この記事では、GoogleColaboratoryのGPUを使用して、BERTのチュートリアルを行う方法を書いていきます。
学習済みモデルは、GoogleDriveに保存し、GoogleColaboratoryにドライブをマウントして使用します。
*注意
GoogleDriveに学習済みモデルがデータセットを保存するため、500MBの空きが必要です。
一度だけ試す場合は、GoogleDriveとGoogleColaboratory、を連携せず、GoogleColaboratoryのGPUインスタンス上にモデルやデータセットを保存する方が良いかもしれません。
*宣伝
新しく、BERTを用いて日本語文章の二値分類の記事と多値分類を行う記事を書きました。
次のステップとしてご利用ください。
Google Colaboratory上でBERTを使い、日本語文章の二値分類を行う
BERTを用いて、日本語文章の多値分類を行う
BERTのチュートリアル
BERTのGitHubリポジトリにあるチュートリアルを動かします。
BERTのGitHubはこちらです。
google-research/bert: TensorFlow code and pre-trained models for BERT
READMEにあるSentence (and sentence-pair) classification tasksとPrediction from classifierの内容をGoogle Colaboratory上で実行します。
上記のチュートリアルでは、Microsoft Research Paraphrase Corpus(MRPC)という文章の等価性(二つの文章の内容が等しいか)を評価するタスクを解いています。
それでは、さっそく実行してみましょう。
用意するもの
- Googleアカウント
のみです。
事前に、GoogleDriveとGoogleColaboratoryが使用できることを確認してください。
チュートリアルの実施
ここから、チュートリアルに沿ってMRPCのタスクを解いていきます。
内容を保存したColaboratory notebookを私のGitHubに公開していますので、ソースコードの方が理解しやすい方はそちらをご覧ください。
Yuu94/bert-tutorial: BERT tutorial at GoogleColaboratory (GPU)
(実行した番号や実行結果が残ったままなのはご了承ください。消し方がわかるかがいれば教えていただけたら...)
本チュートリアルは以下のような流れをとります。
- Colaboratory notebookの設定
- GoogleDriveをマウント
- データセット/BERT学習済みモデルをGoogleDriveへ保存
- BERTのリポジトリをClone
- trainデータを使用した、学習済みモデルのfine-tuning
