はじめに
今回私は最近はやりのchatGPTに興味を持ち、深層学習について学んでみたいと思い立ちました!
深層学習といえばPythonということなので、最終的にはPythonを使って深層学習ができるとこまでコツコツと学習していくことにしました。
ただ、勉強するだけではなく少しでもアウトプットをしようということで、備忘録として学習した内容をまとめていこうと思います。
この記事が少しでも誰かの糧になることを願っております!
※投稿主の環境はWindowsなのでMacの方は多少違う部分が出てくると思いますが、ご了承ください。
最初の記事:Python初心者の備忘録 #01
前の記事:Python初心者の備忘録 #08 ~DSに使われるライブラリ編03~
次の記事:Python初心者の備忘録 #10 ~DSに使われるライブラリ編05~
今回はSeabornについてまとめております。
■学習に使用している資料
Udemy:米国データサイエンティストがやさしく教えるデータサイエンスのためのPython講座
■Seaborn
▶Seabornとは
MatPlotlibのラッパーライブラリで、MatPlotlibを基礎によりビジュアライズされたグラフを作成することができるライブラリ。
使用するにはimport seaborn as snsでインポートする必要がある。
※内部でMatPlotlibを使用しているので、JupyterLabでは%matplotlib inlineと書く必要がある。
# seabornはsnsとしてインポート
import seaborn as sns
%matplotlib inline
▶ヒストグラム(distplot)
※新しいバージョン(Seaborn:0.11.0以上)ではsns.displot()としてください。sns.distplot(data)で簡単にヒストグラムを作成可能。
Seabornではデフォルトで、ヒストグラムの正規化やカーネル密度推定(KDE)による確率密度関数(PDF)を同時に描画してくれる。
