本記事は、2024年7月発売の書籍「つくりながら学ぶ!生成AIアプリ & エージェント開発入門」をベースに、私なりにGoogle Colabで動作する「生成AIエージェント」を実装してみた内容の解説です

上記の書籍「つくりながら学ぶ! 生成AIアプリ & エージェント開発入門」(発売日 2024/7/18) [link]、著者:ML_Bear(本名: 内田 直孝)さん
を参考にしながら、自分なりにいろいろ変更を加えてみて実装してみました。
Google ColaboratoryのNotebookファイルは以下となります。
本記事では今回作成してみたプログラムについて解説します。
拙著である、「つくりながら学ぶ!PyTorchによる発展ディープラーニング」などと、装丁が似ているようにも感じる?のは、マイナビ出版の(私がとても信頼している)同じ編集者の方がこちらの書籍もご担当してくださっているためです
[1] 実装したプログラムの概要
今回の実装は、本書で紹介されているエージェント実装の1例目、第9章「インターネットで調べ物をしてくれるエージェントを作ろう」を参考にしました。
書籍の内容をそのまま写経して実装してみるのも良い学びですが、それではQiitaの記事として公開できないので、大きく以下の2点の変更を加えました。
-
変更点1 : Google Colaboratory上で動作するようにする
-
変更点2 : LangChainのAgentExecutorと同じ動作をするように、LangGraphのReactAgentExecutorを対比しながら実装する
本記事のサマリー図は以下の通りです
書籍内容の侵害とならないよう、プログラムの重要部分のみピックアップしながら実装を解説します。
[2] LLM-Agent にさせたいこと
今回LLM-Agent(生成AIエージェント)にさせたい内容は、「User(私)が質問した内容に対して、ネット上のページを検索して、質問への回答文章を生成する」 という、調べ物作業です。
Agentととして実装するにはあまりに単純ですが、入門の第一歩としては、ほど良いレベルです。
具体的な処理の流れは以下の通りです。
- user(私)が質問文を入力する
- Agentは「ToolのSearch」でWeb検索する際に使用する検索ワードを適切に選ぶ
- 「Search Tool」を利用して、検索上位のページのURLや本文の冒頭を取得する
- AgentはSearch結果に応じて、本文全体を取得するWebページを決める
- 「Fetch Tool」を利用して、Webページの本文を取得する
- 質問の回答に十分な情報が集まっていなければ「2.」 に戻る
- 質問の回答に十分な情報が集まれば、Agentは回答文を生成する
このような動作をする、LLM-Agentを実装しました。
それでは以下より、実装解説に入ります。
[3] 2つのToolの作成
最初にLLM-Agentが使用可能な、機能?道具?である、「Tool」を関数として実装し、用意します。
AgentはこのToolを使用しても良いですし、使用しなくても良いです。
利用するかどうかは、Agentが状況に応じて判断してくれます。
[3-1] Search Toolの実装
Webサーチには書籍の実装の通り、「DuckDuckGo」を使用しました。
@toolデコレータをつけた関数をAgentはToolとして使用可能になりますが、その際、この関数の「docstring」(関数の冒頭のコメントでの関数内容の説明)が非常に重要です。
そこで今回は、関数冒頭のコメント内容を書籍とは変更し、自分なりのプロンプトにしてみます。Searchのメインは以下の通りです。
@tool(args_schema=SearchDDGInput)
def search_ddg(query, max_result_num=5):
"""
## Toolの説明
本ToolはDuckDuckGoを利用し、Web検索を実行するためのツールです。
## Toolの動作方法
1. userが検索したいキーワードに従ってWeb検索します
2. assistantは以下の戻り値の形式で検索結果をuserに回答します
## 戻り値の形式
Returns
-------
List[Dict[str, str]]:
- title
- snippet
- url
"""
# [1] Web検索を実施
res = DDGS().text(query, region='jp-jp', safesearch='off', backend="lite")
# [2] 結果のリストを分解して戻す
return [
{
"title": r.get('title', ""),
"snippet": r.get('body', ""),
"url": r.get('href', "")
}
for r in islice(res, max_result_num)
]
Tool系の関数は、関数冒頭のコメント(docstring)部分が最終的にLLMのSystem Promptに統合されて、LLMは対話の回答生成時にToolを使用することになる仕組みと、私は昔ライブラリコードを読んだ際に認識しています(最新版でも同じであろうか?)
