概要
scikit-learnの公式サイトには実行時間とクラスタリングをした結果だけで精度がわからないためいくつか選んで実行してまとめた。
そして、実行時間と精度を比較した。
実行環境
Mac Mini(2018)
OS : macOS Mojave 10.14.6
CPU : 3.2GHz 6コア第8世代Intel Core i7
メモリ : 16GB
ストレージ : 256GB
Python : Python 3.7.3
用いた手法とベンチマーク
手法
以下の4つを用いた。それぞれの説明は他を参照してほしいです。
K-Means
def kmeans(X, y, n):
"""
K Meansによるクラスタリング
Parameters
----------
X : numpy array
データ
y : numpy array
正解ラベル
n : int
クラスタ数
Returns
-------
acc_km : float
正解率
time_km : float
実行時間
"""
km = KMeans(n_clusters=n,
init="random",
n_init=10,
max_iter=300,
random_state=0)
start_km = time.time()
y_km = km.fit_predict(X)
end_km = time.time()
y_km = np.reshape(y_km, (1, len(y[0])))
acc_km, _, _ = ACC(y_km, y)
time_km = round(end_km - start_km, 2)
make_graph(X, y_km, n)
return acc_km, time_km
Spectral clustering
def spectralclustering(X, y, n):
"""
Spectral Clusteringによるクラスタリング
Parameters
----------
X : numpy array
データ
y : numpy array
正解ラベル
n : int
クラスタ数
Returns
-------
acc_sc : float
正解率
time_sc : float
実行時間
"""
sc = SpectralClustering(n_clusters=2,
affinity="nearest_neighbors")
start_sc = time.time()
y_sc = sc.fit_predict(X)
end_sc = time.time()
y_sc = np.reshape(y_sc, (1, len(y[0])))
acc_sc, _, _ = ACC(y_sc, y)
time_sc = round(end_sc - start_sc, 2)
make_graph(X, y_sc, n)
return acc_sc, time_sc
Agglomerative clustering
def agglomerativeclustering(X, y, n):
"""
Agglomerative Clusteringを用いたクラスタリング
Parameters
----------
X : numpy array
データ
y : numpy array
正解ラベル
n : int
クラスタ数
Returns
acc_ac : float
正解率
