今回開発したのがこちら。『教えて!ポイ活先生』
楽天、PayPay、dポイント、Vポイント、Pontaの5大経済圏の各種サービスのプレスリリースやキャンペーンページを定期的にスクレイピングして、リアルタイムで実施中のポイント高還元情報やお店のキャンペーンなどを集めることができるものになっております。
なかなかサービス横断的に色んなポイントの高還元情報を集めてきたり、PayPayや楽天などサービス側からではなく、キャンペーンをお店や自治体名から検索できるのは今まであまりなかったんじゃないかなと思って作りました。
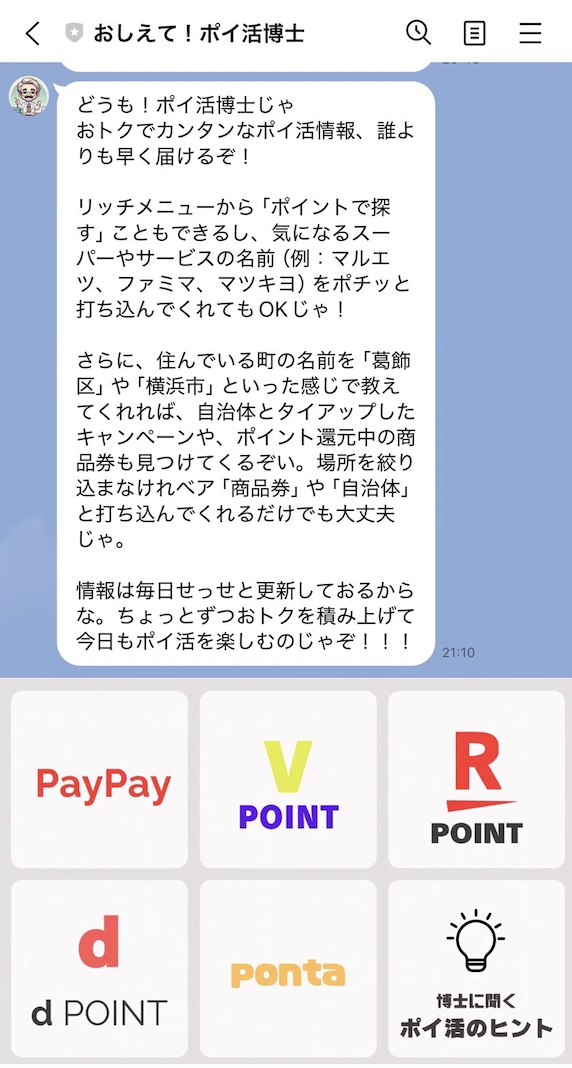
ここから友達追加できます。
使い方は簡単。
使い方
①リッチメニューからポイントで探す
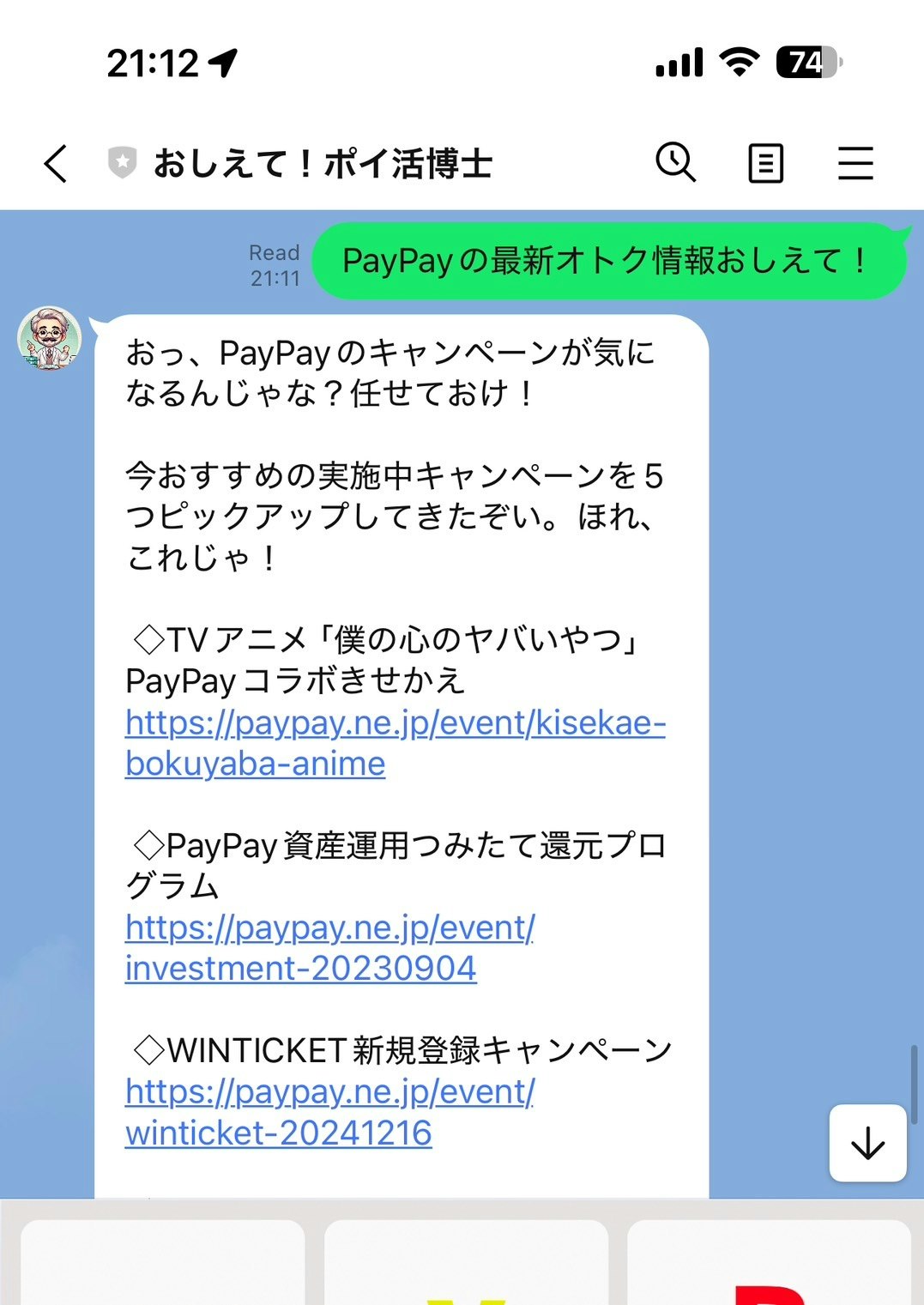
リッチメニューを押すとポイントからキャンペーンを探すことができます。ちなみに手動ですが「PayPayのすべて」「Pontaのすべて」「Vポイントのすべて」と打ち込んでくれれば全ての実施中のキャンペーンが取得できます(dポイントと楽天ポイントは量が多すぎた。)
②お店やサービス名で探す

例えば「マルエツ」「ローソン」「眼鏡市場」とか打ってくれれば、そのお店でやっているポイントキャンペーンを拾ってきます。
③住んでいる街から探す

例えば「葛飾区」「横浜市」とか打ってくれれば、その街・自治体やっているキャンペーンや商品券など拾ってきます。
④「商品券」「自治体」

なかなか場所を指定しても結果返ってこなかったりするので、「商品券」「自治体」とだけ打ってくれても、それぞれ場所を絞り込まず実施中のキャンペーンを拾ってきます。住んでいる自治体だけでなく、近場のキャンペーンとか拾ってくることができると思います。
⑤「博士に聞くポイ活のヒント」

これはおまけ要素です。ポイ活のお得豆知識を教えてくれます。パターンの数結構用意したので、おそらく全部出すのは結構時間がかかるはずです。これもいろいろな情報をスクレイピングしつつ集めたりしました。
作った動機
まず個人的な動機として、色んなポイントサービスを横断してオトク情報を取得するのって難しいなっていうのを日々感じていたので、年末年始の時間ある時に裏側のコードをまず組むことにしました。
ただインターフェースをアプリとかサイトにするよりかは、入り口をLINEっていう日常生活に密着しているものにして、そこから色々なポイントサービスの情報にアクセスできるのがいいかと思ってLineのAPIで作ることに。かつ欲しい情報を送ったら必要な情報だけ取ってくるっていうパーソナライゼーションもポイ活みたいな活動とは親和性が高いのかなと思ったのが、今回の仕様に落ちついた理由です。
あとLINEなので、淡々と返すだけよりもちょっと可愛いおじさんと擬似的にコミュニケーション取ってるような感じが面白いかな、みたいなところ。
開発
Line Messaging Api 部分
from flask import Flask, request, abort
from linebot import LineBotApi, WebhookHandler
from linebot.exceptions import InvalidSignatureError
from linebot.models import MessageEvent, TextMessage, TextSendMessage
import os
from dotenv import load_dotenv
from response_handler import generate_reply, generate_all_reply
from localpoint import search_local, search_gift, local_campaign
from search import search_campaign_by_name
from tips_handler import reply_tips
# 環境変数をロード
load_dotenv()
LINE_CHANNEL_ACCESS_TOKEN = os.getenv("LINE_CHANNEL_ACCESS_TOKEN")
LINE_CHANNEL_SECRET = os.getenv("LINE_CHANNEL_SECRET")
line_bot_api = LineBotApi(LINE_CHANNEL_ACCESS_TOKEN)
handler = WebhookHandler(LINE_CHANNEL_SECRET)
app = Flask(__name__)
@app.route("/callback", methods=["POST"])
def callback():
signature = request.headers["X-Line-Signature"]
body = request.get_data(as_text=True)
# デバッグ用ログ
print(f"Request body: {body}")
