概要
本記事ではTransformerというモデルを用いて、株価を予測するモデルを構築したのでまとめています。構築したモデルのインプットとアウトプットは以下の通りです。
- インプット:直近60営業日分の株価
- アウトプット:5営業日後の株価
アプリケーション化したものに関する記事は以下を参照ください。
https://qiita.com/YusukeOhnishi/items/9778ecd356f76fbee530
また実装したコードについてはGitHub(https://github.com/YusukeOhnishi/Transformer_for_StockPrediction)にアップロードしておりますので、実際に動かしてみたい場合にはクローンしてご使用ください。Google Colaboratoryにて動作することを確認していますので、Google ColaboratoryにてランタイムのタイプをGPUに変更して実行していただけるとよいかと思います。
今回作成したモデルでは1銘柄に対して学習・推論を行っていますが、もっと汎用的なモデルを作成したい場合には、銘柄情報等をインプットにすることなどが考えられます。
また本記事の内容はあくまでも技術的に推論モデルを作ることが可能だという内容になるので、実際に株式購入を検討されている方は、ご自身の判断で投資は行ってください。
Transformerとは
Transformerは2017年に発表されたモデルで、主に自然言語処理で用いられているモデルです。自然言語処理の問題では単語の出現順序が重要な要素であるため、このようなデータの順序をモデルに組み込んでいます。また自然言語処理のみではなく、時系列データなどの予測などに利用することが可能ですので、本記事で取り扱う株価の推移などに適用することが可能です。
このような時系列データ及び自然言語を取り扱うモデルは他にもあり、例えばRNN、LSTMなどの再帰的に層を繋げるモデルなどが以前は主流でした。
これらのモデルは大きくエンコーダー、デコーダーという2つの部品からできており、エンコーダーに入力となる時系列データを渡し、デコーダーから対応する時系列データを出力するという流れになります。例えば言語翻訳などで考えると、日本語の文章をエンコーダーに渡すと対応する英語の文章をデコーダーが出力するといったものです。
これまでの研究で、このエンコーダーとデコーダーの間に、データのどの部分に着目するのかということを学習させる機構であるAttentionを入れることで精度が大きく向上することが知られています。
Transformerは、このAttentionという機構のみでエンコーダーとデコーダー間を繋いだモデルです。このような実装を行うことで、より高速で高精度なモデルが実現されています。原論文に記載されているモデルの構成は以下の通りです。

Transformerモデルの詳細については別記事を参考にしてください。
- https://crystal-method.com/topics/transformer-2/
- https://blogs.nvidia.co.jp/2022/04/13/what-is-a-transformer-model/
データ
株価のデータはPythonのpandas_datareaderというライブラリを用いて、yahoo finance(https://finance.yahoo.com/)から取得します。取得したデータはいくつかの要素を含みますが、今回は「Adj Close」の値のみを用いて実装を行います。これは配当を加味した終値になります。
また実装では例として、ソフトバンクグループの2003年1月1日から2022年12月31日までの計20年分の株価(https://finance.yahoo.com/quote/9984.T/history)を用います。
実装
データ取得と整形
上の通りYahoo financeからデータを取得します。データ取得は下記のように実装します。
from pandas_datareader import data as wb
import yfinance as yfin
yfin.pdr_override()
## Security code
stock_code='9984.T'
## Start Date
start_date='2003-1-1'
## End Date
end_date='2022-12-31'
# Get data
df=wb.DataReader(stock_code,start=start_date,end=end_date)
df
Open High Low Close Adj Close Volume
Date
2003-01-01 225.833328 225.833328 225.833328 225.833328 203.087509 0
2003-01-02 225.833328 225.833328 225.833328 225.833328 203.087509 0
2003-01-03 225.833328 225.833328 225.833328 225.833328 203.087509 0
2003-01-06 231.666672 233.500000 229.166672 230.666672 207.434036 25549200
2003-01-07 234.833328 235.333328 224.666672 225.833328 203.087509 33570000
... ... ... ... ... ... ...