time_ac : float
実行時間
-------
"""
ac = AgglomerativeClustering(n_clusters=n)
start_ac = time.time()
y_ac = ac.fit_predict(X)
end_ac = time.time()
y_ac = np.reshape(y_ac, (1, len(y[0])))
acc_ac, _, _ = ACC(y_ac, y)
time_ac = round(end_ac - start_ac, 2)
make_graph(X, y_ac, n)
return acc_ac, time_ac
DBSCAN
def dbscan(X, y, n):
"""
DBSCANを用いたクラスタリング
Parameters
----------
X : numpy array
データ
y : numpy array
正解ラベル
n : int
クラスタ数
Returns
-------
acc_dbs : float
正解率
time_dbs : float
実行時間
"""
dbs = DBSCAN(eps=0.1,
min_samples=2)
start_dbs = time.time()
y_dbs = dbs.fit_predict(X)
end_dbs = time.time()
y_dbs = np.reshape(y_dbs, (1, len(y[0])))
acc_dbs, _, _ = ACC(y_dbs, y)
time_dbs = round(end_dbs - start_dbs, 2)
make_graph(X, y_dbs, n)
return acc_dbs, time_dbs
Birch
def birch(X, y, n):
"""
Birchによるクラスタリング
Parameters
----------
X : numpy array
データ
y : numpy array
正解ラベル
n : int
クラスタ数
Returns
-------
acc_br : float
正解率
time_br : float
実行時間
"""
br = Birch(n_clusters=2)
start_br = time.time()
y_br = br.fit_predict(X)
end_br = time.time()
y_br = np.reshape(y_br, (1, len(y[0])))
acc_br, _, _ = acc(y_br, y)
time_br = round(end_br - start_br, 2)
make_graph(X, y_br, n, "Birch")
return acc_br, time_br
Mini batch K-Means
def minibatchkmeans(X, y, n):
"""
Mini Batch K Meansによるクラスタリング
Parameters
----------
X : numpy array
データ
y : numpy array
正解ラベル
n : int
クラスタ数
Returns
-------
acc_mbkm : float
正解率
time_mbkm : float
実行時間
"""
mbkm = MiniBatchKMeans(n_clusters=n,
init="random",
n_init=10,
