ZUNDAMON ENGINE 5 爆誕

Unreal Engine (UE) Advent Calendar 2022 1日目です。
ネタです。
アンリアルエンジンを読み上げるずんだもん
— 荻野雄季 (@YuukiOgino) November 30, 2022
VOICEVOX:ずんだもん pic.twitter.com/usfRdJGDtT
とある日、日本酒を1合ぐらいキメた後に、UEのツールチップやチュートリアルが、ずんだもんの声ならやる気出るんじゃないか、と思ってVOICEVOX COREライブラリをUE5で読み込めないか調査したら、思ったよりもすんなり出来てしまったのでプラグインとして公開します。
品質は中品質にギリ届くかぐらいです。許してください。
成果物
まずは成果物です。
画像ではわかりくいので、以下の動画が成果になります。
ZUNDAMON ENGINE5 爆誕
— 荻野雄季 (@YuukiOgino) November 29, 2022
まぁ、ただ単純にずんだもんにツールチップの文言を読んでもらうだけなんですけどw
これが12/1のアドカレに書くネタです。 #UE5 pic.twitter.com/xUdIAXHRXg
11月上旬で思いついてノリで開発した割には動いているので、VOICEVOX COREは素晴らしいです。
プラグインはGithubに公開してます。
VoicevoxToolTipTextSpeechプラグイン
ZUNDAMON ENGINE 5 ことVoicevoxToolTipTextSpeechプラグインです。
ネタで作ったものです。そのため、大雑把に書いてます。
概要
NaotsunさんのSlateのテキストに無理やり(?)アクセスする方法で公開されたサンプルコードを、一部VOICEVOX COREのAPIを実行するように修正を加えたものになります。
対応プラットフォーム&エンジンバージョン
- Windows10(11は試してないですが、多分動きます。)
- UnrealEngine5.0
使い方
使い方の説明です。

ツールチップが表示されているときにキーボードのPボタンを押すと、ずんだもんのボイスでToolTipのテキストを読み上げます。
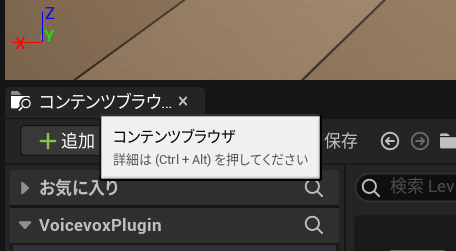
コンテンツブラウザ、とずんだもんの声で読み上げてくれます。
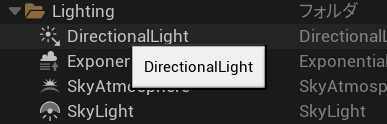
おまけに英語は読めないので、上記のようにほとんどの英単語はアルファベットの単語ごとでしゃべります。
UnrealEngineを読みあげるずんだもん。
— 荻野雄季 (@YuukiOgino) November 30, 2022
かわいいですね。
VOICEVOX:ずんだもん pic.twitter.com/NWoISUedCJ
ずんだもんのボイスなら許せそうですw
注意事項
見てわかる通り非常に無駄な機能で、ジョークグッズの類です。
ソースコードですがサンプルコードの9割弱そのまま利用させていただいたため再配布の形になるのと、サンプルコードにライセンス表記がなかったため、念のため一部自分が修正を加えたソースコードのみ公開しています。
そのため、配布したVoicevoxToolTipTextSpeechプラグインは必要なソースがごっそり抜けてるためビルドが通りません。
一応公開されたサンプルコードの一部を移植し、多少修正を加えれば動くと思うので興味があれば触ってみてください。
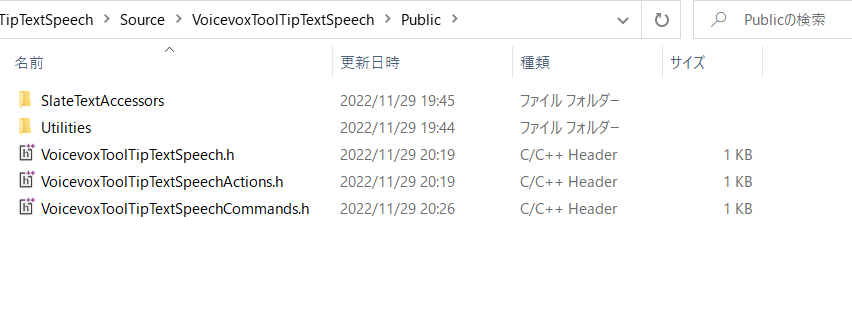
上記にあるSlateTextAccessorsフォルダとUtilitiesフォルダを移植、エラーが起きている部分を修正を行えば動くはずです。
VoicevoxToolTipTextSpeechプラグインに関してはサポートを行いません。
VOICEVOX Engine for UE5プラグイン
本題です。
VOICEVOX Engine for UE5プラグインについて説明です。
概要