もし、正規化やPDFが必要なければ引数にnorm_hist=Falseやkde=Falseを与えることで、ただのヒストグラムを表示できる。
sns.set()などのスタイル変更の関数も多数用意されている。
関数の返り値はMatPlotlibのaxesと同じなので、axesに使用していた関数を呼び出すことが可能。※他のsnsプロット関数も同様
df = pd.read_csv('tmdb_5000_movies.csv')
sns.distplot(df['vote_count'])
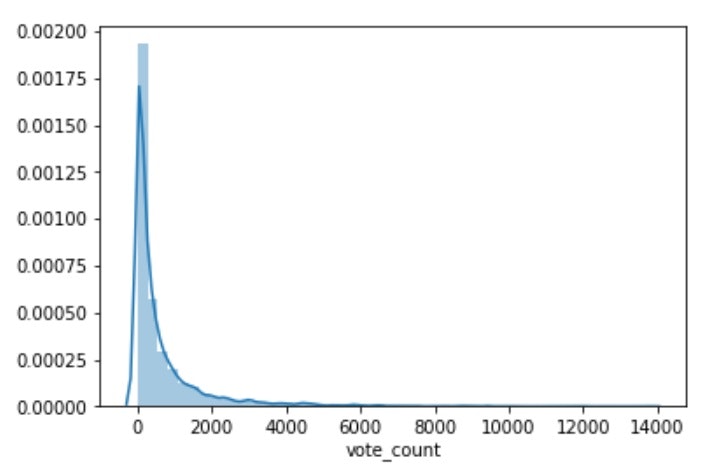
※青線がPDF
# normalize(正規分布)ではなくcountを見る
sns.distplot(df['vote_count'], norm_hist=False, kde=False)
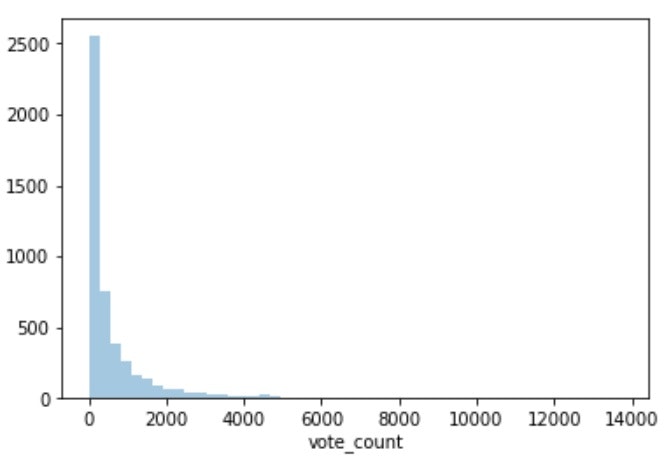
# スタイルが変わる
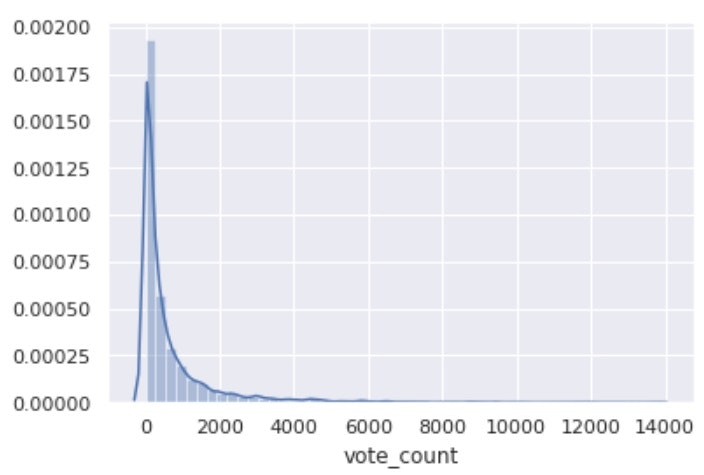
sns.set()
sns.distplot(df['vote_count'])
▶散布図
・sns.jointplot()
2数値間の散布図を表示できる。
sns.jointplot(x, y)で作図でき、散布図だけでなくそれぞれのヒストグラムも表示してくれる。
kind=''で表示方法の変更が可能で、下記などがある。
・reg:2数値間の大体の相関を実線で表示。
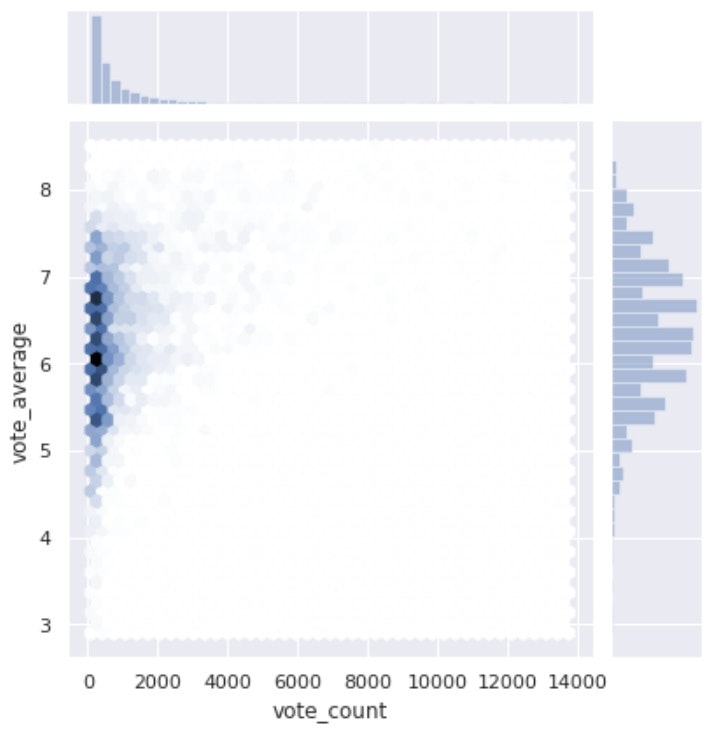
・hex:プロットの密集具合を色の濃さで表す。
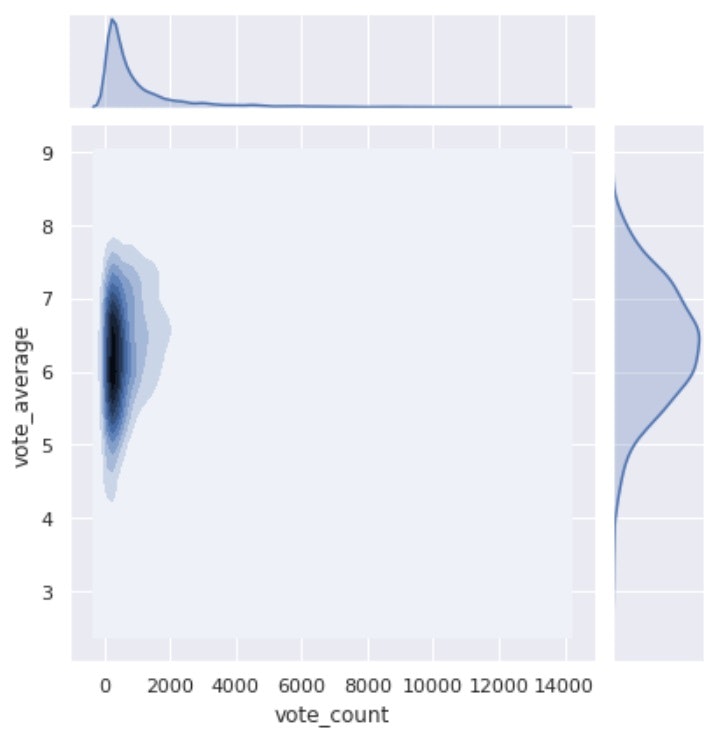
・kde:それぞれの確率密度関数に基づいて、地図の標高を表すような形で表示
※この時はalphaなどのstyle引数は渡し方が普通と異なるので注意。
# 散布図+ヒストグラム
sns.jointplot(x='vote_count', y='vote_average', data=df, alpha=0.3)