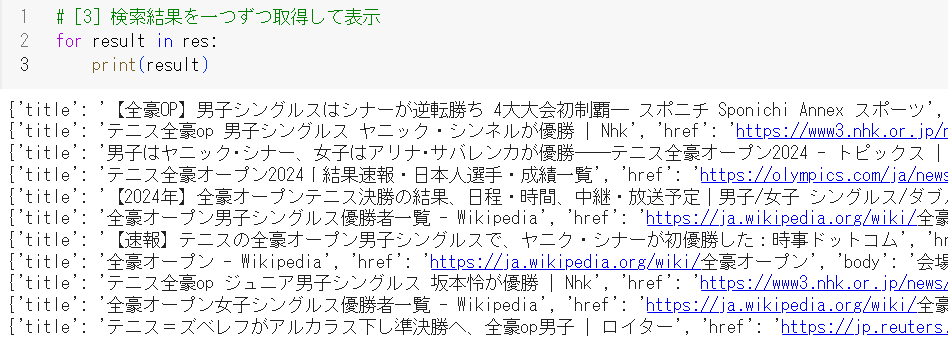
続いて「人力」でこのTool関数がどのように動作するのか、確認・検証しておきます。
# [1] 検索文章
query_ddg = "2024年全豪オープンテニスの男子シングルスって誰が優勝した?"
# [2] DuckDuckGoを人力で動かして?、検索
res = DDGS().text(query_ddg, region='jp-jp', safesearch='off', backend="lite")
# [3] 検索結果を一つずつ取得して表示
for result in res:
print(result)
質問文は書籍内でも使用されている、
「2024年全豪オープンテニスの男子シングルスって誰が優勝した?」 です。
結果は以下の図の通りです。
Webページの「title」、「href」、「bodyの冒頭」が取得できています。
この検索を、人(User)がタイミングと検索ワードを決めて実行するのではなく、LLM-Agentによしなに勝手に実行してもらいたい です。
[3-2] Fetch Toolの実装
こちらのTool関数のdocstring(コメント文)も自分なりに書籍から変更して作ってみます。
Fetch部分について、書籍の実装と本記事の違いですが、書籍ではWebページの本文が長くてもきちんと全文を取得できるように、chunk分けを実施しています。
本記事では簡易実装として、本文の冒頭3,000文字を取得することにして、厳密に全文取得をしていません。メイン部分は以下となります。
@tool(args_schema=FetchPageInput)
def fetch_page(url, page_num=0, timeout_sec=10):
"""
## Toolの説明
本Toolは指定されたURLのWebページから本文の文章を取得するツールです。
詳細な情報を取得するのに役立ちます
## Toolの動作方法
1. userがWebページのURLを入力します
2. assistantはHTTPレスポンスステータスコードと本文の文章内容をusrに回答します
## 戻り値の設定
Returns
-------
Dict[str, Any]:
- status: str
- page_content
- title: str
- content: str
- has_next: bool
"""
# [1] requestモジュールで指定URLのWebページ全体を取得
try:
response = requests.get(url, timeout=timeout_sec)
response.encoding = 'utf-8'
except requests.exceptions.Timeout:
return {
"status": 500,
"page_content": {'error_message': 'Could not download page due to Timeout Error. Please try to fetch other pages.'}
}
# [2] HTTPレスポンスステータスコードが200番でないときにはエラーを返す
if response.status_code != 200:
return {
"status": response.status_code,
"page_content": {'error_message': 'Could not download page. Please try to fetch other pages.'}
}
# [3] 本文取得の処理へ(書籍ではtry-exceptできちんとしていますが、簡易に)
doc = Document(response.text)
