要約
TorchScript を torch::jit::load() で読み込むときは、第2引数にデバイス名 (torch::kCUDA など) を書いてあげるとうまくいきます。(GPUを使用する場合)
Example.cpp
// 例えば、第2引数にkCUDAを指定してあげる
model_ = std::make_unique<torch::jit::Module>(torch::jit::load(modelPath_, torch::kCUDA));
▼ to 関数を使用してもタイトルのエラーを吐きます。
models_.to(device_); // これを実行してGPUに送っても不完全
環境
OS : Ubuntu 22.04
CUDA : CUDA Toolkit 12.4
LibTorch :
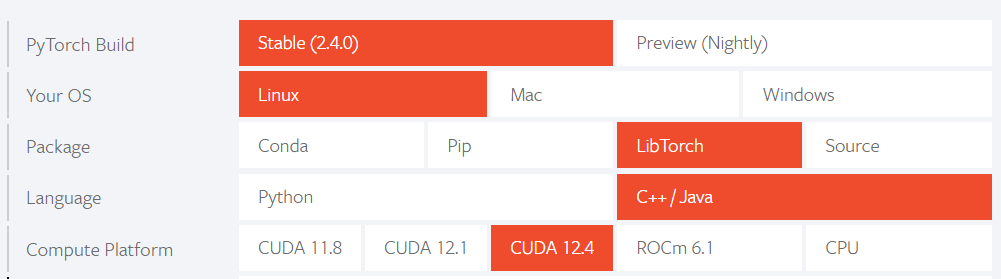
使用フレームワーク : Qt 6.7.2
状況
YOLOv10 を Libtorch で動かしたい。
公式GitHub から .pt ファイルをダウンロードして、公式サイトを参考に、TorchScript 形式にするところまではできた!
よーし、あとはこれを読み込んで、検出を行うプログラムを書こう。
Executor.cpp
#include <Executor.h>
bool Executor::Load()
{
canUseCUDA_ = torch::cuda::is_available();
device_ = canUseCUDA_ ? torch::kCUDA : torch::kCPU;
try
{
model_ = std::make_unique<torch::jit::Module>(torch::jit::load(modelPath_));
return true;
}
catch (const c10::Error& e)
{
qDebug() << e.msg(); // Qt のデバッグ用関数。std::cout みたいなもの
return false;
}
}
void Executor::Detect(const QImage& qimage)
{
// QImage を テンソルに変換する関数(ユーザー定義)
auto img_tensor = QImageToTensor(qimage);
// アスペクト比を変えることなく、入力画像が 640×640 に収まるように縮小 or 拡大(ユーザー定義関数)
img_tensor = ResizeImage(img_tensor);
// パディングを行い、テンソルのサイズが 1×3×640×640 (= input)になるよう調節する(ユーザー定義関数)
img_tensor = PadImage(img_tensor);
// モデルとテンソルを GPU に送る
models_.to(device_);
img_tensor.to(device_);
// 実行
auto output = model_->forward({img_tensor});
if(canUseCUDA_){
detections_ = output.toTensor().cuda();
}
else{
detections_ = output.toTensor().cpu();
}
// 検出されたオブジェクトのデータを保存したりする
}
ということで動かしてみよう。ん?エラー?どれどれ
Error
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
いや、テンソルはすべてGPU側に送っているが?
IncompleteProgram.cpp
models_.to(device_);
img_tensor.to(device_);
解決法
いろいろ探し回った結果、Github の issue で解決法を見つけました。(下のほう)
どうやら、モデルをロードするときは、モデルのパスとデバイス名の両方を与えてあげると良いらしいです。これによってすべてのテンソルが正常に GPU 側に送られます。
ということで、
// model_ = std::make_unique<torch::jit::Module>(torch::jit::load(modelPath_));
model_ = std::make_unique<torch::jit::Module>(torch::jit::load(modelPath_, device_));
としたら問題なく動いてくれました。
第2引数を与えない場合でもコンパイルエラーにはならないので注意が必要ですね。