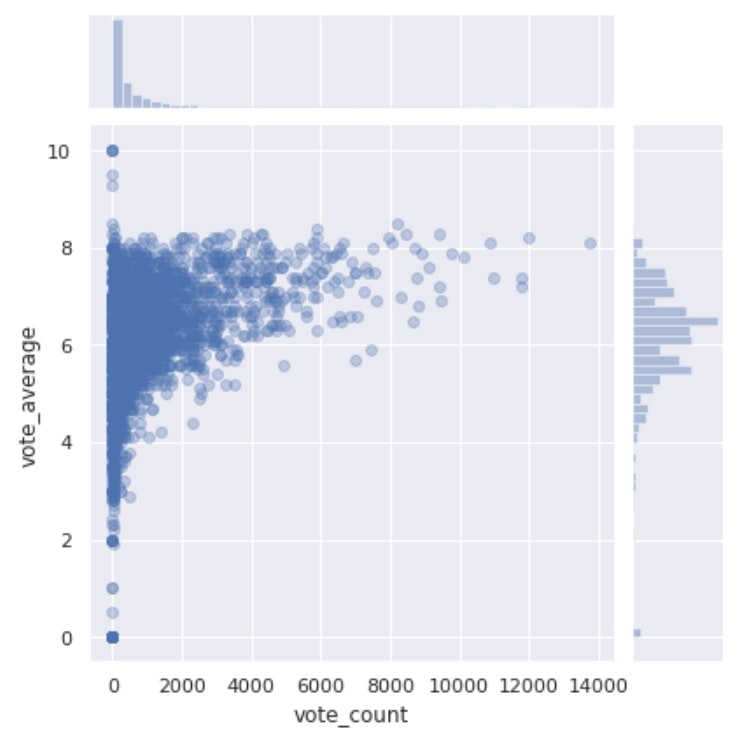
# kind='reg'
df = pd.read_csv('tmdb_5000_movies.csv')
# 100未満は信頼性が低いとする
df = df[df['vote_count'] > 100]
sns.jointplot(x='vote_count',
y='vote_average',
data=df, kind='reg',
joint_kws = {'scatter_kws': dict(alpha=0.3)}) # styleの渡し方が異なる

# kind='hex'
sns.jointplot(x='vote_count', y='vote_average', data=df, kind='hex')
# kind='kde'
sns.jointplot(x='vote_count', y='vote_average', data=df, kind='kde')
・sns.pairplot()
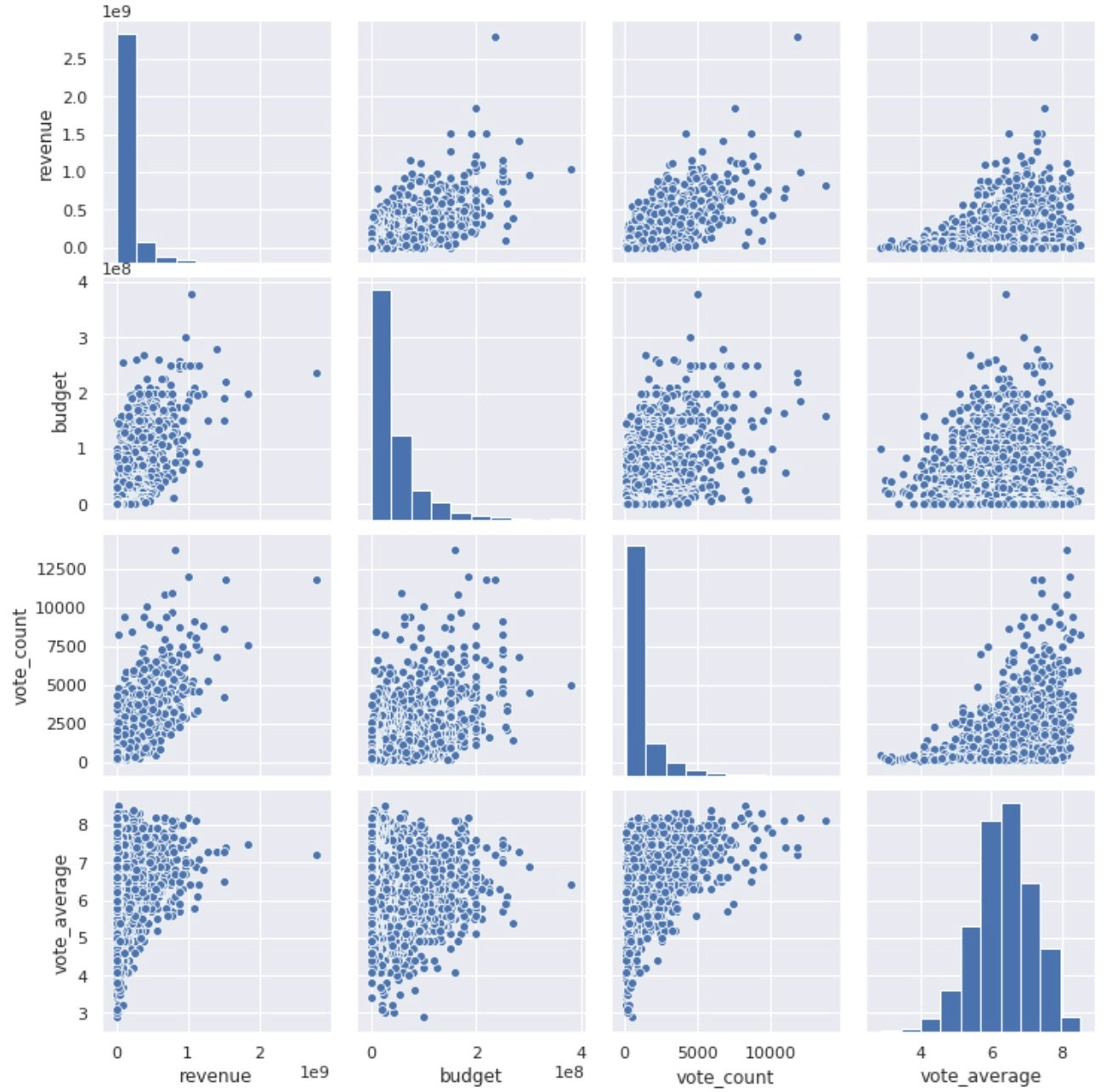
DataFrame内のすべての数値項目の各2数値間のグラフをすべて表示する。
同じ数値同士の場合は、その数値のヒストグラムを表示する。
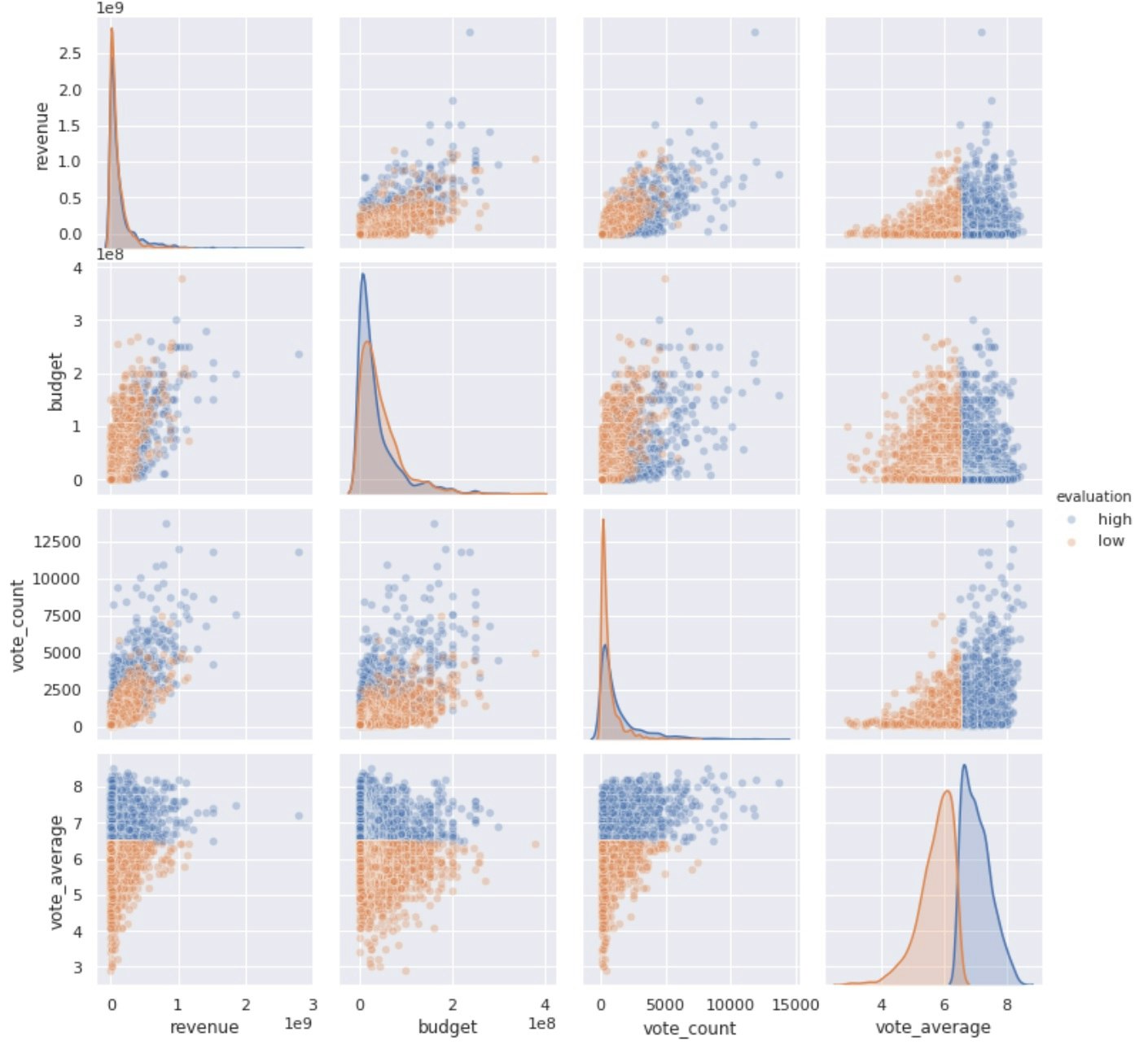
hue=categoryという引数を指定すると、categoryそれぞれのuniqueなデータごとに色分けしてプロットしてくれる。
# DataFrameの全ての数値カラムでpairplotを作る
# sns.pairplot(df)
# 表示したいカラムのみに絞ることも可能
sns.pairplot(df[['revenue', 'budget', 'vote_count', 'vote_average']])
#hue引数で,カテゴリ別に色付け
vote_average_median = df['vote_average'].median()