title = doc.title()
html_content = doc.summary()
content = html2text.html2text(html_content)
# [4] 本文の冒頭を取得
chunk_size = 1000*3 #【chunk_sizeを大きくしておきます】
content = content[:chunk_size]
# [5] return処理
return {
"status": 200,
"page_content": {
"title": title,
"content": content, # chunks[page_num], を文書分割をやめて、contentにします
"has_next": False # page_num < len(chunks) - 1
}
}
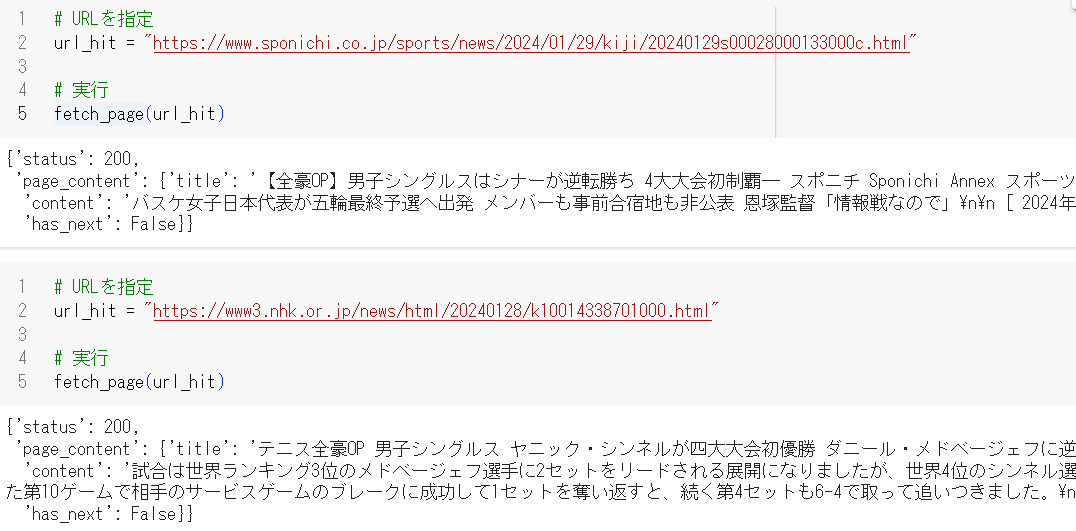
続いて「人力」でこのTool関数がどのように動作するのか、確認・検証しておきます。
さきほどのSearchでヒットした1件目と2件目のURLに対して実行してみます
# URLを指定
url_hit = "https://www.sponichi.co.jp/sports/news/2024/01/29/kiji/20240129s00028000133000c.html"
# 実行
fetch_page(url_hit)
結果は以下の通りです。contentが取得した本文を示しています。
1件目の結果は、ページ内のメインの本文とは関係ない部分を取得してしまっています。
2件目の結果は、本文をうまく取得できているようです。
LLM-Agentが利用するToolを用意できたので、あとはAgentのクラスを作成し、これらのToolをよしなに使用させます。
最初に書籍で紹介・解説されている、LangChain Agent を使用したLLM-Agentを作成してみます。
[4] Agent(LangChain Agent)の実装
[4-1] Agentのシステムプロンプトを作成
まずはAgentのSystem Promptを記述します。
このプロンプト内容に従ってAgentは動作するので、非常に重要な部分です。
こちらも書籍とは違う文章を自分で作成してみます(なお書籍の文章よりも非常に短い内容にしています)
CUSTOM_SYSTEM_PROMPT = """
## あなたの役割
あなたの役割はuserの入力する質問に対して、インターネットでWebページを調査をし、回答することです。
## あなたが従わなければいけないルール
1. 回答はできるだけ短く、要約して回答してください
2. 文章が長くなる場合は改行して見やすくしてください
3. 回答の最後に改行した後、参照したページのURLを記載してください
"""
Prompt Engineeringについて
私がこれまで趣味でいろいろとLLMモデルを触っていて感じるのは、LLMモデルによってプロンプトの良し悪し、好みが変わるという点です(望んだ動作が実現できるかが変わる)。
GPT系、Claude系、Llama系はもちろんですが、「GPT-3.5 Turbo」と「GPT-4」でもかなり違うと認識しています。
具体的には、GPT-3.5≒初期ChatGPTの頃のプロンプトは冗長すぎて、GPT-4レベルの場合はもっと簡素に書いた方が、よしなにうまく動いてくれる、という印象です。
GPT-3.5の頃は「何をやらせたいか」をプロンプトに記述するのが良い傾向(に感じていました)が、GPT-4レベルになると、やらせたいことは大雑把で、「何はやってほしくないか、どんなルールに従って欲しいか」を丁寧に記述する方が良い動作になる感触を持っています。