- testデータを使用した、データ予測
- 予測結果(出力)の確認
最終的には、GoogleDrive上が以下のようなディレクトリ構成になります。
上手く読み込めない等の問題があれば、これを確認しながら作業してみてください。
マイドライブ/
└ bert/
├ uncased_L-12_H-768_A-12/ # 学習済みモデル
├ tmp/ # 出力ファイル
├ mrpc_output_result/
└ mrpc_output/
├ glue_data/ # データセット(MRPC)
└ MRPC/
├ bert/ # 公式リポジトリ
└ run_classifier.py
├ 60c2bdb54d156a41194446737ce03e2e/ # データセットDLスクリプト
└ download_glue_data.py
└ bert_tutorial.ipynb
それでは、各部分の説明をしていきます。
*これより先はColaboratory notebookでの操作になります。
Colaboratory notebookの設定
Colaboratory notebookでGPUを使用する設定を行います。
GoogleDrive側から、Colaboratory notebookを作成し、GoogleColaboratoryにアクセスができたら、ランタイム->ランタイムのタイプを変更を押してください。
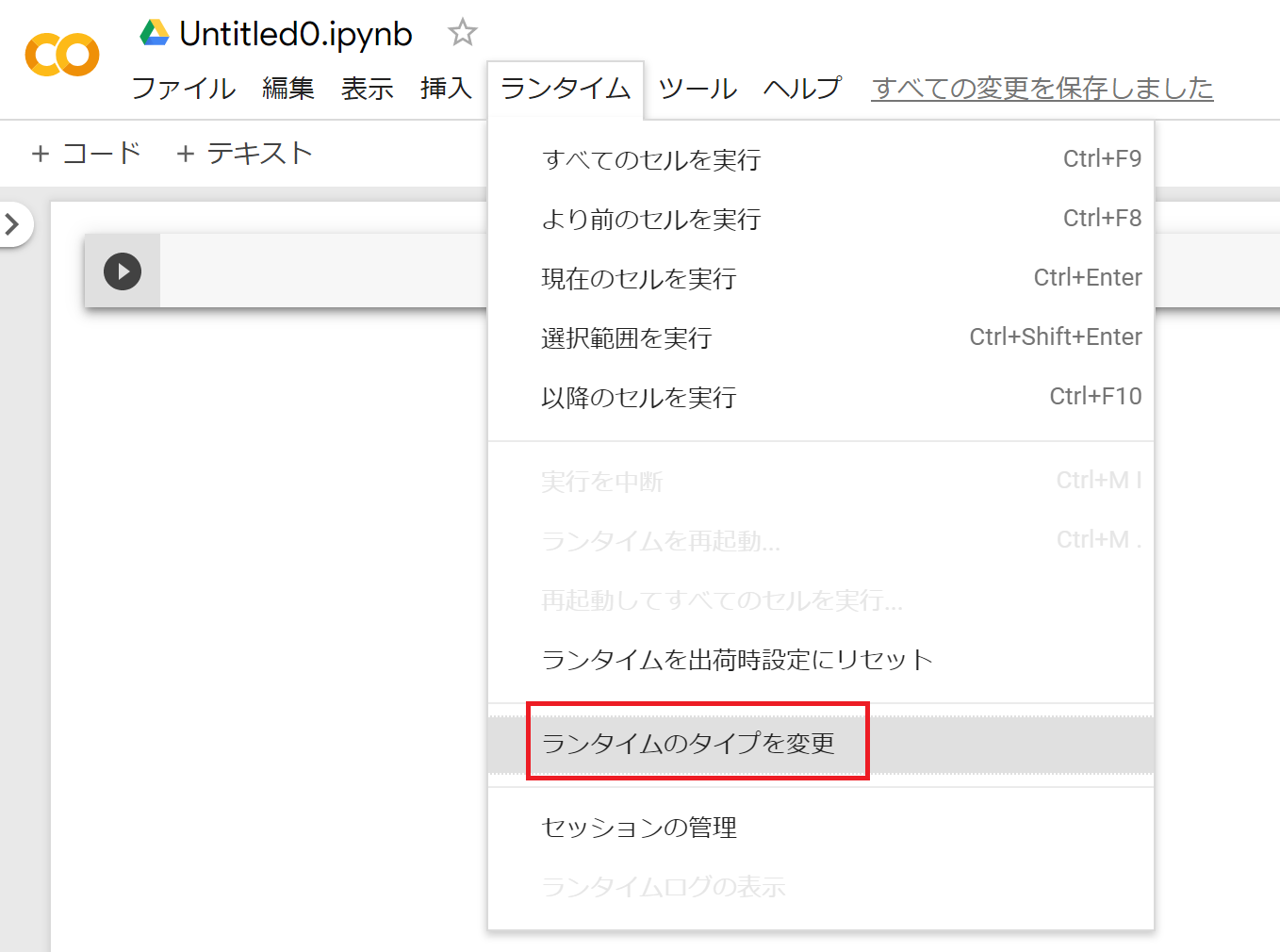
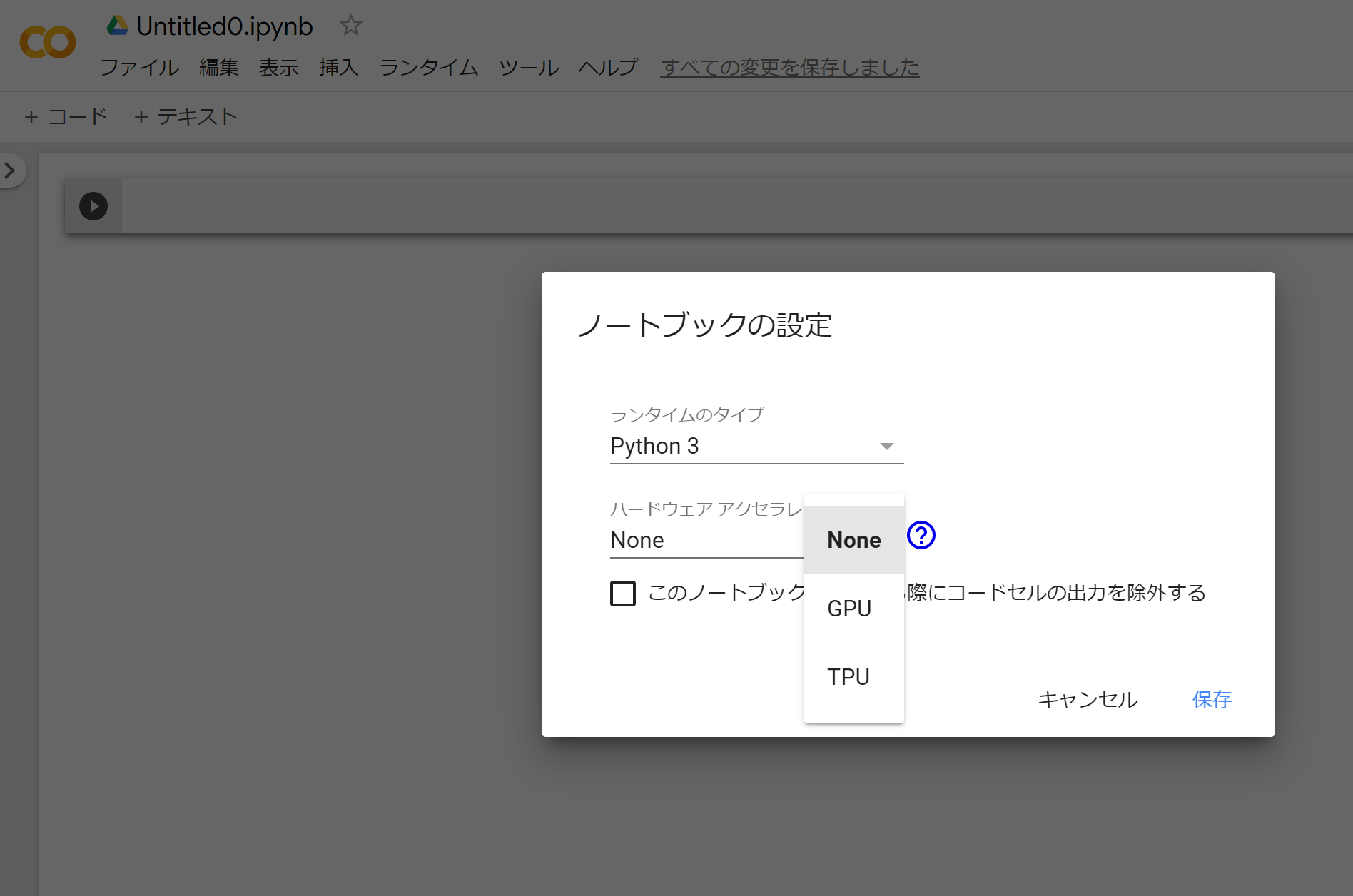
ノートブックの設定画面が出るので、ハードウェアのアクセラレータをGPUに変更し、保存を押します。
最後に、右上の接続を押し、RAM/ディスクになるまで待ちます。
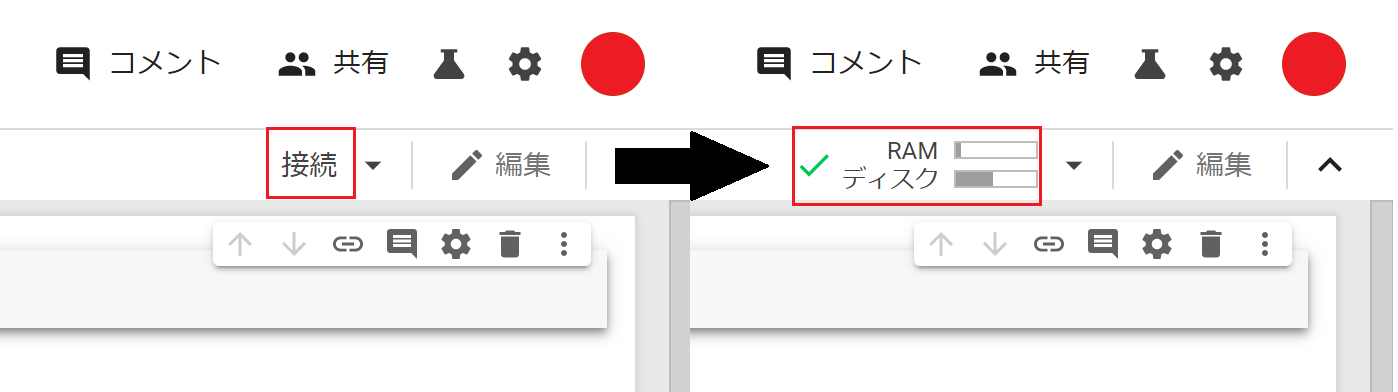
これで、GoogleColaboratoryでGPUを使用する準備が整いました。
GoogleDriveをマウント
以下のコードをColaboratory notebookに貼り付けてください。
from google.colab import drive
drive.mount('/content/drive')
出力にリンクが表示されるので、リンク先にアクセスし、GoogleDriveとGoogleColaboratoryの連携を許可してください。
その後、Enter your authorization code:下の入力窓にコード入れ、Enterを押してください。
マウントしたGoogleDriveに作業ディレクトリを移動します。
今回は、GoogleDriveの一番上位のディレクトリにbertというフォルダを作成し、この中で作業を行います。
以下のコマンドを1セルづつ入力し、実行します。
- 作業ディレクトリの作成
