今までEDAはpandas-profilingを使っていたのですが、Sweetvizなるものをたまに見かけるので試してみました。
データはTitanicデータを使用しました。
目次
1. EDAとは
EDAとは**Explanatory Data Analysis(探索的データ解析)**の略です。
機械学習などのデータ分析業務を実施する際、データの理解を目的として以下のような作業を行います。
- データの可視化
- データの特徴の把握
- データ間の関係性の把握
EDAについての詳細は調べればたくさん出てくるので本記事では省略します。
以下の記事等をご参考ください。
・【データサイエンティスト入門編】探索的データ解析(EDA)の基礎操作をPythonを使ってやってみよう
・EDA (Exploratory Data Analysis)ってなんだろう?
・探索的データ解析(EDA)
2. Sweetviz実行例
SweetvizはEDAを実施する際に行う様々な作業を半自動で実施できるライブラリです。
早速、Titanicデータでの実行例を紹介します。
実行後、上記のようなhtmlが作成されます。
中身について、3つに分けて見ていきます。
① 全体概要と相関係数
①の部分では、データ全体の特徴と相関係数が確認できます。
全体にも言えることですが、Sweetvizの大きなメリットとして、学習データと推論データを分けて見られることが挙げられます。
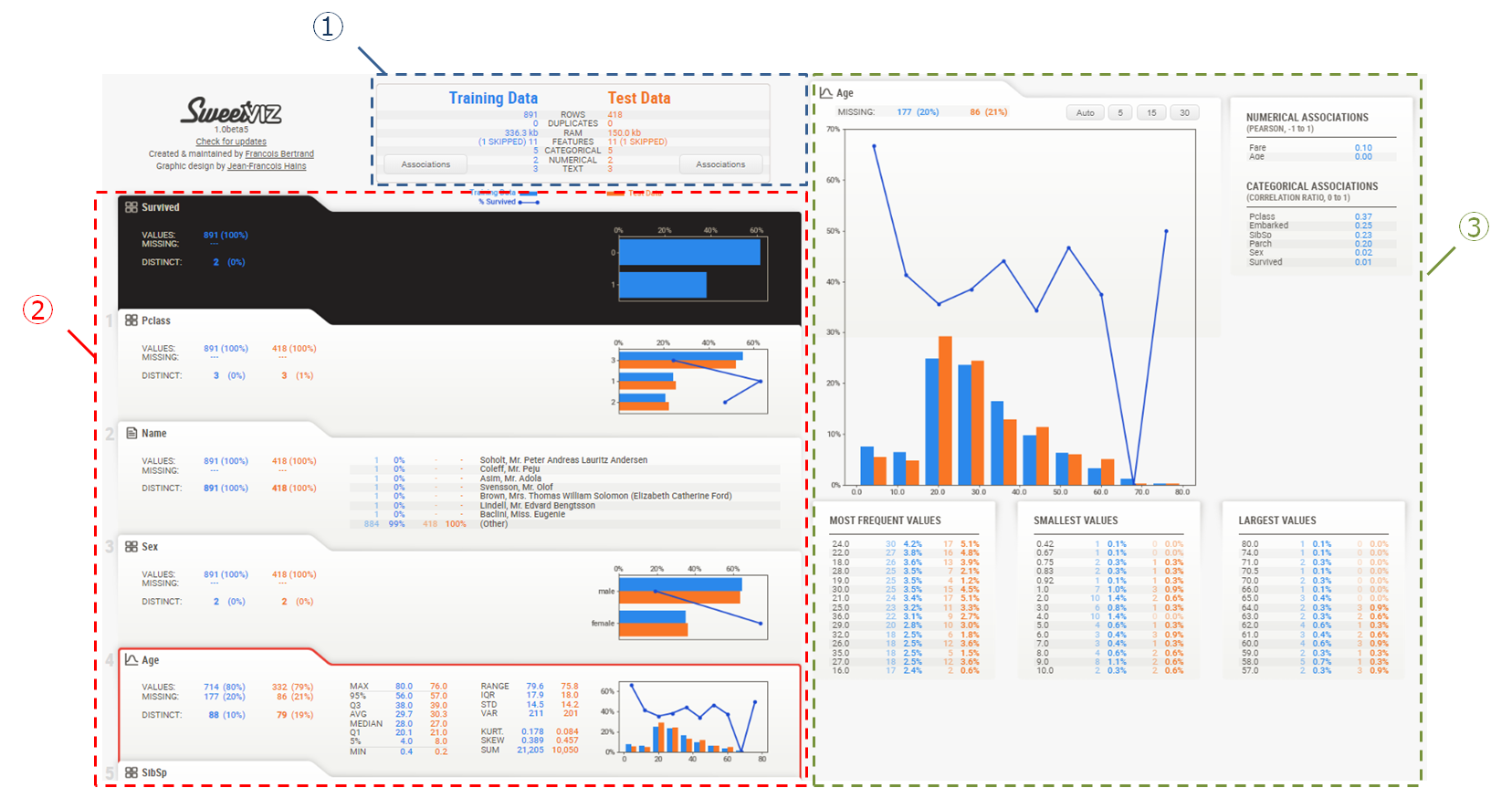
図の部分では学習データと推論データそれぞれに対して
以下の内容を確認することができます。
- 行数
- 重複有無
- メモリ使用量
- 特徴量の数(1 SKIPPEDというのは実行時に「PassengerID」列をSkipする設定にしているから表示されています。)
- カテゴリ列の数
- 数値列の数
- テキスト列の数
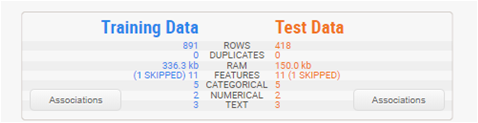
また、Associationsボタンを押すことで相関係数を確認することができます。
上記は学習データでの例ですが、推論データでも同様に確認できるので、
学習データと推論データの相関係数の差を見て分布に差があるかどうかの当たり付けをしてもいいかもしれません。
② 各特徴量の概要
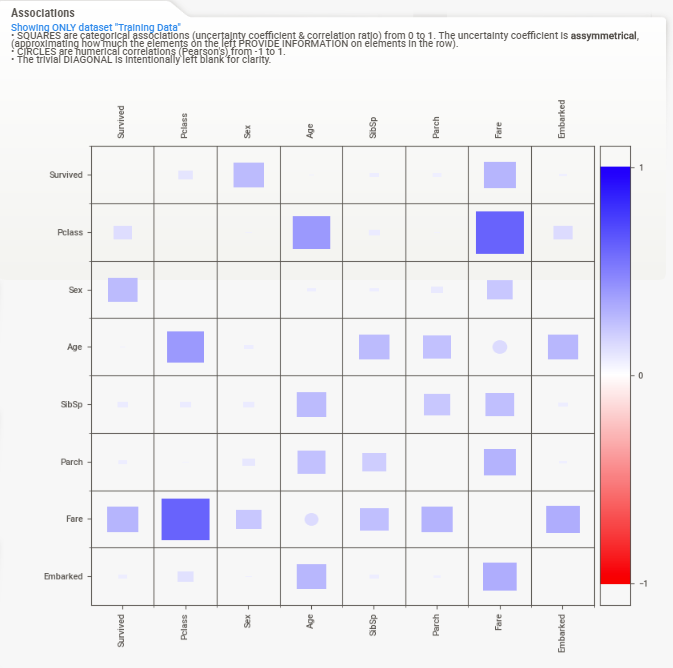
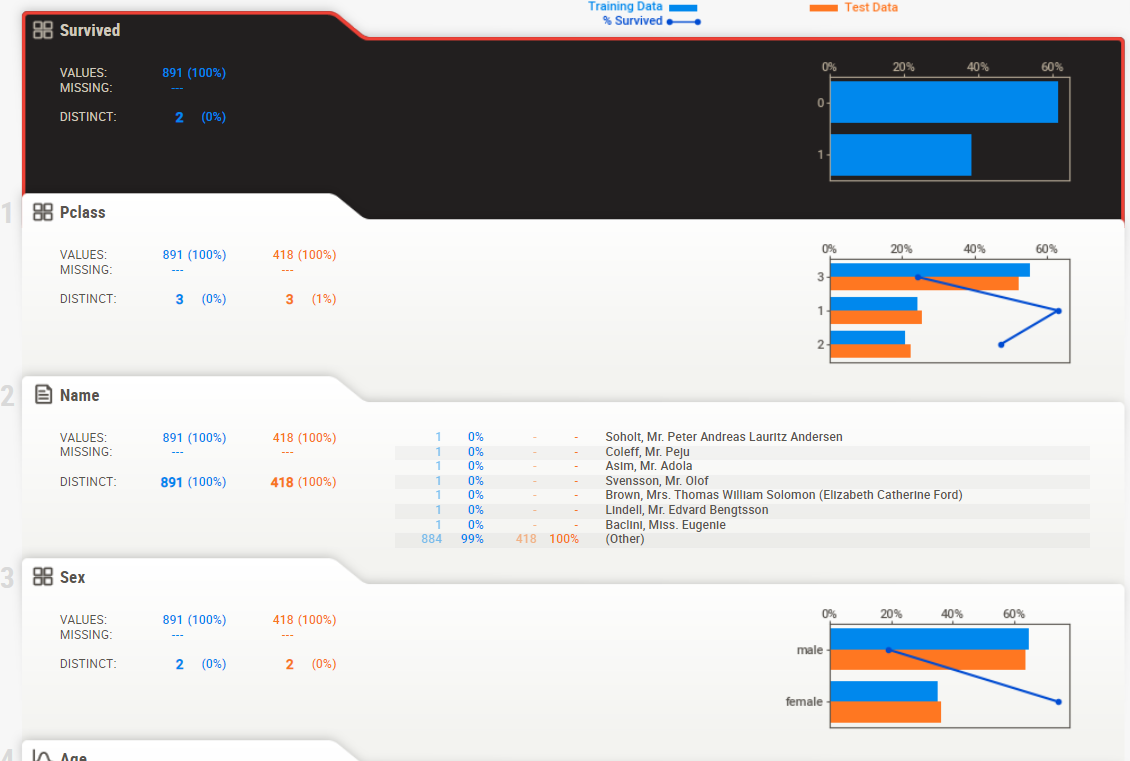
②の部分では大きく以下のことを確認できます
- 目的変数(Survived)の分布
- 説明変数の分布
- 陽性率(目的変数が1である割合)
- 上記3つの学習データと推論データの比較
分布が見られるのは当たり前なのですが、
**「陽性率」や「学習データと推論データの比較」**が見られるのは非常に便利に感じます。
これらを見ることで
- AIによる予測精度が概ねどの程度出そうか