# vote averageが下位50%だったらlow, 上位50%だったらhigh
df['evaluation'] = df['vote_average'].apply(lambda x: 'high' if x > vote_average_median else 'low')
sns.pairplot(df[['revenue', 'budget', 'vote_count', 'vote_average', 'evaluation']],
hue='evaluation',
plot_kws={'alpha':0.3},
#diag_kind='hist' ⇐ 対角線のヒストグラムの表示形式を指定できる
)
▶Categorical Plot
前項のhue='evaluation'のように何かカテゴリーが関係しているグラフのこと。
・sns.barplot()
sns.barplot(x, y)でxというカテゴリーごとに、yの平均を棒グラフで表示する。
この時、エラーバー(95%の信頼区間:CI)も同時に表示する。
- 信頼区間
- ある母集団から抽出した標本に対して同じ統計を取った際に、○○%の標本はこの範囲に収まるという推定区間
デフォルトでは平均をとるが、引数にestimator=''を与えることで別の統計量をプロットすることも可能。
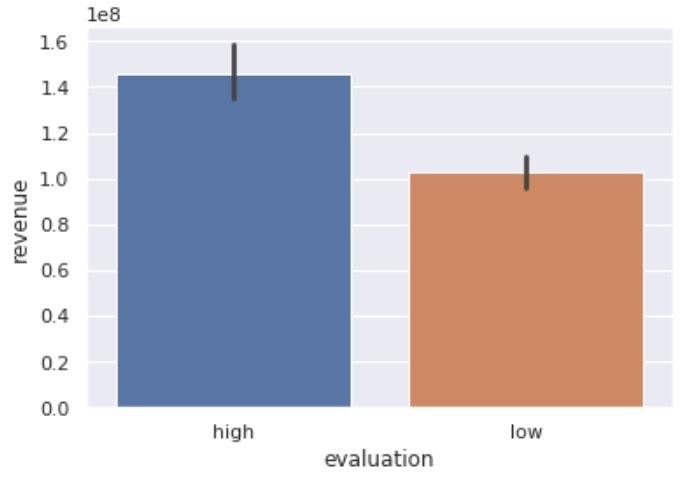
# 評価が高いものと低いもののrevenueのグラフ
# デフォルトでは平均値が棒グラフで表示される
sns.barplot(x='evaluation', y='revenue', data=df)
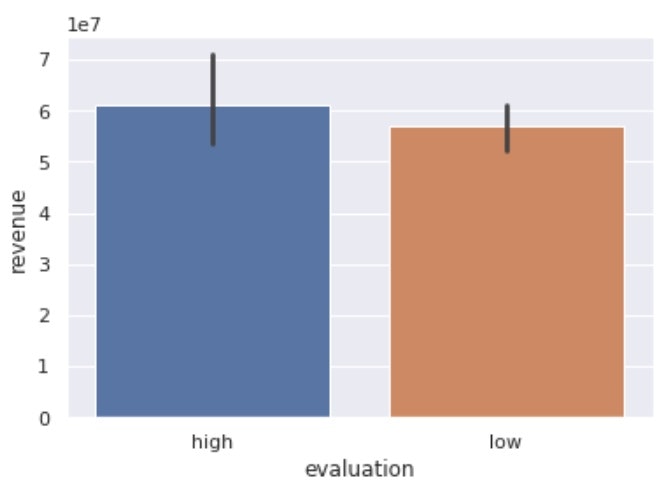
# estimator引数にaggregate functionを入れる
# 中央値をみる
sns.barplot(x='evaluation', y='revenue', data=df, estimator=np.median)
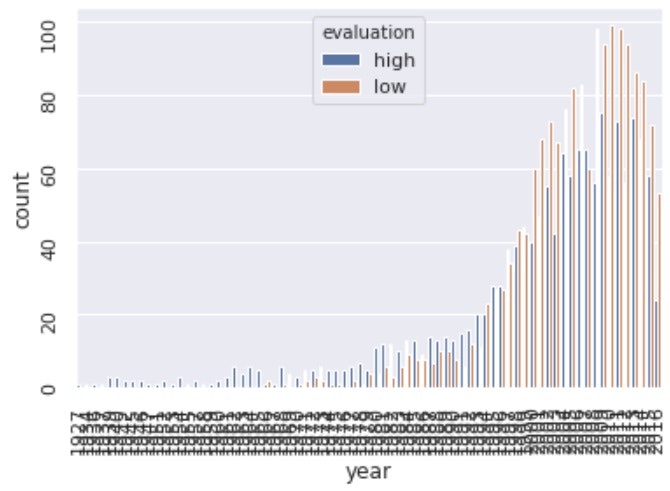
・sns.countplot()
