はじめに
近年、Geminiをはじめとする大規模言語モデル(LLM)は、Long Context(長文脈)への対応能力を飛躍的に向上させ、より複雑なタスクや自然な対話を可能にしています。
Google DeepMindが発表した論文Many-Shot In-Context Learningでは、プロンプトに多くの例(Many-Shot)を与えることでLLMの精度が向上することが報告されています。Long Contextの勉強のためにこの論文を読んでいたところ、興味深い主張を見つけました。それは、「Many-ShotによってLLM事前学習バイアスを打ち消すことができる」というものです。これは、事前学習バイアスを克服できる可能性を示す一方で、プロンプト内に意図的に間違った情報を繰り返し与えることでLLMの出力を操作できてしまう危険性も示唆しています。
本稿では、この主張されている挙動が実際に起こるのかを検証したいと思います。
Many-Shot In-Context Learning(Many-Shot ICL)とは
Many-Shot In-Context Learning(Many-Shot ICL)とは、Google DeepMindによって発表された、多くの例を用いてLLMにタスクのパターンや規則性を学習させることで、複雑なタスクや事前学習における偏りの影響を軽減することで性能向上が期待される手法です。同社が開発したGeminiはLong contextの理解に優れており、Many-Shot ICLの研究成果が活用されていると考えられます。また、最近登場したLLMの多くはコンテキスト長が長いほどベンチマークスコアに上昇傾向が見られ、Long contextは近年の技術トレンドであることがわかります。

Many-Shot ICLは、従来のRAG(Retrieval-Augmented Generation)やFine-tuningと比較しても高い性能を発揮することが報告されています。関連性の高い情報を多数提示することで、LLMが自律的に有効な情報を選択し、タスクを遂行できる可能性が示唆されています。しかし、Many-Shot ICLは長いプロンプトを前提とするため、計算コストが増大するデメリットもあります。また、提示する例の選択を誤ると、精度低下につながるリスクもあります。特に、誤った情報を過剰に提示すると、LLMが誤情報を学習し、意図しない出力を行う可能性があります。
今回は、Llama2にMany-Shotを与えた際の出力を確認し、論文中の主張を再現して見たいと思います。また、Llama2以降に登場したモデルでは、この課題に対してどのように修正されているかも合わせて検証します。
Many-Shot ICLを実際に試してみる
論文では、Financial PhraseBankという感情分析データセットを用いた実験が紹介されています。この実験では、Many-Shot ICLを用いることで、正解ラベルを意図的にシャッフルした場合や、抽象的なラベルに変更しても、テスト精度が大幅に向上し、最終的に元の正解ラベルを用いた場合と同等の性能に近づくことが示されています。(ラベルをシャッフルの際には、精度が一時的に低下していますが、これはMany-Shot ICLによるタスク学習の効果によって、LLMが事前学習バイアスを克服する過程であると論文では説明されています。)
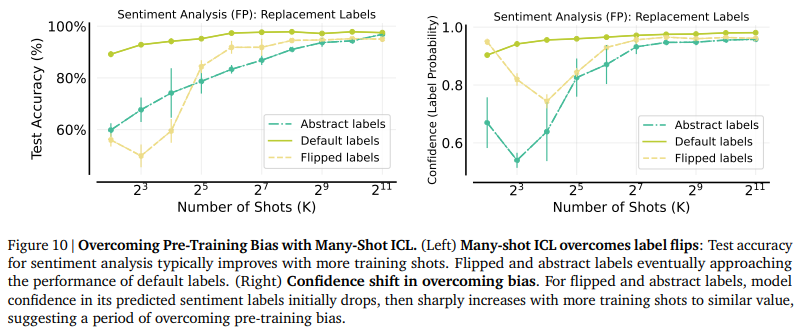
Many-Shot In-Context Learningより引用
この実験を再現してみましょう。引用論文をサーベイしてみるとLlama2が使われているみたいなので、まずはLlama2で試してみます。
Models & Tasks. We employ LLMs from the LLaMa-2 (Touvron et al., 2023b), LLaMa (Touvron
et al., 2023a), and Falcon (TII, 2023) families due to their strong performance and open source
nature.
