皆さんはLinuxネットワークスタックの問題にあたってしまった時、あるいは単なる興味でLinuxネットワークスタックの中を調べたいと思い立った時、どのようにして調査を進めますか?カーネルのソースコードに printk を仕込んでカーネルを再コンパイルするでしょうか?もしくは最初からソースコードを読むという強い方もいらっしゃるかもしれません。どちらの方法もなかなかの茨の道です。おそらく、ほとんどの方は最終的にftrace やbpftraceなどのDynamic Tracingツールを使って、カーネルの動作を実際に動かしながら見るという方法に至ると思います。
この記事では ipftrace2 というDynamic Tracingツールの基本的な使い方をサンプルとともに紹介します。ipftrace2はネットワークスタック、特にパケット処理の部分をトレーシングをすることに特化した作りになっており、Linuxカーネルの中に流れるどのパケットがどの関数を通ったのかを知ることができます。
ネットワークスタックの調査というドメインでは ftrace や bpftrace よりもかなり便利に使えると思っていますので、そういった調査をされる方はぜひこれを機に試してみてください。
実験環境構築
この記事で紹介するサンプルは Vagrant でUbuntu 21.10 (Impish Indri) のBoxで動作確認しています。ipftrace2はLinuxカーネルのいくつかのオプションに依存していますが、現状ディストリビューションによっては有効化されていないことも多いです。Ubuntu 21.10ではすべて有効化されていますので、スムーズにipftrace2を使い始めるのにはおすすめです。
VagrantでVMを立ち上げてログインします。
mkdir ipftrace2_tutorial
cd iftrace2_tutorial
vagrant init ubuntu/impish64
vagrant up
vagrant ssh
ipftrace2をインストールします。このチュートリアルでは執筆時の最新版であるv0.4.0を使います。
curl -OL https://github.com/YutaroHayakawa/ipftrace2/releases/download/v0.4.0/ipftrace2_amd64.tar.gz
tar xvf ipftrace2_amd64.tar.gz
sudo cp ipft /usr/local/bin/ipft
環境構築は以上です。以降のサンプルはすべてVMに vagrant ssh した状態で実行してください。
基本の使い方
まずは一番基本的な使い方として 1.1.1.1 に ping でICMPパケットを送信する様子をトレースしてみましょう。
まずは ipft を起動します。少し時間がかかりますが、トレースに必要なセットアップが終了すると Trace ready! と表示されます。
sudo ipft -m 1
その後、別のシェルで ping コマンドを使ってパケットを送信します。
sudo ping -m 1 -c 1 1.1.1.1
その後 ipft を Ctrl-C で終了させると以下のような出力が得られるはずです。Timestamp のカラムはパケットが関数を通った時間、CPU のカラムは関数が呼ばれたCPU、Function のカラムはパケットが通った関数を表しています。タイムスタンプを見ればわかるように上から下に時系列で並んでいます。
Attaching program (total 1408, succeeded 1408, failed 0, filtered: 0)
Trace ready!
