はじめに
Pythonを使ってデータ分析をしてみたい...とか、ゼミや研究でPythonを使うことになったけどプログラミングやったことない...という方へ。
これさえわかればとりあえず基礎は大丈夫です (多分)。知識のおさらいに使うのもありだと思います。
まず、汎用的なPythonの文法の基礎を最小限扱ってから、データ分析に用いる基本的な道具やテクニックについて記載しています。
Pythonの基本的な文法について知ってる人は2. データ分析のためのPython基礎まで飛んでもらってOKです。
この記事は2019年度に大学のゼミのメンバーにPythonを教えるのに使った資料を元に修正・追加したものです。(別のとある私立大学の講義にも採用していただきました!!)
あくまでデータ分析を行うためのPythonの基礎なので、データ分析そのものについてはあまり言及してません。もっと学びたい方にはおすすめ書籍を最後に紹介します。
実行環境の準備
初めてプログラミングをすると躓きがちなのはプログラミングをするための環境構築ですが、Google Colaboratoryを用いることでちゃちゃっとPythonを使えるようにします。
GoogleDriveを開いて、Colaboratoryをインストールします。
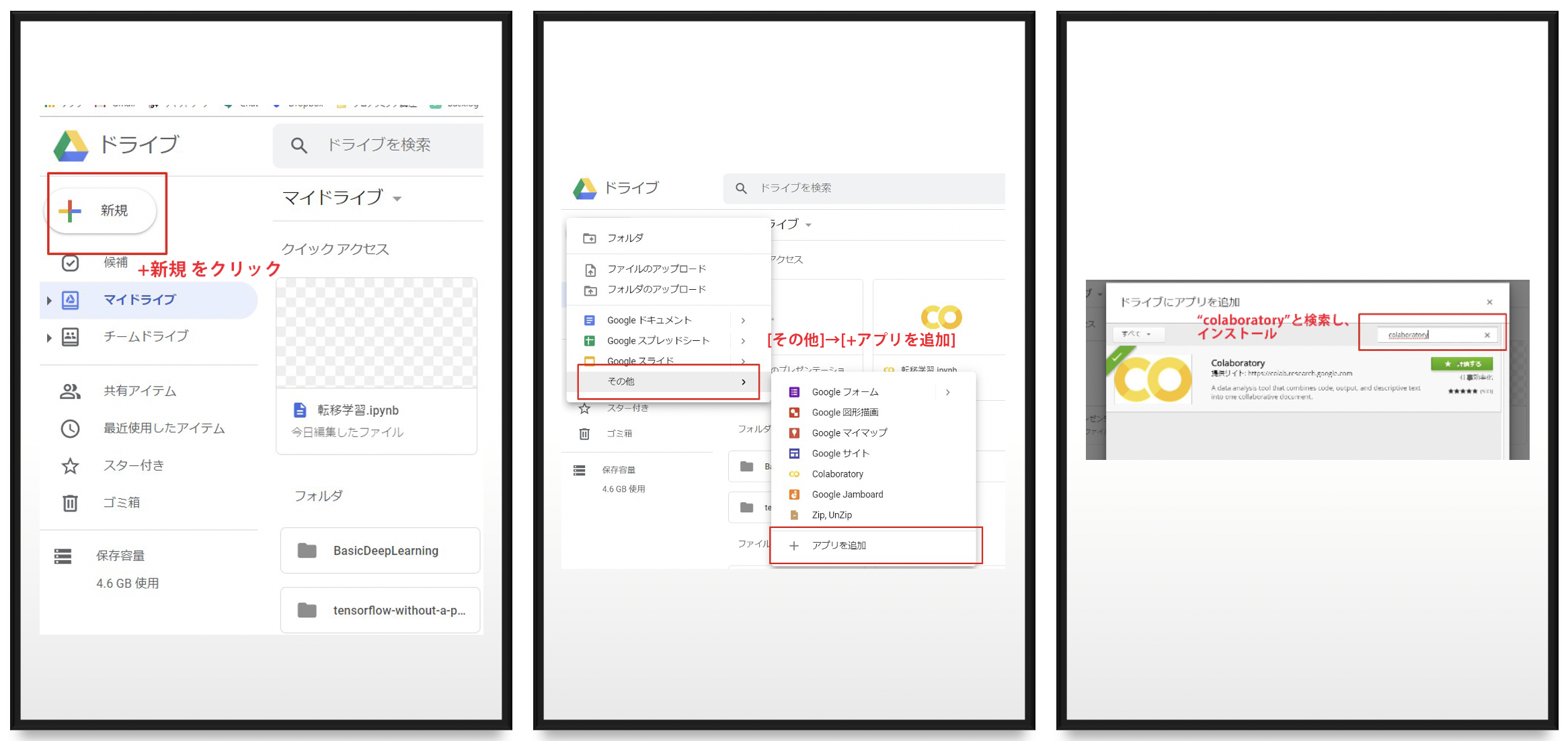
以下、Google Colaboratoryでの実行を前提としますが、実行環境が整っている方はjupyter等ご自身の環境で実施いただければと思います。
1. Python文法基礎
まずは、Pythonの基礎から。
1.1 文字を画面に表示させてみる
print関数を用います。
print("Hello World!")
