ローカル LLM で画像を認識させたい
前回までは Docker, Conda を使わずに Open WebUI を使ってテキストでいろんな LLM とお話してみました。次は画像を認識できるローカル LLM モデルを使っていきたいと思います(視覚言語モデル:VLMと言うらしいです)。OCRのようにイメージファイルを読み込んでから文字を読み取ったり数式やグラフなどを理解して回答してくれるようになります。モデルは Qwen2-VL を使ってみます。
Open WebUI + vLLM を使ってモデルを使ってみる
Open WebUI で Qwen2-VL のモデルを使う方法として今回は vLLM を使用してみます。
今のところこの vLLM は Windows に対応していないため MacOS / Linux で動かす必要があるのですが、Windows 11 の WSL2 を有効にして WSL + Ubuntu の中で動作させるというやり方で動かそうと思います。
※WSL2 のセットアップを終わらせて Ubuntu のセットアップを完了している前提になります(ごめんなさい)。
vLLM Requirements
OS: Linux
Python: 3.8 – 3.12
・新規 conda 作成が推奨ですよ
・python 3.10 + CUDA 12.1 が今のデフォルト
・インストールは pip を使ってくださいね、Pytorch が必要になりますよ
・開発したい場合はフルビルドが必要な環境がありますよ、その場合リソースに注意してね
と書いてありますね。
今回は conda は使用しない、CUDA12.1(GPU有)、フルビルド無し通常インストールの方でやりますね。
Qwen2-VL Requirements
Python のバージョンは特に記載がないので python 3.11 を使っていきましょ
vLLM での Qwen2-VL 使い方もここに記載があります。OpenAI 互換 API サービスを使っている場合の注意事項や制限事項もあるのでコーヒーでも飲みながらチェックしてみてくださいね
WSL2 + Ubuntu 環境の確認
Windows の Powershell で環境をチェックしていきます。
nVidia のドライバの確認
PS> nvidia-smi
| NVIDIA-SMI 555.85 Driver Version: 555.85 CUDA Version: 12.5 |
新しいドライバが入っていますね。
WSL の確認
PS>wsl --version
WSL バージョン: 2.3.24.0
PS>wsl --list --verbose
NAME STATE VERSION
* Ubuntu Running 2
docker-desktop Running 2
PS>wsl --status
既定のディストリビューション: Ubuntu
Ubuntu が稼働中なことを確認できました。
Ubuntu にログインしていきます。
Ubuntu の確認
PS>wsl --distribution Ubuntu
user@localhost:~$cat /etc/lsb-release
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=24.04
DISTRIB_CODENAME=noble
DISTRIB_DESCRIPTION="Ubuntu 24.04.1 LTS"
Ubuntu 24.0 ですね。
CUDA Toolkit の確認
user@localhost:~$ nvcc --version
Build cuda_12.1.r12.1
CUDA toolkit のバージョンは12.1ですね。
Python の確認
user@localhost:~$ python -V
Python 3.11.10
システムには python 3.11.10 がインストールされていますね。
Qwen2-VL + vLLM の環境構築
環境が整っていればすぐに終わりますが新規構築の場合は Pytorch やモデルをダウンロードしないといけないので数時間以上かかります。
pyenv + venv 環境を作成
我が家ではpyenv + venv 環境を使用していますが使わない方はスキップしてくださいね。
user@localhost:~$ pyenv versions
system
* 3.11.10 (set by )
user@localhost:~$ python -m venv .venv01
cd .venv01
source bin/activate
Qwen2-VL + vLLM のセットアップ
Qwen2-VL の説明ページに書いてある通りに実行していきますね。
Deployment
We recommend using vLLM for fast Qwen2-VL deployment and inference. You need to use vllm>=0.6.1 to enable Qwen2-VL support. You can also use our official docker image.