- 学習データと推論データのデータ取得方法や件数に問題がなさそうか
(時期やユーザ等が異なるケースが多いと思われるが、分布がある程度似ていればデータ取得フローに問題なしと判断できる) - 陽性率の高い説明変数の値は何か
など、AIアルゴリズムを実装して予測精度やLIME/SHAPなどの説明性を算出するより前に、かなり多くのことを事前に予想することが可能です。
事前に予想ができていれば、AIの結果を盲目的に信じることもなく、また結果の考察もしやすくなります。
③ 各特徴量の詳細
③の部分では、各特徴量についてもう少し細かい情報を確認することができます。
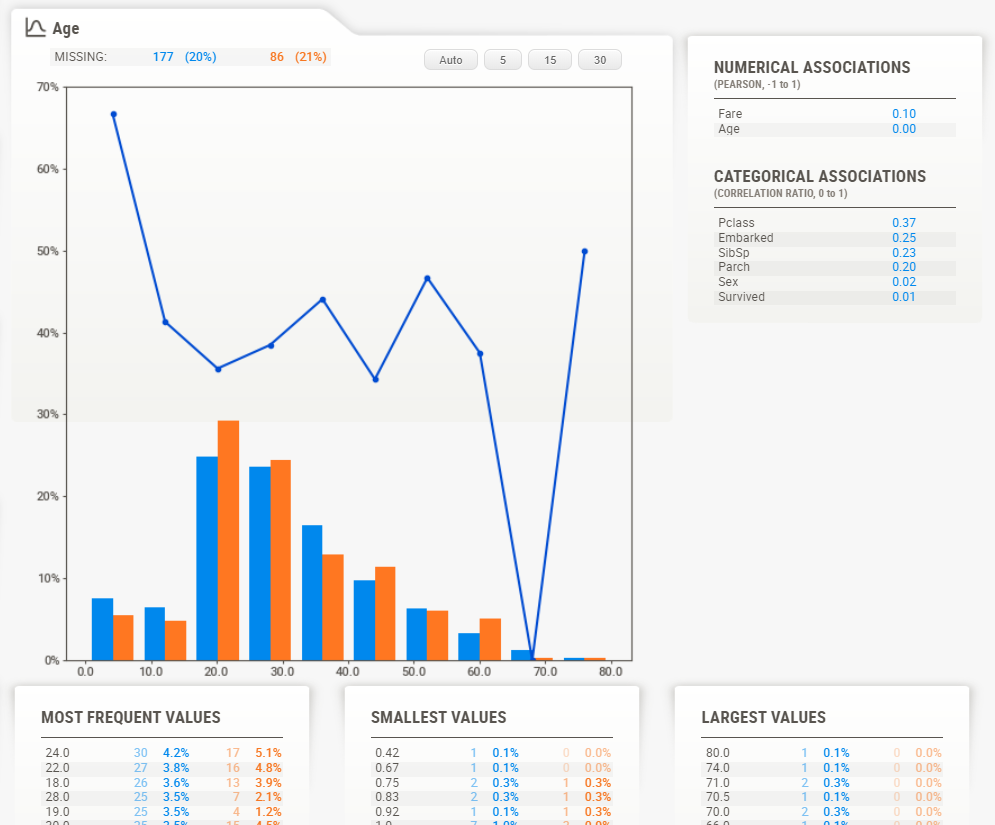
例えば、②の情報に加えて以下のような内容が表示されます。
- 欠損率
- 相関係数の高い特徴量
- 頻度の高い値リスト
- 値の大きい順(小さい順)のリスト
ここは普通といえば普通です。
値の大きい順(小さい順)のリストはpandas-profilingでは上位5件しか見れないので、もう少し見たい場合や外れ値が5件以上ある場合はSweetvizが有効です。
ただ、結局②でも表示されていた
- 陽性率(目的変数が1である割合)
- 学習データと推論データの比較
がSweetvizを使用するメリットのように思えます。
実装例
以下のgitにコードとSweetvizが出力したhtmlが置いてあります。
html見てみるだけでもいいですし、コード動かすのもだいぶ簡単です。
