可能符号である。
4.{1, 10, 100, 1000, 10000}
$ 間に半角スペースを入れて符号を入力してください
$ 1 10 100 1000 10000
$ S[1] = {0,00,000,0000}
$ S[2] = {0,00,000,0000}
$ S[2]はS[0]の要素に含まれないので、分節可能符号である。
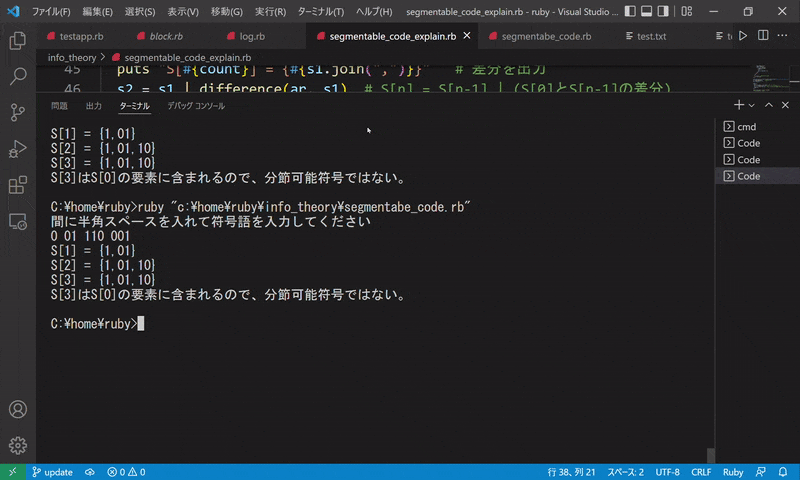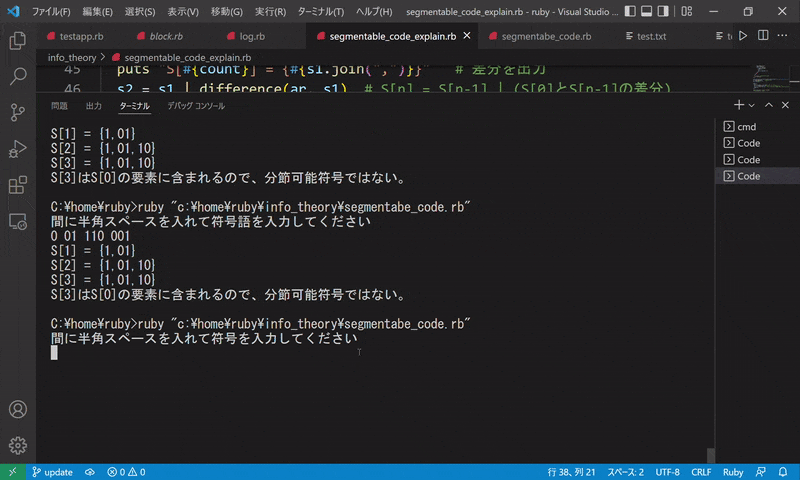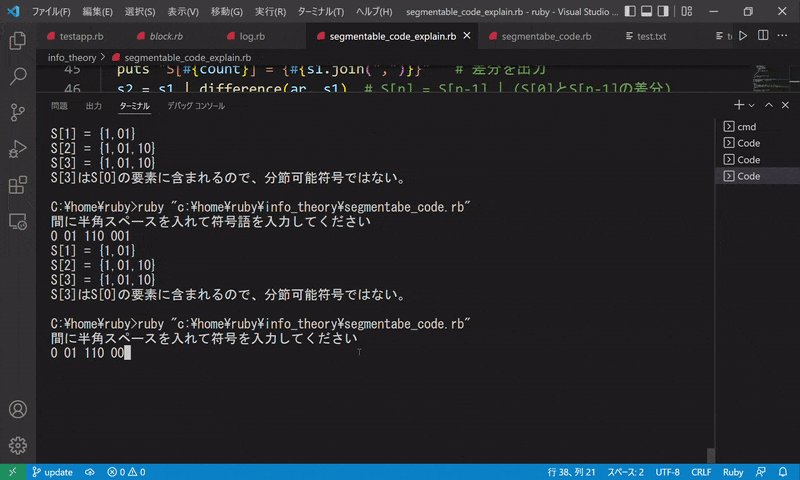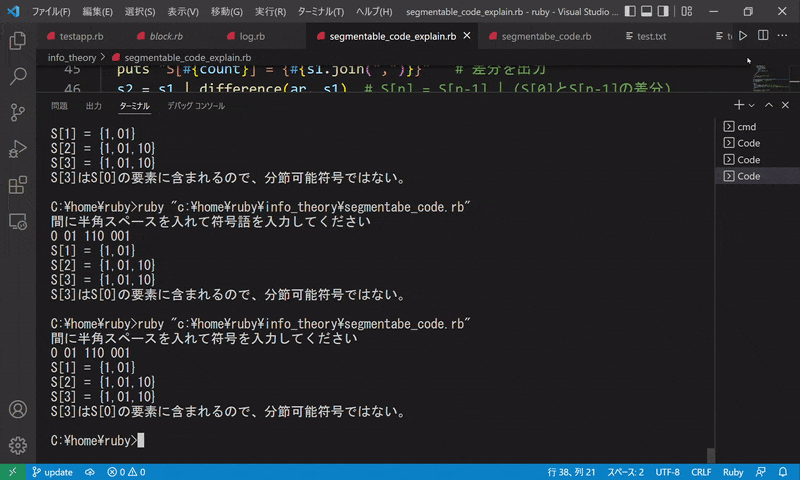
5.{01, 11, 0110, 1011}
$ 間に半角スペースを入れて符号を入力してください
$ 01 11 0110 1011
$ S[1] = {10}
$ S[2] = {10,11}
$ S[3] = {10,11}
$ S[3]はS[0]の要素に含まれるので、分節可能符号ではない。
ご指摘いただいたのでプログラムを見直してみた(5/30 追加)
変数の名前をmax => longer、min => shorterに変更しました。
また、S[0] に相当するarを分かりやすいように s0、S[n]に相当するs2もsnに変更しました。
| 変更前 | 変更後 |
|---|---|
max |
longer |
min |
shorter |
ar |
s0 |
s2 |
s0 |
配列の便利なメソッドについてもいくつか教えていただいたので、minmax_byとstart_with?を用いて冗長だった部分を直しました。