「GPT-3.5 Turbo」と「GPT-4」では良いプロンプトの書き方は違うと思うのですが、世の中のプロンプトの書き方参考情報は、「ChatGPTが登場し、皆がPrompt Engineeringに没頭した、GPT-3.5世代プロンプト」の情報やひな型が多いです。
書籍でも著者が解説してくださっていますが、LLMのモデルを変える場合は、いろいろなPrompt内容を試すのが重要だと感じています
以上で、Agentに実行してもらいたいお仕事内容を記述したSystem Promptが完成したので、続いてAgent本体を実装します
[4-2] langchain.agents AgentExecutorの実装
実装は以下の通りです。
最初にSystem Promptを含む、プロンプトを動的に扱ってくれるChatPromptTemplateを使用して変数promptを作成します。
ChatPromptTemplateの詳細については、書籍の解説をご覧ください。
ここで、MessagesPlaceholder(variable_name="agent_scratchpad")とは、Agentが自身の思考と行動とその結果を格納する場所です(Reactアルゴリズムで動作します)
from langchain.agents import AgentExecutor, create_tool_calling_agent
from langchain_core.prompts import MessagesPlaceholder, ChatPromptTemplate
def create_agent():
# [1]、[2]で定義したAgentが使用可能なToolを指定します
tools = [search_ddg, fetch_page]
# プロンプトを与えます。ChatPromptTemplateの詳細は書籍本体の解説をご覧ください。
# 重要な点は、最初のrole "system"に上記で定義したCUSTOM_SYSTEM_PROMPTを与え、
# userの入力は{input}として動的に埋め込むようにしている点です
# agent_scratchpadはAgentの動作の途中経過を格納するためのものです
prompt = ChatPromptTemplate.from_messages([
("system", CUSTOM_SYSTEM_PROMPT),
# MessagesPlaceholder(variable_name="chat_history"), # チャットの過去履歴はなしにしておきます
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad")
])
# 使用するLLMをOpenAIのGPT-4o-miniにします(GPT-4だとfechなしに動作が完了してしまう)
llm = ChatOpenAI(temperature=0., model_name="gpt-4o-mini")
# Agentを作成
agent = create_tool_calling_agent(llm, tools, prompt)
return AgentExecutor(
agent=agent,
tools=tools,
verbose=True, # これでAgentが途中でToolを使用する様子が可視化されます
# memory=st.session_state['memory'] # memory≒会話履歴はなしにしておきます
)
(注意)実装途中のコメントは私が記入しており、誤りがあった場合は書籍ではなく、私の問題です。
今回はLLMモデルには、早速?、GPT-4o-mini を使用してみることにしました。
[4-3] AgentExecutorの実行
