はじめに
リコーのYuuki_Sです。
弊社ではRICOH THETAという全周囲360度撮れるカメラを出しています。
RICOH THETA VやTHETA Z1は、OSにAndroidを採用しており、Androidアプリを作る感覚でTHETAをカスタマイズすることもでき、そのカスタマイズ機能を「プラグイン」と呼んでいます。(詳細は本記事の末尾を参照)。
上述の通りTHETAは、カメラでありながらAndroid端末でもあるため、単体で撮影し機械学習の処理をかけて出力することが可能です。
以前、@KA-2さんがTHETAプラグインで連続フレームにTensorFlow Liteの物体認識をかける記事を掲載しましたが、今回はセマンティックセグメンテーションを実施する方法を記載しようと思います。
本記事を参考にすることで、セグメンテーション結果をライブプレビューに反映したり、
下図の様に人物と背景で異なる画像処理をおこなうことが可能になります。

セマンティックセグメンテーションとは
画像中のそれぞれのピクセルがどの様な属性(クラス)の物体に属しているか分類することを指します。
例えば、下図のように様々な物体が写った画像から、この領域のピクセルは人間、この領域は車といった具合に領域分割することです。
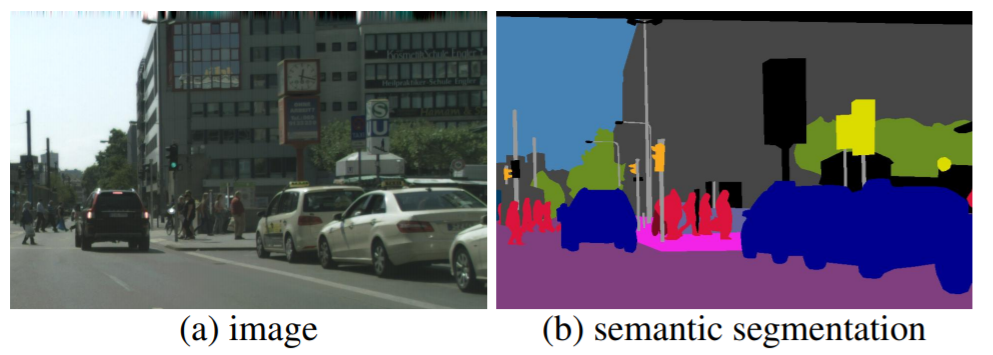
画像引用元:"Panoptic Segmentation" Alexander Kirillov et al.,CVPR, 2019
この様な分類処理は、昔から画像処理の分野でおこなわれていましたが、Deep Learningを用いることで飛躍的に性能が向上しました。
今では、iPhoneのポートレートモードや自動車の自動運転などでも利用されています。
TensorFlow Liteのセグメンテーション
TensorFlow Liteのページで紹介されているモデルの1つに、このセグメンテーション処理があります。

詳しくはTensorFlow Lite Segmentationのページを参照してください。
TensorFlow Liteでは、下記の21種類のクラス分けが可能です。
(background/aeroplane/bicycle/bird/boat/bottle/bus/car/cat/chair/cow/diningtable/dog/horse/motorbike/person/pottedplant/sheep/sofa/train/tv)
今回試した環境では、人間とTVのクラス分けが出来ることを確認しました。
THETA Plug-in SDKで動作環境構築
それでは、本題であるTHETA上でのセグメンテーション動作環境構築に入っていきます。
作業のベースとなるプロジェクトファイル一式は、@KA-2さんの以下記事で解説したものです。
下準備
今回使用するセグメンテーションのサンプルコードは、AndroidXライブラリを用いてKotlinで書かれています。これらに対応させつつ、サンプルコードを導入しMainActivity.javaからセグメンテーション処理を利用できるようにします。
※KotlinもAndroidXも使用経験がなく、試行錯誤で対応した結果を記載しているため、冗長な部分があるかもしれません。
build.gradle(Module:app)の設定
*「apply」に2行追加。
*「testInstrumentationRunner」を変更。
*「aaptOptions」で、モデルファイルを圧縮しないように指定。
*「implementation」の定義を書き換え。
*「targetSdkVersion」等を変更。
apply plugin: 'kotlin-android'
apply plugin: 'kotlin-android-extensions'
android {
compileSdkVersion 29
buildToolsVersion "29.0.2"
~省略~
defaultConfig {
~省略~
targetSdkVersion 29
~省略~
testInstrumentationRunner "androidx.test.runner.AndroidJUnitRunner"
}
~省略~
aaptOptions {
noCompress "tflite"
}
}
dependencies {
implementation fileTree(include: ['*.jar'], dir: 'libs')
implementation 'androidx.appcompat:appcompat:1.0.0'
implementation 'androidx.constraintlayout:constraintlayout:1.1.3'
testImplementation 'junit:junit:4.12'
androidTestImplementation 'androidx.test.ext:junit:1.1.1'
androidTestImplementation 'androidx.test.espresso:espresso-core:3.1.0'
implementation 'com.theta360:pluginlibrary:2.1.0'
