0. はじめに
初めまして、Yuulisです。今年の3月ぐらいから、Unityの強化学習ライブラリである、ML-Agentsを使って強化学習をして遊んでいる高校生です。
Qiita初投稿ではありますが、ML-Agentsの日本語解説記事を増やすという目的も兼ねて、今回から強化学習でAIに避難行動を学習させていこうと思います。
1. ML-Agents環境を用意する
ML-Agentsを使う上で環境構築は重要です。しかし、うまく書ける自信がないので、自分の中で分かりやすかったサイトを貼っておきます。
また、以下の書籍もかなり参考になりました。誤植が一部ありますが、気づける範囲です。これからML-Agentsを始めたい、という方には是非おすすめです。
Unity ML-Agents 実践ゲームプログラミング v1.1対応版 (Unityではじめる機械学習・強化学習)

※ML-Agentsの最新バージョンは、2021/05/04時点でRelease 17となっていますが、私の環境はUnity 2019.4.23f1, ML-Agents Release 12です。
追記 (2021/08/29) ML-Agentsパッケージが2.0.0に更新されました。
2. 今回作るもの
初回の今回は、4つの非常口の中から一番近いものに避難するAIを作ることを目標とします。

2-1. 学習環境全般
長方形のエリアの四隅に、非常口を設置します。なお、エリアには壁は存在せず、下に落ちると失敗です。
2-2. エージェントの設定
環境の観察
環境の観察は、Raycast Observationという方法を使います。エージェントの周囲からレーザーを発射し、そのレーザーに当たったものを検知します。
行動
行動を記録するデータ型は、Discreteというものを使います。これは、離散値(0, 1, 2...)の要素を持つ整数配列です。
今回は、1回の行動の配列の長さは1で、配列1つの要素に入り得る要素の数は次の5つです。
| 数値 | 行動 |
|---|---|
| 0 | 移動しない |
| 1 | 前 |
| 2 | 後ろ |
| 3 | 右回転 |
| 4 | 左回転 |
※例えば、[1],[3],[2]というデータがあれば、「前、右回転、後ろ」を意味します。
報酬
生成時に最も近かった非常口に触れれば+1.0。それ以外の場合は+0.3。
エリアから落下したら-0.2。
1行動ごとに-1.0 / MaxStep
※MaxStepというのは、1回の学習で行動できる回数のことです。例えばMaxStep = 5000ならば、エージェントは5000回行動できます。
3. 実装
3-1. ML-AgentsライブラリをUnityに追加
では、いよいよ実装していきます。まずは、ML-AgentsライブラリをUnityに追加します。
Unityの新しいプロジェクト「EvacuationLearning」を作成したら、「ウィンドウ」から「Package Maneger」を選択してください。
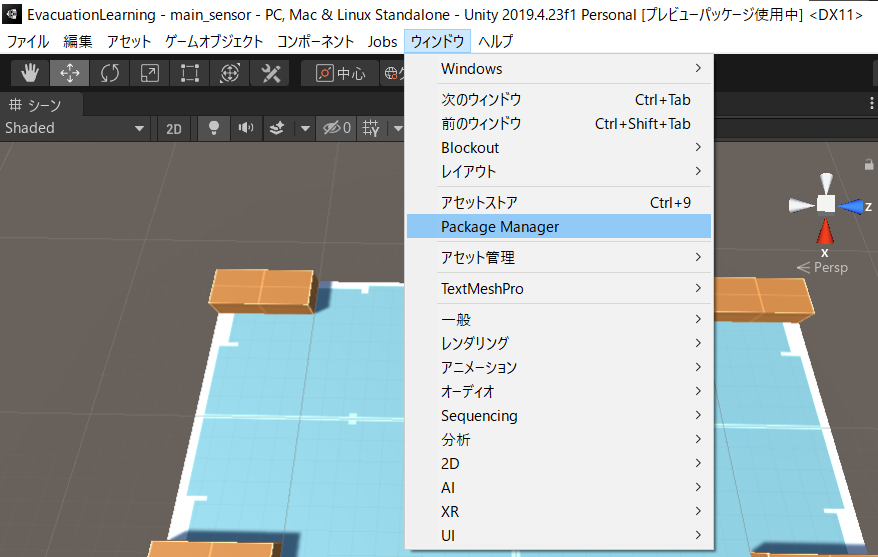