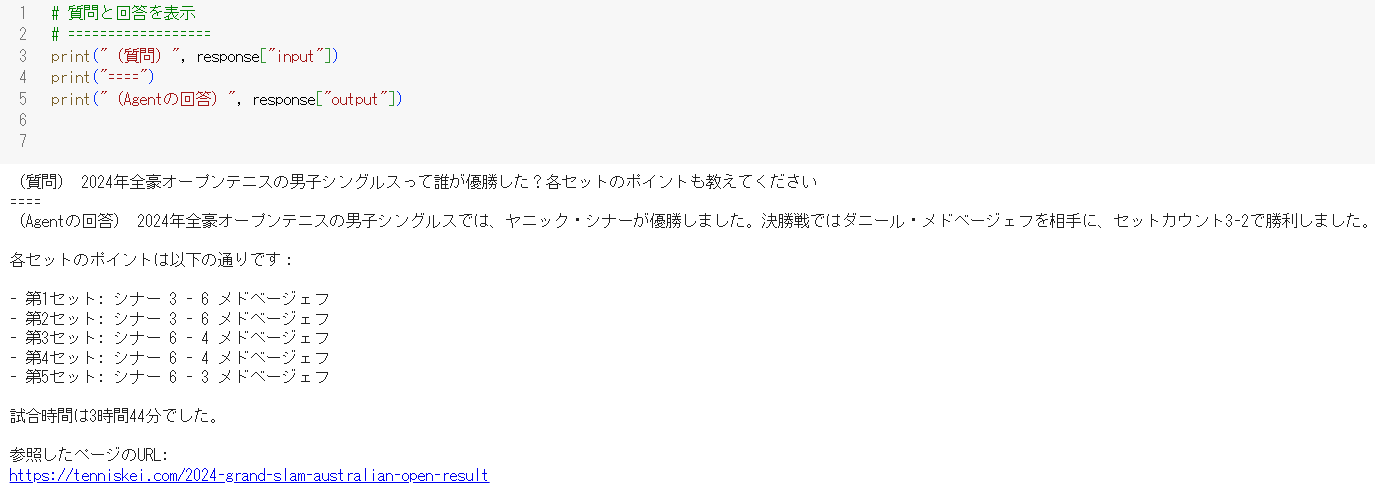
それではAgentを動作させます。
質問は最初の質問に少し文章を加えて、
「2024年全豪オープンテニスの男子シングルスって誰が優勝した?各セットのポイントも教えてください」
としました。
※(注意)実行してみても以下と同じような結果にならない場合、何度か実行し直してみてください。
LLMのTempretureは0.にしていますが、結果は毎回少し変化します
# [1] Agentを作成
web_browsing_agent = create_agent()
# [2] 質問文章
query_ddg = "2024年全豪オープンテニスの男子シングルスって誰が優勝した?各セットのポイントも教えてください"
# [3] エージェントを実行
response = web_browsing_agent.invoke(
{'input': query_ddg}, # userの入力に上記の質問を入れる
)
動作している途中の様子を以下の図に示します。
最初に「Search Tool」を検索ワード「2024年全豪オープンテニス 男子シングルス 優勝者 各セットのポイント」で利用して結果を求めていることが分かります。

上記図から、次にAgentは「Fetch Tool」を利用して、https://www.sponichi.co.jp/s・・・から本文を求めていることが分かります。
このURLの記事は最初の「DuckDuckGo」でのSearch結果1件目と同じなので、今回の実装でのFetchでは、うまく必要な本文が求まりません。
するとAgentは次に検索ワードを少し変えてSearchを再度実施し、別ページをFetchして、最終的に回答を生成しました
このようにAgentは、与えたToolをよしなに使用し、回答生成に十分だと判断できれば、よしなに終了して、最終回答文を生成してくれます。
(なお、たまFetchがなく、Searchだけで回答完了になる場合があります)
以下がAgentが最終的に生成した回答文となります。
なお、本記事での実装は単にprint文出力しているだけですが、書籍ではStreamlitを使用した、カッコよいUIで出力されています。
[5] Agent(LangGraph Agent)の実装
[5-1] LangGraph Agentについて
LangChainコミュニティでは、Agent作成の際、LangChain Agentを使用するのではなく、LangGraph Agentを使用するように移行しつつあります。
LangGraph Agentの場合はグラフ(的)な感じで、ノードにAgentやToolを設定し、AgentやMulti-Agentの動作を実装します。
厳密にはグラフではない(と私は認識している)のですが、グラフ的な扱い方をすることで、AgentのTool使用や、Agent間通信、Agentと人間のインタラクションなどの複雑なEvent類?を、統一的に扱い、そして循環的に処理できるので(実装側でWhileやfor文で制御する必要がなくなるため)、LangGraphへと移行しつつあります。
ただし、本書籍にも、そして私が知る限り他の日本語サイトにも、
「LangChainでのReact-Agent」と「LangGraphでのReact-Agent」で同じ動作内容の具体例でAgent実装を対比した解説を見たことがありません。
そこで本記事では、先ほどの[4]のLangChainのAgentExecutorと同じ動作をするように、LangGraphのReactAgentExecutorを対比させながら実装します。
【参考にしたLangGraphの公式サイト部分】
上記の以外に、
npakaさんの記事
そして、電通総研のAITC(AIトランスフォーメーションセンター)の後藤さんの記事