max_iter=300)
start_mbkm = time.time()
y_mbkm = mbkm.fit_predict(X)
end_mbkm = time.time()
y_mbkm = np.reshape(y_mbkm, (1, len(y[0])))
acc_mbkm, _, _ = acc(y_mbkm, y)
time_mbkm = round(end_mbkm - start_mbkm, 2)
make_graph(X, y_mbkm, n, "MiniBatchKMeans")
return acc_mbkm, time_mbkm
ベンチマーク
以下の3+3種類を用いた。
Two Circle(2つの円の距離が近い場合と遠い場合)
| 近い場合 |
遠い場合 |
 |
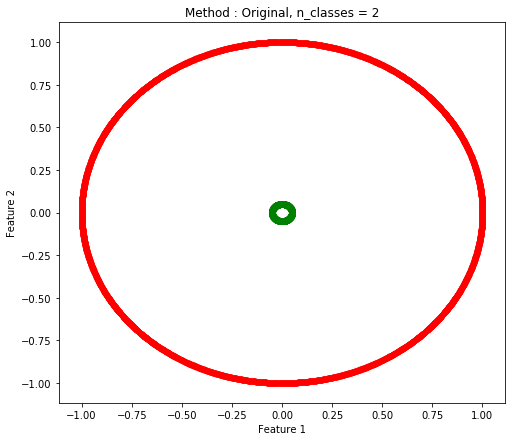 |
Two Moon(ノイズなしとノイズあり)
| ノイズなし |
ノイズあり |
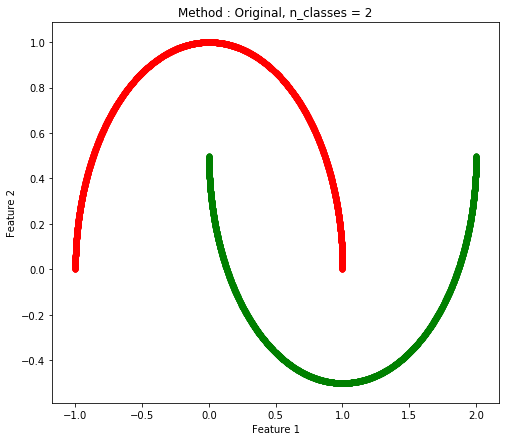 |
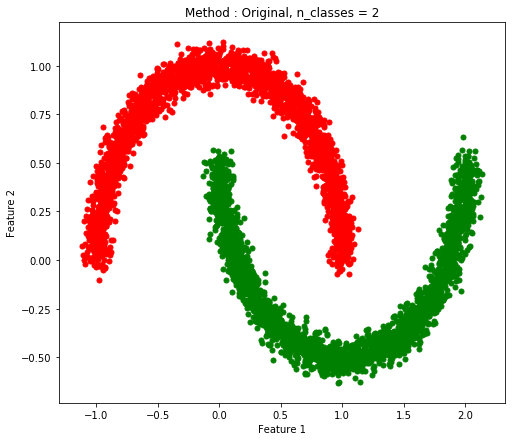 |
Blobs(2つの集合の距離が近い場合と遠い場合)
| 近い場合 |
遠い場合 |
 |
 |
結果
数値は上段が精度で、下段が実行時間[sec].
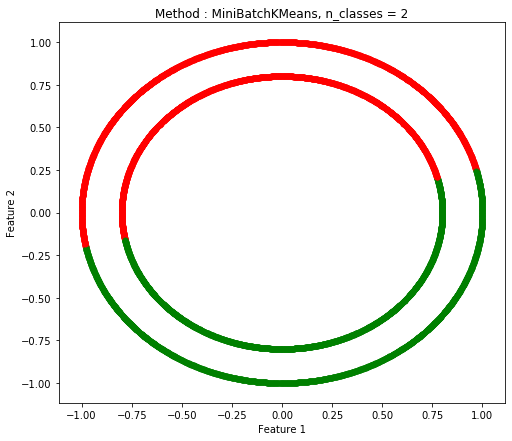
Two Circle(2つの円の距離が近い場合)
| K-Means |
Spectral Clustering |
Agglomerative Clustering |
| 0.5 |
1.0 |
0.5014 |
| 0.03 sec |
11.35 sec |
0.42 sec |
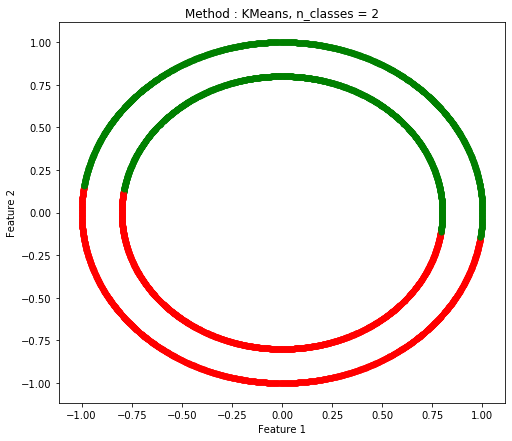 |
 |
 |
| DBSCAN |
Birch |
Mini Batch K-Means |
| 1.0 |
0.5002 |
0.5008 |
| 0.03 sec |
0.08 sec |
0.03 sec |
 |
 |
 |
Two Circle(2つの円の距離が遠い場合)
| K-Means |
Spectral Clustering |
Agglomerative Clustering |
| 0.7054 |
1.0 |
0.6738 |
| 0.02 sec |
9.62 sec |
0.4 sec |
 |
 |
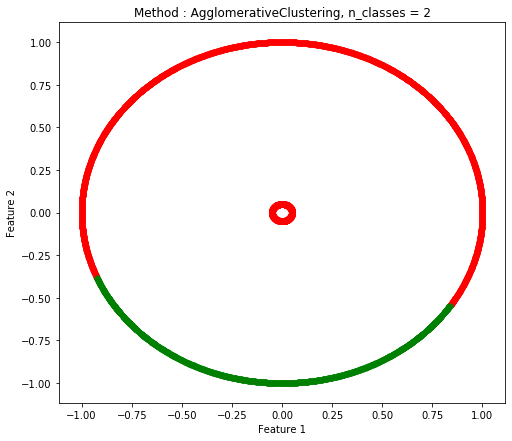 |
| DBSCAN |
Birch |
Mini Batch K-Means |
| 1.0 |
0.7484 |
0.7042 |
| 0.16 sec |
0.09 sec |
0.03 sec |
 |
 |
 |
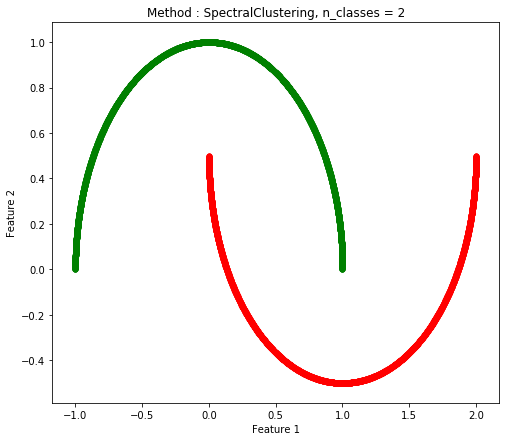
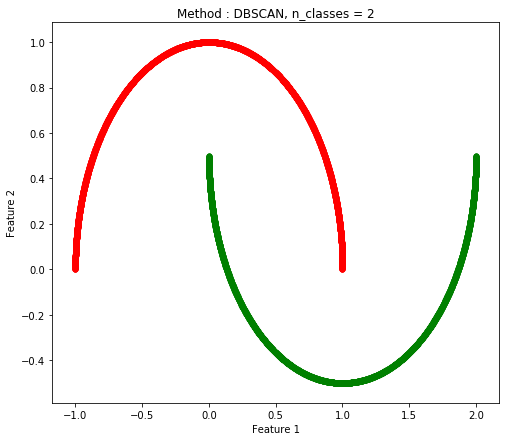
Two Moon(ノイズなし)
| K-Means |
Spectral Clustering |
Agglomerative Clustering |
| 0.752 |
1.0 |
0.7918 |
| 0.03 sec |
34.15 sec |
0.39 sec |
 |
 |
 |
| DBSCAN |