Package Manegerの読み込みが終わったら(少し時間がかかる)、左上のボタンから「Add package from disk...」を選択してください。
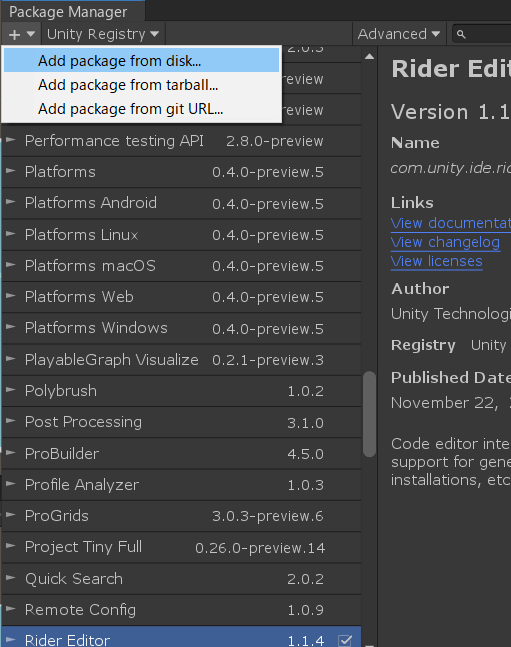
1. ML-Agents環境を用意する でクローン(ダウンロード)したML-Agents toolkitのディレクトリに移動し、com.unity.ml-agents/package.jsonとcom.unity.ml-agents.extensions/package.jsonを追加します。
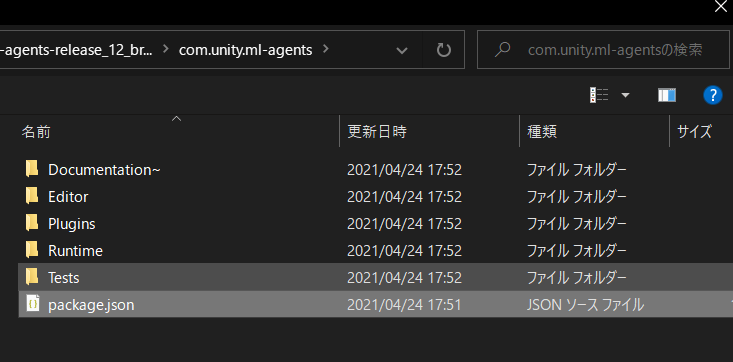
パッケージを追加したら、今度は「ファイル」から「ビルド設定」を選択し、左下の「プレイヤー設定」を選択します。
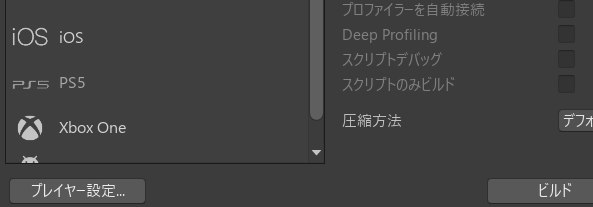
下にスクロールして、「API 互換性レベル」を「.NET 4.x」に変更します。
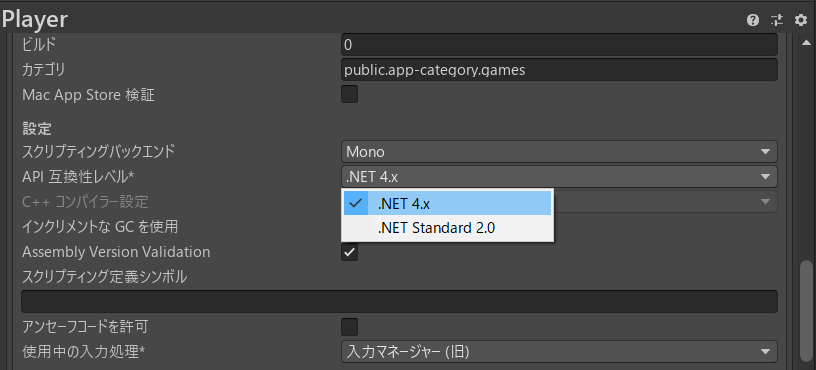
以上でML-AgentsライブラリをUnityに追加することができました。
3-2. 学習環境の作成
次に、エージェントが学習する環境を作成します。
以下のオブジェクトを追加し、ヒエラルキーの「Transform」タブを以下のように設定してください。
Areaは「Plane」、その他は「Cube」のオブジェクトを使います。
| オブジェクト名 | 座標 | 角度 | サイズ |
|---|---|---|---|
| Area | (0, 0, 0) | (0, 0, 0) | (1.5, 1, 3) |
| Agent | (0, 0.5, 0) | (0, 0, 0) | (1, 1, 1) |
| Target1 | (-6.5, 0.5, -12.5) | (0, 0, 0) | (2, 1, 5) |
| Target2 | (6.5, 0.5, -12.5) | (0, 0, 0) | (2, 1, 5) |
| Target3 | (6.5, 0.5, 12.5) | (0, 0, 0) | (2, 1, 5) |
| Target4 | (-6.5, 0.5, 12.5) | (0, 0, 0) | (2, 1, 5) |
「Agent」には「Rigidbody」を追加します。以下のように設定してください。
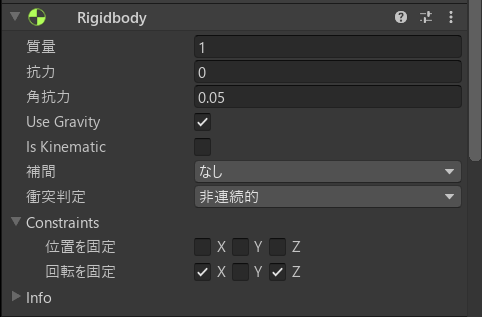
さらに、Agentの向いている方向が分かるよう、顔のパーツも追加します。この辺はお好みです。私は以下のように設定しました。
目は「Cylinder」、口は「Cube」です。
| オブジェクト名 | 座標 | 回転 | サイズ |
|---|---|---|---|
| Eye | (0.25, 0.2, 0.35) | (90, 0, 0) | (0.2, 0.2, 0.2) |
| Eye(1) | (-0.25, 0.2, 0.35) | (90, 0, 0) | (0.2, 0.2, 0.2) |
| Mouth | (0, -0.2, 0.5) | (0, 0, 90) | (0.1, 0.5, 0.1) |