Got 28 traces^C
Timestamp CPU Function
===
6878466019827 000 __ip_local_out
6878466039712 000 ip_output
6878466045204 000 nf_hook_slow
6878466051026 000 apparmor_ipv4_postroute
6878466056323 000 ip_finish_output
6878466061790 000 __cgroup_bpf_run_filter_skb
6878466067453 000 __ip_finish_output
6878466102825 000 ip_finish_output2
6878466268906 000 dev_queue_xmit
6878466311224 000 __dev_queue_xmit
6878466351341 000 qdisc_pkt_len_init
6878466390487 000 netdev_core_pick_tx
6878466427979 000 sch_direct_xmit
6878466465682 000 validate_xmit_skb_list
6878466502296 000 validate_xmit_skb
6878466538933 000 netif_skb_features
6878466576780 000 skb_network_protocol
6878466614825 000 validate_xmit_vlan
6878466653054 000 validate_xmit_xfrm
6878466691927 000 dev_hard_start_xmit
6878466746729 000 e1000_xmit_frame
6878466753689 000 e1000_tx_map
6878466759479 000 skb_clone_tx_timestamp
6878466973290 001 __dev_kfree_skb_any
6878467019647 001 consume_skb
6878467028553 001 skb_release_head_state
6878467033686 001 sock_wfree
6878467039285 001 skb_release_data
6878467045653 001 kfree_skbmem
このトレースは ping がsocketから送信したICMP Echo RequestのパケットがNICドライバに入って外に出ていくまでの関数呼び出しの一覧です。呼び出されている関数を眺めるだけでも apparmor (Linuxのセキュリティ機能の1つ)、cgroup 、e1000 (IntelのNICドライバ) など、ちょっと見知った名前が色々現れて楽しいです。このトレースをLinuxのソースコードと照らし合わせることで、効率よくカーネルのコードリーディングなどを進めることができます。
ipftrace2の基本的な使い方はこれだけです。とりあえず使う方法を紹介したところで、少しipftrace2の仕組みの話をさせてください。仕組みを理解することで、どうすれば自分が調査したいカーネルの動きをトレースできるのかが明らかになると思います。
ipftrace2の仕組み