https://github.com/yuomori0127/sweetviz_titanic
公式は以下です。
Sweetviz
3. pandas-profiling実行例
同じEDAのためのライブラリであるpandas-profilingも見ていきます。
pandas-profilingのTitanic実装例はcolab上のものが公開されています。
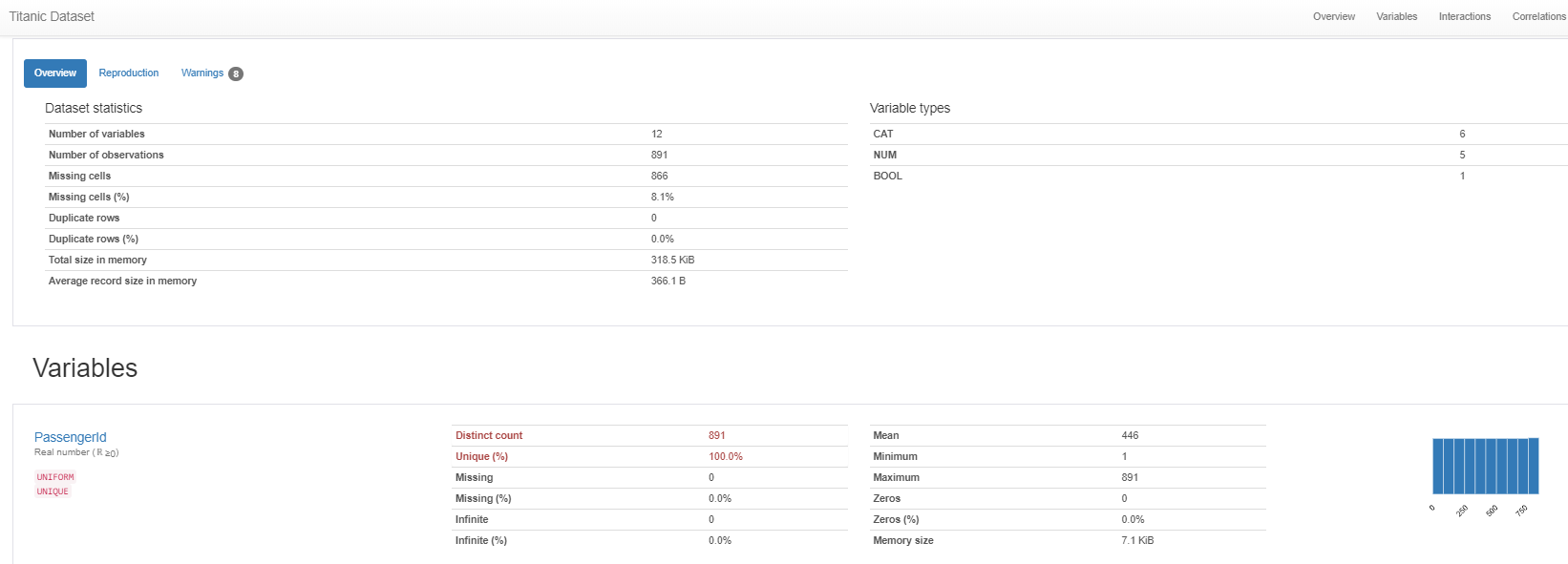
データ入れるだけでこれを出してくれるので、これでも十分すぎると思います。
というか私もかなり使ってました。
Sweetvizにはない、pandas-profilingのメリットは
データの前処理をする上で削除すべき説明変数を提案してくれるという点です。
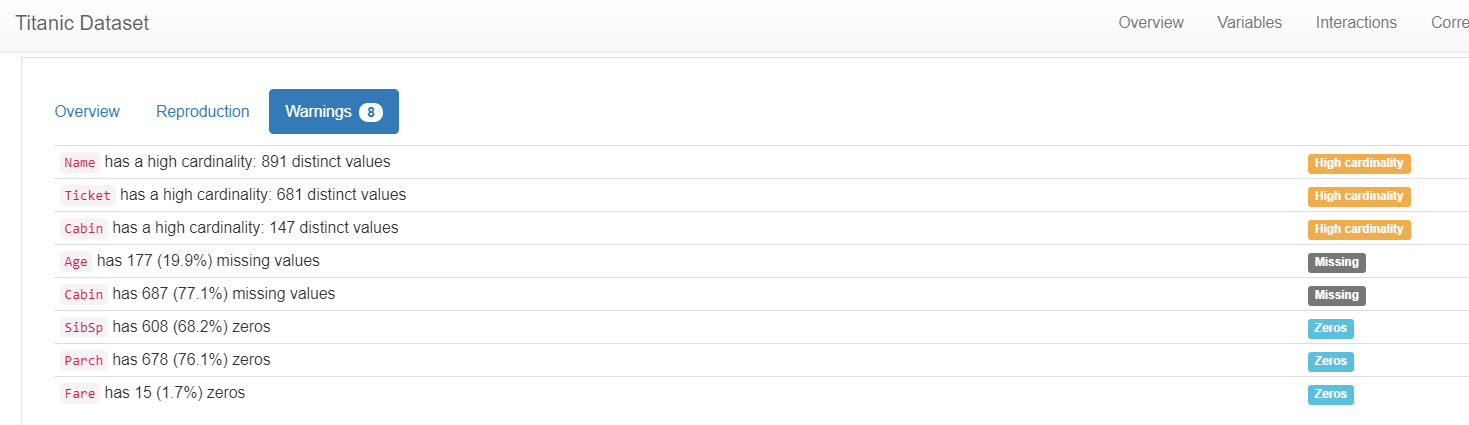
図のように、
- カーディナリティ(値の種類数)が多い
- 欠損値が多い
- ゼロが多い
- 相関係数が高い
など、データの前処理をする上で削除すべき説明変数を提案してくれます。
いちいち図や分布を見て自分で閾値を引いて判断しなくても、これらを提案してくれるのはSweetvizにはない非常に便利な機能です。
公式は以下になります。
pandas-profiling
4. Sweetvizとpandas-profilingの比較
Sweetvizとpandas-profilingの比較表を作成しました。
EDAで行う基本的な機能は両方備えていますが、