これらのオブジェクトは「Agent」の子オブジェクトにしてください。
次はそれぞれにMaterialを付けます。この辺もお好みです。別にMaterial用のディレクトリを作っておくとよいでしょう。
ちなみに私はBlockoutという無料アセットを使っています。アセットストアからダウンロードできます。
エージェント本体には赤色のマテリアル、エージェントの顔には黒色のマテリアルを適用しました。
それ以外のオブジェクトにはBlockoutのマテリアルを適用。
最後に、「TrainingArea」という空のオブジェクトを追加し、すべてのオブジェクトを子オブジェクト化します。
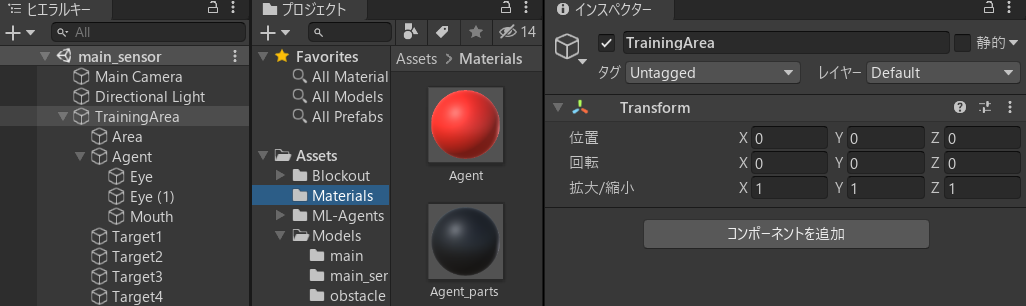
これで、「TrainingArea」を複製することで並行学習が簡単になりました。
以上で学習環境の作成が完了です。
3-3. 学習のためのスクリプトを作成
今度は、「Agent」に強化学習のスクリプトを適用します。
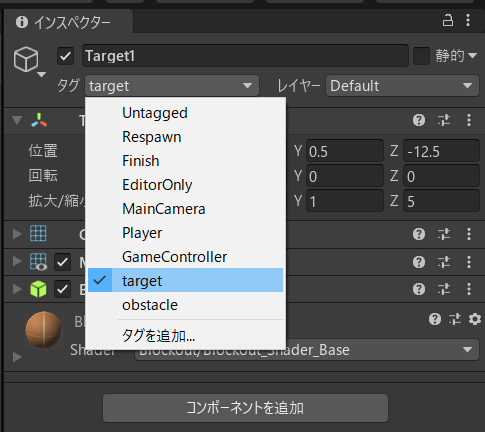
その前に、今後のために、「Target」にtagを付けておきます。
インスペクターウィンドウの「タグ」を選択し、「タグを追加...」をクリック(画像ではすでに「target」と「obstacle」というタグができていますが無視して結構です)。
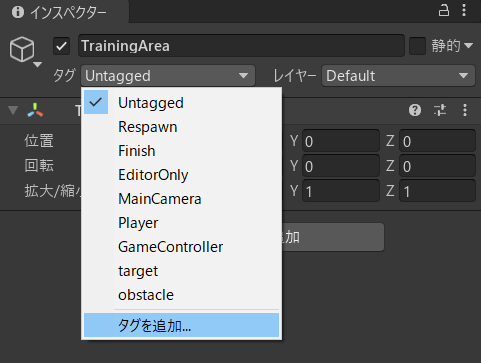
以下のような画面になるので、「タグ」の右下の+ボタンをクリックし、新しいタグの名前「target」を入力して「Save」。
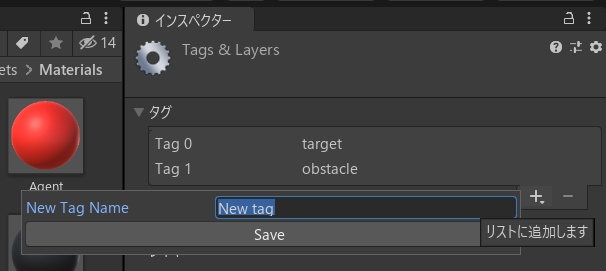
Target1~4のそれぞれに「target」タグをつけます。
では、スクリプトを書いていきましょう。
エージェントのインスペクターウィンドウの「コンポーネントを追加」から、新しいスクリプト「AgentControl.cs」を作成。
以下のように書き換えます。
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
// ML-Agentsパッケージの追加
using Unity.MLAgents;
using Unity.MLAgents.Sensors;
using Unity.MLAgents.Actuators;
public class AgentControl : Agent // 基底クラスをAgentに変更
{
public Transform target1;
public Transform target2;
public Transform target3;
public Transform target4;
Rigidbody rBody;
private bool onEpisode = false; // エピソード実行中かどうか
private string closestTarget; // 生成時に最も近かったターゲット名を格納
// 初期化時
public override void Initialize()
{