ipft -m 1 を実行すると、まず ipft はLinuxカーネル全体の関数の中から struct sk_buff * を引数に取る関数を探します。そして見つかった関数の呼び出しをフックするeBPFのプログラムをアタッチします。アタッチされたeBPFプログラムは関数が呼び出されるたびに引数で渡された struct sk_buff * の mark フィールドをチェックし、1 がセットされていればその関数の呼び出しを記録するためのイベントをperf eventでユーザスベースに送信します。ユーザスペースではこのログを収集して Ctrl-C のあとに表示します。説明の簡単さのためにかなり簡略化していますが、これがだいたいのipftrace2の仕組みです。
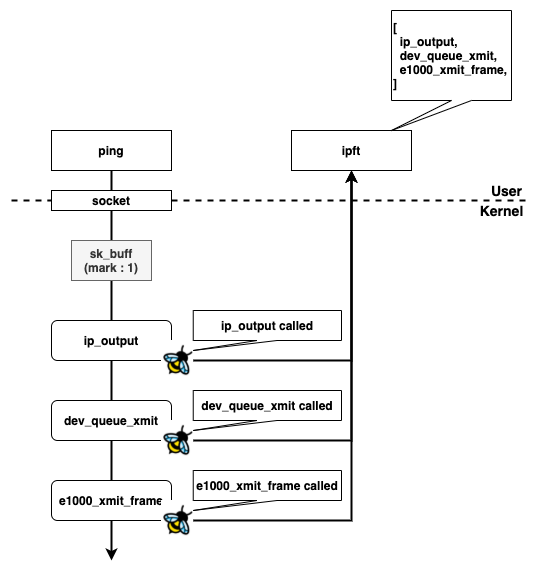
ipftrace2は struct sk_buff * の mark フィールドに指定したmarkがついているパケットが関数の引数に渡された場合のみ呼び出しを記録します。したがって、できるだけたくさんの関数をトレースするためには、なるべくカーネルの中での早いタイミングでmarkをつけることが望ましいと言えます。Linuxにはいくつかの箇所でmarkをつけることができますが、その中でもipftrace2のケースで有用なものの前後関係を並べたものがこの図です。
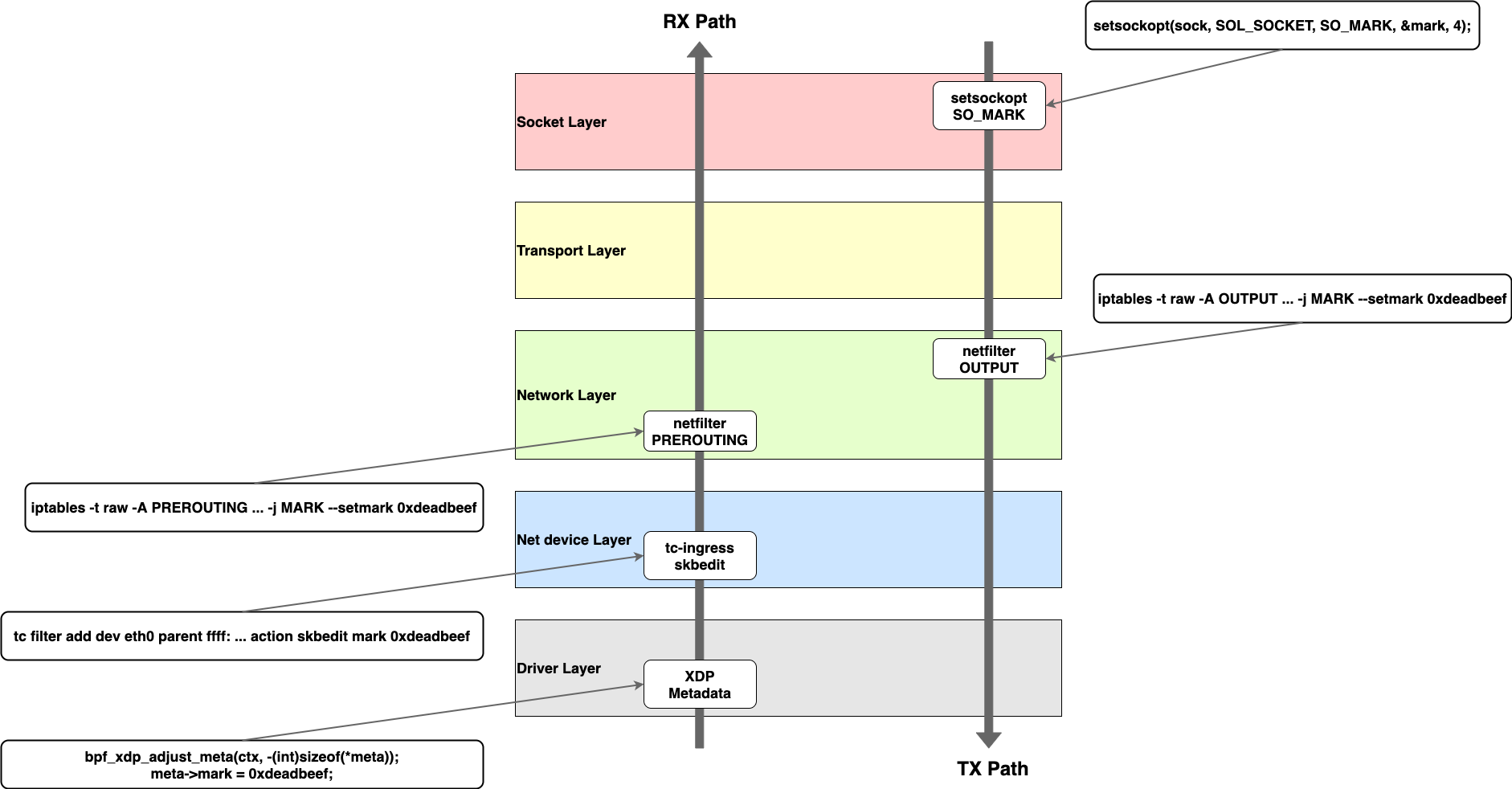
ちなみに先程の例で ping コマンドに -m 1 というオプションを渡したのは setsockopt(SO_MARK) を使ってmarkをつけることに相当します。しかし、ping のようにアプリケーション側が対応していればよいのですが、対応していないアプリケーションではコードの改変が必要です。これはハードルが高いので、実際にはnetfilter (iptables等) の OUTPUT チェインで MARK ターゲットを使ってmarkをつけるのが便利です。もちろんその場合トレースできる区間はNetwork Layer ~ Driver Layerまでになりますが、これでも十分多くの情報を得られます。
受信側に関してもXDP Metadataを使う方法は自分でeBPFプログラムを書く必要があるため、少し面倒です。tc-ingress は比較的簡単な方ではありますが、1つのルールを設定するために複数のコマンドを組み合わせる必要があるなど、少し手軽さに欠けます。そのため、受信側に関してもやはりnetfilterの PREROUTING チェインを使うのがおすすめです。この場合トレースできる区間はNetwork Layer ~ Socket Layerまでということになります。
すこし長くなってしまいましたが、仕組みの話は以上です。ここからは iptables を使ってmarkをつける方法を紹介します。
iptablesを使って柔軟にmarkをつける
iptables を使ってmarkをつけることの利点は iptables が備えている豊富なマッチングの機能を活用できることです。例えば宛先が 1.1.1.1 のパケットに1 というmarkをつけるには以下のように指定します。
sudo iptables -t raw -A OUTPUT -d 1.1.1.1 -j MARK --set-mark 1
この状態で -m オプション無しで ping を実行します。
ping -c 1 1.1.1.1
先ほどとほとんど同じような出力が得られたと思います。