がとても参考になりました。
それでは実装へ。
[5-2] System PromptとToolについて
System PromptとTool関数は、LangChain用に作成する場合と同じとなります。
そのため、本記事でここまでに作成したものを再使用します。
Agentクラスは変更です。
[5-3] langgraph.prebuild ReactAgentExecutorの実装
LangGraphではグラフを自身で細かく定義します。
各ノードにAgentやToolやを定義していくのですが、PrebuildとしてReactAgentが用意されているので、今回はこちらのAgentを使用して実装します。
なお、LangGraphの場合、Agentへのプロンプトの渡し方は3種類ほどあるのですが(このように柔軟性が高い)のですが、今回はLangChainの実装と対比するために、先ほどと同様に、ChatPromptTemplate.from_messagesで変数promptを作成します。
from langgraph.prebuilt import create_react_agent
from langchain_core.prompts import MessagesPlaceholder, ChatPromptTemplate
from langchain_core.messages import AnyMessage
# プロンプトを定義
prompt = ChatPromptTemplate.from_messages([
("system", CUSTOM_SYSTEM_PROMPT), # [3] で定義したのと同じシステムプロンプトです
("user", "{messages}")
# MessagesPlaceholder(variable_name="agent_scratchpad") # agent_scratchpadは中間生成物の格納用でしたが、LangGraphでは不要です
])
# LangGraphではGraph構造で全体を処理するので、stateを変化させノードが移るタイミングで、promptを(会話やAgentの自分メモ)を進めるように定義します
def _modify_messages(messages: list[AnyMessage]):
return prompt.invoke({"messages": messages}).to_messages()
# ReactAgentExecutorの準備
# modelとtoolsは[3]と同じものを使用します
tools = [search_ddg, fetch_page]
llm = ChatOpenAI(temperature=0, model_name="gpt-4o")
# 【2024年8月3日現在では、modelにgpt-4o-miniを使用すると日本語ではうまく動作してくれません】そのため、gpt-4oを使用
web_browsing_agent = create_react_agent(llm, tools, state_modifier=_modify_messages)
# 変数名はgraphや、appを使用しているケースもあります
変数名をLangChainのAgentと同じものに合わせたので、何が何に変わったのか分かりやすいかと思います。
注意点としては、「GPT-4o-mini」では日本語の質問に対してうまく動作できませんでした(文字化け、encodeミスがLangGraph内部の途中で発生しています)
そのためGPT-4oをLLMに使用しています。
LangGraphのLLM-Agentにおいては、state_modifierの概念が非常に重要です。
