実行環境
今回はGoogle Colaboratoryで実行します。
もちろんJupyterでも同じことはできるのですが、手軽に形態素解析ツールのMeCabが使える上、
クラウド上で実行するので計算も早いし使うデータの容量もほぼ気にならないのでColabをオススメします。
青空文庫データの取得
Web上からスクレイピングして取得する方法でもいいのですが、
git cloneでgit上からもデータを楽に取得できます。
!git clone --branch master --depth 1 https://github.com/aozorabunko/aozorabunko.git
MeCabのインストール
形態素解析ツールMeCabをインストールします。
こちらの記事を参考にさせていただきました。
Colabではこちらのコードを打つだけでMeCabが使えるようになります。
!apt install aptitude
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3==0.7
早速試しにMeCabで形態素解析をしてみましょう。
import MeCab
mecab = MeCab.Tagger("-Ochasen")
text = mecab.parse ("すもももももももものうち")
print(text)
実行結果
すもも スモモ すもも 名詞-一般
も モ も 助詞-係助詞
もも モモ もも 名詞-一般
も モ も 助詞-係助詞
もも モモ もも 名詞-一般
の ノ の 助詞-連体化
うち ウチ うち 名詞-非自立-副詞可能
EOS
見事に難解な(?)この文章の解析をしてくれました。
分かち書きだけ抽出したい場合はTaggerメソッドの引数を"-0wakachi"にします。
mecab_wakachi = MeCab.Tagger("-Owakati")
text_2 = mecab_wakachi.parse ("すもももももももものうち")
print(text_2)
実行結果
すもも も もも も もも の うち
ドライブをマウント
次に、Colabのプログラム上から青空文庫のデータを読み込む為にGoogleドライブへのマウントを実行します。
出てくるURLに飛ぶとアカウントの認証画面が出てくるので、アカウントを選択し認証コードを貼り付けて実行してください。
from google.colab import drive
drive.mount('/content/drive')
画面左の「ファイル」メニューに、drive上に保存したデータが表示されてアクセスできるようになります。
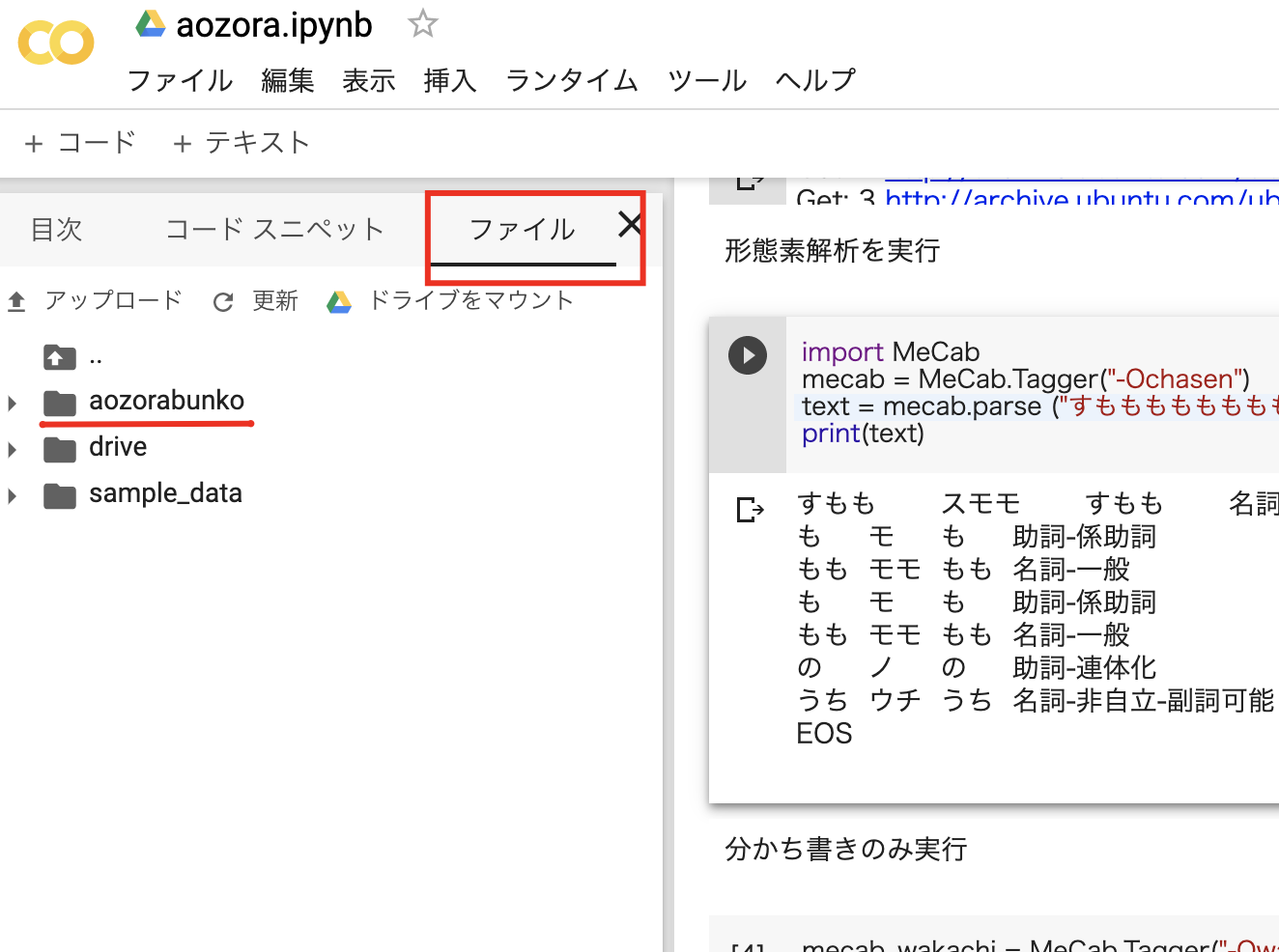
解析するファイルを選択
ダウンロードした'aozorabunko'ディレクトリの中の'cards'ディレクトリに小説のデータがhtml
などの形式で保存されています。
解析したいhtmlのパス(小説が書いてあるファイルのパス)を指定します。
今回は芥川龍之介の「羅生門」で解析してみます。
