#Pythonで学ぶアルゴリズム< 二分探索 >
はじめに
基本的なアルゴリズムをPythonで実装し,アルゴリズムの理解を深める.
その第10弾として二分探索を扱う.
二分探索
中央値など,ある値を見たときに,その値がそれよりも前か後ろかを判断する.
・探索範囲が半分(二分割)ずつ狭まっていく ⇒ 高速化
※注意
データが五十音順など規則的に並んでいる必要がある
場合によって事前にデータの並び替えが必要となることもある
線形探索との違い
オーダーを示すと,次のようになる.
線形探索:$O(n)$
二分探索:$O(log_2n)$
より直感的に理解するためにその関係をグラフに示す.
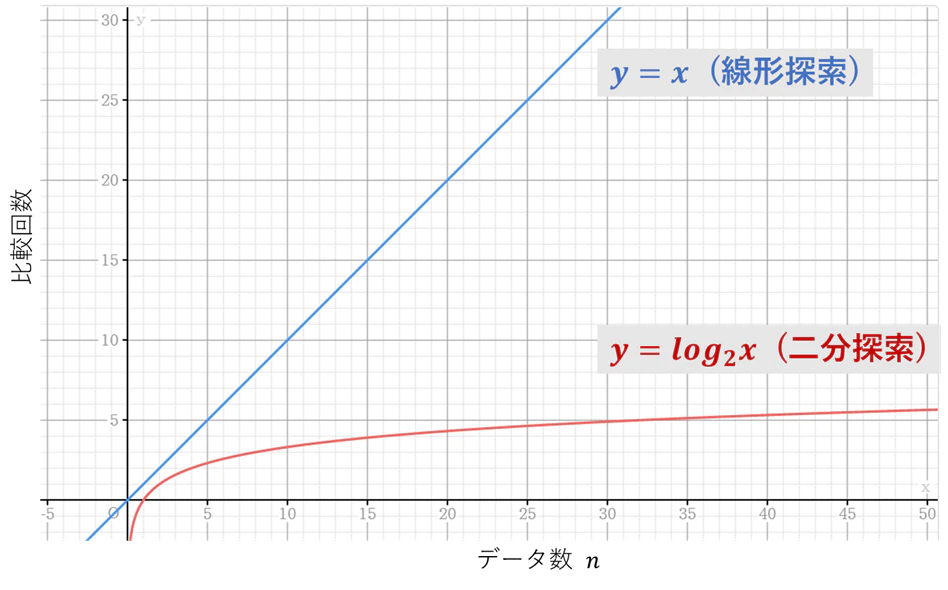
例えば,データが1000個,100万個あったとすると,線形探索では1000回,100万回の比較が必要だが,二分探索では10回,20回の比較だけでよくなる.
規則正しくデータが並べられている必要があるという制約はあるものの,データが多くなった時には,二分探索が有効であることが分かる.ただし,データが少ない時には,速度に大きな差はないため,データの並びに関係ない線形探索が用いられることも少なくない.
実装
二分探索について2つの実装をする.1つ目は規則正しく並べれられたデータが与えられた場合,2つ目はソート可能であるが,不規則に並べられ並び替えの処理が必要な場合を想定している.以下にコードとその出力を示す.
コード1
"""
2020/12/22
@Yuya Shimizu
二分探索
"""
def binary_search(data, target):
left = 0 #探索する範囲の左端を設定
right = len(data) - 1 #探索する範囲の右端を設定
while left <= right:
mid = (left + right) // 2 #探索する範囲の中央値
if data[mid] == target:
return mid #中央値と一致した場合はその位置を返す
elif data[mid] < target:
left = mid + 1 #中央値よりも大きい場合は探索範囲の左端を変える
else:
right = mid - 1 #中央値よりも小さい場合は探索範囲の右端を変える
return False
if __name__ == '__main__':
data = [10, 20, 30, 40, 50, 60, 70, 80, 90]
target = 5
found = binary_search(data, target)
if not found:
print(f"{target} is not found in the data")
else:
print(f"{target} is found at data[{found}]")
出力(データが見つかったとき)
50 is found at data[4]
出力(データが見つらなかったとき)
5 is not found in the data
コード2
"""
2020/12/22
@Yuya Shimizu
二分探索
"""
def binary_search(data, target):
data_sorted = sorted(data) #データを昇順に並び替え sorted(data, reverse=True)とすれば降順にできる
left = 0 #探索する範囲の左端を設定
right = len(data) - 1 #探索する範囲の右端を設定
while left <= right:
mid = (left + right) // 2 #探索する範囲の中央値
if data_sorted[mid] == target:
return mid , data_sorted #中央値と一致した場合はその位置と並び変えたデータを返す
elif data_sorted[mid] < target:
left = mid + 1 #中央値よりも大きい場合は探索範囲の左端を変える
else:
right = mid - 1 #中央値よりも小さい場合は探索範囲の右端を変える
return False, -1
if __name__ == '__main__':
data = [10, 50, 60, 20, 30, 40, 90, 70, 80]
target = 50
found, data_sorted = binary_search(data, target)
if not found:
print(f"{target} is not found in the data")
else:
print(f"data_sorted is the sorted data : \n{data} >>> {data_sorted}\n")
print(f"{target} is found at data_sorted[{found}]")
出力(データが見つかったとき)
data_sorted is the sorted data :
[10, 50, 60, 20, 30, 40, 90, 70, 80] >>> [10, 20, 30, 40, 50, 60, 70, 80, 90]
50 is found at data_sorted[4]
出力(データが見つらなかったとき)
5 is not found in the data
2つ目は必要であるか分からないが,ソートも含めて行う関数を作るならこんな感じかなと試しに作った.ソート可能なデータリストであればうまくいくと思う.繰り返し,左端や右端を中央値と入れ替えることで探索範囲の縮小を行っている.
感想
線形探索とこれほどまでに違いがあるということを知った.仕組みからして当たり前ではあるが,グラフに表すことでそのことをより直感的に理解することができた.
参考文献
Pythonで始めるアルゴリズム入門 伝統的なアルゴリズムで学ぶ定石と計算量
増井 敏克 著 翔泳社