this.rBody = GetComponent<Rigidbody>();
onEpisode = false;
}
// エピソード開始時
public override void OnEpisodeBegin()
{
// エージェントの状態をリセット
this.rBody.angularVelocity = Vector3.zero;
this.rBody.velocity = Vector3.zero;
this.transform.rotation = Quaternion.identity;
// エリアのランダムな位置に生成
this.transform.localPosition = new Vector3(Random.Range(-6.5f, 6.5f), 0.5f, Random.Range(-14.0f, 14.0f));
// エピソード開始
onEpisode = true;
// スポーン時の最近のターゲットを取得
float dis1 = Vector3.Distance(this.transform.localPosition, target1.localPosition);
float dis2 = Vector3.Distance(this.transform.localPosition, target2.localPosition);
float dis3 = Vector3.Distance(this.transform.localPosition, target3.localPosition);
float dis4 = Vector3.Distance(this.transform.localPosition, target4.localPosition);
float leastDis = Mathf.Min(dis1, dis2, dis3, dis4);
if (leastDis == dis1) closestTarget = "Target1";
if (leastDis == dis2) closestTarget = "Target2";
if (leastDis == dis3) closestTarget = "Target3";
if (leastDis == dis4) closestTarget = "Target4";
}
// 行動実行時 size = 5
public override void OnActionReceived(float[] vectorAction)
{
Vector3 dirToGo = Vector3.zero;
Vector3 rotateDir = Vector3.zero;
// 離散値ごとの行動設定
int action = (int)vectorAction[0];
if (action == 1) dirToGo = transform.forward; // 前
if (action == 2) dirToGo = transform.forward * -1.0f; // 後ろ
if (action == 3) rotateDir = transform.up; // 右