print(f"Signature: {signature}")
try:
handler.handle(body, signature)
except InvalidSignatureError:
abort(400)
return "OK"
@handler.add(MessageEvent, message=TextMessage)
def handle_message(event):
user_message = event.message.text
reply_message = "" # 初期化
if len(user_message) < 2:
reply_message = """お、何か聞きたいことがあるのか。\n\nそれならリッチメニューから「ポイントで探す」こともできるし、気になるスーパーやサービスの名前(例:マルエツ、ファミマ、モスバーガー)をポチッと打ち込んでくれてもOKじゃ!\n\nさらに住んでいる町の名前を打ってくれれば、自治体とタイアップしたキャンペーンやポイント還元中の商品券も探してくるぞ。「商品券」とただ打ち込んでくれるだけでもよいのじゃ。さぁ今日もお得にポイ活を楽しむのじゃよ"""
elif "豆知識" in user_message:
reply_message = reply_tips()
elif "すべて" in user_message:
reply_message = generate_all_reply(user_message)
elif user_message.endswith(("市", "区", "町", "村")):
reply_message = search_local(user_message)
elif "自治体" in user_message:
reply_message = local_campaign()
elif "商品券" in user_message:
reply_message = search_gift()
# キーワードが含まれる場合(楽天、PayPayなど)
elif any(keyword in user_message for keyword in ["楽天", "PayPay", "paypay", "Vポイント", "dポイント", "ponta"]):
reply_message = generate_reply(user_message)
# それ以外の場合
else:
reply_message = search_campaign_by_name(user_message)
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text=reply_message)
)
if __name__ == "__main__":
port = int(os.getenv("PORT", 5000)) # HerokuのPORT環境変数を取得
app.run(host="0.0.0.0", port=port)
スクレイピングで一番難しかったのが、dポイント。というのもサイトが、Javascriptで動的に生成されてる上に、記事のidなども動的にアクセスするたびに変わるんです。かつ全部見るには「もっと見る」ボタンでexpandする形になってて、それも色んな方法試したのですが、うまい具合に情報を綺麗に取ってくることはできませんでした。(なぜかリンクだけとれてタイトルが取れなかったり、途中で切り上げちゃったり)
スクレイピング部分
from selenium import webdriver
from selenium.webdriver.support.ui import Select
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
def fetch_dpoint_campaign_data():
# ChromeDriverの設定
driver = webdriver.Chrome()
# URLにアクセス
url = "https://dpoint.docomo.ne.jp/campaign/index.html"
driver.get(url)
results = [] # 結果を格納するリスト
try:
# タブをスクロールしてクリック可能にする
second_tab = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#selectSecond"))
)
driver.execute_script("arguments[0].scrollIntoView();", second_tab) # 要素までスクロール
time.sleep(1) # 少し待つ
driver.execute_script("arguments[0].click();", second_tab) # JavaScriptでクリック
# セレクトボックスで2番目のオプションを選択
select = Select(second_tab)
select.select_by_index(1) # 2番目のオプション
