はじめに
今回私は最近はやりのchatGPTに興味を持ち、深層学習について学んでみたいと思い立ちました!
深層学習といえばPythonということなので、最終的にはPythonを使って深層学習ができるとこまでコツコツと学習していくことにしました。
ただ、勉強するだけではなく少しでもアウトプットをしようということで、備忘録として学習した内容をまとめていこうと思います。
この記事が少しでも誰かの糧になることを願っております!
※投稿主の環境はWindowsなのでMacの方は多少違う部分が出てくると思いますが、ご了承ください。
最初の記事:Python初心者の備忘録 #01
前の記事:Python初心者の備忘録 #05
次の記事:Python初心者の備忘録 #07 ~DSに使われるライブラリ編02~
本記事からはデータサイエンスでよく使われるPythonライブラリを紹介していこうと思います。
今回はDockerによる環境構築とNumPyについてまとめております。
■学習に使用している資料
Udemy:米国データサイエンティストがやさしく教えるデータサイエンスのためのPython講座
■Dockerでの環境構築
実際に手を動かしながらライブラリについて学習したいという方はDockerで簡単に学習環境が作成できるので、下記手順でDocker環境の作成をお願いします。
※本記事ではWindows向けに書かれているので、Macを使用されている方は下記記事を参考。
データサイエンスのためのPython入門①〜DockerでJupyter Labを使う〜
まずWindowsでDockerを使用する場合、Linux環境を用意する必要があるが、PowerShellを開いて、wsl --installと打つだけで完了。
詳しくはWSL2のインストールを分かりやすく解説【Windows10/11】を参照。
次にDocker Hubの登録と、Docker Desktopのインストールを行う。
1.下記URLからDocker Hubへのサインアップを行う。
https://hub.docker.com/
※Usernameは自分のリポジトリ名となるので、慎重に決定する。
2.次に下記サイトからWindows用のDocker Desktopをダウンロードし、Docker Desktop installer.exeを起動して、セットアップを行う。
https://www.docker.com/products/docker-desktop/
3.任意の場所にdocker_files、workというフォルダを用意し、docker_filesに次の2ファイルを格納する。
version: '3.10'
services:
basic:
build:
context: .
dockerfile: Dockerfile
image: ds-python
container_name: ds-python
ports:
- "8888:8888"
volumes:
- "workフォルダの格納場所/work:/work"
restart: on-failure
FROM ubuntu:latest
# update
RUN apt-get -y update && apt-get install -y \
libsm6 \
libxext6 \
libxrender-dev \
libglib2.0-0 \
libgl1-mesa-glx \
sudo \
wget \
vim
#install anaconda3
WORKDIR /opt
# download anaconda package and install anaconda
# archive -> https://repo.anaconda.com/archive/
RUN wget https://repo.anaconda.com/archive/Anaconda3-2021.05-Linux-x86_64.sh && \
sh /opt/Anaconda3-2021.05-Linux-x86_64.sh -b -p /opt/anaconda3 && \
rm -f Anaconda3-2021.05-Linux-x86_64.sh
# set path
ENV PATH /opt/anaconda3/bin:$PATH
# update pip and install packages
RUN pip install --upgrade pip && \
pip install opencv-python && \
pip install nibabel
WORKDIR /
RUN mkdir /work
# execute jupyterlab as a default command
CMD ["jupyter", "lab", "--ip=0.0.0.0", "--allow-root", "--LabApp.token=''"]
上記Dockerfileは2024/04/13に更新しました。
※workフォルダはローカルとDockerの仮想環境で共有のフォルダとなるので、ここでデータのやり取りを行うことができる。
4.コマンドプロンプトでdocker_files直下に移動し、下記コマンドを実行する。
docker-compose up -d
5.下記URLにアクセスすることで必要なライブラリが入ったJupyterLabを使用することができる。
http://localhost:8888/
※dockerを停止したい場合はdocker-compose downを実行する
■NumPy
▶NumPyとは
行列計算が得意なライブラリ
DS=Pythonとなったのは、このライブラリがあったからともいえる。
使用する際はimportする必要がある。