forループの部分はご指摘の前から自分でもtimesと迷っていたのですが、やっぱりtimesの方が見やすいか、ということで直しました。
そして、ジャッジの部分をメソッドにしてその結果から出力するというように変更しました。
以下、直したコードです。(今後もご指摘があればこちらに追記していきたいと思います。ご指摘ありがとうございます!)
def difference(a, b)
diff = Array.new
a.size.times do |i|
b.size.times do |j|
shorter, longer = [a[i], b[j]].minmax_by(&:length)
if longer.start_with?(shorter)
count = -longer.size
longer.size.times do |k|
if longer[k] == shorter[k]
count += 1
else
diff << longer[count..-1]
end
end
end
end
end
return diff.uniq
end
def judge(s0, s1, sn, count)
sn.tally.each do |key, value|
if s0.tally.key?(key)
return 0
end
end
return s1.size == 0 && count == 2 ? 1 : 2
end
puts "間に半角スペースを入れて符号を入力してください"
s0 = gets.chomp.split
unless s0.uniq.size == s0.size
puts "正則な符号ではない。よって分節可能符号でもない"
exit
end
s1 = difference(s0, s0)
sn = Array.new
puts "S[1] = {#{s1.join(",")}}"
count = 1
loop do
sn = s1 | difference(s0, s1)
count += 1
puts "S[#{count}] = {#{sn.join(",")}}"
sn == s1 ? break : s1 = sn
end
print "S[#{count}]はS[0]の要素に"
case judge(s0, s1, sn, count)
when 0
puts "含まれるので、分節可能符号ではない。"
when 1
puts "含まれないので、分節可能符号である。"
puts "また、語頭符号でもある。"
when 2
puts "含まれないので、分節可能符号である。"
end
さいごに
完成形
完成したものはこちらです。
符号を入力すると、S[n] を毎回出力し、最終的に分節可能符号であるかどうかを出力します。
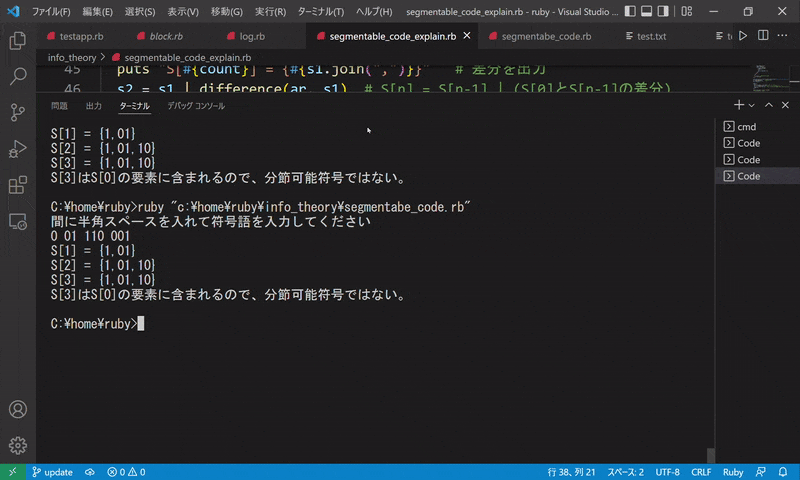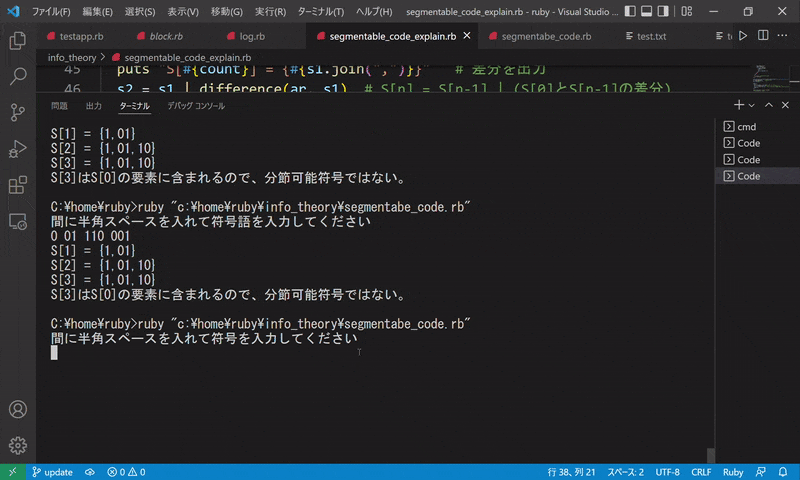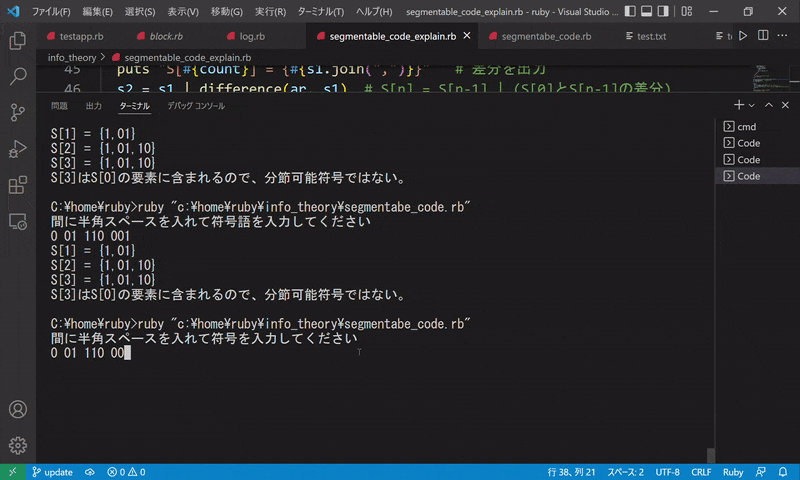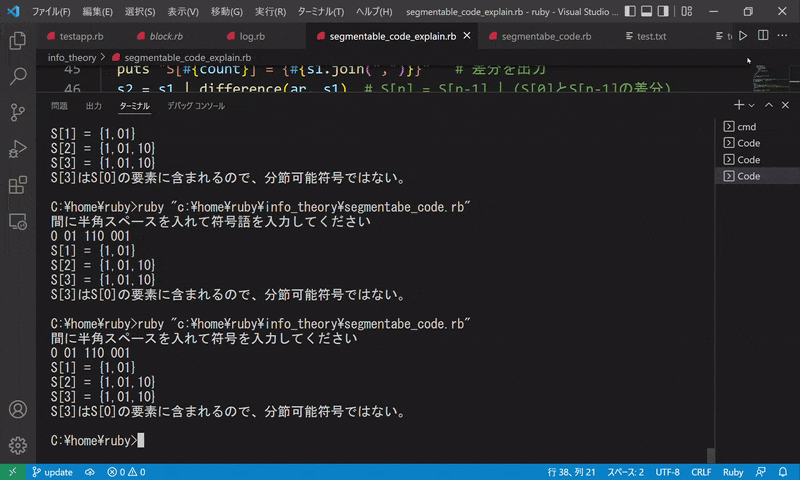
判別アルゴリズムがあっても、なかなか複雑なので自分でやるには少しネックです。プログラムに任せてしまうことですぐに判別できるようになりました。
あとからわかったのですが、講義の応用課題(やらなくていい)の部分で判別アルゴリズムを実装するという問題がありました(笑)
他にもっと簡単な実装方法があれば教えていただけると幸いです。
参考図書