In-Context Learning Learns Label Relationships but Is Not Conventional Learningより引用
1. Llama2
実験には、meta-llama/Llama-2-7b-chat-hfを使用し、正解ラベルに以下の操作を加え、例として与えます。
- ラベルをシャッフル([‘negative’, ‘neutral’, ‘positive’]→[‘neutral’, ‘positive’, ‘negative’])
- 抽象的なラベルに変更([‘negative’, ‘neutral’, ‘positive’]→ [‘A’, ‘B’, ‘C’])
実装したコード
import os
import argparse
import random
from collections import defaultdict
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset, Dataset
from dotenv import load_dotenv
load_dotenv()
HF_TOKEN = os.getenv("HF_TOKEN")
def equalize_labels(ds, num_sample):
label_counts = defaultdict(int)
for data in ds:
label_counts[data["label"]] += 1
num_labels = len(label_counts)
samples_per_label = num_sample // num_labels
remainder = num_sample % num_labels
sampled_data = []
label_data = defaultdict(list)
for data in ds:
label_data[data["label"]].append(data)
for label, data_list in label_data.items():
num_samples = samples_per_label
if remainder > 0:
num_samples += 1
remainder -= 1
sampled_data.extend(random.sample(data_list, min(num_samples, len(data_list))))
random.shuffle(sampled_data)
new_dataset = Dataset.from_list(sampled_data)
return new_dataset
def flip_labels(ds, prompt, args):
for i in range(args.num_shots):
sentence = ds["sentence"][i]
label = ds["label"][i]
# correct label -> 0: negative, 1: neutral, 2: positive
if label == 0:
ans = "neutral"
elif label == 1:
ans = "positive"
elif label == 2:
ans = "negative"
prompt += f"Text: {sentence}\nSentiment: {ans}\n\n"
return prompt
def abstract_labels(ds, prompt, args):
for i in range(args.num_shots):
sentence = ds["sentence"][i]
label = ds["label"][i]
# correct label -> 0: negative, 1: neutral, 2: positive
if label == 0:
ans = "A"
elif label == 1:
ans = "B"
elif label == 2:
ans = "C"
prompt += f"Text: {sentence}\nSentiment: {ans}\n\n"
return prompt
def main(args):
model = AutoModelForCausalLM.from_pretrained(args.model_id, device_map="cuda", torch_dtype="auto", token=HF_TOKEN)
tokenizer = AutoTokenizer.from_pretrained(args.model_id)
ds = load_dataset("takala/financial_phrasebank", "sentences_allagree", trust_remote_code=True)["train"]
ds = equalize_labels(ds, args.num_shots)
# Base prompt
prompt = """
# Task
Analyze the sentiment of the following texts and classify them as “positive”, “negative”, or “neutral”.
# Examples
Please refer to the following examples.
"""
# Create label-fliped examples
if args.fliped_labels:
prompt = flip_labels(ds, prompt, args)
# Create label-abstracted examples
elif args.abstracted_labels:
prompt = abstract_labels(ds, prompt, args)
# Target text
prompt += f"Text: Sales in Finland decreased by 10.5 % in January , while sales outside Finland dropped by 17 % .\nSentiment: "
with torch.no_grad():
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=128,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
)
output = tokenizer.decode(output_ids.tolist()[0][token_ids.size(1) :], skip_special_tokens=True)
print(output)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Overcoming Pre-training Biases with Many-Shot ICL")
parser.add_argument("--model_id", type=str, default="meta-llama/Llama-2-7b-chat-hf", help="Inference model")
parser.add_argument("--num_shots", type=int, default=32, help="Number of Shot")
parser.add_argument("--fliped_labels", action="store_true", help="Flag for label fliped")
parser.add_argument("--abstracted_labels", action="store_true", help="Flag for label fliped")
args = parser.parse_args()
main(args)
「Sales in Finland decreased by 10.5 % in January , while sales outside Finland dropped by 17 % .」(正解ラベル: negative)という文章を入力し、感情分類を試行してみます。Shot数(例の数)は0→8→32と段々増加させ、出力の変化を観察します。
| Num of Shots | Fliped Labels(シャッフル) | Abstract Labels(抽象化) |
|---|---|---|
| 0 | negative | negative |
| 8 | negative | B |
| 32 | neutral | A |
この結果から、Shot数を増やすことで、Llama2が操作されたラベルに基づいて回答するようになることが確認できました。特に、ラベル抽象化の場合、少ないShot数でも抽象的なラベル(A, B, C)で回答しようとする傾向が見られました。これらの結果は、論文の主張を概ね裏付けるものであり、Many-Shot ICLが事前学習バイアスを打ち消す効果を持つことを示唆しています。
それでは、Llama2を元にして作られたの別LLMではどうでしょうか?