sns.countplot(x)でxというカテゴリーの単純な数を棒グラフで表示できる。
引数にhue=categoryを指定することで、category内のunipueな値毎にプロットしてくれる。
# 西暦別のカウント
df['year'] = df['release_date'].apply(lambda x: x[:4])
# countplotの戻り値はmatplotlibのaxes
ax = sns.countplot(x='year', data=df, hue='evaluation')
ax.tick_params(rotation=90)
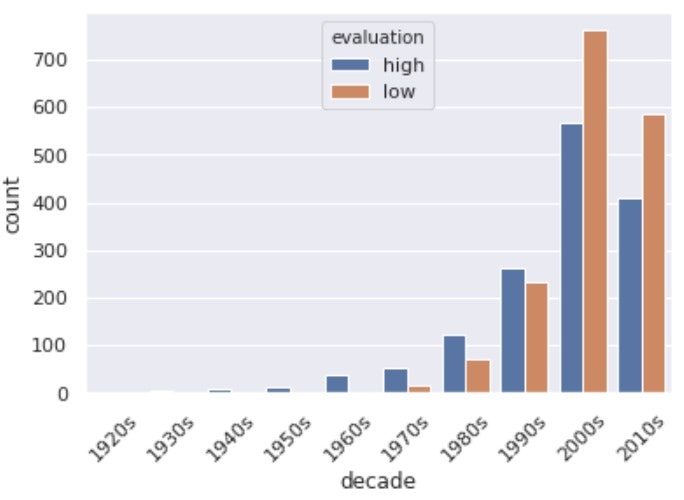
# 上記だと見にくいので、年代カラムを作る 例)2012->2010s
df['decade'] = df['release_date'].apply(lambda x: x[:3] + '0s')
sns.countplot(x='decade', data=df.sort_values('decade'), hue='evaluation')
# 直接pltで装飾することも可能
plt.xticks(rotation=45)
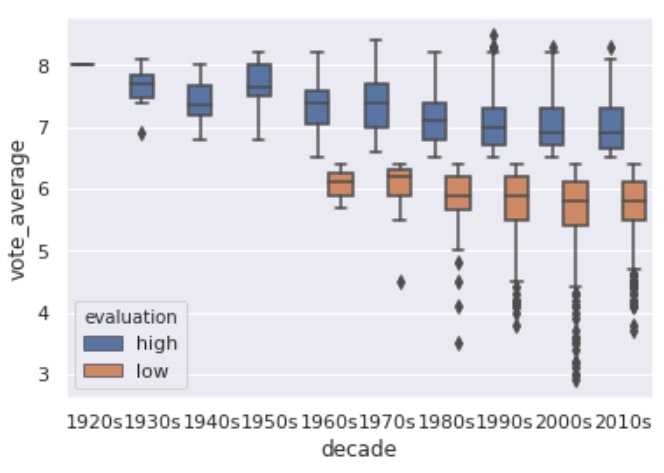
・sns.boxplot()
sns.boxplot(x, y)でx内のカテゴリ別にyの値の箱ひげ図を表示できる。
# 箱ひげ図(boxplot)
sns.boxplot(x='decade', y='vote_average', data=df.sort_values('decade'), hue='evaluation')
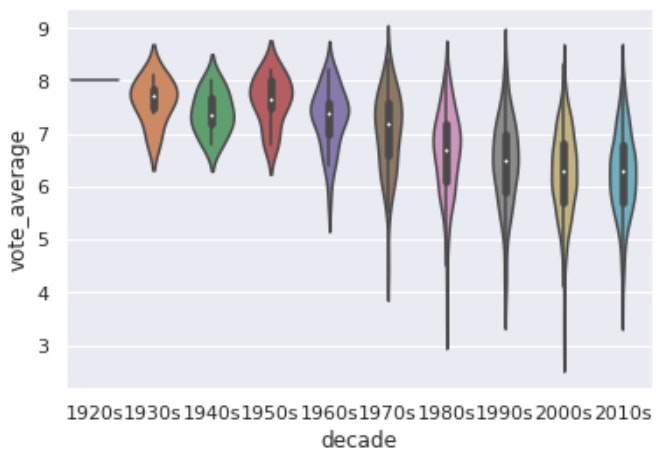
・sns.violinplot()
箱ひげ図の派生で、カテゴリ別に正規化した形で表示してくれる。
データの偏りがより視覚的に見えるようになる。
# violin plot
sns.violinplot(x='decade', y='vote_average', data=df.sort_values('decade'))