implementation 'org.nanohttpd:nanohttpd-webserver:2.3.1'
implementation('org.tensorflow:tensorflow-lite:0.0.0-nightly') { changing = true }
implementation('org.tensorflow:tensorflow-lite-gpu:0.0.0-nightly') { changing = true }
implementation 'org.jetbrains.kotlin:kotlin-stdlib:1.3.71'
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-android:1.3.0'
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-core:1.3.0'
implementation 'androidx.core:core-ktx:1.2.0'
implementation "androidx.exifinterface:exifinterface:1.1.0"
}
build.gradle(Project:~)の設定
TensorFlow Lite側のコードがkotlinのため、以下を追加しました。
buildscript {
~省略~
dependencies {
~省略~
classpath "org.jetbrains.kotlin:kotlin-gradle-plugin:1.3.0"
~省略~
}
}
学習済みモデルの配置
TensorFlow LiteのセグメンテーションのページにあるDownload stater modelのボタンを押して、学習済みモデルをダウンロードします。
記事執筆時点のファイル名は「deeplabv3_257_mv_gpu.tflite」です。
このファイルをassetsフォルダーに配置してください。
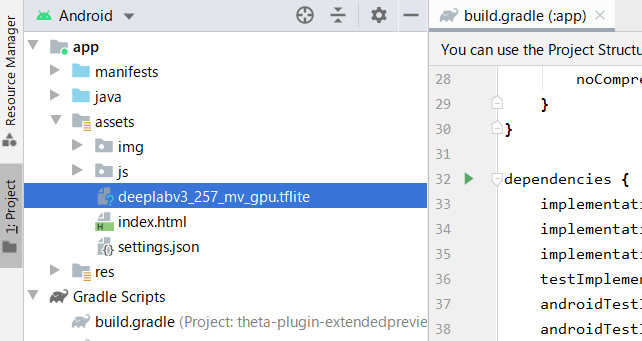
セグメンテーション処理クラスの追加
Android用のサンプルコードから、以下の3ファイルを取得します。
| ファイル名 | 説明 |
|---|---|
| ImageUtils.kt | 画像の読み込みと操作をおこなうユーティリティ |
| ModelExecutionResult.kt | セグメンテーション結果の構造を記載したクラス |
| ImageSegmentationModelExecutor.kt | セグメンテーションの実処理が記述されているファイル |
取得したファイルは、配置の仕方にあわせpackageの定義を書き換えてください。
以下は、ベースとしたプロジェクトの「~\app\src\main\java\com\theta360\extendedpreview」に3つのファイルを配置した場合の例です。この場合、packageの定義は3ファイル共に以下となります。また、元のpackage定義はコメントアウトしてください。
package com.theta360.extendedpreview
//package org.tensorflow.lite.examples.imagesegmentation
AndroidXへのリファクタリング
ここまで終えたら、プロジェクト全体をAndroidXへリファクタリングします。
ツールバーのRefactorからMingrate to AndroidXを選択します。
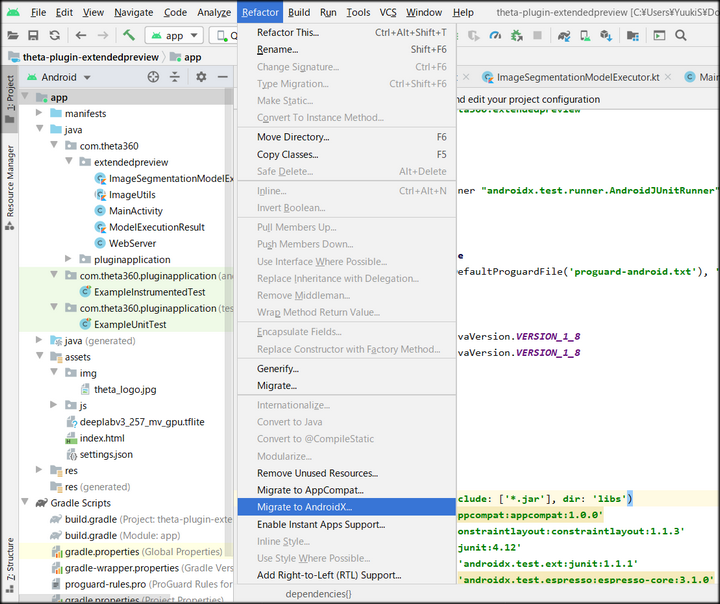
選択後、現状のプロジェクトの状態をZip形式でバックアップするか尋ねられますので、必要な場合はバックアップします。
その後、リファクタリングが必要な箇所の検索が始まり、終わるとリストが表示されますので、Do Refactorボタンをクリックします。
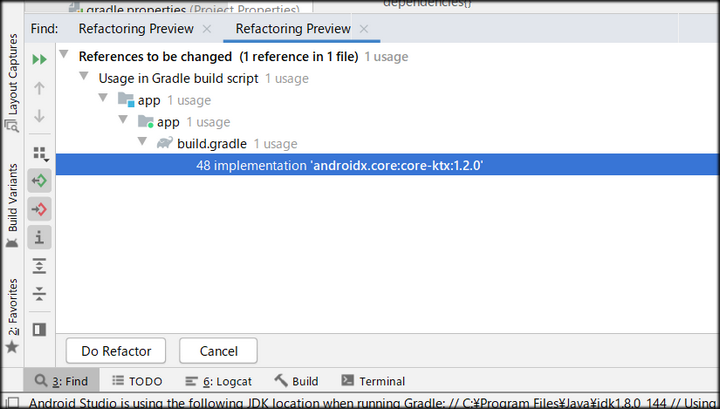
最後に、レイアウトファイルを編集します。
activity_main.xmlを開き、
<androidx.constraintlayout.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android"
を
<androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android"
に書き換えます。
以上で、MainActivity.javaからセグメンテーション処理を利用できる様になります。
MainActivityからセグメンテーション処理を利用する
まずは、プレビュー画面にセグメンテーション結果を重ねて描画してみます。
処理の流れは下記になります。
プレビュー画像の取得→中央部分を正方形で切り抜き→セグメンテーション処理に流し込む→結果を受け取り重ねて描画
これをおこなうコードは次の通りです。
private byte[] latestFrame_Result;
private ImageSegmentationModelExecutor imageSegmentationModel;
public void drawTFThread() {;
