はじめに
先月データサイエンス100本ノック(構造化データ加工編)が出てデータ分析の教材がまた一つ充実したという感じがありますが、この問題集はDockerなどのツールにある程度慣れていないと取り組めない設計になっているようです。
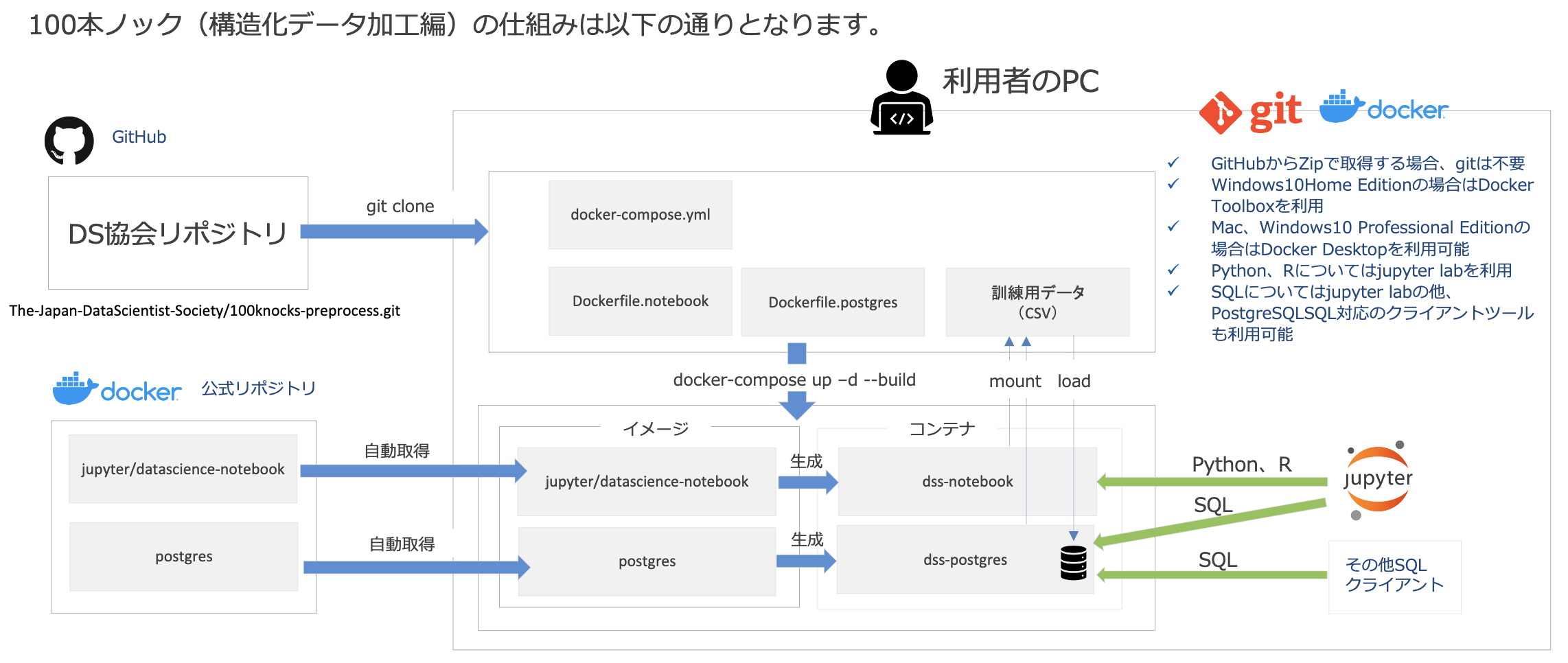
確かにDockerはデータ分析分野でも重要な技術になってきているので、エンジニアでなくても覚える価値は十分ありますし、SQLなどDBまわりの知識ももちろん大事です。ただ、PythonやRを使った分析をちょっと試してみたいだけ、という場合にはDockerやSQLにも同時に取り組もうとすると負荷が重すぎるかもしれません。
この記事では、「ひとまず手元でCSVのデータハンドリングができればOK」くらいのスタンスの方向けに、DockerもDBもSQLも使わずに100本ノックを解くための環境の整え方についてまとめてみます。
前提
-
pipやAnacondaで入れたJupyterLabが使える
JupyterLabはJupyter Notebookなどで代用できますが、ここではJupyterLabをおすすめします。
方法
-
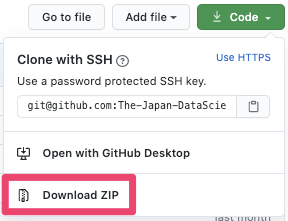
GitHubリポジトリからzipファイルをダウンロード・解凍(またはgit clone)
-
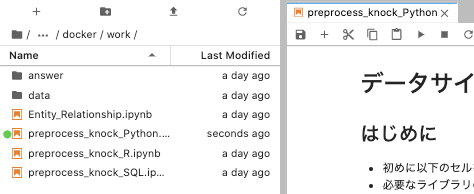
JupyterLabで、解凍されたフォルダ内をdocker > workと進み、preprocess_knock_Python.ipynbまたはpreprocess_knock_R.ipynbを開く
-
最初のセルのコードを以下のように書き換えて実行
import pandas as pd
df_customer = pd.read_csv('data/customer.csv')
df_category = pd.read_csv('data/category.csv')
df_product = pd.read_csv('data/product.csv')
df_receipt = pd.read_csv('data/receipt.csv')
df_store = pd.read_csv('data/store.csv')
df_geocode = pd.read_csv('data/geocode.csv')
df_customer <- read.csv("data/customer.csv")
df_category <- read.csv("data/category.csv")
df_product <- read.csv("data/product.csv")
df_receipt <- read.csv("data/receipt.csv")
df_store <- read.csv("data/store.csv")
df_geocode <- read.csv("data/geocode.csv")
以上で、100本ノックを解き始めることができます。
おわりに
Dockerは重要な技術ですが、学ぶためにそれなりに時間がかかるほかPC上で動かすにもある程度のメモリ等が必要になります。データサイエンス100本ノックのケースでは、DockerがDBとどう関わるのか知る必要も出てきます。
そのあたりで挫折しそうな方の参考になれば、と思っての投稿でした。
補足
JupyterLabではなくColabを使う方法もあるようです。