if (action == 4) rotateDir = transform.up * -1.0f; // 左
this.transform.Rotate(rotateDir, Time.deltaTime * 200f);
this.rBody.AddForce(dirToGo * 0.6f, ForceMode.VelocityChange);
// エリアから落下したとき
if (this.transform.localPosition.y < 0)
{
AddReward(-0.3f); // 罰
EndEpisode();
}
// ステップごとの罰
AddReward(-1.0f / MaxStep);
}
// 目標にぶつかったとき
public void OnCollisionEnter(Collision collision)
{
if (collision.gameObject.tag == "target")
{
// エピソード中なら
if (onEpisode)
{
// 生成時に最も近かったターゲットなら
if (collision.gameObject.name == closestTarget)
{
AddReward(1.0f); // 最大報酬
EndEpisode();
}
// それ以外なら
else
{
AddReward(0.3f); // 小さな報酬
EndEpisode();
}
}
// エピソード中でなければ
else
{
// ランダムな位置に生成のやり直し
this.transform.localPosition = new Vector3(Random.Range(-6.5f, 6.5f), 0.5f, Random.Range(-14.0f, 14.0f));
}
}
}
// 人間が操作するとき
public override void Heuristic(float[] actionsOut)
{
actionsOut[0] = 0;
if (Input.GetKey(KeyCode.UpArrow)) actionsOut[0] = 1;
if (Input.GetKey(KeyCode.DownArrow)) actionsOut[0] = 2;
if (Input.GetKey(KeyCode.RightArrow)) actionsOut[0] = 3;
if (Input.GetKey(KeyCode.LeftArrow)) actionsOut[0] = 4;
}
}
大まかな説明はスクリプト内にコメントしておきました。
では、Agentのインスペクターウィンドウに戻り、設定を行っていきます。
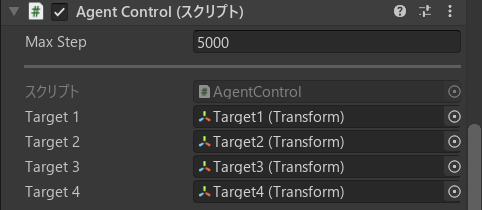
まずは先ほど書いたスクリプトの設定。
Target1~4には、3-2. 学習環境の作成 で作ったTargetをドラッグアンドドロップ。
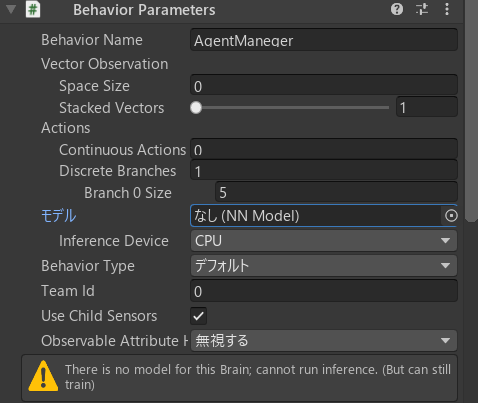
次に、「Behavior Parameters」という、エージェントの行動にかかわるスクリプトを追加。すでにある場合もありますが、追加されてなければ「コンポーネントを追加」から追加できます。
