先日、Twitterで「PyCaretという無料Data○obotのようなライブラリが出たらしい!」
というツイートをみかけたので、試しにKaggleのHouse Pricesをテーマに実装してみました。
目次
1. PyCaretとは
PyCaretは、low-codeで機械学習に関する様々なタスクを実行できるオープンソースのライブラリです。
データ分析者が各々の知識と経験を元に行うような、データ前処理・機械学習モデル構築・モデル評価などのタスクを数行のコードで実行することができます。
しかも超基本的なことだけでなく、Kaggleのようなコンペティションでよく用いられる新しめの機械学習アルゴリズムやいくつかのアンサンブル手法も簡単に実行することができます。
また、分類や回帰だけでなく、クラスタリングや異常検知、自然言語処理(2020/04/29時点ではトピックモデルのみ)も扱えます。
詳細は、公式サイトをご確認ください。
https://pycaret.org/about/
2. House Pricesをやってみる
Kaggleの説明や、House Pricesの説明、コンペの参加方法などはネット上に無数に記事がありますので省略させてください。
House Pricesのサイトだけ載せておきます。
https://www.kaggle.com/c/house-prices-advanced-regression-techniques/overview
2-1. データ前処理
まずはデータを読み込み、簡単なEDA(Explanatory Data Analysis:探索的データ分析)、前処理をPyCaretを使って行います!
と言いたいところですが、PyCaret使いませんでした。。
簡単な部分はPyCaret使わなくても1行で書けますし、少し複雑になるとPyCaretでは出来ないからです。
ということで、本記事の目的から逸れるので簡単な説明とコードだけサクッと載せます。
KaggleのNotebookにコピペすればそのまま実行できるはずですので、ご自身の手で動かしてみたい方は是非!
PyCaretのインストール
! pip install pycaret
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import pycaret
from pycaret.regression import *
データ読み込み
train_df = pd.read_csv('../input/house-prices-advanced-regression-techniques/train.csv')
test_df = pd.read_csv('../input/house-prices-advanced-regression-techniques/test.csv')
さすがにdescribeぐらいはやっておく
pd.options.display.max_columns = None # Show all cols
train_df.describe()
目的変数の分布をみる
sns.distplot(train_df['SalePrice'])
plt.ylabel('Frequency')
plt.title('SalePrice distribution')
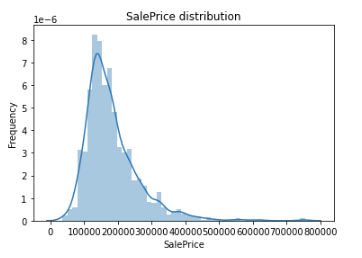
コンペの評価指標が**「目的変数の対数のRMSE」**なので、対数を取る
# 評価指標に合わせるためにlogを取る
# https://www.kaggle.com/c/house-prices-advanced-regression-techniques/overview/evaluation
train_df["SalePrice"] = np.log1p(train_df["SalePrice"])
対数を取った後に再度可視化
sns.distplot(train_df['SalePrice'])
plt.ylabel('Frequency')
plt.title('SalePrice distribution')
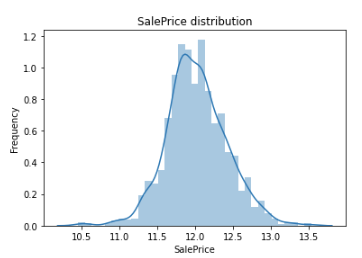
正規分布っぽくなりました。
Id列削除
train_df.drop("Id", axis = 1, inplace = True)
test_df.drop("Id", axis = 1, inplace = True)
欠損値補完。PyCaret使わなくても1行で出来る。
train_df["PoolQC"] = train_df["PoolQC"].fillna("None")
test_df["PoolQC"] = test_df["PoolQC"].fillna("None")
新しい特徴量の作成
train_df['TotalSF'] = train_df['TotalBsmtSF'] + train_df['1stFlrSF'] + train_df['2ndFlrSF']
test_df['TotalSF'] = test_df['TotalBsmtSF'] + test_df['1stFlrSF'] + test_df['2ndFlrSF']
trainデータをベースとした、カテゴリデータのダミー変数への変換。
こんなことはPyCaretでは出来ない気がします。(もしできたらゴメンナサイ)
def fix_missing_cols(in_train, in_test):
missing_cols = set(in_train.columns) - set(in_test.columns)
for c in missing_cols:
in_test[c] = 0
in_test = in_test[in_train.columns]
return in_test
def dummy_encode(in_df_train, in_df_test):
df_train = in_df_train
df_test = in_df_test
categorical_feats = [
f for f in df_train.columns if df_train[f].dtype == 'object'
]
print(categorical_feats)
for f_ in categorical_feats:
prefix = f_
df_train = pd.concat([df_train, pd.get_dummies(df_train[f_], prefix=prefix)], axis=1).drop(f_, axis=1)
df_test = pd.concat([df_test, pd.get_dummies(df_test[f_], prefix=prefix)], axis=1).drop(f_, axis=1)
df_test = fix_missing_cols(df_train, df_test)
return df_train, df_test
目的変数がget_dummiesされるのを防ぐため、先に抜いておく
y_train = train_df["SalePrice"]
train_df = train_df.drop("SalePrice", axis=1)
上で定義した関数の実行
train_df, test_df = dummy_encode(train_df, test_df)
目的変数をくっつける
train_df = pd.concat([train_df,y_train],axis=1)
最後にshapeを確認
train_df.shape,test_df.shape
以上で前処理は終了です。
次からはPyCaretしっかり使っていきます!