!mkdir drive/'My Drive'/bert
2.作業ディレクトリへ移動
cd drive/'My Drive'/bert
データセット/BERT学習済みモデルをGoogleDriveへ保存
データセットの保存
GoogleColaboratoryからプログラムを実行し、データセットを保存します。
チュートリアルでは、GLUE dataというデータセットが使用されていますので、これをGoogleDriveに保存します。
公式チュートリアルにて、使用を推薦しているプログラム(スクリプト)がありますので、そのプログラムを実行してデータセットを保存します。
以下のコマンドをセルで実行し、プログラムをGoogleDriveに保存します。
!git clone https://gist.github.com/60c2bdb54d156a41194446737ce03e2e.git
保存したプログラムを実行します。
!python 60c2bdb54d156a41194446737ce03e2e/download_glue_data.py \
--data_dir glue_data --tasks MRPC
--data_dir: 保存するディレクトリの名前
--tasks: 保存するタスク名(allで全てのタスク)
BERT学習済みモデルの保存
公式が公開している、BERTの学習済みモデルをGoogleDriveに保存します。
公開されている学習済みモデルは、複数存在しますが、このチュートリアルでは、BERT-Base, Uncasedを使用します。
以下のコマンドを実行して、GoogleDriveに保存します。
!wget https://storage.googleapis.com/bert_models/2018_10_18/uncased_L-12_H-768_A-12.zip && \
unzip uncased_L-12_H-768_A-12.zip && \
rm uncased_L-12_H-768_A-12.zip
公開している学習済みモデルの一覧は、GitHubのREADME - pre-trained-modelsにリンクがあります。
*Base/Largeは、BERT論文内の構造BaseまたはLargeを指しています。
*Uncasedは、英単語を小文字化して学習させたものです。
*日本語を含む多言語に対応したモデルはMultilingualが付いたものです。
TensorFlowのバージョン変更
本チュートリアルはTensorFlow 1系で動作するプログラムであるため、以下のコマンドを実行してTensorFlowのバージョンを1系に変更します。
デフォルトではTensorFlowは2系になっています。
%tensorflow_version 1.x
BERTのリポジトリをClone
今回のタスクは、BERTのリポジトリにあるrun_classifier.pyを実行して行います。
