はじめに
2023年に元Googleの研究者によってSakana AIというAIスタートアップが設立されました。近年のAI分野で最も有名な論文である「Attention Is All You Need」の著者の1人と、Stable Diffusionを発表したStability AIの元トップ研究者が共同創業者であることで注目を集めました。
そんなSakana AIからEvolutionary Optimization of Model Merging Recipesという論文が発表されました。
本稿では、Evolutionary Model Merge(進化的モデルマージ)を実装することで理解を深めたいと思います。
Evolutionary Model Mergeとは
Evolutionary Model Mergeとは、進化的アルゴリズムを用いて、複数のモデルから新たな基盤モデル構築する技術です。例えば、日本語力に長けたモデルと英語の数学問題を解くことに長けたモデルをマージすることで、日本語の数学問題を解くことに長けたモデルを生み出すことが可能です。
モデルのマージには、2つのアプローチが用いられています。
- DFS: 複数のモデルのレイヤーを積み重ねてモデルを構築する
- PS: 重みを線形補間してモデルを構築する
そして、この2つのアプローチの組み合わせを進化的アルゴリズムを使って自動で最適化するというのが革新的な部分です。さらに、 Deep Learningモデルの学習方法の主流である誤差逆伝搬を使用しないため、膨大なコストを抑えることができると述べられています。
今回は、論文で発表された「日本語の数学問題を解くことができるLLM」であるEvoLLM-JPを再現してみようと思います。実装には、mergekitというライブラリを使用しました。コードは以下に公開しています。
mergekit-evolveでEvolutionary Model Mergeを実装
ハードウェア要件
マージ処理自体にGPUは必要ありませんが、マージモデルの性能を評価する際にGPUが必要です。7Bのモデルをマージする場合には、メモリが16GBあれば十分だと思います。(mergekitではDFSは実装されていないため、マージ元のモデルと同一のパラメータ数にしかなりませんでした。)
1. mergekit-evolveのインストール
git clone https://github.com/arcee-ai/mergekit.git
cd mergekit
pip install -e .[evolve]
2. データセットの作成
データセットにはMGSMの日本語版を使用します。
import datasets
ds = datasets.load_dataset("juletxara/mgsm", "ja")
ds["train"].save_to_disk("./mgsm-jp/train")
3. eval_tasks/spartqa_train.yamlの作成
eval_tasks/spartqa_train.yamlには、マージモデルの評価指標を記載します。評価用のプロンプトやスコアの算出方法はこちらを参考にしました。簡単に言うと、生成文に登場する数字のうち最後の数字と問題の答えを照合し、正解数が多いモデルを次の世代へ残すような処理になっています。
task: mgsm_train
dataset_path: arrow
dataset_kwargs:
data_files:
train: mgsm-jp/train/data-00000-of-00001.arrow
test: mgsm-jp/test/data-00000-of-00001.arrow
output_type: generate_until
training_split: null
test_split: train
doc_to_text: "次の数学の問題を解いてください。最終的な答えを出す前に、解答の推論過程を記述してください。答えには整数の答え以外何も追加しないでください。\n問題:{{question}}\n答え:"
doc_to_target: ""
#process_results スコア計算
process_results: !function mgsm_metric.process_results
metric_list:
- metric: acc
aggregation: mean
higher_is_better: true
import re
def extract_regex(text):
num_list = re.findall(r'\d+', text)
if num_list is not None:
return num_list
else:
return None
def score_mgsm(pred, question, answer_number, answer) -> bool:
if "." in pred:
pred = pred.rstrip("0").rstrip(".")
pred = pred.replace(",", "")
if str(answer_number) == pred:
return 1
else:
return 0
def process_results(doc, results):
try:
pred = extract_regex(results[0])[-1]
score = score_mgsm(pred, doc["question"], doc["answer_number"], doc["answer"])
except IndexError:
score = 0
return {"acc": score}
4. evol_merge_config.ymlの作成
evol_merge_config.ymlには、マージ元のモデルやマージ方法を記載します。論文に従ってモデルを選択し、マージ方法はdare_tiesとしました。
※今回は使いませんでしたが、複数のタスクに重みを付けてマルチタスクにすることもできます。
genome:
models:
- WizardLMTeam/WizardMath-7B-V1.1
- GAIR/Abel-7B-002
merge_method: dare_ties
base_model: augmxnt/shisa-gamma-7b-v1
layer_granularity: 8
allow_negative_weights: true
tasks:
- name: mgsm_train
weight: 1.0
5. mergekit-evolveの実行
以下のコマンドを実行することで、Evolutionary Model Mergeを行うことができます。大体、処理に半日ほどかかりました。
-no-merge-cudaではなく、-merge-cudaを指定すると、マージ処理にGPUを使用し、高速で処理を実行できます。私の場合には、メモリが足りなかったので、-no-merge-cudaを指定しています。
mergekit-evolve ./evol_merge_config.yml \
--storage-path evol_merge_storage \
--task-search-path eval_tasks \
--in-memory \
--no-merge-cuda \
--wandb
完了するとマージの結果の詳細が出力されます。
best_score 0.75
evaluations 108
population/mgsm_train_acc_max 0.5
population/mgsm_train_acc_mean 0.5
population/mgsm_train_acc_min 0.5
population/score_mean 0.5
population/score_std 0.0
5. マージ後のモデルの保存
Evolutionary Model Mergeで作成された最良モデルのパラメータ(evol_merge_storage/best_config.yaml)をmergeディレクトリに保存します。
mergekit-yaml evol_merge_storage/best_config.yaml merge
精度比較
マージ元のモデルとEvoLLM-JP-v1-7Bを用いて精度を比較してみました。
| ID | Model | Type | Size | MGSM-JA(acc↑) |
|---|---|---|---|---|
| 1 | Shisa Gamma 7B v1 | JA general | 7B | 6.4 |
| 2 | WizardMath 7B v1.1 | EN math | 7B | 35.2 |
| 3 | Abel 7B 002 | EN math | 7B | 21.2 |
| 4 | EvoLLM-JP | 7B | 41.2 | |
| 5 | Merged Model | 1+2+3 | 7B | 30.8 |
- Shisa Gamma(日本語特化のモデル)と比較すると大幅に精度が向上
- Abelと比較すると性能が向上したが、WizardMathは超えることができなかった
論文に記述されている評価精度を再現することはできませんでした。(WizardMathとAbelの精度の優劣が逆。Sakana AIのEvoLLM-JPも論文の精度とは程遠い...)