2-2. 機械学習アルゴリズム構築
今回は、コンペで良く用いられる、**[XGBoost, LightGBM, CatBoost, 3手法のアンサンブル]**の4つの精度(RMSE)を算出してみたいと思います。
以下の表が埋まるイメージです。
| XGBoost | LightGBM | CatBoost | 3手法のアンサンブル |
|---|---|---|---|
| xx.xx | xx.xx | xx.xx | xx.xx |
Data○obotのように10個20個モデル作成を行うこともできるのですが、
時間の節約のため、上記3つ+アンサンブルの4つで行きたいと思います。
沢山のモデルを作成する方もコードは記載しておきます。
まずは、train,testのsplitを行います。
https://pycaret.org/train-test-split/
exp1 = setup(train_df, target = 'SalePrice', train_size = 0.99)
※一番下の空欄のテキストボックスでEnterを押さないと次に進みません!!
1行で両方実行出来ちゃいます。
ただ、Kaggle特有の謎の行為をしなければなりません。
train_size = 0.99
です。
Kaggleは元々trainとtestが分かれているので、train,testのsplitをする必要がありません。
ただ、setupコマンド自体は実行する必要があり、train_size = 1.0としてみるとエラーとなります。
なので、仕方なくtrain_size = 0.99としています。
※上手い回避策があれば教えてくださいませ。。
次に、Data○obotのように何十個もモデルを作成したい場合は、以下を実行します。
ただ、時間が結構かかります。
https://pycaret.org/compare-models/
compare_models()
モデルを指定する場合は、以下を実行します。
XGBoostの例です。これは数分です。
https://pycaret.org/regression/
tuned_xgboost = tune_model('xgboost',n_iter=100,optimize='mse')
これとは別に xgboost = create_model('xgboost') ともできるのですが、
これはoptimizerが指定できないので少なくともコンペでは使いものになりません。
また、tune_modelを行う場合は必ずn_iterを指定してください。
デフォルト値が10なのでこれもまた使いものになりません。
ちなみに、optimizeがコンペの評価指標であるrmseではなくmseなのは、rmseが未実装だからです。
この何とも手が届かない感じ。。
ちなみに、実行結果は以下のようになります。
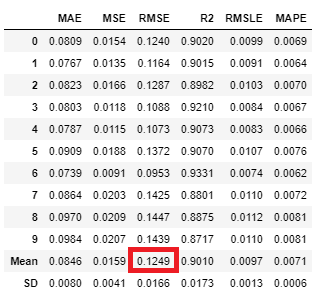
fold10でのRMSEの平均が 0.1249 でした。
表を更新します。
| XGBoost | LightGBM | CatBoost | 3手法のアンサンブル |
|---|---|---|---|
| 0.1249 | xx.xx | xx.xx | xx.xx |
同様に、LightGBMもモデルを作成していきます。
tuned_lightgbm = tune_model('lightgbm',n_iter=1000,optimize='mse')
LightGBMは早いのでn_iter=1000 にしてみました。
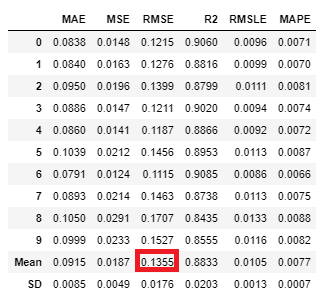
XGBoostの方が精度高いですね。
| XGBoost | LightGBM | CatBoost | 3手法のアンサンブル |
|---|---|---|---|
| 0.1249 | 0.1355 | xx.xx | xx.xx |
CatBoostも実行します。