Hello World!
1.2 四則演算
3 + 4 #足し算
#出力: 7
8 - 3 #引き算
#出力: 5
9 * 3 #掛け算
#出力: 27
9 / 3 #割り算
#出力: 3.0
5 // 2 #割り算の商
#出力: 2
5 % 2 #割り算の余り
#出力: 1
5 ** 2 #累乗
#出力: 25
1.3 変数の扱い(整数型・浮動小数点型)
Pythonのデータ型について知りましょう。データ型とは、文字通りデータの型のことです。と言ってもピンとこないかもしれません。
習うより慣れろってことで、よく用いられるデータ型についていくつかみてみましょう。
a = 4
a
#出力: 4
ちなみに、文字としてのaを表示させたい場合には
print('a')
#出力: a
b = 1.2
b #出力:1.2
a + b
#aは「整数型」、bは「浮動小数点型」
#出力:5.2
「=」は等価ではなく代入を意味します。
a = a + 1
a #出力:5
c = 2
c += 1 #二項演算子 c = c + 1 と同じこと
c #出力: 3
d = 6
d -= 1 #二項演算子 c = c - 1 と同じこと
d
e = 100*5
e #出力:500
f = 4
f == 4 #出力:True
#「==」は比較演算子。代入によりfは4であることは正しいのでTrue
f == 5 #出力:False
Pythonでのプログラムの書き方で注意
Pythonでは字下げ(インデント)がプログラムとして意味を持ちます。
意味もなく字下げをするとエラー。
x = 1
x = x + 1
x
File "<ipython-input-92-80d18cdaadaa>", line 2
x = x + 1
^
IndentationError: unexpected indent
1.4 文字列型
文字列型のデータはシングルクォーテーションあるいはダブルクォーテーションで文字列を囲むことで作成
a = "データ分析"
b = 'Python'
a,b
('データ分析', 'Python')
文字列をつなげてみます。+を用います。
a = "データ分析のための"
b = 'Python基礎'
a + b
'データ分析のためのPython基礎'
以下の場合はエラーとなります。
c = "4" #文字列型
d = 3 #整数型
c + d #変数の型が違うのでエラー
TypeError Traceback (most recent call last)
<ipython-input-98-237326ccb44f> in <module>()
1 c = "4" #文字列型
2 d = 3 #整数型
----> 3 c + d #変数の型が違うのでエラー
TypeError: must be str, not int
文字列の長さ(文字数)の取得にはlen()関数を用いる
a = "DataAnalytics"
len(a) #出力:13
1.5 メソッド
データ型ごとに使える関数と思ってください。
単独で使える普通の関数と違い、メソッドは変数や値に付けて呼び出します。
文字列型で使えるメソッドを少し使ってみましょう。
name = 'Donald Trump'
#アルファベットを全て大文字にするupperメソッド
print(name.upper())
#アルファベットを全て小文字にするlowerメソッド
print(name.lower())
DONALD TRUMP
donald trump
1.6 リスト型
数値や文字列などを並べて格納できるデータ型。文字や文字列などを、カンマで区切って並べる。
かたまりのデータをまとめて扱うときに便利。
L = [1,2,3,4]
L
[1, 2, 3, 4]
順番が最初のデータは「0番目」となります。
L[1] #2番目の要素を取得
#出力:2
L[:] #全要素を取得
#出力:[1, 2, 3, 4]
内容の変更は代入で行います。
L[2]=999 #3番目の要素を変更
L #出力:[1, 2, 999, 4]
データの追加にはappendメソッドを用います。
L.append(30) #リストの末尾に30を追加
L #出力:[1, 2, 999, 4, 30]
###リストのスライス
データの間に「仕切り」があり、その仕切りの番号を指定すると考えるとわかりやすい。
arashi = ["櫻井翔","松本潤","大野智","相葉雅紀","二宮和也"]
print(arashi[0:1])
print(arashi[1:4])
print(arashi[2:2])
['櫻井翔']
['松本潤', '大野智', '相葉雅紀']
[]
練習問題
arashiリストから、相葉ちゃんとニノだけリストから取り出し表示させよう。
解答
print(arashi[3:5])
#出力:['相葉雅紀', '二宮和也']
1.7 辞書型
辞書では、見出し語 (キー) と対応する要素である 値(value)を紐づけて対応関係を管理します。
arashi = {'櫻井翔':'38','松本潤':'36','大野智':'39'}
print(arashi)
{'櫻井翔': '38', '松本潤': '36', '大野智': '39'}
キーを指定することでそのキーに紐づく値を取得します。
arashi["大野智"] #キーで参照
#出力:'39'
1.8 タプル型
a = (1,2,3,4)
a #出力:(1,2,3,4)
print(a[0]) #出力:1