pip install git+https://github.com/huggingface/transformers@21fac7abba2a37fae86106f87fcf9974fd1e3830
pip install accelerate
pip install qwen-vl-utils
最後のところは CUDA toolkit は 12.1 なので、
pip install 'vllm==0.6.1' --extra-index-url https://download.pytorch.org/whl/cu121
以上で完了です。
Qwen2-VL-2B-Instruct の起動と確認
動作確認のために説明ページを参考に小さなモデルで実行していますデフォルトではポート8000番で動作するようです。
python -m vllm.entrypoints.openai.api_server --served-model-name Qwen2-VL-2B-Instruct --model Qwen/Qwen2-VL-2B-Instruct
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
ものすごい勢いでVRAMの使用量が上がっていきますね。
めげずにブラウザで http://localhost:8000 にアクセスします。
[ "detail": "Not Found" ]
の文字が表示されたらOKです。
参考:VRAMの使用量
起動時に特に指定しないとデフォルトのモデルパラメータをフルでVRAMを使用します。メモリが足りないと以下のようなエラーになります。vllm のパラメータを参考に調整しましょう。モデル側を制限するパラメータ --max_model_len が必要になります。
ValueError: The model's max seq len (32768) is larger than the maximum number of tokens that can be stored in KV cache (4224). Try increasing `gpu_memory_utilization` or decreasing `max_model_len` when initializing the engine.
参考までにうちでは下記のような使い方になります。
python -m vllm.entrypoints.openai.api_server --served-model-name Qwen2-VL-2B-Instruct --model Qwen/Qwen2-VL-2B-Instruct --max_model_len 2048 --cpu-offload-gb 0 --gpu-memory-utilization 0.5
Open WebUI で vLLM を設定
Open WebUI を起動させましょう。
open-webui serve --host 0.0.0.0 --port 8080
Open WebUI の画面の左下のアイコンから 「設定」-->「 管理者画面」 を表示させて、「接続」を表示させると「OpenAI API」という項目があります。この右側のプラスを押して入力行を追加します。URLに [http://localhost/8000/v1] keyに [vllm] を入力して右下の「保存」ボタンを押しましょう。(keyは何を入力してもいいです)
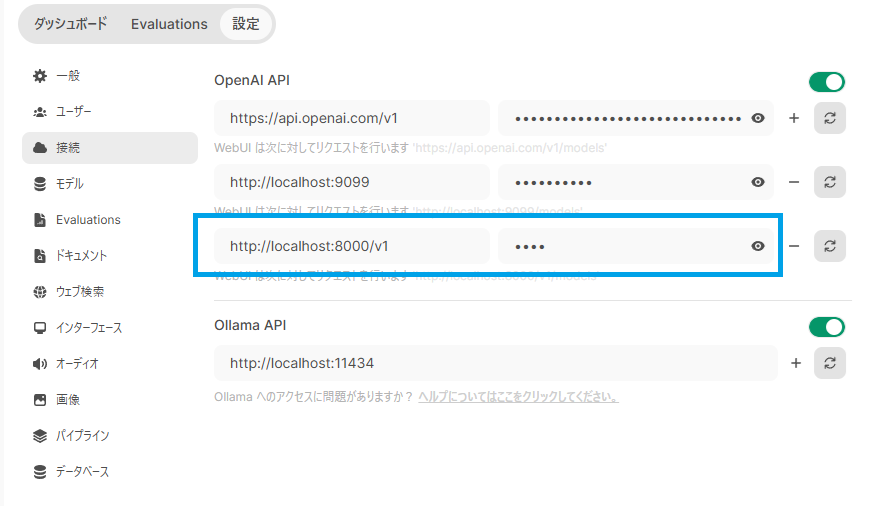
保存ボタンを押すと接続が開始されます。接続が切れていると表示されないためその場合は右側のリロードボタンを押すと再接続されます。
Key の入力に間違いがなければワークスペースにモデルが表示されます。
Qwen2-VL-2B-Instruct さんにあいさつしてみた

航空会社や機種まで認識するんですね、ちょっとおどろきました。
動画についてはまだvLLM経由だと使えないようですね。
⚠️NOTE: Now vllm.entrypoints.openai.api_server does not support video input yet. We are actively developing on it.
それではみなさんも快適な ローカルLLM ライフをお楽しみください!