これは、私が若…くはないけどピカピカのAWS1年生だった、数年前のお話です。
何をやらかしたのか
やらかし前の状態
本番運用しているWebアプリケーションの裏側に、EC2インスタンス3台でクラスタを組んだ某データストア製品を使用していました。データはクラスタ内でレプリケーションされており、1台がダウンしただけならクラスタは稼働を継続できます。2台がダウンするとクラスタ全体が機能しなくなります。
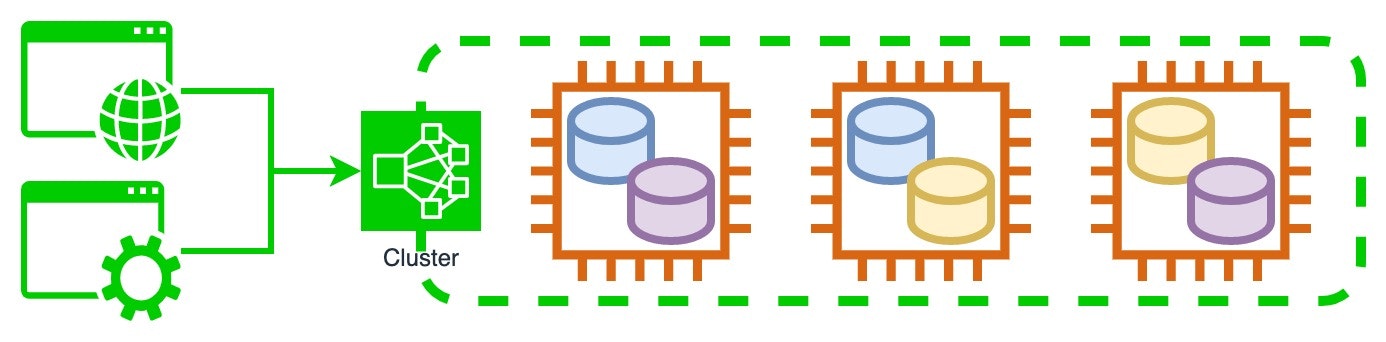
ある日、3台のうち1台で障害が発生してインスタンスへ疎通できない状態になりました。この時点ではクラスタは正常に応答しており、あと1台ダウンしない限りはサービスに影響が出ない状態でした。
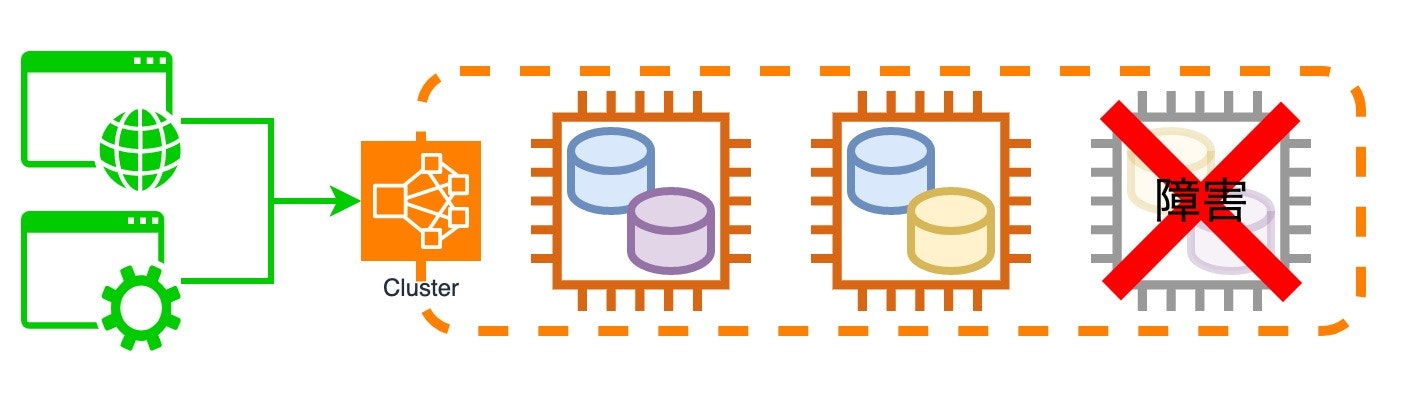
まず、ダウンしてしまったインスタンスを再起動して復旧させようとしました。ところがEC2マネジメントコンソールから再起動、停止を選択しても障害中のインスタンスは反応しません。そして私は間違いを犯します。
やらかしたこと
この日は休日の午前であり、一番詳しい人はまだ寝ているようです。私は焦りました。
「やばい。早く3台構成に戻さないと、あと1台止まったらクラスタ全体が止まってしまう。」
既存のサーバが壊れてしまったなら、新しくサーバを作ってクラスタに参加させるしかありません。サーバのセットアップには複数のセットアップスクリプトを実行する必要があり、焦った状態で正しく実施できる自信がなかったので、正常稼働中インスタンスのディスクを元に新たなインスタンスを起動しようとしました。そしてAWS EC2コンソールで稼働中のインスタンスを選択して、 アクション > イメージ > イメージの作成 を実施しました。
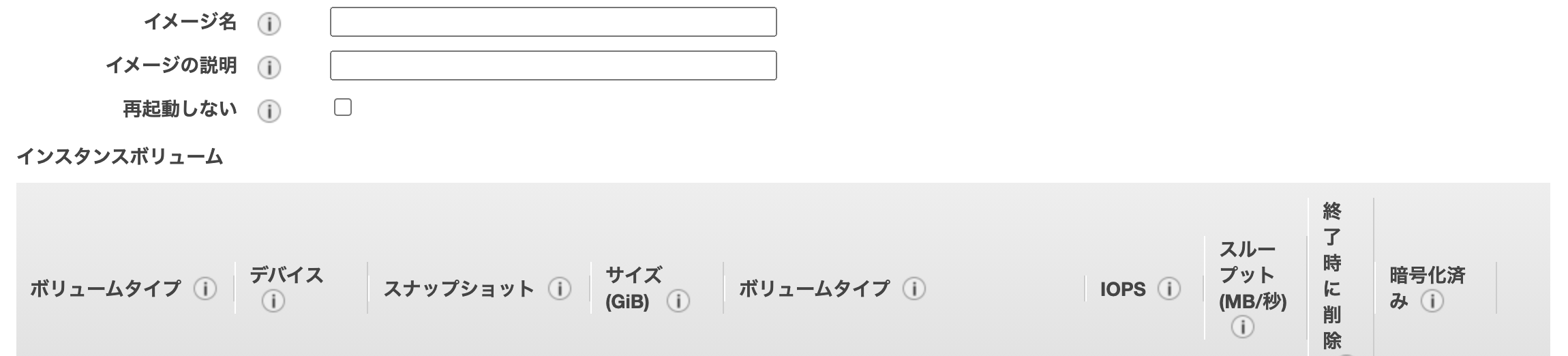
操作を終えて数秒後、我に返りました。あれ今「再起動しない」って項目なかった? しかもチェック外れてなかった? もう一度イメージ作成画面を開いてみよう。