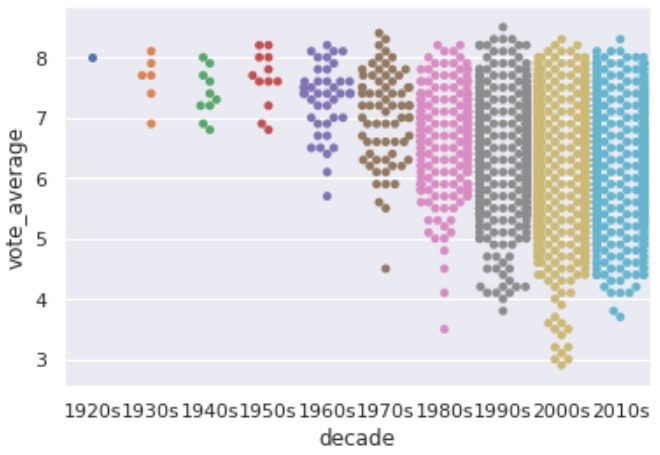
・sns.swarmplot()
箱ひげ図の派生で、実際にプロットしてデータの偏りを表示する。
これにより、データの数も見れるのでより詳細な偏りを知ることができる。
# swarm plot
sns.swarmplot(x='decade', y='vote_average', data=df.sort_values('decade'))
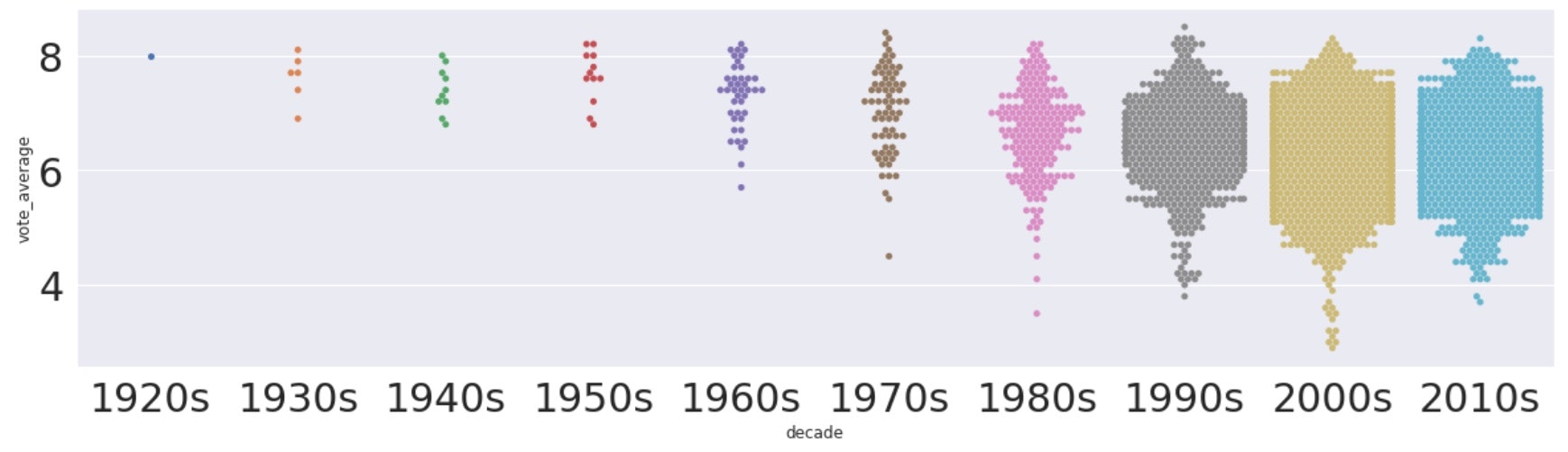
▶axesを使ったstyle編集
SeabornはMatPlotlibのラッパーライブラリなので、axesオブジェクトに対してスタイルの指定を行い、そのオブジェクトをax=axesとそれぞれのsns関数に渡すことで、スタイル編集を適用することができる。
# オブジェクトの生成とスタイルの指定
fig, ax = plt.subplots(figsize=(20, 5))
ax.tick_params(labelsize=30)
# axesオブジェクトを引数に入れる
sns.swarmplot(ax=ax, x='decade', y='vote_average', data=df.sort_values('decade'))
▶Heatmap
何か値の表があった際に、値の大きさによって色付けを行い、一目で値の大小を見分けられるようにしたグラフ。
混同行列(分類器:AIモデル)の結果などによく使われる。
sns.heatmap(x)で相関表xについてのHeatmapを作成できる。
df.groupby('columnA', 'columnB').mean()[['column_values']].pivot_table(values='column_value', index='columnA', columns='columnB')で2種のカテゴリカラムについてのを引数に渡すことで、2カラムのcategoryごとの統計量もグラフにすることができる。