2022-12-26 5772.000000 5824.000000 5728.000000 5778.000000 5778.000000 5392700
2022-12-27 5797.000000 5870.000000 5785.000000 5796.000000 5796.000000 6626000
2022-12-28 5770.000000 5785.000000 5680.000000 5711.000000 5711.000000 7324500
2022-12-29 5650.000000 5656.000000 5576.000000 5618.000000 5618.000000 8281700
2022-12-30 5681.000000 5735.000000 5624.000000 5644.000000 5644.000000 9104100
取得したデータは上記のように各日付に対して、Open(始値)、High(高値)、Low(安値)、Close(終値)、Adj Close(配当調整済み終値)、Volume(取引高)が入力されたものです。
今回着目したいのはAdj Closeであるため、この値をプロットすると以下のようになります。
# Plot 'Adj Close' values
plt.plot(df.iloc[:,-2])
plt.xlabel('date')
plt.ylabel('Adj Close')
plt.show()

このようなデータから今回用いるモデルに適用できる時系列データ列を作成します。
学習用データは以下のように実装します。
import math
import numpy as np
import tqdm
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
## Split ratio of train data and validation data
train_rate=0.7
## How many business days to see
observation_period_num=60
## How many business days to predict
predict_period_num=5
# Normalization
mean_list=df.mean().values
std_list=df.std().values
df=(df-mean_list)/std_list
# Array initialization
inout_data=[]
# Put data in array
for i in range(len(df)-observation_period_num-predict_period_num):
data=df.iloc[i:i+observation_period_num,4].values
label=df.iloc[i+predict_period_num:i+observation_period_num+predict_period_num,4].values
inout_data.append((data,label))
inout_data=torch.FloatTensor(inout_data)
train_data=inout_data[:int(np.shape(inout_data)[0]*train_rate)].to(device)
valid_data=inout_data[int(np.shape(inout_data)[0]*train_rate):].to(device)
print('train data:',np.shape(train_data)[0])
print('valid data:',np.shape(valid_data)[0])
- データを正規化する。
- データの0番目からobservation_period_num(60)営業日分のデータを取得し、これを学習用Input dataとする。
- 2に対してpredict_period_num(5)営業日ずらしたpredict_period_num番目からobservation_period_num(60)営業日分のデータを取得し、これを学習用Label dataとする。
- 開始位置を1営業日ずらして2、3を繰り返す。

これを繰り返すことで合計で[営業日数]-[observation_period_num]-[predict_period_num]個のInput DataとLabel dataが生成されますが、このうち最初のtrain_rate(0.7)の割合分を訓練データ、残りを検証用データとしています。
モデル
続いてTransformerのモデル部分に関して説明します。モデル部分の実装は2つのパーツで構成しています。
1つ目はPositional Encodingです。これはモデルでいう入力部分に相当するもので、この機構を取り入れることで、時系性を持ったデータに対して、各データが何番目のデータなのかということを考慮することができます。今回の場合だと60営業日分のデータを1つの時系列データとしているので、60営業日の何日目のデータなのかということを取り入れていることになります。
詳細については以下の記事を参考にするとわかりやすいかと思います。
https://qiita.com/masaki_kitayama/items/01a214c07b2efa8aed1b
実装は以下の通りです。
# Functions for positional encoding
class PositionalEncoding(nn.Module):
def __init__(self,d_model,max_len=5000):
super().__init__()
self.dropout=nn.Dropout(p=0.1)
pe=torch.zeros(max_len, d_model)
position=torch.arange(0, max_len,dtype=torch.float).unsqueeze(1)
div_term=torch.exp(torch.arange(0,d_model, 2).float()*(-math.log(10000.0)/d_model))