Attaching program (total 1519, succeeded 1519, failed 0, filtered: 0)
Trace ready!
Got 27 traces^C
Timestamp CPU Function
===
40013378172996 000 ip_output
40013378194882 000 nf_hook_slow
40013378205895 000 apparmor_ipv4_postroute
<skip...>
40013378625806 001 sock_wfree
40013378635022 001 skb_release_data
40013378641651 001 kfree_skbmem
iptables の設定を削除するには設定に使った -A を -D に置き換えればいいだけです。
sudo iptables -t raw -D OUTPUT -d 1.1.1.1 -j MARK --set-mark 1
他にもまだまだ色んな条件でmarkをつけることができます。以下はほんの一例です。
# TCPのポート番号でマッチ
sudo iptables -t raw -A OUTPUT -d 1.1.1.1 -p tcp --dport 443 -j MARK --set-mark 1
# TCPのSYN/ACKフラグにマッチ
sudo iptables -t raw -A PREROUTING -s 1.1.1.1 -p tcp --sport 443 --tcp-flags SYN,ACK SYN,ACK -j MARK --set-mark 1
# 送信元が1.1.1.1のパケットに1秒に1回マッチ
sudo iptables -t raw -A PREROUTING -s 1.1.1.1 -m limit --limit 1/s --limit-burst 1 -j MARK --set-mark 1
上記の例はすべて以下のコマンドで動作確認できます。
curl -L https://1.1.1.1
iptables を使うことで非常に柔軟なマッチができるということがわかったと思います。上に挙げ例以外にもまだまだできることが沢山あると思いますので、ぜひ自由な発想でmarkingを楽しんでください。
次にチェックする所
この記事のサンプルを通してipftrace2に興味を持っていただいた方はぜひREADMEやドキュメントを読んでみてください。この記事では紹介できなかった便利な機能がたくさんあります。また、ipftrace2を触ってみたものの、次にトレースしてみるものが思いつかないという方はぜひ合わせてtinetをチェックしてみてください。tinetにはLinuxネットワークスタックの機能を試すための豊富なサンプルがあります。個人的にipftrace2とtinetの相性は抜群だと思っています。tinetでLinuxの機能を試す => ipftrace2でトレーシングしてみる => Linuxのソースを見るというサイクルで効率よく調査が進むこと請け合いです。
まとめ
Linuxネットワークスタックのトレーシングに特化したツール、ipftrace2 を紹介しました。ぜひ皆様のカーネルのトラブルシューティングや勉強に役立てていただければと思います。何かしらのフィードバックをしていただけると、次に何かの記事を書くときの励みになりますので、もしよろしければTwitterなどに記事のリンクとともに感想や疑問などを投稿してみてください。ここまでお付き合いいただき、ありがとうございました。