そのため、以下のコマンドを使用して、GoogleDriveにBERTのリポジトリをCloneします。
!git clone https://github.com/google-research/bert.git
trainデータを使用した、学習済みモデルのfine-tuning
3.で保存をした、データセット内のtrainデータとクローンしたrun_classifier.pyを使用して、学習済みモデルのfine-tuningを行います。
データセットの保存形式
今回保存したデータ形式は以下の様になっています。
- ファイル形式: TSV(Tab Separated Values)
- 1列目(Quality): 文1と文2に等価性があるか否か(0, 1)
- 2列目(#1 ID): 文1のID
- 3列目(#2 ID): 文2のID
- 4列目(#1 String): 文1
- 5列目(#2 String): 文2
TSVは、カンマで区切られたCSVに対して、タブで区切られた形式のファイルです。
MRPCは、文章の等価性を評価するタスクなので、ここでは、4列目の文1と5列目の文2の内容に等価性があるかを予測(1列目)します。
他のタスクを解く際に、train/testデータの形式を類似させることで、run_classifier.pyの改修を少なくすることができます。
他のファイルも似たような形式なので、ここでは説明を省きます。
学習済みモデルのfine-tuning
以下のコマンドを使用して、run_classifier.pyを実行し、fine-tuningを行います。
!python bert/run_classifier.py \
--task_name=MRPC \
--do_train=true \
--do_eval=true \
--data_dir=glue_data/MRPC \
--vocab_file=uncased_L-12_H-768_A-12/vocab.txt \
--bert_config_file=uncased_L-12_H-768_A-12/bert_config.json \
--init_checkpoint=uncased_L-12_H-768_A-12/bert_model.ckpt \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=2e-5 \
--num_train_epochs=3.0 \
--output_dir=tmp/mrpc_output/
オプション(引数)が多いですが、以下のような意味です。
- task_name: 解くタスクを指定
- MRPC: 2つのニュース記事の等価性を判定
- CoLa: 文章が文法的に正しいか判定
- MNLI: テキスト同士の関連性を判定
- XNLI: 翻訳系のタスク(?)