import numpy as np
# 「as np」として、np.○○と関数を使用するのが通例
▶NumPy Arrays(ndarray)
NumPyにおいて行列を作成する関数
np.array()で作成可能で、引数にlistを複数してすることで簡単に行列として扱うことができる。
作成した要素の方は普通のint型ではなく、NumPy特有のnumpy.int64となっているので注意
# ベクトルの作成も可能
vector = np.array([1, 2, 3]) # x軸、y軸、z軸の3次元表現ととらえることができる
print(vector) # ⇒[1 2 3]
# 行列の作成
matrix = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(matrix) # ⇒ [[1 2 3]
# [4 5 6]
# [7 8 9]]
# list同様にindexingで要素の取得も可能
matrix[0][0] # ⇒ 1
# 要素はint型ではない
type(matrix[0][0]) # ⇒ numpy.int64
▶dtype
np.arrayの第2引数にdtype=○○を渡すことで、ようそのデータタイプを指定することができる。
他にも.astype()でもともとあるndarrayのデータ型を変更することができる。
# NumPyは多くのdtypeが用意されているが,よく使うのは
# np.unit8 (u: unsigned つまり0~255) 普通の画像データはこれ
ndarray = np.array([1, 2, 3], dtype=np.uint8)
# np.float32 機械学習に使うデータを保存する時によく使う
ndarray = np.array([1, 2, 3], dtype=np.float32)
# np.float64 実際のモデル学習には64bitで学習することが多い
ndarray = np.array([1, 2, 3], dtype=np.float64)
# .astype()で元のndarrayのdtypeを変更可能
ndarray.astype(np.uint8)
▶ndarrayの演算
ndarray同士の演算では、それおぞれの要素ごとに演算を行うことができる。
Listでは不可能な動作なので、これもNumPyの強みの一つといえる。
rray1 = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
array2 = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 演算は要素毎の計算
array1 + array2 # ⇒ [[2 4 6]
# [8 10 12]
# [14 16 18]]
array1 - array2 # ⇒ [[0 0 0]
# [0 0 0]
# [0 0 0]]
array1 / array2 # ⇒ [[1 1 1]
# [1 1 1]
# [1 1 1]]
array1 * array2 # ⇒ [[1 4 9]
# [16 25 36]
# [49 64 81]]
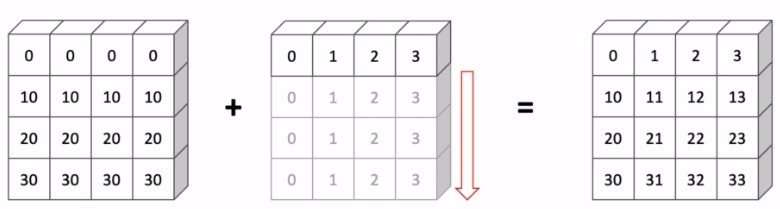
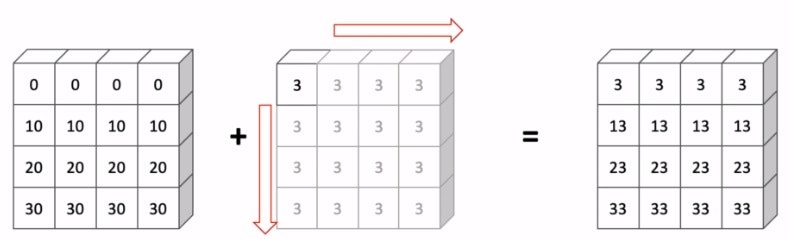
▶Broadcasting
演算の際に要素数が同じ数じゃなくても、自動的に拡張して計算をしてくれる機能
拡張する際のルールが厳密には存在するが、直感的な理解でも十分
# 要素の数が一致してなくても、ちゃんと計算できる
array1 = np.array([1, 2, 3])
array2 = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
array1 + array2 # ⇒ [[2 4 6]
# [5 7 9]
# [8 10 12]]
Broadcastingの例
▶.shape
作成したndarrayの構成を出力することができる。
出力の際はそれぞれの次元に何個の要素が含まれているかを出力する。
出力された結果は、右から1次元、2次元…を表している。
NumPyでは、次元のことをrankと表現する。
ndarray = np.array([[1, 2], [3, 4], [5, 6]])
# .shapeでshapeを確認
ndarray.shape # ⇒ (3, 2) 1次元は2個、2次元は3個
# [[1, 2]
# [3, 4]
# [5, 6]]
# 以下の2つは似てるようでshapeの結果が異なるので注意
ndarray1 = np.array([1, 2, 3])
ndarray2 = np.array([[1, 2, 3]])
print(ndarray1.shape) # ⇒ (3,)
print(ndarray2.shape) # ⇒ (1, 3)
▶.reshape()
作成したndarrayの構成を変更することもできる。
変更後の合成要素数が、元の要素数と同じでなければエラーとなるので、.shapeで確認するのが重要となってくる。
# reshapeでshapeを変更できる
ndarray.reshape(2, 3)
print(ndarray) # ⇒ [[1, 2, 3]
# [4, 5, 6]]
# サイズが合わないとエラーになる.3x2=6の元のarrayに対して1x3=3にreshapeはできない
ndarray.reshape(1, 3) # ⇒ エラー
▶次元の拡張 np.expand_dims(ndarray, axis)
ndarray引数に拡張したいndarray、axis引数にどのrankを追加するか指定することができる。