tuned_catboost = tune_model('catboost',n_iter=100,optimize='mse')
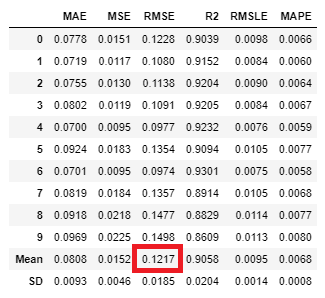
| XGBoost | LightGBM | CatBoost | 3手法のアンサンブル |
|---|---|---|---|
| 0.1249 | 0.1355 | 0.1217 | xx.xx |
3つの中ではCatBoostが一番精度が高いですね。
次は、3つのアンサンブルを実行します。
https://pycaret.org/blend-models/
tuned_blender = blend_models (estimator_list = [ tuned_xgboost,tuned_lightgbm,tuned_catboost] )
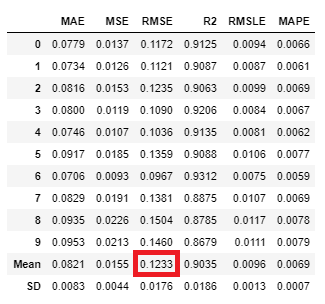
| XGBoost | LightGBM | CatBoost | 3手法のアンサンブル |
|---|---|---|---|
| 0.1249 | 0.1355 | 0.1217 | 0.1233 |
CatBoostシングルに負けてしまいました。
ちなみに、blend_models は各モデルの出力の平均値を取るらしく、
モデルごとに重みを付けることはできません。
https://pycaret.org/regression/
ちなみに、似たような名前でensemble-model というものも存在します。
これは作成した1モデルをバギングまたはブースティングするものです。
公式サイトの例では決定木を作成し、それをブースティングしていますが、
そんなことするなら初めからXGBoostでええやん、と思ったり。。
あまり使い道はないように思えます。
https://pycaret.org/ensemble-model/
次に全学習データで学習しなおします。
TrustCV という言葉もありますし、CatBoostを最終的なモデルとします。
final_model = finalize_model(tuned_catboost)
テストデータの予測値を算出します。
predictions = predict_model(final_model, data = test_df)
submissionできる形式に変更します。
今回、対数を取ってから機械学習にかけているので、それを戻す処理も行います。
sub_df = pd.read_csv('../input/house-prices-advanced-regression-techniques/sample_submission.csv')
sub_df['SalePrice'] = np.expm1(predictions['Label'])
sub_df.to_csv('submission.csv',index=False)
submitするデータはこんな感じです。
sub_df.head()
submit結果!
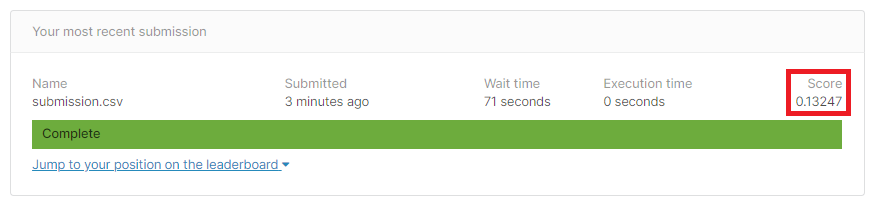
0.13247でした。
同じ前処理で、LightGBMのパラメータをいくつかGRIDSearchしたものが0.12948だったので少し負けてしまいました。恐らくoptimizeにRMSEが指定できないのが原因なのではないかと思っています。
3. 最後に
PyCaret使ってみましたが、個人的にはあまり使いどころが見当たりませんでした。
色々細かいことができないので私は手で作っちゃいます。
完全な初心者が使うにしても、何が何やらわからず、
学習題材にもならない気がしています。
逆に、AIを使った業務をまずは回したい、精度は後回し、アルゴリズムの理解も不要、という場合は良いかもしれません。
また、現時点(2020/04/29)でファーストリリースなので、これから使い勝手が良くなったり、精度が良くなったりしていくと思います。そしたらまた使ってみようと思います!