VOICEVOX Engine for UE5プラグインはヒホさんが制作・公開されている、 VOICEVOX Engineの 非公式 UnrealEngine5対応版、VOICEVOX COREをUE5で使用するためのプラグインです。
とはいえ、現状ではVOICEVOX COREのAPIしかアクセスしかできませんが...、一応BlueprintノードでアクセスできるようにしたのでEngineと言い張りますw
対応プラットフォーム&エンジンバージョン
- Windows10(11は試してないですが、多分動きます。)
- UnrealEngine5.0
VOICEVOX COREライブラリはMac及びLinux対応済みなので、動作確認はしてませんが恐らく読み込めるとは思います。
動作確認したのがWindows10のみなので、公開版ではWindows以外を非対応としています。
開発中に5.1がリリースされてしまったので、こちらは勉強がてら対応します...。
プラグイン使用準備
最低限プラグインのビルドが自力で出来る、という前提で、他に必要なものを記載しています。
VOICEVOX CORE、Open JTalk、ONNX Runtime、の取得
VOICEVOX COREのReadMEに従って、最低限CPUモードの動作に必要なライブラリを取得します。
以下からVOICEVOXのCOREライブラリを取得してください。
プラグインはVOICEVOX CORE 0.13.2を元に開発しました。
上記からダウンロードしたコアライブラリの zip を、適当なディレクトリで展開します。
CUDA 版、DirectML版は、必ず対応しているCOREライブラリのzipファイルをダウンロードしてください。
次にOpen JTalk から配布されている辞書ファイル をダウンロードして、上記コアライブラリを展開したディレクトリに展開してください。
プラグインではopen_jtalk_dic_utf_8-1.11を使用しています。
続いてONNX Runtimeは以下からダウンロードしてください。
基本的に最新版で問題ないはずです。
もし、エラーが起きる場合はv1.13.1以前のバージョンで試してみてください。
VOICEVOX CORE Downloaderを利用してダウンロードする場合は、こちらを見てください。
現状、Downloaderは正常実行できない旨のアナウンスが出ているので、リリースノートからダウンロードしてください。
https://github.com/VOICEVOX/voicevox_core/issues/271
プラグインへ展開
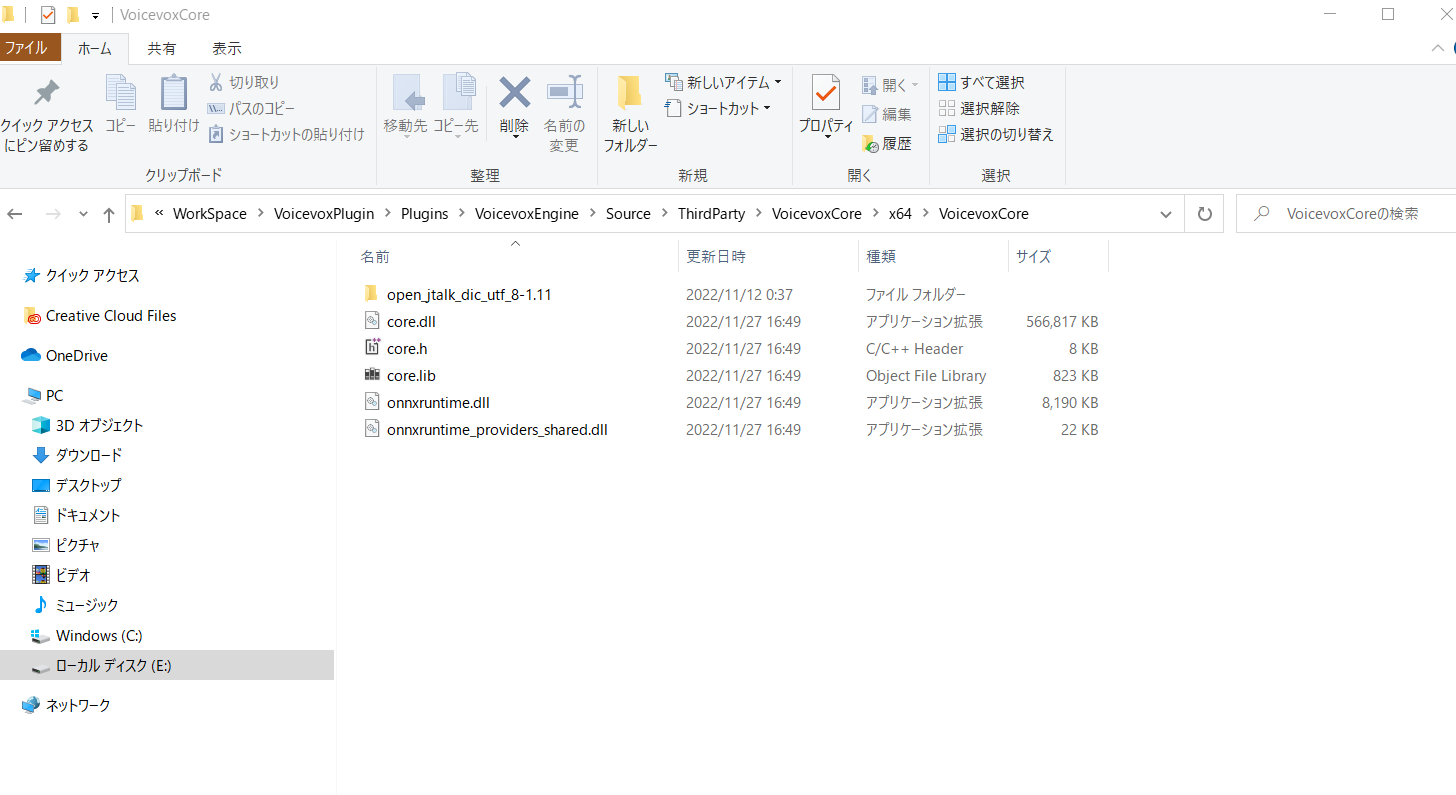
展開したCOREライブラリを、以下のフォルダに配置してください。
【プロジェクトフォルダ】\Plugins\VoicevoxEngine\Source\ThirdParty\VoicevoxCore\x64\VoicevoxCore
※格納例
あとはUEのプラグインビルドの方法にしたがってビルドを行ってください。
プラグインのビルドがわからない場合、公式ドキュメントを見たり、「UE5 プラグイン ビルド」で検索してください。
各ヘッダーファイルについて
プラグインに作成した各ヘッダーファイルの説明です。
cppファイルも公開しているので、セットで見てください。
-
VoicevoxCoreUtil.h
VOICEVOX COREのAPIへ接続するためのUtilクラスを記載しています。
C++で利用する場合はUtilから各VOICEVOX CORE APIを呼ぶことを想定しています。 -
VoicevoxAsyncTask.h
VOICE VOX COREのAPIを実行するBlueprint公開用ノードをまとめています。
大半のAPIが処理に時間がかかるため、ほとんどLatentノードにしています。
各クラスについて
各クラスの説明です。
主にC++でアクセスすることが多い、VoicevoxCoreUtilクラスを記載しています。
※実装例
// Copyright Yuuki Ogino. All Rights Reserved.