2. Llama2ベースのLLM
次に、Llama2ベースのelyza/ELYZA-japanese-Llama-2-7b-fast-instructとlmsys/vicuna-7b-v1.5を用いて同様の実験を行いました。Llama2と同様の条件で、32Shotの場合の挙動を確認しました。
| Model | Fliped Labels(シャッフル) | Abstract Labels(抽象化) |
|---|---|---|
| ELYZA | neutral | A (※) |
| Vicuna | negative | A |
※ 「A,B,C」ではなく「あ,い,う」に置換
ELYZAモデルはLlama2と同様に事前学習バイアスを克服する傾向を示しました。Vicunaもラベル抽象化に対しては同様の結果が見られましたが、ラベルシャッフルに対しては元の正解ラベル(negative)を出力しました。(ただし、これは私のGPU環境上での検証であり、Shot数をさらに増やすことで事前学習バイアスを打ち消す可能性があります。)
これらの結果から、Llama2ベースのモデルでもMany-Shot ICLによって事前学習バイアスを克服可能であることが示唆されました。これは、Long contextへの対応能力や追加学習データの偏りが影響していると考えられます。
3. Gemini
最新モデルであるGemini-2.0 Flashに対して、同様の質問を32Shotで試しました。
- ラベルシャッフル
Sentiment: negative
The text explicitly states "decreased" and "dropped," both of which are negative indicators in the context of sales performance. These words directly convey a decline in sales, making the sentiment clearly negative.
- ラベル抽象化
Text: Sales in Finland decreased by 10.5 % in January , while sales outside Finland dropped by 17 % .
Sentiment: A (Negative)
売上高がフィンランドで10.5%、フィンランド国外で17%減少したとあり、業績の悪化を示しているため、ネガティブな感情と判断しました。
GeminiはLlama2とは異なり、ラベル操作の影響を受けずに正しい回答を出力しました。特に、ラベル抽象化の回答が「A (Negative)」となっている点から、Geminiが例の形式を維持しつつ、背後にある意味を理解していることがわかります。
Geminiが正しく回答できた理由としては、以下の要因が考えられます。
- 大規模な事前学習データ: 事前学習データの規模が大きくなり、事前学習バイアスが強固になった
- Long contextへの対応: 長い文脈を正確に理解し、多入力に対しても適切な回答ができるようになった
これらの実験から、Many-Shot ICLがLLMの挙動に与える影響を確認しました。特に、最新のLLMでは事前学習バイアスに対する耐性が向上していることがわかりました。
まとめ
本稿では、Many-Shot ICLによってLLMの事前学習バイアスを打ち消すことができるかを確認しました。Llama2やLlama2ベースの派生モデルでは、論文で主張されているように、多数の例を与えることで事前学習バイアスを打ち消す傾向が見られました。しかし、Geminiのような最新モデルでは、その傾向は見られませんでした。
今回実験した感情分析のような比較的単純なタスクでは、与えられた情報の内容をLLMが鵜呑みにすることはないかもしれません。しかし、タスクが複雑になると事前学習バイアスを克服し、回答が変化する可能性は大いに考えられます。これは、例さえ与えれば特殊事例にも対応できる利点がある一方で、誤った情報によって回答が操作されてしまう危険性も考慮する必要があります。