以下のように設定。
今回はRayCast Observationを使うので、「Vector Observation」の「Space Size」は0にセット。
また、「Discrete Branches」は2-2. エージェントの設定 の行動の欄を参考に。
最後に、エージェントの観察をするためのセンサーを追加します。
「コンポーネントを追加」から、「Ray Perception Sensor 3D」を追加し、以下のように設定します。
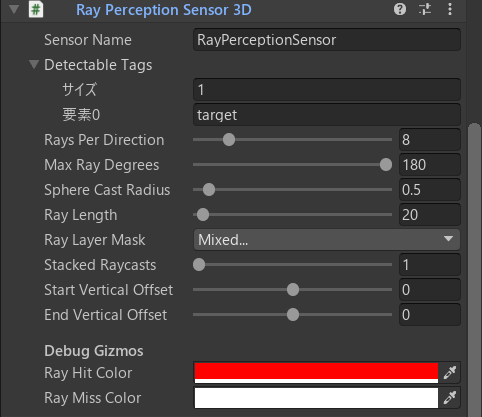
今回は、エージェントの周囲360°から16方向にセンサーを発射します。
そして、学習を効率化させるために、並行学習をします。「TrainingArea」を9個ほど複製し、互いの学習環境に影響を与えないよう、四方50ぐらい間をあけます。
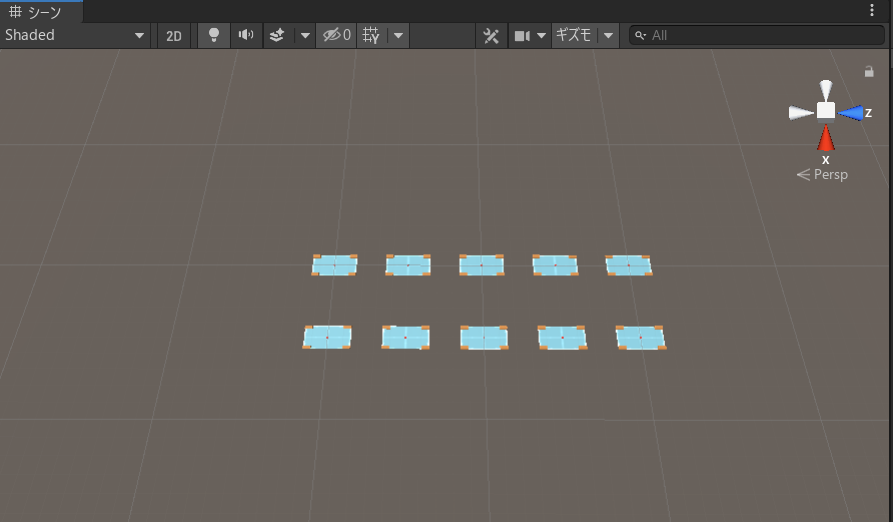
こんな感じ。
以上で学習環境の実装は終了です。
4. 強化学習をやってみる
強化学習を始める前に、学習用パラメータの設定をします。
EvacuationLearning\config\base.yamlを新しく作成します。
以下のようなコードを書きます。
behaviors:
AgentManeger:
trainer_type: ppo
hyperparameters:
batch_size: 128
buffer_size: 2048
learning_rate: 0.0003
beta: 0.005
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: true
hidden_units: 256
num_layers: 3
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.95
strength: 1.0
max_steps: 1000000
keep_checkpoints: 5
checkpoint_interval: 200000
time_horizon: 64
summary_freq: 10000
threaded: true
ここの詳しい説明は書籍にも載っていますが、次回説明しようと思います。
いよいよ学習です!
Anaconda Promptを起動し、以下のコマンドを順に実行します。
-
仮想環境の起動
conda activate (作成した仮想環境名)
※(仮想環境名) >>>となれば成功。 -
プロジェクトのディレクトリに移動
cd (プロジェクトのディレクトリのパス) -
学習開始コマンド
mlagents-learn .\config\base.yaml --run-id=1st
1stの部分は重複は許されません。学習ごとに変える必要があります。
※こんな感じのアスキートアートと、Listening on port (ランダムな値). Start training by pressing the Play button in the Unity Editor.