pe[:,0::2]=torch.sin(position*div_term)
pe[:,1::2]=torch.cos(position*div_term)
pe=pe.unsqueeze(0).transpose(0,1)
self.register_buffer("pe",pe)
def forward(self,x):
return self.dropout(x+self.pe[:np.shape(x)[0],:])
続いて、2つ目はTransformerモデルのメイン部分ですが、こちらはpytorchにTransformerモデルを使うことができるようになっているため、これを使用します。
https://pytorch.org/docs/stable/generated/torch.nn.TransformerEncoderLayer.html
https://pytorch.org/docs/stable/generated/torch.nn.TransformerEncoder.html
モデルとしてはEncoderにデータを渡し、出力結果をデコーダに渡すという、標準的な実装方法としています。実装は以下の通りです。
# Transformer model definition
class TransformerModel(nn.Module):
def __init__(self,feature_size=250,num_layers=1,dropout=0.1):
super().__init__()
self.model_type='Transformer'
self.src_mask=None
self.device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.pos_encoder=PositionalEncoding(d_model=feature_size)
self.encoder_layer=nn.TransformerEncoderLayer(d_model=feature_size,nhead=10,dropout=dropout)
self.transformer_encoder=nn.TransformerEncoder(self.encoder_layer,num_layers=num_layers)
self.decoder=nn.Linear(feature_size,1)
def init_weights(self):
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform(-0.1,0.1)
def _generate_square_subsequent_mask(self,sz):
mask=(torch.triu(torch.ones(sz,sz))==1).transpose(0,1)
mask=mask.float().masked_fill(mask==0,float('-inf')).masked_fill(mask==1,float(0.0))
return mask
def forward(self,src):
if self.src_mask is None or self.src_mask.size(0)!=len(src):
device=self.device
mask=self._generate_square_subsequent_mask(len(src)).to(device)
self.src_mask=mask
src=self.pos_encoder(src)
output=self.transformer_encoder(src,self.src_mask)
output=self.decoder(output)
return output
学習
学習を行うに際して、2つの関数を定義しておきます。
- ミニバッチに分割するための関数
- 学習時に一定回数(patience)の間lossの減少が止まった場合に学習を早期終了させるための関数
それぞれの実装は以下の通りです。
# Define a function for getting mini-batch
def get_batch(source, i, batch_size):
seq_len=min(batch_size, len(source)-1-i)
data=source[i:i+seq_len]
input=torch.stack(torch.stack([item[0] for item in data]).chunk(observation_period_num,1))
target=torch.stack(torch.stack([item[1] for item in data]).chunk(observation_period_num,1))
return input, target
# Function for early stop of train if valid loss is not decreasing
class EarlyStopping:
def __init__(self,patience=5):
self.patience=patience
self.counter=0
self.best_score=None
self.early_stop=False
self.val_loss_min=np.Inf
def __call__(self,val_loss,model):
score=(-val_loss)
if self.best_score is None:
self.best_score=score
elif score<self.best_score:
self.counter+=1
if self.counter>=self.patience:
self.early_stop=True
else:
self.best_score=score
self.counter=0
上記で定義した関数やモデルを用いて学習を行います。学習については一般的なものと同じなので簡単に説明します。
- 損失関数は平均二乗誤差関数
- 最適化手法はAdam
- 1エポック毎に検証用データに対する損失関数を計算
実装は以下のようになります。
# Parameter for mdoel
## Learning Rate
lr=0.00005