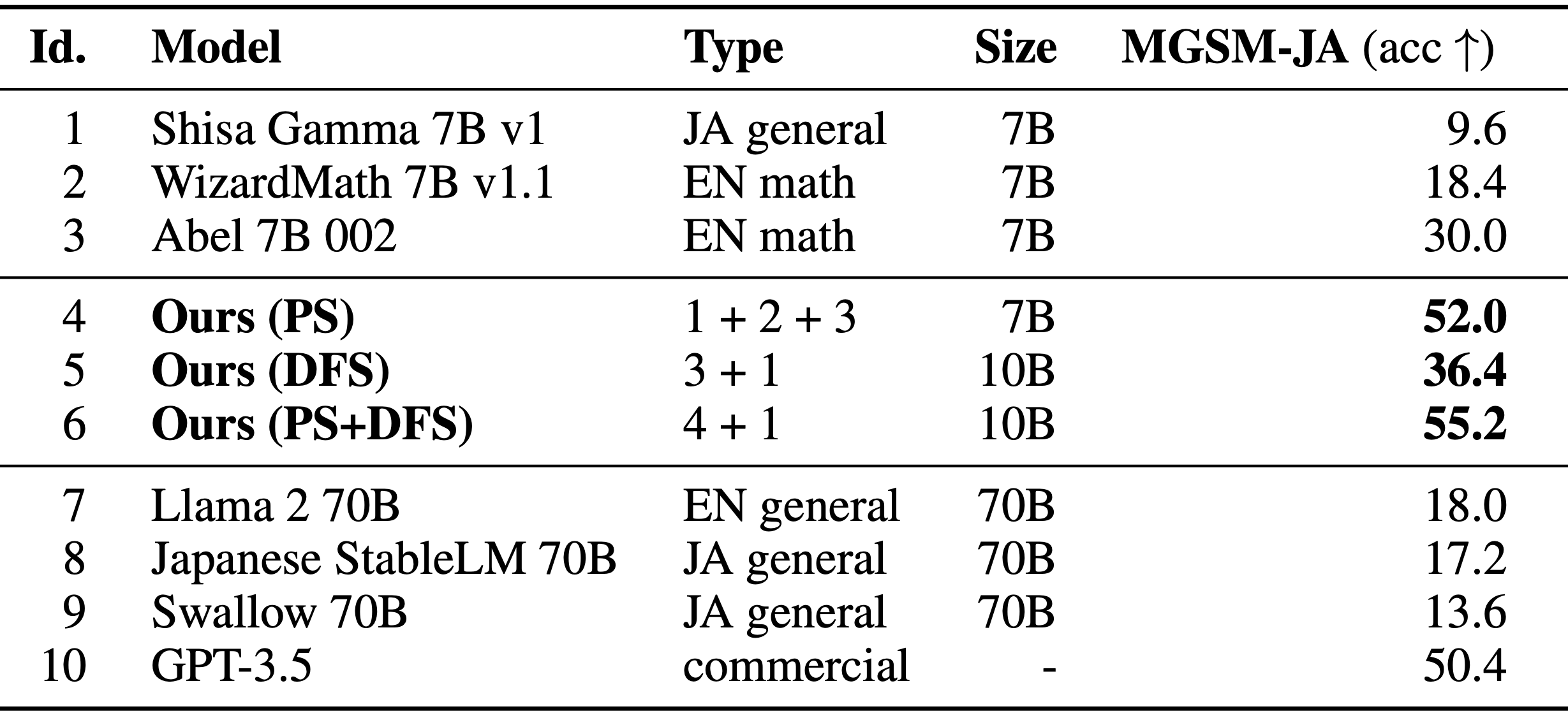
論文より引用
データを増やして再実験
マージの際に使用したデータ(Trainサブセット)が8データしかなかったので、Testサブセットの100データを使用してマージしてみました。
| Only Train | Train + Test |
|---|---|
| 34.7 | 22.7 |
※マージに使用しなかったTestサブセットの150データで精度を算出
データ数を増やしても精度は上がりませんでした。(むしろ低下)
Deep Learning Modelの学習とは異なり、Evolutionary Model Mergeは単純にデータ数を増やしても汎化するわけではないのかもしれません。
まとめ
本稿では、Sakana AIのEvolutionary Model Mergeの実装してみました。論文の再現とはいきませんでしたが、特定のベンチマークに対して性能を向上させることができました。
Evolutionary Model Mergeは、低コストかつ一定の性能向上が期待できるため、様々なユースケースを想定することができます。
- モデルの小型化
- 新規LLMを特定の領域に対応させる
- 英語で専門的な領域に特化させたLLMを作成して、それを日本語モデルとマージ
しかし、Sakana AIはコードを公開しておらずmergekitでも完全には再現できないため、専門家の勘や経験に依存してしまうという現状の課題の解決にはならないのでは?と思ってしまいました。