#include "VoicevoxToolTipTextSpeech.h"
#include "VoicevoxCoreUtil.h"
#if PLATFORM_WINDOWS
#include "Windows/WindowsHWrapper.h"
#include <playsoundapi.h>
#endif
#define LOCTEXT_NAMESPACE "FVoicevoxToolTipTextSpeechModule"
void FVoicevoxToolTipTextSpeechModule::StartupModule()
{
FVoicevoxCoreUtil::Initialize(false);
constexpr int SpeakerId = static_cast<int64>(ESpeakerType::Zundamon);
int OutputBinarySize = 0;
uint8* OutputWAV = FVoicevoxCoreUtil::RunTextToSpeech(SpeakerId, TEXT("アンリアルエンジン、ファイブ"), OutputBinarySize);
#if PLATFORM_WINDOWS
PlaySound(reinterpret_cast<LPCTSTR>(OutputWAV), nullptr, SND_MEMORY);
#endif
FVoicevoxCoreUtil::WavFree(OutputWAV);
}
void FVoicevoxToolTipTextSpeechModule::ShutdownModule()
{
FVoicevoxCoreUtil::Finalize();
}
#undef LOCTEXT_NAMESPACE
IMPLEMENT_MODULE(FVoicevoxToolTipTextSpeechModule, VoicevoxToolTipTextSpeech)
モジュールクラスに組み込むと起動時にボイスを再生してくれます。
C++でプラグインを使用する
Build.csのPublicDependencyModuleNames、もしくはPrivateDependencyModuleNamesに VoicevoxEngine を追加してください。
PublicDependencyModuleNames.AddRange(
new string[]
{
"Core",
"InputCore",
"CoreUObject",
"Engine"
}
);
PrivateDependencyModuleNames.AddRange(
new string[]
{
"VoicevoxEngine"
}
);
FVoicevoxCoreUtil::Initialize
VOICEVOX COERの初期化を行います。
VOICEVOX CORE APIのiniitialize~voicevox_load_openjtalk_dictを呼び出して初期します。
UE::Tasks::Launch(TEXT("VoicevoxCoreTask"), [&]()
{
if (FVoicevoxCoreUtil::Initialize(bUseGPU, CPUNumThreads, false))
{
// 成功時の処理を記述
}
else
{
// 失敗時の処理を記述
}
});
bUseGPUをtrueにするとGPUモードで初期化します。
GPU対応版のCOREライブラリ、かつ対応するGPU(nvidia製GPUを搭載したWindows, Linux PCではCUDA、DirectX12に対応したGPUを搭載したWindows PCではDirectML)がPCに組み込まれていれば使用できます。
GPU対応のCOREライブラリを読み込んでテストしたのですが、バージョン0.13.2でエラーでクラッシュ、もしくはGPUモードに切り替わらない現象を確認したため、当面の間はGPU切り替えは非対応とします。
bUseGPUは常にfalseを設定し、CPUモードで実行してください。