0で一番大きいrank、-1で一番小さいrank(rank1)にrankを追加することができる。
追加は、指定したrankの前にされる。
# rankを1つ追加
# shape: (3,) ->(1, 3)
expand_ndarray = np.expand_dims(ndarray1, axis=0)
# axis=-1にすると最後のrankを追加
# (3,) -> (3, 1)
expand_ndarray = np.expand_dims(ndarray1, axis=-1)
# 指定したrankの前に追加
# (1, 3) -> (1, 1, 3)
expand_ndarray = np.expand_dims(ndarray2, axis=1)
▶次元の削減 np.squeeze(ndarray)
ndarrayのそれぞれのrankで要素数が1のものを削除する。
# shapeで'1'のrankをなくす
# shape: (1, 4, 1, 3, 2) -> (4, 3, 2)
d3_ndarray = np.squeeze(d5_ndarray)
▶.flatten()
ndarrayを1次元にreshapeすることができる。
ndarray = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 1次元にする
ndarray.flatten() # ⇒ array([1, 2, 3, 4, 5, 6, 7, 8, 9])
▶IndexingとSlicing
ndarray内の要素は辞書型と同じような書き方で、取り出すことができる(Indexing)
また、複数の要素を同時に取得することも可能(Slicing)
# 一列の場合は簡単
ndarray = np.array([1, 2, 3, 4])
# indexは0から
print(ndarray[0]) # ⇒ 1
# 最後は-1
print(ndarray[-1]) # ⇒ 4
# N-dimentional
ndarray = np.array([[1, 2], [3, 4], [5, 6]])
#まずは2段階で考える
# [0]で最初の要素[1, 2]を取得
print(ndarray[0]) # ⇒ [1 2]
# それに対してさらにindexing
print(ndarray[0][1]) # ⇒ 2
# ndarrayでは以下のようにまとめて記述するのが一般的
print(ndarray[0, 1]) #[一個目のindex, 二個目のindex]
# 画像の場合は(height, width, channel)の並びになるので覚えておく(後述)
# Slicing
# 一列の場合
ndarray = np.array([1, 2, 3, 4])
# [N:M] N以上M未満を返す
print(ndarray[1:3]) # ⇒ [2, 3]
# Nを省略すると最初からM未満
print(ndarray[:3]) # ⇒ [1, 2, 3]
# Mを省略するとNから最後の要素まで
print(ndarray[1:]) # ⇒ [2, 3, 4]
# 最後の要素はindex=-1なのでこのようにすれば'最後から〇〇番目の要素まで'
print(ndarray[:-2]) # ⇒ [1, 2]
# もしくは'後ろ〇番目の要素から'
print(ndarray[-2:]) # ⇒ [3, 4]
# ':'のみだと,全ての要素を取得
print(ndarray[:]) # ⇒ [1, 2, 3, 4]
# N-dimentionalの場合
array = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], [13, 14, 15, 16]])
# [行, 列]
# まずは1つ目
array[:2] # ⇒ array([[1, 2, 3, 4],
# [5, 6, 7, 8]])
# からの2つ目
array[:2, 1:] # ⇒ array([[2, 3, 4],
# [6, 7, 8]])
# これとは同じにならないことに注意
array[:2][1:] # ⇒ array([[5, 6, 7, 8]])
# 列だけ抽出することも可能
array[:, 2] # ⇒ array([3, 7, 11, 15])
▶NumPyの関数でndarrayを作成
※引数で=○○で指定されているのはdefaultの値
・np.arange(start=0, stop, step=1)
pythonの.range()関数と挙動は同じ
start以上、stop未満の間の数字をstepおきに出力してndarrayを生成する。
# stopとstepは省略可能.その場合start=0, step=1が入る
np.arange(5) # np.arange(0, 5, 1)と同じ ⇒ array([0, 1, 2, 3, 4])
np.arange(1, 10, 2) # ⇒ array([1, 3, 5, 7, 9])
# stepを負の数にすれば降順も可能
np.arange(10, 1, -1) # ⇒ array([10, 9, 8, 7, 6, 5, 4, 3, 2])
・np.linspace(start, stop, num=50)
start以上、stop以下の数字をnum個で区切ったリストを出力する。
※endpoint=falseを引数に加えることで、stop未満で計算してくれる。
# stopを含むので注意
np.linspace(0, 10, 11) # ⇒ array([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.])