new Thread(new Runnable() {
@Override
public void run() {
Bitmap beforeBmp = null;
android.os.Process.setThreadPriority(android.os.Process.THREAD_PRIORITY_BACKGROUND);
imageSegmentationModel = new ImageSegmentationModelExecutor((Context)MainActivity.this, true);
while (mFinished == false) {
byte[] jpegFrame = latestLvFrame;
if ( jpegFrame != null ) {
//JPEG -> Bitmap
BitmapFactory.Options options = new BitmapFactory.Options();
options.inMutable = true;
Bitmap bitmap = BitmapFactory.decodeByteArray(jpegFrame, 0, jpegFrame.length);
Bitmap output = Bitmap.createBitmap(bitmap.getWidth(),bitmap.getHeight(), Bitmap.Config.ARGB_8888);
//crop
Bitmap cropBitmap = Bitmap.createBitmap(bitmap, (bitmap.getWidth() - bitmap.getHeight())/2, 0, bitmap.getHeight(), bitmap.getHeight(), null, true);
//TF処理
ModelExecutionResult result = imageSegmentationModel.execute(cropBitmap);
//結果の描画
Bitmap result_bmp = result.getBitmapResult();
Bitmap afterResizeBitmap = Bitmap.createScaledBitmap(result_bmp,cropBitmap.getWidth(),cropBitmap.getHeight(),true);
Canvas resultCanvas = new Canvas(output);
resultCanvas.drawBitmap(bitmap,0,0,null);
resultCanvas.drawBitmap(afterResizeBitmap,(bitmap.getWidth() - bitmap.getHeight())/2, 0,null);
//ライブビューへの反映
ByteArrayOutputStream baos = new ByteArrayOutputStream();
output.compress(Bitmap.CompressFormat.JPEG, 100, baos);
latestFrame_Result = baos.toByteArray();
} else {
try {
Thread.sleep(33);
} catch (InterruptedException e) {e.printStackTrace();}
}}}}).start();
}
事前処理、事後処理で少し長くなっていますが、セグメンテーション処理をおこなうのは下記の1行です。
cropBitmapという名前の切り抜いたBitmapを渡しています。
ModelExecutionResult result = imageSegmentationModel.execute(cropBitmap);
そして、セグメンテーション結果は以下でBitmapとして受け取ります。
Bitmap result_bmp = result.getBitmapResult();
この例では、セグメンテーション結果と元画像が重なった画像を取得していますが、セグメンテーション結果のマスクのみの取得も可能です。
結果の種類は、ModelExecutionResult.ktで定義されており、以下があります。
| 変数名 | 説明 |
|---|---|
| bitmapResult | 元画像とセグメンテーション結果が重なった画像 |
| bitmapOriginal | 元画像 |
| bitmapMaskOnly | セグメンテーション結果のマスクのみ画像 |
| executionLog | ログ情報 |
| itemsFound | セグメンテーションした物体の属性番号リスト |
さて、処理するコードを書いたので、これを呼び出す記述とプレビューに反映する記述をおこないます。
//処理を呼び出す記述
protected void onResume() {
~省略~
drawTFThread();
}
//プレビューに反映する処理(returnするBitmapを変更)
private WebServer.Callback mWebServerCallback = new WebServer.Callback() {
~省略~