CPUのみのライブラリでbUseGPUをtrueにすると、エラーが返ってきます。
メインスレッドが止まる処理のため、上記の通り非同期で処理することを推奨しています。
こちらは何度も初期化処理を行って問題ないですが、text to speech実行時は最後に初期化した設定で行います。
FVoicevoxCoreUtil::Finalize
VOICEVOX COERの終了処理を行います。
VOICEVOX CORE APIのfinalizeを呼び出して終了処理を行っています。
FVoicevoxCoreUtil::Finalize();
こちらも何度も終了処理を行って問題ないですが、Finalizeを呼び出した後はtext to speechを実行しないようにしてください。
FVoicevoxCoreUtil::LoadModel
スピーカーIDを元にモデルのロードを行います。
VOICEVOX CORE APIのis_model_loaded、およびload_modelを実行しています。
重い処理のため、スピーカーモデルがロードされていない場合のみload_modelを実行します。
UE::Tasks::Launch(TEXT("VoicevoxCoreTask"), [&]()
{
if (FVoicevoxCoreUtil::LoadModel(SpeakerId))
{
// 成功時の処理を記述
}
else
{
// 失敗時の処理を記述
}
});
モデルによってはメインスレッドが止まるため、上記の通り非同期で処理することを推奨しています。
FVoicevoxCoreUtil::RunTextToSpeech
指定したSpeakerIdからtext to speechを実行します。
VOICEVOX CORE APIのvoicevox_ttsを呼び出してテキストから音声データを生成します。
UE::Tasks::Launch(TEXT("VoicevoxCoreTask"), [&]()
{
int OutputBinarySize = 0;
if (uint8* OutputWAV = FVoicevoxCoreUtil::RunTextToSpeech(SpeakerId, *Message, OutputBinarySize);
OutputWAV != nullptr)
{
#if PLATFORM_WINDOWS
PlaySound(reinterpret_cast<LPCTSTR>(OutputWAV), nullptr, SND_MEMORY);
#endif
FVoicevoxCoreUtil::WavFree(OutputWAV);
}
else
{
// 失敗時の処理を記述
}
});
メインスレッドが止まる処理のため、上記の通り非同期で処理することを推奨しています。
指定したSpeakerIdのモデルがロードされていない場合は、load_modelも一緒に行います。
戻り値はテキストを音声データに変換した結果コードです。
戻り値はFVoicevoxCoreUtil::WavFreeに渡して破棄する必要があります。
破棄しない場合はメモリリークする恐れがあります。
FVoicevoxCoreUtil::RunTextToSpeechFromKana
指定したSpeakerIdからAquesTalkライクな記法なtext to speechを実行します。
VOICEVOX CORE APIのvoicevox_tts_from_kanaを呼び出してAquesTalkライクなテキストから音声データを生成します。
例
ボク'ワ/ズ'ンダモン/ナノ'ダ
以下、記載ルールを引用します。
- 全てのカナはカタカナで記述される
- アクセント句は/または、で区切る。、で区切った場合に限り無音区間が挿入される。
- カナの手前に_を入れるとそのカナは無声化される
- アクセント位置を'で指定する。全てのアクセント句にはアクセント位置を 1 つ指定する必要がある。
- アクセント句末に?(全角)を入れることにより疑問文の発音ができる
※VOICEVOX ENGINE ReadMeより引用