・np.logsspace(start, stop, num=50, base=10)
start以上、stop以下の数字をnum個に区切って、base ** その数字をリストとして出力する。
※endpoint=falseを引数に加えることで、stop未満で計算してくれる。
# 10**start以上10**stop以下の数をnum個で区切った数のリスト(logarithm)
np.logspace(0, 3, 10) # ⇒ array([1., 2.15443469, 4.64158883, 10., 21.5443469, 46.41588834, 100., 215.443469, 464.15888336, 1000.])
・np.zeros(shape)
要素がすべて0のshapeの行列を作成
# 要素が全て0のndarrayを作成
shape = (3, 3)
np.zeros(shape) # ⇒ array([[0., 0., 0.],
# [0., 0., 0.],
# [0., 0., 0.]])
# tupleではなくintをいれると,一列のarrayができる
np.zeros(3) # ⇒ array([0., 0., 0.])
・np.ones(shape)
.ones()の要素がすべて1バージョン
# 要素が全て1のndarrayを作成
shape = (3, 3)
np.zeros(shape) # ⇒ array([[1., 1., 1.],
# [1., 1., 1.],
# [1., 1., 1.]])
・np.eye(N)
N x Nの単位行列を作成
単位行列とは対角成分が全て1の正方行列のこと
np.eye(3) # ⇒ array([[1., 0., 0.],
# [0., 1., 0.],
# [0., 0., 1.]])
# N行M列の行列も作れる
np.eye(3, 4) # ⇒ array([[1., 0., 0., 0.],
# [0., 1., 0., 0.],
# [0., 0., 1., 0.]])
▶乱数生成(np.random)
・.rand()
1.0以下でランダムな数字を生成する。
本当にランダムな数字ではないが、ロジックに従って推測できないものとなっている(疑似乱数)
np.random.rand() # ⇒ 0.5861121281146473
# 生成される数字は毎回異なる
np.random.rand() # ⇒ 0.8751994062339193
# 引数を与えると、行列の作成も可能
np.random.rand(3, 2) # ⇒ array([[0.841998 , 0.48121293],
# [0.63081058, 0.7971742 ],
# [0.78018551, 0.66915064]])
・.seed()
引数に任意の値を指定することで、同じ乱数を生成することができる。
# seedを指定すると,毎回同じ乱数を生成してくれる
np.random.seed(1)
np.random.rand() # ⇒ 0.417022004702574
np.random.seed(1)
np.random.rand() # ⇒ 0.417022004702574
# 連続で乱数を作成しても、別の値にはなるが全体的にみると同じ乱数を生成している
np.random.seed(1)
np.random.rand() # ⇒ 0.417022004702574
np.random.rand() # ⇒ 0.025926231827891333
np.random.seed(1)
np.random.rand() # ⇒ 0.417022004702574
np.random.rand() # ⇒ 0.025926231827891333
・.randn()
平均0、分散1の標準正規分布に従って、乱数を生成する。
0から遠い数字ほど出現率が少なくなる。
# 標準正規分布(平均0, 分散1)からランダムの値が返される
np.random.randn(3, 3) # ⇒ array([[-0.52817175, -1.07296862, 0.86540763],
# [-2.3015387 , 1.74481176, -0.7612069 ],
# [ 0.3190391 , -0.24937038, 1.46210794]])
・.normal(mu, sigma)
任意の正規分布から乱数を生成したい場合に使用する。
muが平均で、sigmaが分散を表している。
# 任意の正規分布から乱数を生成
mu = 10
sigma = 1
np.random.normal(mu, sigma) # ⇒ 9.158252634343796
# 10に近い値が生成される
・.randint(low, high=None, size=None)
low以上、high未満の中からsizeの乱数を生成する。
highに引数を与えない場合は、0以上low未満から乱数を生成する。
size = (2, 3)
np.random.randint(10, 100, size=size) # ⇒ array([[96, 23, 19],
# [17, 73, 71]])
# high=Noneの場合は0以上low未満
np.random.randint(10) # ⇒ 3
・.choice()
引数に指定したndarrayの要素の中から、ランダムに値を取ってくる。
index_pool = np.arange(0, 10, 2) # ⇒ array([0, 2, 4, 6, 8])
np.random.choice(index_pool) # ⇒ 2
np.random.choice(index_pool) # ⇒ 6