public byte[] getLatestFrame() {
//return latestLvFrame;
return latestFrame_Result;
}};
以上を変更し実行すると下図のようにプレビューにセグメンテーション結果が描画されます。
この画像中では人間しか分類していない為、1種類しか色分けされていませんが、複数検出されれば、複数の色で描画されます。

なお、現状ではフレームレートが1fps程度しか出ません。認識状態の確認には使えますが、コマ送りです。
(スマホでプラグイン動作のプレビューが見えるのは、やはり便利)
撮影画像に対するセグメンテーション&画像処理
せっかく人領域と背景領域がセグメンテーションにより分離できるようになったので、
これを撮影画像に対して反映し、簡単な処理をした画像を保存する仕組みを作ってみます。
具体的には撮影ボタンが押されたことをトリガとして、撮影画像のファイルパスを取得し、その画像に前述と同じセグメンテーション処理をおこないます。
そして、セグメンテーション結果から人物と背景領域に異なる画像処理をかけて保存します。
これらの処理はTakePictureTask.Callback内のonTakePictureに記述します。
(THETAの撮影画像利用に関しては右記の記事が参考になります。→画像処理を含むTHETAプラグインの実装方法【THETAプラグイン開発】
コードは以下の通りです。
public static final String DCIM = Environment.getExternalStoragePublicDirectory(Environment.DIRECTORY_DCIM).getPath();
public void onTakePicture(String fileUrl) {
//撮影済み画像のファイルパス取得
Matcher matcher = Pattern.compile("/\\d{3}RICOH.*").matcher(fileUrl);
if (matcher.find()) {
fileUrl = DCIM + matcher.group();
Log.d(TAG,matcher.group());
}
//JPEG読み込み、Bitmap化
BitmapFactory.Options options = new BitmapFactory.Options();
options.inMutable = true;
File file = new File(fileUrl);
Bitmap bitmap_input = null;
try(InputStream inputStream = new FileInputStream(file)) {
bitmap_input = BitmapFactory.decodeStream(inputStream);
} catch (IOException e) {
e.printStackTrace();
}
//crop
Bitmap cropBitmap = Bitmap.createBitmap(bitmap_input, (bitmap_input.getWidth() - bitmap_input.getHeight())/2, 0, bitmap_input.getHeight(), bitmap_input.getHeight(), null, true);
//TF処理
ModelExecutionResult result = imageSegmentationModel.execute(cropBitmap);
//結果の処理(マスク画像を抽出し、それをリサイズ)
Bitmap result_bmp_mask = result.getBitmapMaskOnly();
Bitmap afterResizeBitmap = Bitmap.createScaledBitmap(result_bmp_mask,cropBitmap.getWidth(),cropBitmap.getHeight(),true);
//人物領域をマスク画像に基づいて抽出
Bitmap output_Front = Bitmap.createBitmap(bitmap_input.getWidth(),bitmap_input.getHeight(), Bitmap.Config.ARGB_8888);
Canvas resultCanvas_Front = new Canvas(output_Front);
Paint paint = new Paint();
resultCanvas_Front.drawBitmap(cropBitmap,(bitmap_input.getWidth() - bitmap_input.getHeight())/2, 0,paint);
paint.setFilterBitmap(false);
paint.setXfermode(new PorterDuffXfermode(PorterDuff.Mode.DST_IN));
resultCanvas_Front.drawBitmap(afterResizeBitmap,(bitmap_input.getWidth() - bitmap_input.getHeight())/2, 0,paint);