あっっ
やらかした結果何が起きたのか
私は悟りました。ノード喪失に耐えて正常稼働していたクラスタに、自らの手でとどめを刺してしまったのだと。

3台中2台が残り正常稼働していたデータストアのクラスタでしたが、再起動のために追加で1台が止まった結果、クラスタ全体が停止して無応答になりました。そして、そのクラスタに依存していた複数のWebアプリケーション機能しなくなり、再起動が完了するまで数万回のアクセスに対してエラーで応答し続けたのでした。

惨劇はなぜおこってしまったのか
この惨劇は複数の判断ミスが連続したことによって生まれています。
やばい。早く3台構成に戻さないと
やばくありません。1台倒れても大丈夫なための冗長構成です。焦って本番を弄り回すほうがやばいのです。
既存のサーバが壊れてしまったなら
実は、もう少し待てば既存のサーバが復旧してきたのですよ…判断が拙速でしたね。
サーバのセットアップには複数のセットアップスクリプトを実行する必要があり、焦った状態で正しく実施できる自信がなかった
セットアップスクリプトを整理しておいてください。というか、セットアップ手順も分かってないのによく本番を触ろうと思ったな。
正常稼働中インスタンスのディスクを元に新たなインスタンスを起動
正規の手順でセットアップしなさい。思いつきで適当な操作をするな。
あれ今「再起動しない」って項目なかった? しかもチェック外れてなかった?
ダイアログをちゃんと読みなさい。
そして、誤判断の裏には障害に対する準備不足という根本原因がありました。
二度と惨劇を起こさないためにどうしたのか
2度とこのような失敗を起こさないために、障害対応手順の明記と障害対応訓練を実施しました。
障害対応手順の明記
既存のノード復旧を待つか、新規ノードを作成するかの判断のポイント。どんな手順で対応すればよいか等々、明確で正確な障害対応手順書を作りました。(なかったんかい!!
障害対応訓練
開発環境で実際にクラスタの一部ノードを落とし、手順に従ってアプリケーションに影響を出さずに復旧できることを確かめつつ、障害対応の訓練をしました。対応手順には操作に対する反応に応じて次の行動を決める分岐があり、繰り返し訓練を行って全パターンを網羅的に確認しました。
次に同じ障害が起きても、何の問題もなく対処できるはずです(それが普通です...)
蛇足
この記事では盛大にやらかしている私ですが、成果も出してるんですよ常にやらかしてるわけではないんですよ、ということで別のアドベントカレンダーへのリンクを貼らせてください。今年はSupershipグループとElastic Stack (Elasticsearch) のアドベントカレンダーに参加します。こちらも目を通していただけると幸いです。