▶統計量
ndarrayに対して、様々な統計値を確認することができる。
# 標準正規分布から乱数生成
std_norm = np.random.randn(5, 5) # ⇒ array([[-0.17242821, -0.87785842, 0.04221375, 0.58281521, -1.10061918],
# [ 1.14472371, 0.90159072, 0.50249434, 0.90085595, -0.68372786],
# [-0.12289023, -0.93576943, -0.26788808, 0.53035547, -0.69166075],
# [-0.39675353, -0.6871727 , -0.84520564, -0.67124613, -0.0126646 ],
# [-1.11731035, 0.2344157 , 1.65980218, 0.74204416, -0.19183555]])
#最大値を取得
std_norm.max() # ⇒ 1.6598021771098705
#最大値のindexを取得
std_norm.argmax() # ⇒ 22
#最小値を取得
std_norm.min() # ⇒ -1.1173103486352778
#最小値のindexを取得
std_norm.argmin() # ⇒ 20
#平均
std_norm.mean() # ⇒ -0.06134877883769695
#中央値
np.median(std_norm) # ⇒ -0.17242820755043575
#標準偏差 (standard deviation)
std_norm.std() # ⇒ 0.750373507574642
# axis引数で特定のaxisにて統計量を計算(axis=0: 列, axis=1: 行)
# 列ごとのmax
std_norm.max(axis=0) # ⇒ [1.14472371 0.90159072 1.65980218 0.90085595 -0.0126646]
# 行ごとのmax
std_norm.max(axis=1) # ⇒ [0.58281521 1.14472371 0.53035547 -0.0126646 1.65980218]
▶数学で使える便利関数
・np.sqrt()
引数に与えた値の平方根を返す。
# 平方根 (square root)
np.sqrt([1, 2, 3, 4]) # ⇒ array([1. , 1.41421356, 1.73205081, 2. ])
・np.log(ndarray)
ndarrayの要素それぞれがe(ネイピア数)の何乗か(指数)を返す。
つまり、「e ** x = ndarray」という式のxを返却してくれる。
ndarray = np.linspace(1, 10, 10) # ⇒ [1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
# Log関数 (logarithm)
# 底はe(ネイピア数)
np.log(ndarray) # ⇒ [0. 0.69314718 1.09861229 1.38629436 1.60943791 1.79175947 1.94591015 2.07944154 2.19722458 2.30258509]
・np.expo(ndarray)
指数関数
e ** ndarrayを返す。
# 指数関数(Exponential function)
# 底はe(ネイピア数)
expndarray = np.exp(ndarray) # ⇒ [2.71828183e+00 7.38905610e+00 2.00855369e+01 5.45981500e+01 1.48413159e+02 4.03428793e+02 1.09663316e+03 2.98095799e+03 8.10308393e+03 2.20264658e+04]
・np.e
ネイピア数を返す。
2.718281828459045
・np.sum(ndarray)
ndarrayの要素の合計を返す。
第2引数にaxis=○○で、行(1)列(0)ごとの合計を計算することも可能
array = np.arange(1, 11) # ⇒ [ 1 2 3 4 5 6 7 8 9 10]
np.sum(array) # ⇒ 55
#axis引数で行,列別に計算できる
array = array.reshape(2, 5) # ⇒ array([[ 1, 2, 3, 4, 5],
# [ 6, 7, 8, 9, 10]])
np.sum(array, axis=0) # ⇒ array([ 7, 9, 11, 13, 15])
np.sum(array, axis=1) # ⇒ array([15, 40])
・np.abs(ndarray)
ndarrayの絶対値を返す。
# 絶対値 (absolute value)
array = np.arange(-10, 0) # ⇒ array([-10, -9, -8, -7, -6, -5, -4, -3, -2, -1])
np.abs(array) # ⇒ array([10, 9, 8, 7, 6, 5, 4, 3, 2, 1])
NumPyでのNaNの扱い
PythonでいうNoneのようなもの。
Not a Numberの略で、Excelなどでも関数のエラーがある際に見かけると思う。
np.log(-100)など、ありえない数字を求めようとした際に出力される。
NaNはfloat型なので、NumPyでfloat型のエラーが出た際は、NaNの可能性を疑うようにする。