引数にannot='True'を指定することでそれぞれの値をグラフに追加でき、cmap='color'でグラフの色を変更できる。
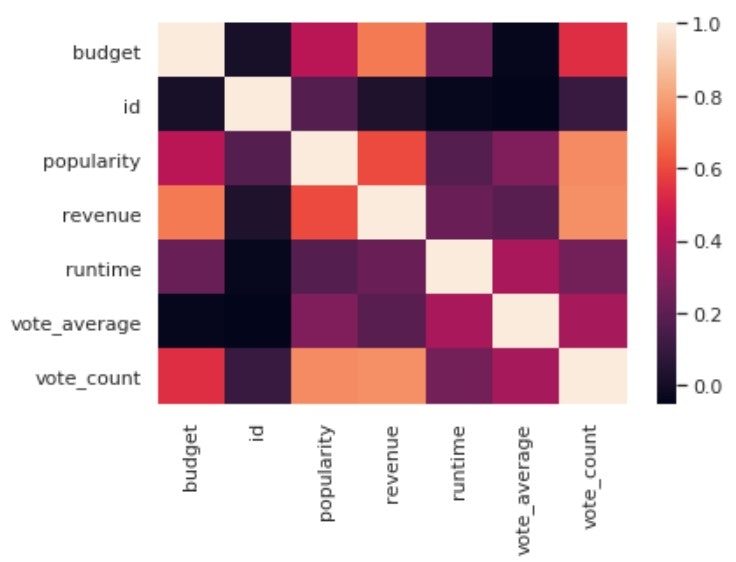
・df.corr()
簡単にdf内の数値カラムに対して、それぞれの相関表を作成してくれる関数。
まずはこの関数で相関表を作成してからsns.heatmap()で描画する。
# 相関表 (Correlation Matrix)
df = pd.read_csv('tmdb_5000_movies.csv')
# 値が0を含むrowを除く(信頼性が低いデータのため)
df = df[(df!=0).all(axis=1)]
corr = df.corr()
# heatmapの表示
sns.heatmap(corr)
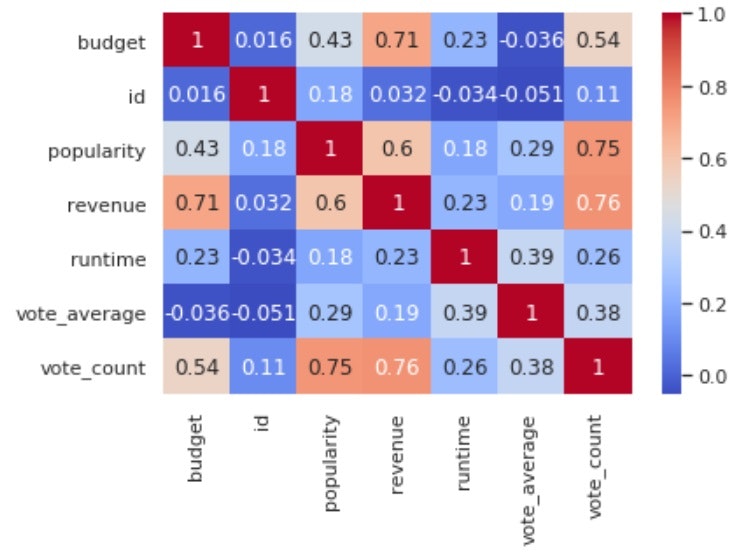
# 相関値の追加と色の変更
sns.heatmap(corr, cmap='coolwarm', annot=True)
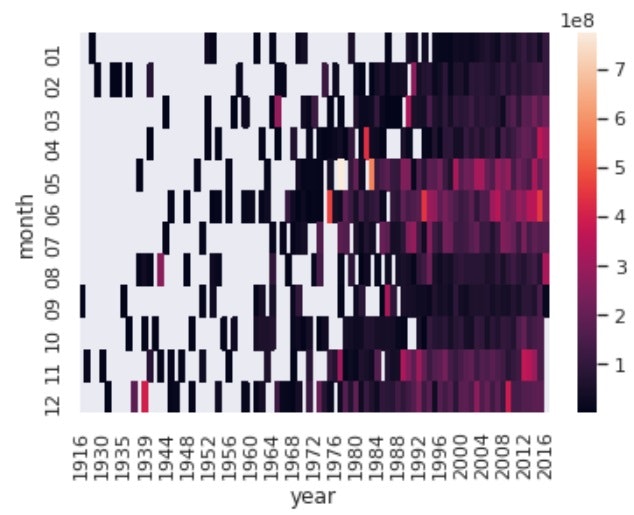
# 2つのカテゴリカラムの統計量のheatmap
# 今回は年と月の'revenue'の中央値
df['year'] = df['release_date'].apply(lambda x: x[:4])
df['month'] = df['release_date'].apply(lambda x: x[5:7])
# pivot_tableの作成
revenue_df = df.groupby(['year', 'month']).mean()[['revenue']].pivot_table(index='month', columns='year', values='revenue')
# heatmapの表示
sns.heatmap(revenue_df)
▶Style変更と付属情報
sns.set(context='notebook', style='darkgrid', palette='deep')でそれぞれStyleを変更することができる。