細かい点は少し異なってきます。
また、機能を全部挙げることはできないのでかなり抜粋しています。
| # | 比較項目 | Sweetviz | pandas-profiling |
|---|---|---|---|
| 1 | 分布の表示 | 〇 | 〇 |
| 2 | 基本統計量の表示 | 〇 | 〇 |
| 3 | 欠損率の表示 | 〇 | 〇 |
| 4 | 相関係数の表示 | 〇 | 〇 |
| 5 | 頻度順のデータ表示 | 〇 | 〇 |
| 6 | 値の大小順のデータ表示 | 〇 | △(5件のみ) |
| 7 | 陽性率の表示 | 〇 | × |
| 8 | 学習データと推論データの比較 | 〇 | × |
| 9 | 削除すべき説明変数を提案 | × | 〇 |
5. どっちを使えばいいの?
個人的にはSweetviz推しです。
やはり**「陽性率の表示」や「学習データと推論データの比較」は非常に便利です。
pandas-profilingのメリットである「削除すべき説明変数の提案」**ですが、
もちろん素晴らしい機能ではあるのですが、提案通りに実行して結局データを見ない、考えないのはあり得ないですし、提案内容が妥当かもわからないので結局参考にしないです。ただ、見落としを防げる可能性があるのはありがたいです。
優劣をつけるのは難しいところではありますが、どちらも簡単に動かせるものなので是非両方試してみて、ご自身に合う方を使ってみてください!