NodeのStateが変更される前に、何をするのか(今回は各ToolやAgentの回答文を生成させる)を定義します。
LangChain Agentとは異なり、ChatPromptTemplate.from_messagesの
MessagesPlaceholder(variable_name="agent_scratchpad")
は使用しません。
LangChain Agentの場合はここに思考や行動の結果を特別扱いして格納していきましたが、LangGraphでは各ノード(Agent)のmessageに格納されます。
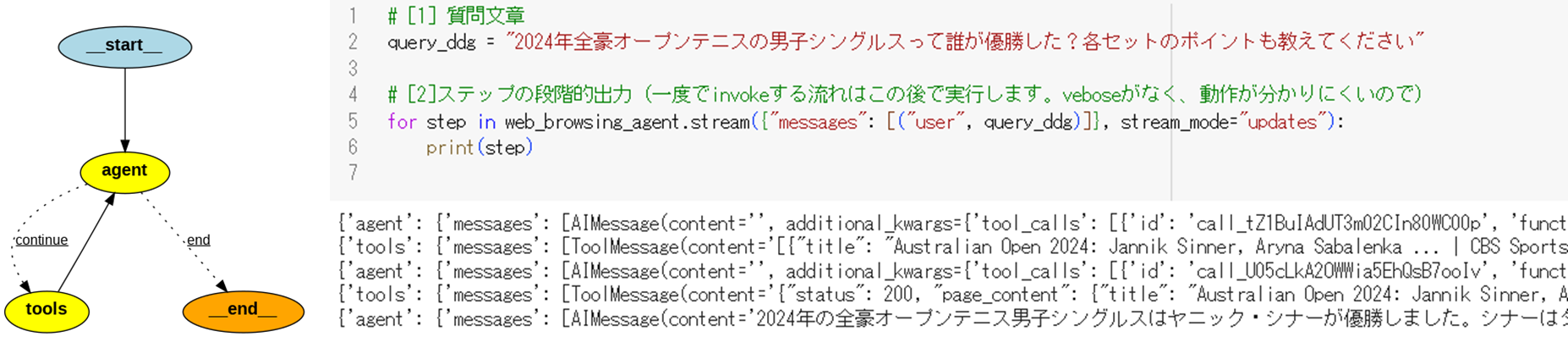
[5-4] LangGraph AgentExecutorの実行
それでは早速動作させます。
LangChainのときと同様に、invokeで動作させても良いのですが、途中経過が分かりづらいため、最初は各stepごとに動作させては出力させます。
# [1] 質問文章
query_ddg = "2024年全豪オープンテニスの男子シングルスって誰が優勝した?各セットのポイントも教えてください"
# [2]ステップの段階的出力(一度でinvokeする流れはこの後で実行します。veboseがなく、動作が分かりにくいので)
for step in web_browsing_agent.stream({"messages": [("user", query_ddg)]}, stream_mode="updates"):
print(step)
出力は以下のようになります。
(注意)毎回同じ動作・出力にはならないため、うまく行かない場合は何度か試してみて下さい
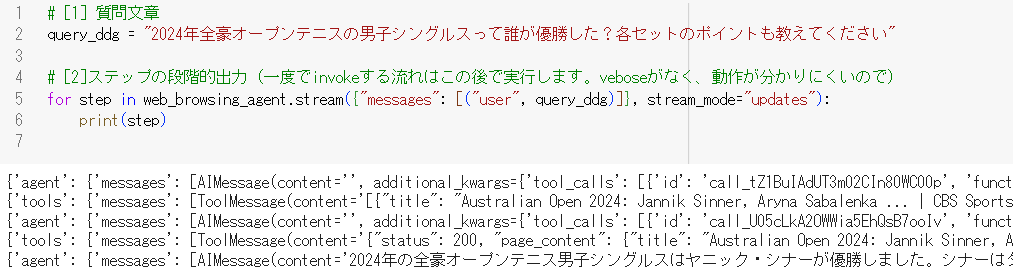
上図の出力から、
- AgentがTool(Search)を使用し、
- Tool(Search)が結果を返し、
- AgentがTool(Fetch)を使用し、
- Tool(Fech)が結果を返し、
- Agentが最終回答を生成した
という流れが分かります。
続いてはinvokeで動作させてみます。
LangChain Agentとは、引数の形が少し異なります。
また、回答文を取り出す際も変数messagesのtypeにAIノード、Humanノード、Toolノードと複数種類のノードタイプがあるので、人間(Human)とLLM(AI)の出力文章(content)のみを出力させます。
# [3] エージェントをinvokeで実行(invokeのあとの変数の入れ方が少し異なります)
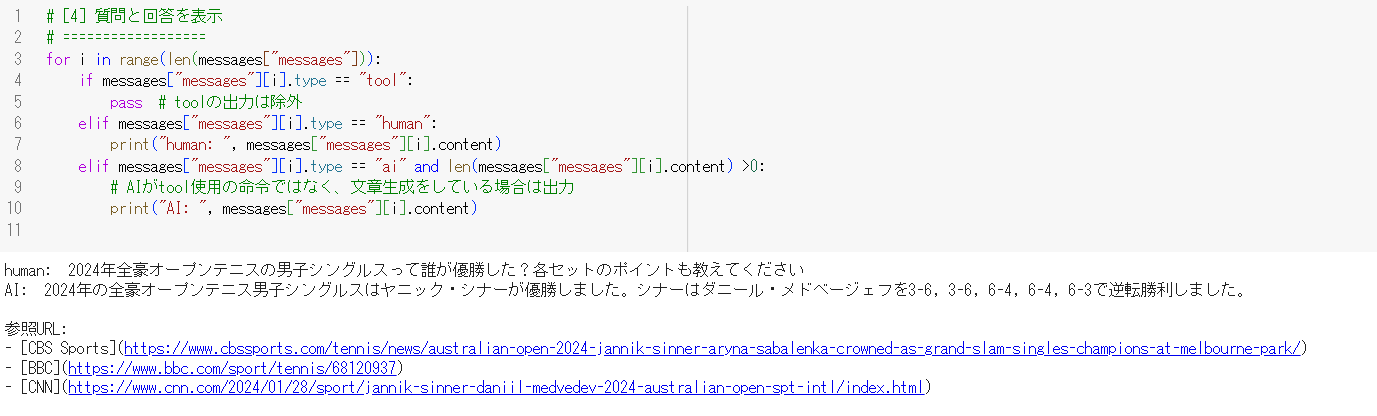
messages = web_browsing_agent.invoke({"messages": [("user", query_ddg)]})
# 変数名はresponseではなく、messagesが使用されます
# [4] 質問と回答を表示
# ==================
for i in range(len(messages["messages"])):
if messages["messages"][i].type == "tool":
pass # toolの出力は除外
elif messages["messages"][i].type == "human":
print("human: ", messages["messages"][i].content)
elif messages["messages"][i].type == "ai" and len(messages["messages"][i].content) > 0:
# AIがtool使用の命令ではなく、文章生成をしている場合は出力
print("AI: ", messages["messages"][i].content)