nanかどうかの確認にはnp.isnan()を使用する。
# 負の値のlogをとると"nan"が返る
neg_val = -10
np.log(neg_val) # ⇒ nan
# 'nan'はnp.nan (*Noneとは別もの)
np.nan # ⇒ nan
# タイプはfloatなので,floatについてのエラメッセージがでたらnp.nanを疑う
type(np.nan) # ⇒ float
# nanチェックにはnp.isnan()を使う
nan_val = np.log(neg_val)
np.isnan(nan_val) # ⇒ True
# is np.nan や == np.nanではダメ
print(nan_val is np.nan) # ⇒ False
print(nan_val == np.nan) # ⇒ False
▶NumPy Arrayの条件フィルターの使い方
・.clip(a, a_min, a_max)
a内の要素をa_minからa_maxでフィルターし、a_min未満は最小値、a_max以上は最大値に置換する。
array = np.arange(10) # ⇒ array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
# 最小値と最大値を設定する.その範囲以外の数字は最小値,もしくは最大値を適用
np.clip(array, 3, 7) # ⇒ array([3, 3, 3, 3, 4, 5, 6, 7, 7, 7])
・.where(condition, True, False)
conditionに条件式を渡し、Trueの場合、Falseの場合それぞれで指定した値に置換する。
conditionのみを引数に渡した場合は、条件に合った要素のみを返す。
array = np.arange(10)
# 条件に一致する要素を入れ替える (この場合Trueは1, Falseは0)
np.where(array > 3, 1, 0) # ⇒ array([0, 0, 0, 0, 1, 1, 1, 1, 1, 1])
# conditionのみ指定すると,その条件に一致するインデックスのみが残る
np.where(array > 3) # ⇒ array([4, 5, 6, 7, 8, 9])
・Filter
arrayに対して直接条件式を適用した場合は、それぞれの要素に条件を適用し、結果をTrueかFalseに変換したarrayを返す。
array[array > 3]というようにした場合は、条件に合った要素のみを返す。
※np.where(array > 3)と似たような挙動をする。
array[array > 3]をndarrayに使用した場合、多次元でもflat(1次元)で帰ってくるので注意
array = np.arange(10)
ndarray = array.reshape(2, 5)
# filter
array > 3 # ⇒ array([False, False, False, False, True, True, True, True, True, True])
ndarray > 3 # ⇒ array([[False, False, False, False, True],
# [ True, True, True, True, True]])
array[array > 3] # ⇒ array([4, 5, 6, 7, 8, 9])
ndarray[ndarray > 3] # ⇒ array([4, 5, 6, 7, 8, 9])
・.all()と.any()
.where()やfilterの結果に対して使用できる。
.all()はすべての要素がTrueの場合にTrueを返す。
.any()はi\いずれかの要素がTrueの場合にTrueを返す。
引数にaxis=を渡すことで、列・行ごとの判定も可能
(ndarray > 3).all() # ⇒ False
(ndarray > 3).any() # ⇒ True
# axis=0: 列ごとに評価, axis=1: 行ごとに評価
(ndarray > 3).all(axis=0) # ⇒ array([False, False, False, False, True])
▶NumPy Arrayの保存とロード
・np.save('path', ndarray)
指定したpathにndarrayを保存する。
拡張子は自動で.npyとなる。
.np.load('path')
指定したファイルからndarrayをロードする。
# numpyオブジェクトをsaveする
file_path = 'sample_ndarray.npy' #拡張子はつけなくても自動で.npyで保存される
np.save(file_path, ndarray)
# numpyオブジェクトをloadする
loaded_ndarray = np.load(file_path)
# dictionaryを.npyとして保存する
dictionary = {
'id': 123456,
'image': np.array([1, 2, 3])
}
file_path = 'sample_dict.npy'
np.save(file_path, dictionary)
# dictionaryはpickleで保存されているのでallow_pickle=Trueを指定してload
loaded_dict = np.load(file_path, allow_pickle=True)
# dictionaryを取り出す場合は'[()]'を使う
loaded_dict[()] # ⇒ {'id': 123456, 'image': array([1, 2, 3])}