time.sleep(10) # コンテンツがロードされるまで待つ
for i in range(1, 51):
selector = f"#dpc_campaign_item_{i:03} > div.campaign_detail > div.campaign_title > p"
link_selector = f"#dpc_campaign_item_{i:03d}"
period_selector = f"#dpc_campaign_item_{i:03d} > div.campaign_detail > p"
try:
# 要素を取得
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, selector))
)
# 要素のテキストを取得
text = element.text
link_element = driver.find_element(By.CSS_SELECTOR, link_selector)
link = link_element.get_attribute("href")
period_element = driver.find_element(By.CSS_SELECTOR, period_selector)
period = period_element.text
# リスト形式で追加
results.append([f"dポイント", text, link, period])
except Exception as e:
print(f"Item {i}: 要素が見つかりませんでした({e})")
finally:
# ブラウザを閉じる
driver.quit()
# 結果をリスト形式で出力
print(results)
return results
工夫した場所
dポイントサイト以外は実施中のキャンペーンしかないのでスクレイピングするたびに上書きすればいいのですが、dポイントに関しては新着の情報を確実に取れる上位50件だけ取るようにして、それまでにスクレイピングしたものもどんどんスタックしていくものの、日付でみて過去分は削除するというコードを組みました。
def filter_campaigns_in_json(filename):
today = datetime.today().date()
try:
with open(filename, "r", encoding="utf-8") as file:
data = json.load(file)
filtered_data = []
for campaign in data:
if campaign[0] == "dポイント":
# 日付のフォーマットを分解し、終了日を取得
try:
date_range = campaign[3] # "2025/01/04 〜 2025/02/16" の形式
end_date_str = date_range.split("〜")[1].strip() # 終了日を取得
end_date = datetime.strptime(end_date_str, "%Y/%m/%d").date()
# 終了日が今日以前ならスキップ、それ以外は追加
if end_date >= today:
filtered_data.append(campaign)
except Exception as e:
print(f"Error processing campaign: {campaign}, Error: {e}")
return filtered_data
except FileNotFoundError:
print(f"ファイル {filename} が見つかりませんでした。")
return []
except json.JSONDecodeError:
print(f"ファイル {filename} の内容が正しいJSON形式ではありませんでした。")
return []
そうやって取ってきたスクレイピングの情報(jsonファイルに落としてます)をフィルタリングしているのが下記のコードになります。
import random
from import_json import campaigns_list
from textwrap import dedent
def generate_reply(user_message):
"""
ユーザーのメッセージに応じた返信を生成する。
"""
def format_campaign_response(platform_name, campaign_url):
# 条件に応じたメッセージの準備
header = f"おっ、{platform_name}のキャンペーンが気になるんじゃな?任せておけ!\n"
overview = "今おすすめの実施中キャンペーンを5つピックアップしてきたぞい。ほれ、これじゃ!\n"
#footer = f"\n\nもし『{platform_name}のすべて』と打ち込んでくれれば、ワシが全部のキャンペーンをここにズラッと並べてやるからのう。\n\nスーパー名や自治体名でも探せるから、気軽に聞いてくれい!\n\n"