paint.setXfermode(null);
if (cropBitmap != null) {
cropBitmap.recycle();
cropBitmap = null;
}
if (afterResizeBitmap != null) {
afterResizeBitmap.recycle();
afterResizeBitmap = null;
}
if (result_bmp_mask != null) {
result_bmp_mask.recycle();
result_bmp_mask = null;
}
//背景領域を彩度0にする
Bitmap output_back = Bitmap.createBitmap(bitmap_input.getWidth(),bitmap_input.getHeight(), Bitmap.Config.RGB_565);
Canvas resultCanvas_Back = new Canvas(output_back);
Paint paint_ColorFilter = new Paint();
ColorMatrix cm = new ColorMatrix();
cm.setSaturation(0);
ColorMatrixColorFilter f = new ColorMatrixColorFilter(cm);
paint_ColorFilter.setColorFilter(f);
resultCanvas_Back.drawBitmap(bitmap_input,0,0,paint_ColorFilter);
//人物領域と背景領域を重ね合わせ
Bitmap output = Bitmap.createBitmap(bitmap_input.getWidth(),bitmap_input.getHeight(), Bitmap.Config.RGB_565);
Canvas resultCanvas = new Canvas(output);
resultCanvas.drawBitmap(output_back,0,0,null);
resultCanvas.drawBitmap(output_Front,0,0,null);
//画像保存処理開始
try {
FileOutputStream fos = null;
String targetFileName = fileUrl.substring(fileUrl.length() - 11);
targetFileName = targetFileName.substring(0,7);
int addNum = Integer.parseInt(targetFileName) + 1;
String outputFileName = fileUrl.substring(0,fileUrl.length() - 11) + String.format("%07d", addNum)+".JPG";
fos = new FileOutputStream(outputFileName);
output.compress(Bitmap.CompressFormat.JPEG, 100, fos);
fos.close();
String[] FolderUrls = new String[]{"DCIM/100RICOH"};
notificationDatabaseUpdate(FolderUrls);
} catch (Exception e) {
Log.e("Error", "" + e.toString());
}
startPreview(mGetLiveViewTaskCallback, previewFormatNo);
}
また、画像を保存するためにマニフェストファイルに外部ストレージアクセスを追記します。
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE"/>
ポイントとしてはマスク画像を利用した合成にPorterDuffの機能を利用しています。
PorterDuffは、キャンバス上でBitmapの合成を可能にする機能です。
これによって、マスク画像と撮影画像に比較演算をおこない、撮影画像から人物領域を抜き出しています。
結果
撮影ボタンを押すと、下図のような画像が保存されます。
人物の領域だけ色が残っているのが分かるかと思います。

まとめ
今回はTensorFlow Liteのセグメンテーション処理をTHETA上でおこなう方法を紹介しました。
機械学習で撮影対象を認識し、対象ごとに異なる処理をかけることは最近のスマホアプリでもトレンドだと思いますが、カメラ単体で完結するのは珍しいと思いますので、ぜひ興味があればTHETAプラグイン、触ってみてください。
RICOH THETAプラグインパートナープログラムについて
THETAプラグインをご存じない方はこちらをご覧ください。
パートナープログラムへの登録方法はこちらにもまとめてあります。
QiitaのRICOH THETAプラグイン開発者コミュニティ TOPページ「About」に便利な記事リンク集もあります。
興味を持たれた方はTwitterのフォローとTHETAプラグイン開発コミュニティ(Slack)への参加もよろしくおねがいします。