## Epoch Number
epochs=1000
## Mini-Batch size
batch_size=64
## How many epochs to stop train if valid loss is not decreasing
patience=20
model=TransformerModel().to(device)
criterion=nn.MSELoss()
optimizer=torch.optim.AdamW(model.parameters(),lr=lr)
scheduler=torch.optim.lr_scheduler.StepLR(optimizer,1.0,gamma=0.95)
earlystopping=EarlyStopping(patience)
train_loss_list=[]
valid_loss_list=[]
for epoch in range(1,epochs+1):
# train
model.train()
total_loss_train=0.0
for batch, i in enumerate(range(0,len(train_data),batch_size)):
data,targets=get_batch(train_data,i,batch_size)
optimizer.zero_grad()
output=model(data)
loss=criterion(output,targets)
loss.backward()
optimizer.step()
total_loss_train+=loss.item()
scheduler.step()
total_loss_train=total_loss_train/len(train_data)
#valid
model.eval()
total_loss_valid=0.0
for i in range(0,len(valid_data),batch_size):
data,targets=get_batch(valid_data,i,batch_size)
output=model(data)
total_loss_valid+=len(data[0])*criterion(output, targets).cpu().item()
total_loss_valid=total_loss_valid/len(valid_data)
#etc
train_loss_list.append(total_loss_train)
valid_loss_list.append(total_loss_valid)
if epoch%10==0:
print(f'{epoch:3d}:epoch | {total_loss_train:5.7} : train loss | {total_loss_valid:5.7} : valid loss')
earlystopping((total_loss_valid),model)
if earlystopping.early_stop:
print(f'{epoch:3d}:epoch | {total_loss_train:5.7} : train loss | {total_loss_valid:5.7} : valid loss')
print("Early Stop")
break
plt.xlabel('epoch')
plt.ylabel('train_loss')
plt.plot(train_loss_list)
plt.show()
plt.xlabel('epoch')
plt.ylabel('valid_loss')
plt.plot(valid_loss_list)
plt.show()
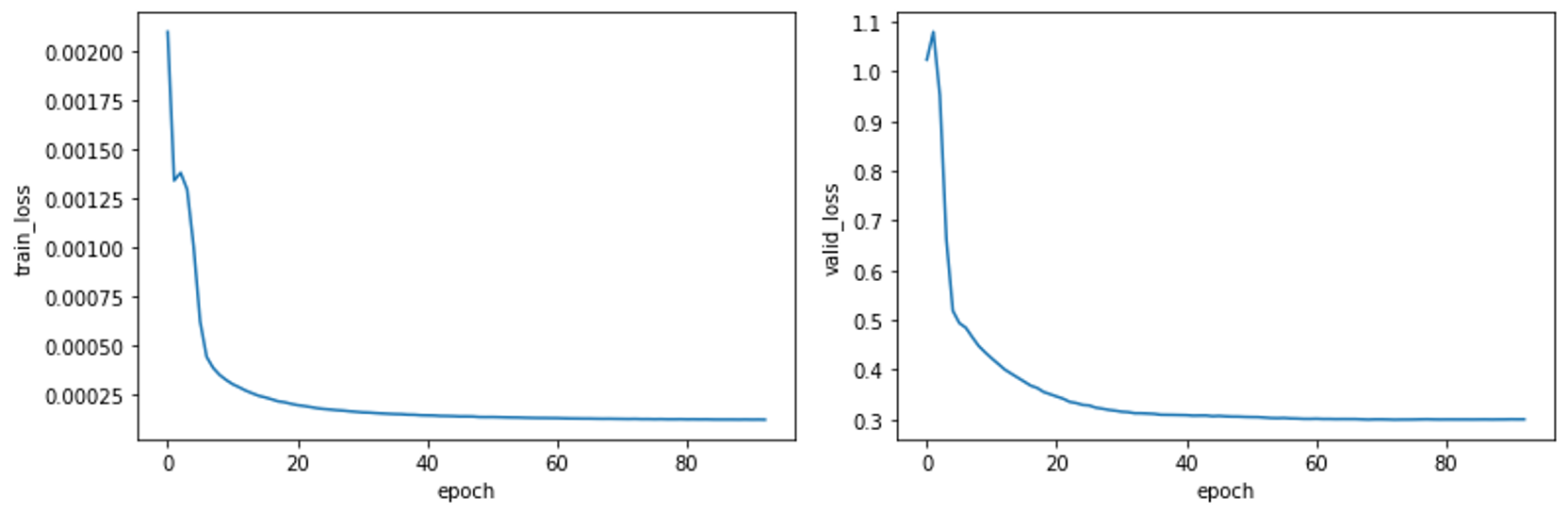
上記を実行した場合の訓練データと検証データそれぞれに対するlossの推移は以下のようになり、lossはエポックが進むたびに減少しており、学習が問題なく進んでいることがわかります。
推論
作成したモデルを用いて実際のデータとモデルの予測した値を比較してみます。
出力結果の最終要素、つまり予測された5営業日後の株価と実際の株価をプロットすると以下のようになります。
model.eval()
result=torch.Tensor(0)
actual=torch.Tensor(0)
with torch.no_grad():
for i in range(0,len(valid_data)-1):
data,target=get_batch(valid_data,i,1)
output=model(data)
result=torch.cat((result, output[-1].view(-1).cpu()),0)
actual=torch.cat((actual,target[-1].view(-1).cpu()),0)
plt.plot(actual,color='red',alpha=0.7)
plt.plot(result,color='black',linewidth=1.0)
plt.show()
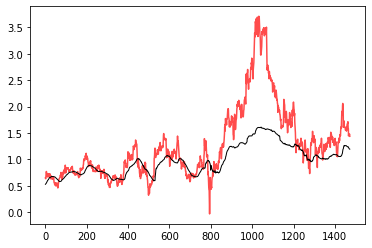
この結果から推測された株価では、急な株価変動が起こった場合に大きなずれが生じていると分かります。
このような急激な価格変動は株式会社の決算情報や外部の要素等によって引き起こされている可能性が高いです。今回作成したモデルではインプットとして、株価のみを与えているため、株価の動きの特徴を見ることで次の値を予測するため、トレード手法でいうテクニカル分析のみに対応しています。そのため、このような大きな変動は今回作成したモデルでは予測不可というのが正しい挙動です。
一方で今回作成したモデルはGoogle Colaboratory(GPU使用)環境で実行した場合、学習の時間を含め5分以下、とかなり高速です。その点を踏まえるとテクニカル分析としては十分に予測できていると思います。
最後に、上述の急激な価格変動を予測できるようにする改善方法をいくつか挙げておきます。その他改善方法等あればコメントいただけると幸いです。
- 決算情報を入力データに追加する。
- 自然言語処理を用いて、ニュースなどの情報を取り入れる。(かなり計算量は増えますが)