というコードが出たら成功。
▄▄▄▓▓▓▓
╓▓▓▓▓▓▓█▓▓▓▓▓
,▄▄▄m▀▀▀' ,▓▓▓▀▓▓▄ ▓▓▓ ▓▓▌
▄▓▓▓▀' ▄▓▓▀ ▓▓▓ ▄▄ ▄▄ ,▄▄ ▄▄▄▄ ,▄▄ ▄▓▓▌▄ ▄▄▄ ,▄▄
▄▓▓▓▀ ▄▓▓▀ ▐▓▓▌ ▓▓▌ ▐▓▓ ▐▓▓▓▀▀▀▓▓▌ ▓▓▓ ▀▓▓▌▀ ^▓▓▌ ╒▓▓▌
▄▓▓▓▓▓▄▄▄▄▄▄▄▄▓▓▓ ▓▀ ▓▓▌ ▐▓▓ ▐▓▓ ▓▓▓ ▓▓▓ ▓▓▌ ▐▓▓▄ ▓▓▌
▀▓▓▓▓▀▀▀▀▀▀▀▀▀▀▓▓▄ ▓▓ ▓▓▌ ▐▓▓ ▐▓▓ ▓▓▓ ▓▓▓ ▓▓▌ ▐▓▓▐▓▓
^█▓▓▓ ▀▓▓▄ ▐▓▓▌ ▓▓▓▓▄▓▓▓▓ ▐▓▓ ▓▓▓ ▓▓▓ ▓▓▓▄ ▓▓▓▓`
'▀▓▓▓▄ ^▓▓▓ ▓▓▓ └▀▀▀▀ ▀▀ ^▀▀ `▀▀ `▀▀ '▀▀ ▐▓▓▌
▀▀▀▀▓▄▄▄ ▓▓▓▓▓▓, ▓▓▓▓▀
`▀█▓▓▓▓▓▓▓▓▓▌
¬`▀▀▀█▓
Version information:
ml-agents: 0.23.0,
ml-agents-envs: 0.23.0,
Communicator API: 1.3.0,
PyTorch: 1.7.0+cu110
2021-05-05 12:47:13 INFO [learn.py:275] run_seed set to 7390
2021-05-05 12:47:14 INFO [environment.py:205] Listening on port 5004. Start training by pressing the Play button in the Unity Editor.
このコードが出たら、すぐにUnityの画面に戻って「Play」ボタンを押してください。ある程度時間が経過すると、エラーになって学習開始コマンドの打ち直しになります。
学習中は2021-05-05 12:47:48 INFO [stats.py:139] AgentManeger. Step: 10000. Time Elapsed: 35.025 s. Mean Reward: -0.017. Std of Reward: 0.632. Training.