AquesTalkライクな記法に適応していない文字を渡すとクラッシュするので注意してください。
UE::Tasks::Launch(TEXT("VoicevoxCoreTask"), [&]()
{
int OutputBinarySize = 0;
if (uint8* OutputWAV = FVoicevoxCoreUtil::RunTextToSpeechFromKana(SpeakerId, *Message, OutputBinarySize);
OutputWAV != nullptr)
{
#if PLATFORM_WINDOWS
PlaySound(reinterpret_cast<LPCTSTR>(OutputWAV), nullptr, SND_MEMORY);
#endif
FVoicevoxCoreUtil::WavFree(OutputWAV);
}
else
{
// 失敗時の処理を記述
}
});
メインスレッドが止まる処理のため、上記の通り非同期で処理することを推奨しています。
指定したSpeakerIdのモデルがロードされていない場合は、load_modelも一緒に行います。
戻り値はテキストを音声データに変換した結果コードです。
戻り値はFVoicevoxCoreUtil::WavFreeに渡して破棄する必要があります。
破棄しない場合はメモリリークする恐れがあります。
FVoicevoxCoreUtil::WavFree
VOICEVOX COERのvoicevox_ttsで生成した音声データを開放します。
VOICEVOX CORE APIのvoicevox_wav_freeを実行しています。
UE::Tasks::Launch(TEXT("VoicevoxCoreTask"), [&]()
{
int OutputBinarySize = 0;
uint8* OutputWAV = RunTextToSpeech::RunTextToSpeechFromKana(SpeakerId, *Message, OutputBinarySize);
#if PLATFORM_WINDOWS
PlaySound(reinterpret_cast<LPCTSTR>(OutputWAV), nullptr, SND_MEMORY);
#endif
// 最後に必ず呼び出す
FVoicevoxCoreUtil::WavFree(OutputWAV);
});
FVoicevoxCoreUtil::RunTextToSpeech、およびFVoicevoxCoreUtil::RunTextToSpeechFromKanaで取得したポインタは、使用しなくなったタイミングで必ずWavFreeを実行して破棄してください。
FVoicevoxCoreUtil::Metas()
スピーカーモデル名やスピーカーIDのリストを取得します。
文字列はJSON形式です。
FVoicevoxCoreUtil::Metas();
他のJSON変換コードを利用したい場合は、こちらのメソッドを利用してください。
FVoicevoxCoreUtil::MetaList()
スピーカーモデル名やスピーカーIDのリストを取得します。
TArray<FVoicevoxMeta> Metas = FVoicevoxCoreUtil::MetaList();
内部でMetasから取得したJSON文字列を、JsonUtilitiesモジュールでStructのTArrayへ変換しています。
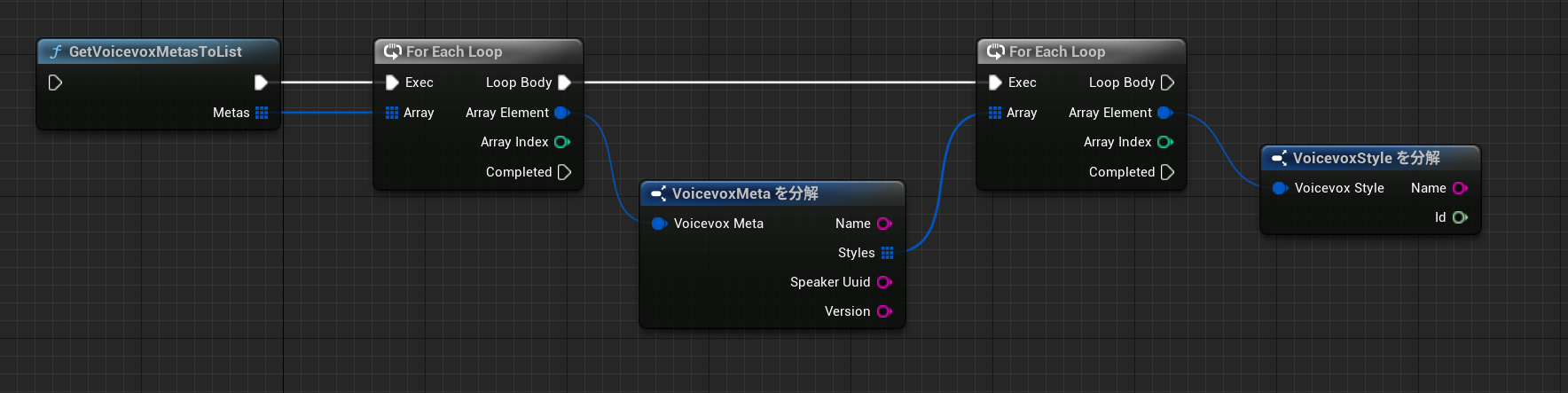
以下、戻り値のStructの中身です。
/**
* @struct FVoicevoxStyle
* @brief VOICEVOXのモデルスタイル情報構造体
*/
USTRUCT(BlueprintType)
struct FVoicevoxStyle
{
GENERATED_USTRUCT_BODY()
//! スタイル名
UPROPERTY(BlueprintReadOnly)
FString Name;