- do_train: 学習するか否か
- do_eval: 評価結果を表示するか否か
- data_dir: データセット(MRPC)のディレクトリPath
- vocab_file: 学習済みモデルの
vocab.txtのPath - bert_config_file: 学習済みモデルの
bert_config.jsonのPath - init_checkpoint: 学習済みモデルの
bert_model.ckpt.***のPath - max_seq_length: 最長トークンの長さ
- train_batch_size: 学習Batchサイズ
- learning_rate: 学習率
- num_train_epochs: エポック数
- output_dir: 結果出力先
fine-tuningが終了すると、出力の最終行に以下のようなものが出力されると思います。
INFO:tensorflow:***** Eval results *****
I0105 10:34:39.428679 140299170789248 run_classifier.py:923] ***** Eval results *****
INFO:tensorflow: eval_accuracy = 0.85294116
I0105 10:34:39.428822 140299170789248 run_classifier.py:925] eval_accuracy = 0.85294116
INFO:tensorflow: eval_loss = 0.4425803
I0105 10:34:40.041571 140299170789248 run_classifier.py:925] eval_loss = 0.4425803
INFO:tensorflow: global_step = 343
I0105 10:34:40.041978 140299170789248 run_classifier.py:925] global_step = 343
INFO:tensorflow: loss = 0.4425803
I0105 10:34:40.042183 140299170789248 run_classifier.py:925] loss = 0.4425803
これが評価結果です。
今回は、accuracyが0.85でした。
悪くなさそうなので、testデータを使用て予測します。
testデータを使用した、データ予測
先ほどのコマンドを実行すると、tmp/mrpc_output/にfine-tuning済みのモデルが出力されます。
これを使用して、testデータを予測します。
コマンドは以下のものを使用します。
!python bert/run_classifier.py \
--task_name=MRPC \
--do_predict=true \
--data_dir=glue_data/MRPC \
--vocab_file=uncased_L-12_H-768_A-12/vocab.txt \
--bert_config_file=uncased_L-12_H-768_A-12/bert_config.json \
--init_checkpoint=tmp/mrpc_output \
--max_seq_length=128 \
--output_dir=tmp/mrpc_output_result/
新しい部分または変更があったオプションの説明です。
- do_predict: 予測を行うか否か
- init_checkpoint: fine-tuning後のbert_model.ckpt.***のPath
- output_dir: 予測結果の出力先
予測結果は、tmp/mrpc_output_result/に出力されます。
予測結果(出力)の確認
GoogleDriveのbert/tmp/mrpc_output_result/に、test_results.tsvが出力されています。
- 1行目: Qualityが0の確率
- 2行目: Qualityが1の確率
これで、BERTを使用してMRPCのタスクを解くチュートリアルが完了しました。
次のステップ
今回使用した環境を使って、日本語文章の二値分類を試したいと思います。
以上、最後までお付き合いありがとうございました。
追記: GoogleColaboratory -> 設定 -> その他でコーギーモード/猫モードを有効にすると、まったく作業に集中できなくなることがわかりました。