それぞれの引数はsns.set_context('')のように「.set_ + 引数名」での指定も可能。
sns.set()で指定するpaletteは、hueで指定したカテゴリに適用される。
もともとのグラフに適用したい場合は、sns,displot(palette='deep')のようにSeabornのプロット関数の引数で指定する必要がある。
plt.title('text')などのようにMatPlotlibと同じような方法でStyle変更や付属情報の追加が可能。
# context引数 : ’paper’, ‘notebook’, ‘talk’, ‘poster’
sns.set(context='poster')
# style引数:‘darkgrid’, ‘whitegrid’, ‘dark’, ‘white’, ‘ticks’
sns.set(style='whitegrid')
# palette引数 : 参考:https://matplotlib.org/3.1.3/tutorials/colors/colormaps.html
# seabornのpalette:deep, muted, bright, pastel, dark, colorblind
# 「hue=」で指定したカテゴリに対して適用される。
sns.set(context='notebook', style='ticks', palette='dark')
# 元のグラフに適用したい場合はsnsのプロット関数に引数として指定する。
sns.violinplot(palette='dark')
# snsは内部でpltを使っているので,matplotlibの装飾も同様に可能
sns.distplot(df['vote_average'])
plt.xlabel('Evaluation Score')
plt.title('Distribution of scores')
plt.savefig('saved_seaborn.png')
次の記事
まだ