# footer に条件を追加
if platform_name in ["PayPay", "Vポイント","Ponta"]:
footer = f"\n\nもし『{platform_name}のすべて』と打ち込んでくれれば、ワシが全部のキャンペーンをここにズラッと並べてやるからのう。\n\nスーパー名や自治体名でも探せるから、気軽に聞いてくれい!\n\n\n"
else:
footer = "\n\nさらに知りたい情報があれば、気軽に聞いてくれい!\n\n"
# キャンペーン選択
#"if "すべて" in user_message:
#selected_campaigns = [c for c in campaigns_list if c[0] == platform_name]
selected_campaigns = random.sample(
[c for c in campaigns_list if c[0] == platform_name],
min(5, len([c for c in campaigns_list if c[0] == platform_name])),
)
# キャンペーンのフォーマット
campaign_text = "\n\n".join([f" ◇{c[1]}\n{c[2]}" for c in selected_campaigns])
campaign_text += f"\n\n\n\n ⚫︎{platform_name}の全てのキャンペーンはこちら:\n {campaign_url}\n"
# 応答メッセージの組み立て
return dedent(f"""
{header}
{overview}
{campaign_text}
{footer}
""").strip()
# 各プラットフォームに応じた応答を返す
if "PayPay" in user_message or "paypay" in user_message:
return format_campaign_response("PayPay", "https://paypay.ne.jp/event/")
elif "楽天ポイント" in user_message:
return format_campaign_response("楽天ポイント", "https://pointcard.rakuten.co.jp/campaign/")
elif "Vポイント" in user_message:
return format_campaign_response("Vポイント", "https://cpn.tsite.jp/list/all")
elif "dポイント" in user_message:
return format_campaign_response("dポイント", "https://dpoint.docomo.ne.jp/campaign/index.html")
elif "Ponta" in user_message or "ponta" in user_message:
return format_campaign_response("Ponta", "https://point.recruit.co.jp/point/?tab=campaign")
# 何も該当しない場合の応答
return "申し訳ないが、そのメッセージに関連するキャンペーン情報は見つからんかったぞい!また別の質問をしてみてくれい。"
これは自治体や商品券用のコード。末尾が「市・区・町・村」の時に条件分岐して下記の関数を呼び出しているのですが、楽天市場、眼鏡市場、都市ガス、都市電気というキーワードが入ってるとおかしな挙動をしてしまうので、exclueded_keywordに入れて除外するようにしてます。
from import_json import campaigns_list
def search_local(user_message):
# 入力に基づくキャンペーン検索
result = [
[campaign[0], campaign[1], campaign[2]] # キャンペーン名、詳細、リンクを抽出
for campaign in campaigns_list
if user_message in campaign[1]
]
# フォーマット結果
if result:
formatted_results = "\n".join(
[
f"\n・{campaign[0]}: {campaign[1]}\n{campaign[2]}"
for campaign in result
]
)
return f"おっ、{user_message}ではこんなキャンペーンがあるようじゃぞ!これは活用せん手はないのう。詳細や条件はリンクからしっかり確認してくれい!:\n\n{formatted_results}"
else:
return f"おっ{user_message}について知りたいんじゃな?ちょっと待っとれ\n\n……ふむふむ、調べてみたが、今のところ自治体と提携したキャンペーンや商品券は見当たらんようじゃ。残念じゃのう。\n\nとはいえ、最近は大きな自治体を中心にこういったキャンペーンが増えてきとるから、定期的にチェックするのが吉じゃぞ!\n\nちなみに「自治体」と打ってくれれば今実施中の自治体キャンペーンを送ってやるぞ"
def search_gift():
# 商品券に関するキャンペーン検索
results = [campaign for campaign in campaigns_list if "商品券" in campaign[1]]
if results:
formatted_results = "\n".join(
[f"\n\n・{campaign[0]}: {campaign[1]}\n{campaign[2]}" for campaign in results]
)
return f"お、自治体商品券についてじゃな。\n\n調べてみたところ、今は下記のものが実施中じゃ{formatted_results}"
else:
return "お、自治体商品券についてじゃな。しかし、現在該当するキャンペーンは見つからなかったぞ。"
def local_campaign():
excluded_keywords = ['楽天市場', '眼鏡市場', '都市電気', '都市ガス']
related_campaigns = [
[campaign[0], campaign[1], campaign[2]]
for campaign in campaigns_list
if any(keyword in campaign[1] for keyword in ['市', '区', '町', '村'])
and all(excluded not in campaign[1] for excluded in excluded_keywords)
]
if related_campaigns:
formatted_related = "\n".join(
[
f"\n\n・{campaign[0]}: {campaign[1]}\n{campaign[2]}"
for campaign in related_campaigns
]
)
return f"おっ、自治体でやっておるキャンペーンについて知りたいんじゃな?ちょっと待っとれ\n\n……ふむふむ、今は下記のものが実施中じゃ{formatted_related}"
スーパーやサービス名で絞り込む用のコード
rom import_json import campaigns_list
def search_campaign_by_name(keyword):
"""
キーワードに基づいてキャンペーンを検索し、結果をポイントごとに整形して返す。
"""
# 条件に一致するキャンペーンを抽出
result = [
[campaign[0], campaign[1], campaign[2]] # ポイント名、キャンペーン名、リンクを抽出
for campaign in campaigns_list
if keyword in campaign[1] # キャンペーン名にキーワードが含まれるかチェック
]
# 結果がある場合
if result:
# ポイント名ごとに分類
campaigns_by_point = {}
for campaign in result:
point_name = campaign[0]
if point_name not in campaigns_by_point:
campaigns_by_point[point_name] = []
campaigns_by_point[point_name].append(campaign)
# メッセージを整形
formatted_results = []
for point_name, campaigns in campaigns_by_point.items():
#formatted_results.append(f"\n- {point_name}-")
formatted_results.extend(
[f"\n\n『{campaign[1]}({point_name})』\n{campaign[2]}" for campaign in campaigns]
)
return f"おっ、『{keyword}』に関連するキャンペーンを探しておるのか?\n\nふむふむ……おおっ、こんなのが見つかったぞい!これは見逃せんぞい!" + "\n".join(formatted_results)
else:
return f"""……ん?残念ながらその名前ではキャンペーン情報は見つからんのう。ワシはポイントサイトや色んな会社の公式情報を参考にしておる。\n\n融通が利かなくて申し訳ないのじゃが正式名称じゃないとワシは認識できないのじゃ。ひらカナを変えたり、他のやり方で試せば出せるかもしれん。\n
ちなみに、自治体商品券を探すなら、末尾に『市・区・町・村』をつけてくれると助かるぞい。ワシも頑張って探してみるから、また声をかけてくれのう!"""
かいつまんでコードを説明しましたが、全コードは下記に入ってます。