のようなログがプロンプトに表示されます。
今回は100万Step学習することになっているので、1時間程度かかります。
ちなみに、Mean RewardはStepごとの報酬平均、Std of Rewardは標準偏差を表しています。
今回の場合では、前者が1に近づき、後者の値が0.4以下ぐらいになれば成功だといえるでしょう。
私のケースでは、70万Stepあたりで変化がほぼなくなったので、学習を終了しました。
5. 学習結果の確認
学習が終わったら、結果を確認しましょう。
EvacuationLearing\results\1stに、AgentManeger.onnxというファイルができているはずです。
それをUnityのプロジェクトウィンドウにドラッグアンドドロップ。
さらにそれを、「Agent」のヒエラルキーウィンドウの「Behavior Parameters」の「モデル」の部分にアタッチします。
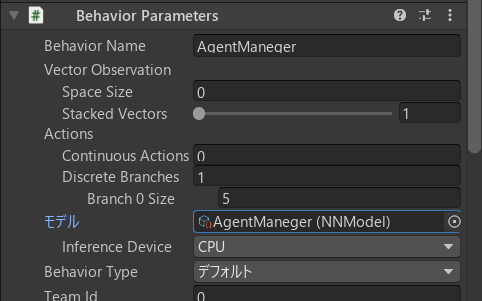
「Play」ボタンを押してみましょう。こんな感じに動きましたか?(さらっとTwitterの宣伝)
報酬グラフや詳しい情報は、以下のコマンドをAnaconda Promptで実行すると得られます。
tensorboard --logdir results
すると、localhostのリンクが出てくるので、コピペしてアクセス。
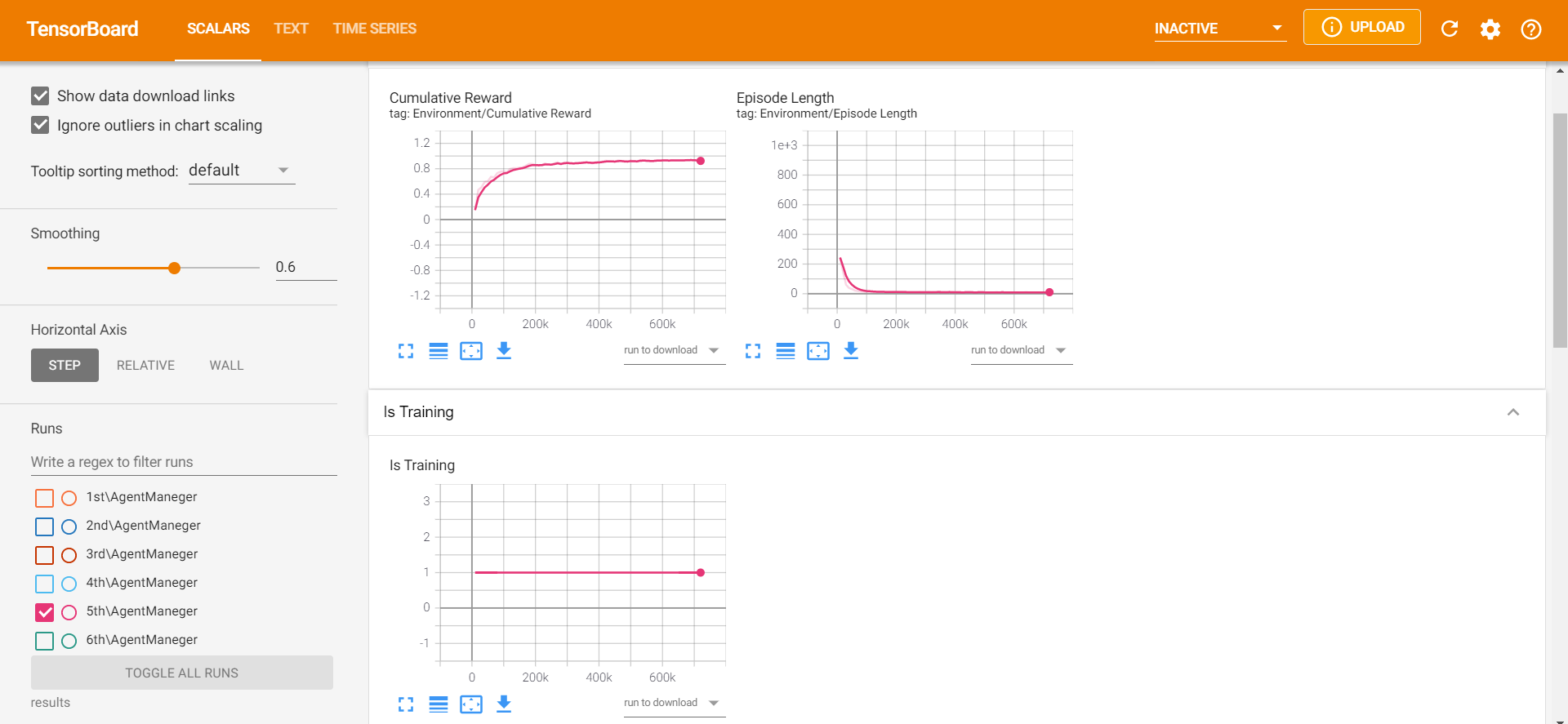
うん、うまい具合に学習できました。
6. 終わりに
いかがでしたでしょうか。
強化学習に興味を持っていろいろ調べた結果、UnityのML-Agentsを発見したのですが、やはり解説が少ないです(あったとしてもほぼ同じ内容)。これからこの分野を開拓していきたいと思っています。
初投稿ということもあり、執筆に時間がかかってしまいました。誤字や不明な点があれば、ご指摘ください。
また、この記事を読んで、少しでも強化学習に興味を持っていただけたら幸いです。
ありがとうございました。