//! スピーカーID
UPROPERTY(BlueprintReadOnly)
int64 Id;
};
/**
* @struct FVoicevoxMeta
* @brief VOICEVOXのメタ情報構造体
*/
USTRUCT(BlueprintType)
struct FVoicevoxMeta
{
GENERATED_USTRUCT_BODY()
//! モデル名
UPROPERTY(BlueprintReadOnly)
FString Name;
//! スタイル情報リスト
UPROPERTY(BlueprintReadOnly)
TArray<FVoicevoxStyle> Styles;
//! スピーカーユニークID
UPROPERTY(BlueprintReadOnly)
FString Speaker_uuid;
//! バージョン情報
UPROPERTY(BlueprintReadOnly)
FString Version;
};
以下は、動作の確認が取れていないため正常動作は保証していません。
VOICEVOX Engineで主に使用するAPIですが、自分の理解が追い付いてなく必要最低限の確認しかとっていません。
FVoicevoxCoreUtil::GetPhonemeLength
音素列から、音素ごとの長さを求めます。
VOICEVOX COERのyukarin_s_forwardを実行しています。
渡した引数でクラッシュしない以外は確認を取っていないため、正常動作の保証はしていません。
FVoicevoxCoreUtil::FindPitchEachMora
モーラごとの音素列とアクセント情報から、モーラごとの音高を求めます。
VOICEVOX COERのyukarin_sa_forwardを実行しています。
渡した引数でクラッシュしない以外は確認を取っていないため、正常動作の保証はしていません。
FVoicevoxCoreUtil::DecodeForward
フレームごとの音素と音高から、波形を求めます。
VOICEVOX COERのdecode_forwardを実行しています。
渡した引数でクラッシュしない以外は確認を取っていないため、正常動作の保証はしていません。
Blueprint公開ノード
VoicevoxAsyncTask.hにBlueprint公開ノードを一通り実装しています。
C++に比べると最低限の機能確認程度になっていますが、スピーカーIDを指定してのテキストの音声読み上げに対応してます。
音声生成中のクラッシュが取り切れていないので、エディタプレイでVoicevoxSimplePlayTextToSpeechノードを実行した場合は、必ず最後まで再生させてから終了するようにしてください。
※実装例
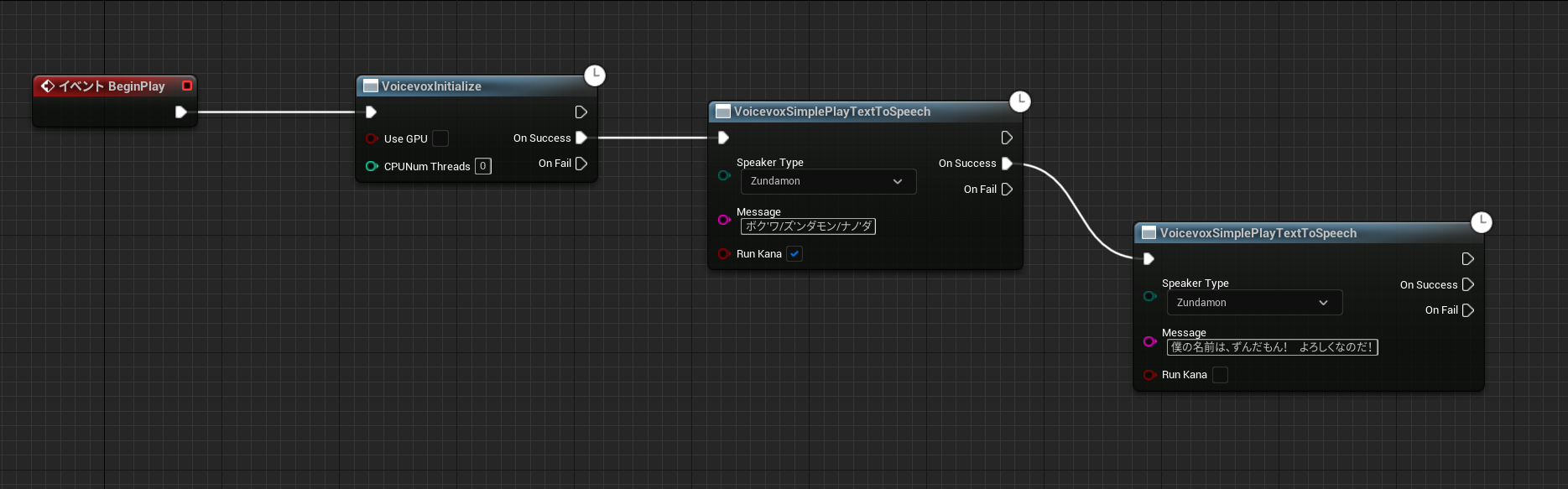
ノード説明
Blueprintに公開したノードの一通り説明を記載します。
VoicevoxInitializeノード
VOICEVOX COERの初期化を行います。
VOICEVOX CORE APIのiniitialize~voicevox_load_openjtalk_dictを呼び出して初期します。
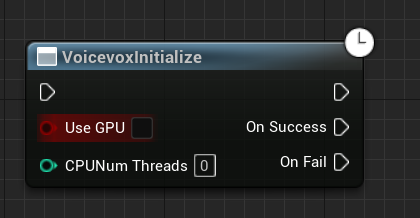
UseGPUをtrueにするとGPUモードで初期化します。
GPU対応版のCOREライブラリ、かつ対応するGPU(nvidia製GPUを搭載したWindows, Linux PCではCUDA、DirectX12に対応したGPUを搭載したWindows PCではDirectML)がPCに組み込まれていれば使用できます。
GPU対応のCOREライブラリを読み込んでテストしたのですが、バージョン0.13.2でエラーでクラッシュ、もしくはGPUモードに切り替わらない現象を確認したため、当面の間はGPU切り替えは非対応とします。
UseGPUは常にfalseを設定し、CPUモードで実行してください。
CPUのみのライブラリでUseGPUをtrueにすると、エラーがアウトプットログに表示されます。