Agentとのやりとりの結果は以下の通りです。
以上で、LangChain版AgentをLangGraph版Agentに置き換えることができました。
[5-5] LangGraph Agentのグラフ構造を可視化
せっかくLangGraphでAgentを構築したので、そのグラフ構造、各ノードを確認すべく、グラフを可視化してみましょう。
create_react_agent関数の戻り値はLangGraph型であるCompiledGraphなので、すぐにグラフ描画できます。
# 参考:https://github.com/langchain-ai/langgraph/blob/main/examples/persistence.ipynb
from IPython.display import Image, display
# 描画
display(Image(web_browsing_agent.get_graph().draw_png()))
もしくは
# 描画
display(Image(web_browsing_agent.get_graph().draw_mermaid_png()))
により、普通のグラフの図、もしくはmermaidでの図が以下のように描画されます。
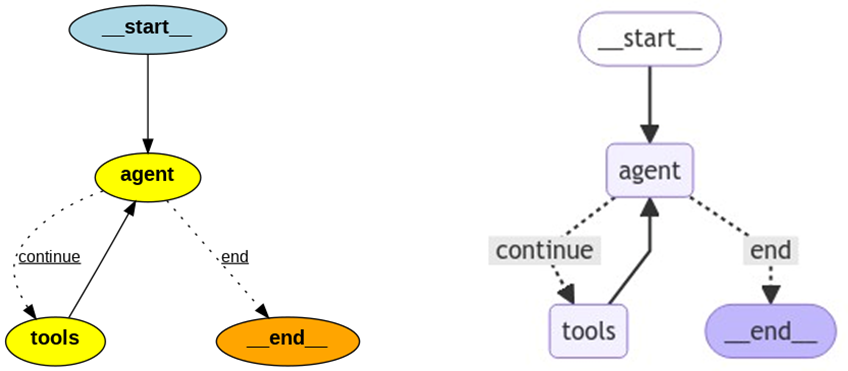
グラフを見ると、まず開始状態(start ノード)から始まり、Agentがtoolsを使用し続けて、終了条件(end)を満たせば、end ノードに移るという構造が描画されています。
Agentにやってもらっている内容がシンプルなので仕方ないのですが、ちょっと簡素なグラフですね。
Multi-Agentのケースや、独自のグラフ構造を作成した場合などに、この可視化機能は役立つと思います。
[6] さいごに
今回は、書籍:「つくりながら学ぶ! 生成AIアプリ & エージェント開発入門」(発売日 2024/7/18) [link]、著者:ML_Bear(本名: 内田 直孝)さん
の書籍を読んで学習し、1つだけですが、自分なりにプログラムを実装してみました。
本書を読んだ感想は、
- 最新のLLMの技術知識をしっかりと丁寧に解説してくれている
- 私も本格的に継続的にはLLM系の実装に触れていないので、学びがとても多かった
- LLMアプリなどを作る際の土台となる知識がしっかりと身につく
- 今回の実装では割愛しましたが、StreamlitでカッコよいUIも作れる
- 作ってみるアプリやLLM-Agentが簡単過ぎず、難しすぎず、ほど良い
- 前から順番にやっていくことでどんどん理解が深まる
という特徴があり、非常に学びになりました。
一方で普段からLLM系の業務に携わっている方には少し物足りないかもしれません
(タイトルの通り、入門書なので)
「これから、AI・LLM系の何か動くものを実装してみたいな~」 と思っている方に非常におすすめできる書籍だと感じました
私のおすすめの学習方法は、本書の内容を自身でGoogle Colaboratory上で動くように実装し直してみる、です(Google ColaboratoryでもStreamlitは使用できます)。
ただ本書を漫然と読むだけでは、普通に読み終えて終わりなので、実際にプログラムが動くように自分なりに実装し直したり、本記事のようにいろいろ変更してみるのがおすすめです。
(再掲)本記事で実装したGoogle Colabのnotebookはこちらになります。
以上、ご一読いただき、ありがとうございました。
小川 雄太郎
https://github.com/YutaroOgawa/about_me
【免責】
本記事の内容は執筆者の意見/発信であり、執筆者が属する企業等の公式見解ではございません