Birch |
Mini Batch K-Means |
| 1.0 |
0.7184 |
0.7548 |
| 0.03 sec |
0.08 sec |
0.04 sec |
 |
 |
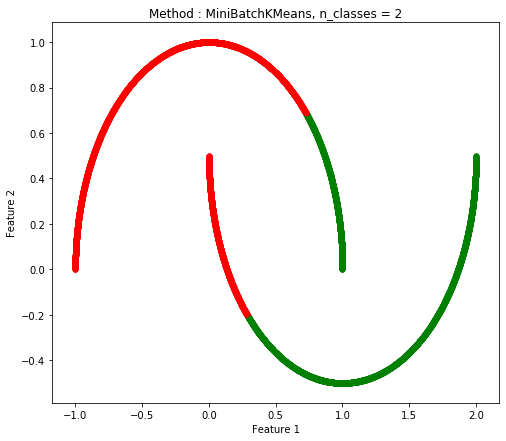 |
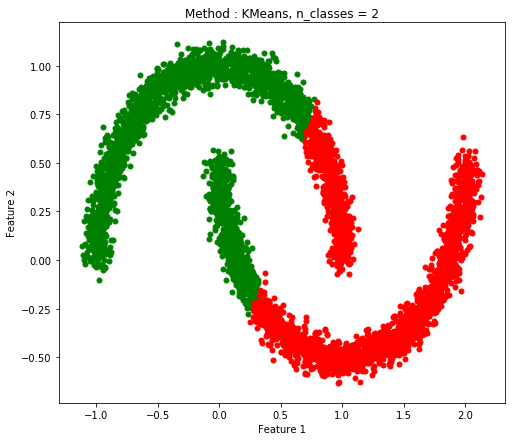
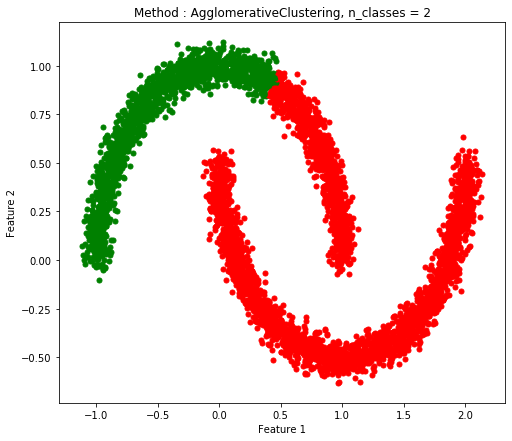
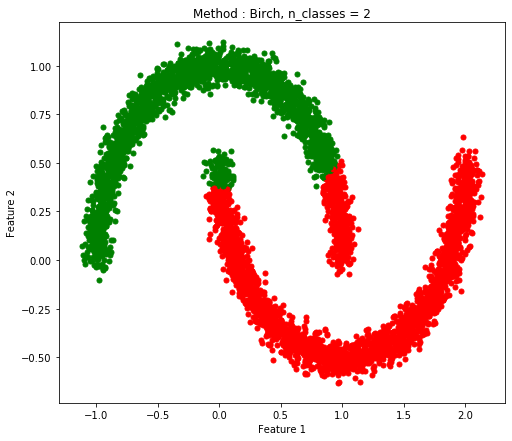
Two Moon(ノイズあり)
| K-Means |
Spectral Clustering |
Agglomerative Clustering |
| 0.7532 |
1.0 |
0.8226 |
| 0.03 sec |
4.96 sec |
0.43 sec |
 |
 |
 |
| DBSCAN |
Birch |
Mini Batch K-Means |
| 1.0 |
0.9072 |
0.7554 |
| 0.03 sec |
0.08 sec |
0.05 sec |
 |
 |
 |
Blobs(2つの集合の距離が近い場合)
| K-Means |
Spectral Clustering |
Agglomerative Clustering |
| 0.9786 |
0.9778 |
0.9712 |
| 0.02 sec |
0.43 sec |
0.42 sec |
 |
 |
 |
| DBSCAN |
Birch |
Mini Batch K-Means |
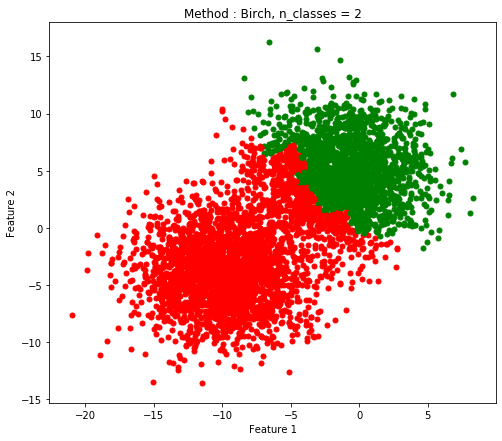
| 0.5004 |
0.8692 |
0.9772 |
| 0.01 sec |
0.15 sec |
0.02 sec |
 |
 |
 |
Blobs(2つの集合の距離が遠い場合)
| K-Means |
Spectral Clustering |
Agglomerative Clustering |
| 1.0 |
1.0 |
1.0 |
| 0.01 sec |
0.53 sec |
0.43 sec |
 |
 |
 |
| DBSCAN |
Birch |
Mini Batch K-Means |
| 1.0 |
1.0 |
1.0 |
| 0.12 sec |
0.08 sec |
0.02 sec |
 |
 |
 |
最後に
全部で6種類のテストに対して、6つの手法を試してみた。
K-Meansはどのテストに対しても一番早く実行が完了されていた。しかし、精度についてはいいとは言えない。
Spectral Clusteringがどのテストに対してもほとんど1.0といい精度だったが、時間が一番かかっていた。
Agglomerative Clusteringはこの6つのテストに対しては時間もかかり、精度も高いとは言えない。
DBSCANも1つ以外はうまくいってて、うまくいかなかったのは多分epsの問題だと思う。
Birchもこの6つのテストに対しては時間はあまりかかっていないが、精度は高いとは言えない。
Mini Batch K-MeansはK-Meansとあまり変わらない印象である。
色々と実装してシミュレーションすることができ、勉強になったので、別の手法でもシミュレーションしてみたい。
参考
scikit-learn