こちらは何度もVoicevoxInitializeノードを行って問題ないですが、VoicevoxSimplePlayTextToSpeechノード実行時は最後に初期化した設定で行います。
VoicevoxLoadModelノード
スピーカーIDを元にモデルのロードを行います。
必ずVoicevoxInitializeノードを実行した後に呼び出してください。
VOICEVOX CORE APIのis_model_loaded、およびload_modelを実行しています。
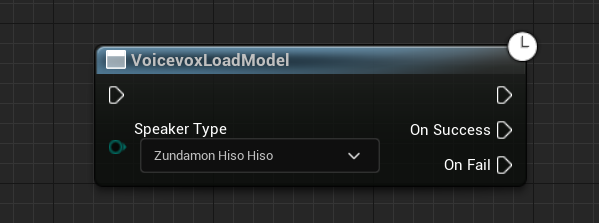
VoicevoxSimplePlayTextToSpeechノード実行前にあらかじめスピーカーモデルを読み込みたい場合に使用してください。
モデルデータを読み込まないでVoicevoxSimplePlayTextToSpeechノードを実行した場合より、ちょっとだけ処理が早くなります。
VoicevoxSimplePlayTextToSpeechノード
指定したSpeakerIdからtext to speechを実行します。
必ずVoicevoxInitializeノードを実行した後に呼び出してください。
VOICEVOX CORE APIのvoicevox_ttsを呼び出してテキストから音声データを生成し、再生を行います。
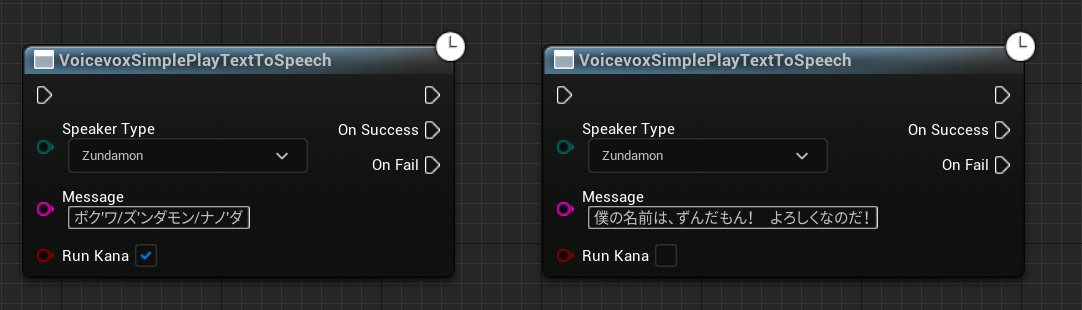
RunKanaにチェックを入れると、AquesTalkライクなテキストでないと変換できません。
再生は簡単にWindows APIのPlaySoundを呼び出してるだけです。
#if PLATFORM_WINDOWS
PlaySound(reinterpret_cast<LPCTSTR>(OutputWAV), nullptr, SND_MEMORY);
#endif
※C++でUEのサウンドキューに変換しようと思いましたが、わからなすぎて諦めました...
GetVoicevoxMetasToStringノード
VOICEVOXのMetasを取得します。
必ずVoicevoxInitializeノードを実行した後に呼び出してください。
戻り値はJSON文字列です。
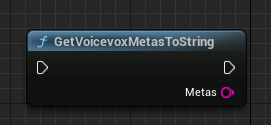
他のJSON変換プラグインを使用したい場合は、GetVoicevoxMetasToStringノードから文字列を取得して変換をしてください。
GetVoicevoxMetasToListノード
VOICEVOXのMetasを取得します。
必ずVoicevoxInitializeノードを実行した後に呼び出してください。
戻り値はJSON変換済みの構造体リストです。
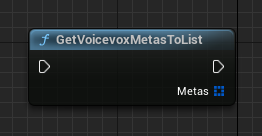
例として以下のようにForEachLoopで配列を回して使用します。
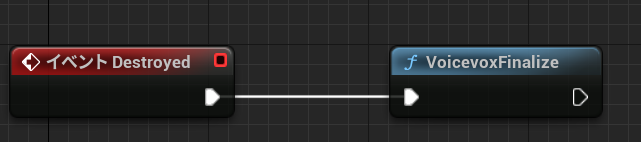
VoicevoxFinalizeノード
VOICEVOX CORE APIのfinalizeを呼び出して終了処理を行っています。
連続でVoicevoxFinalizeノードを行って問題ないですが、VoicevoxFinalizeノードを呼び出した後はVoicevoxInitializeノード以外はクラッシュしてしまうため、実行しないようにしてください。
VOICEVOX Engine for UE5プラグインが利用できる点
元々ネタとして開発したので正直、UEで直に使えるようにしたところでメリットが自分には思いつきません。
VOICEVOXで生成したボイスをゲームに利用したいなら、公式で公開されているVOICEVOX Editorで編集してWavファイルを生成し、UE5にインポートしたほうが早いしクオリティも良いです。
ノベルゲームやノベルパートでまだボイスを当てていないときのプロトタイプとして、一時的にVOICEVOXのキャラボイスを使ってイメージをつかむ、というぐらいですかねぇ...