path_to_html='aozorabunko/cards/000879/files/127_15260.html'
BeautifulSoupでスクレイピング
BeautifulSoupを使ってhtmlファイルの中から小説の本文のみを取得します。
from bs4 import BeautifulSoup
with open(path_to_html, 'rb') as html:
soup = BeautifulSoup(html, 'lxml')
main_text = soup.find("div", class_='main_text')
# ルビが振ってあるのを削除
for yomigana in main_text.find_all(["rp","h4","rt"]):
yomigana.decompose()
sentences = [line.strip() for line in main_text.text.strip().splitlines()]
print(sentences)
実行結果
['ある日の暮方の事である。一人の下人が、羅生門の下で雨やみを待っていた。', '広い門の下には、...(略)]
リスト形式で本文を取得できました。これを解析の為にstr型に変換します。
rashomon_text=','.join(sentences)
WordCloud実行の為の準備
つぎに、WordCloudを用いて「羅生門」の本文の特徴を可視化してみましょう。
実行の為に、本文を分かち書きします。
mecab_wakachi = MeCab.Tagger("-Owakati")
rashomon_text_wakachi = mecab_wakachi.parse(rashomon_text)
print(rashomon_text_wakachi)
実行結果
ある 日 の 暮方 の 事 で ある 。 一 人 の 下人 が 、 羅生門 の 下 で 雨 やみ を 待っ て い た 。 , 広い 門 の 下 に は 、 この 男 の ほか に 誰 も ...(略)
WordCloudの取得・実行
WordCloudをインストールします。
!pip install wordcloud
WordCloudの画像を表示します。
from wordcloud import WordCloud
import matplotlib.pyplot as plt
f_path = '/usr/share/fonts/opentype/ipafont-gothic/ipagp.ttf' #日本語フォントの取得
wordcloud = WordCloud(background_color="white",
font_path=f_path,
width=700,
height=600).generate(rashoumon_text_wakachi)
plt.figure(figsize=(12,10))
plt.imshow(wordcloud)
plt.axis("off") #メモリの非表示
plt.show()

WordCloudが表示されました(^o^)