何か面白いことを思いついたら、ライセンスと利用規約の範囲内でプラグインを面白おかしく使ってもらえれば幸いです。
注意点
もしネットワークでVOICEVOX Engine for UE5プラグインを使用する場合、デバッグ時はワンプロセスは無効にしてください。
クラッシュすると思います。
現在判明している不具合
-
COREのAPIを非同期で行った場合、特にRunTextToSpeechからの戻りを待たずにプレイ終了したり、続けてRunTextToSpeechを実行するとクラッシュします。
→この部分はどうしようか、現在模索中です。 -
パッケージングを行うとOpen JTalkフォルダのみコピーを失敗します。
→お手数ですが、パッケージング済みのフォルダにopen_jtalk_dic_utf_8-1.11フォルダを手動でコピーしてください。
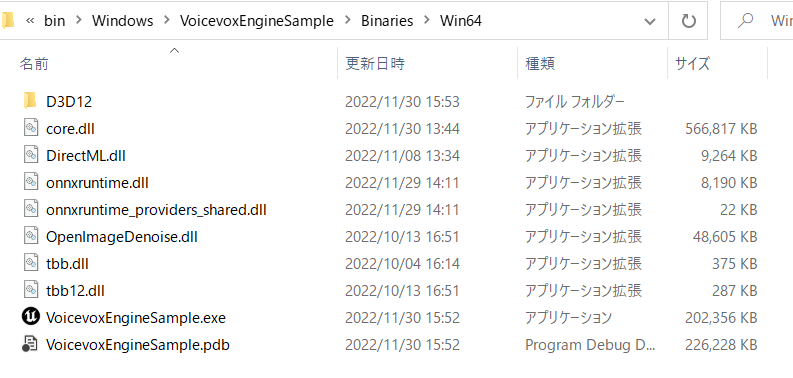
以下にコピーしてもらえれば動作します。
【パッケージング出力フォルダ名】\Windows\【プロジェクト名】\Binaries\Win64
- GPUモードに対応したCOREライブラリでGPUに切り替えるとエラー、もしくはクラッシュする
→こちら原因調査中です。
ライセンス
VOICEVOX ENGINEのライセンスを継承し、LGPL v3と、ソースコードの公開が不要な別ライセンスのデュアルライセンスとなります。
利用規約
VOICEVOX Engine for UE5の利用規約はVOICEVOXのホームページに記載された利用規約を継承するため、利用前に必ず一読してください。
各スピーカーモデルのライセンスはVOICEVOX公式ホームページのキャラクター一覧を参照してください。
VOCEVOXの利用規約及び各キャラクターの利用規約を厳守するようにお願いいたします
問い合わせに関して
VOICEVOX Engine for UE5プラグインに関して質問があれば、Twitter、Qiitaのコメント欄で聞いてもらうか、公開したGithubのissueに記載してください。
間違ってもVOICEVOX CORE作者のヒホさん、VOICEVOX公式Twitterアカウント及びVOICEVOX ホームページで、VOICEVOX Engine for UE5プラグインの問い合わせをしないようにお願いいたします。
今後について
個人では満足していますが、もしVOICEVOXのEditor部分をUEでも使えるようにしてほしい、という声が多ければEditor機能も開発するかもです。
後は非同期でCOREのAPIを実行するとクラッシュすることが多いので、安定化に繋がる方法を模索中です。
あと、VOICEVOX ENGINEの中身も移植しないとですね...。こちらはやる気があればやります。
まとめ
せっかく公開したので利用規約とライセンスを守ってVOICEVOX Engine for UE5プラグインを色々使ってあげてください。
プルリクも大歓迎です。
あと、C++のみでサウンドキュー、というかサウンドウェーブの動的生成ってどうやるんですかね...
音声データを生成したポインタをサウンドウェーブに変換して再生したい、と思ってはいますがどうやればいいのか悩んでます。
参考資料一覧
VOICEVOX Engine for UE5プラグイン開発に参考にした資料は以下の通りです。
- VOICEVOX CORE
- VOICEVOX ENGINE
- VOICEVOX ENGINE SHARP
- Node VOICEVOX Engine
- Slateのテキストに無理やり(?)アクセスする方法
- Tasks System
- UE5 Task Systemでお手軽な非同期処理! ※サンプルプロジェクト配布あり
※上記ブログのalweiさんも同じく1日目に記事を書いていますので、そちらもご覧ください。
クレジット
VOICEVOX
VOICEVOX:ずんだもん
ずんだもん立ち絵素材
(ず・ω・きょ)
明日は@koorinonakaさん、@g__skrさん、@O_Y_Gさんです。期待してます。