リスト型との違いはイミュータブル(変更不可能)である点。
変更されたら困るデータを管理するのに便利。
a[1]=10
#変更できないのでエラー
TypeError Traceback (most recent call last)
<ipython-input-130-5434a1e381e3> in <module>()
----> 1 a[1]=10
2 #変更できないのでエラー
TypeError: 'str' object does not support item assignment
1.9 制御構造
if文
条件に従って動作を指定します。
以下では変数が20以上(age>=20がTrue)なら「20歳以上だね」、そうでなければ(else)「未成年だね」を返します。
コロンのあとはキーボードのTabキーでインデントを付けてください。
age = 20
if age >= 20:
print('20歳以上だね')
else:
print('未成年だね')
#出力: 20歳以上だね
age = 20
if age >= 20:
print('20歳以上だね') #インデントがないのでエラー
else:
print('未成年だね')
File "<ipython-input-154-b2f09d489829>", line 4
print('20歳以上だね')
^
IndentationError: expected an indented block
for文
繰り返し処理を実行します。こちらもコロンのあとはインデントを付けます。
for i in range(5): #0から数えて5回繰り返し
print(i)
#出力
0
1
2
3
4
1.10 関数定義
自分の関数を作っちゃおう。
defで定義の宣言をし、関数名(この場合はf())と変数を定義します。コロン以下に関数の挙動をプログラムします。
def f(x,y):
return x**2 + y**2 # 戻り値を返す(計算結果が渡される)
print(f(10,20)) #10の二乗+20の二乗
#出力:500
1.11 FizzBuzz問題
3の倍数で’Fizz'、5の倍数で'Buzz'、3と5の公倍数で'FizzBuzz'、
それ以外の数でそのまま数を表示させるプログラムをつくってみます。
条件を加える場合はelifを用います。
for i in range(1,31):
if i%3 == 0 and i%5==0:
print('FizzBuzz')
elif i%3 == 0:
print('Fizz')
elif i%5 == 0:
print('Buzz')
else:
print(i)
1
2
Fizz
4
Buzz
Fizz
7
8
Fizz
Buzz
11
Fizz
13
14
FizzBuzz
16
17
Fizz
19
Buzz
Fizz
22
23
Fizz
Buzz
26
Fizz
28
29
FizzBuzz
練習問題
引数に数字を入れると、上記のFizzBuzzのルールで数字が表示される関数を作ろう。
また実際にその関数で表示を確かめてみよう。
解答
def FizzBuzz(i):
if i%3 == 0 and i%5 == 0:
print('FizzBuzz')
elif i%3 == 0:
print('Fizz')
elif i%5 == 0:
print('Buzz')
else:
print(i)
FizzBuzz(100)
#出力:Buzz
FizzBuzz(105)
#出力:FizzBuzz
1.12 モジュール
Pythonは関数のような機能をまとめ、必要な時に読み込んで使えるモジュールという仕組みを持っています。
ここまでで使った関数はPythonに内蔵されているいつでも使える関数で、これらを組み込み関数と呼びます。http://docs.python.jp/3/library/functions.html にその一覧があります。
一方、限られた用途で使うものはモジュールから読み込むことで使えるようになります。
Pythonにはこの便利なモジュールがたくさん付属しているのですが、このPythonに付属のモジュールの集合体のことを標準ライブラリといいます。
ちなみに、Anacondaには標準ライブラリの他にも便利なライブラリが付属しています。
import math #mathモジュールを読みこむ(インポート)
math.cos(0) #出力:1.0
モジュール名.関数名 のようにモジュール名と関数名を. でつなげて使う
import numpy as np #NumPyモジュールをnpという名前でインポート
#円周率π
np.pi #出力:3.141592653589793
#cos(180°)
math.cos(np.pi) #出力:-1.0
2. データ分析のためのPython基礎
データ分析でよく使われるライブラリの一例と主な用途
Numpy : 数値計算、行列演算
Pandas:データの操作、演算
Matplotlib : グラフの描画
他にもいろんなライブラリがありますが、今回はこの3つについて解説します。
2.1 Numpyでベクトルや行列の計算
Numpyは数値計算のためのライブラリです。行列の演算をしてみましょう。
import numpy as np #NumPyモジュールをインポートし、'np'として用いる
arr1 = np.array([1,4,3]) #1×3行列の作成
arr1
array([1, 4, 3])
arr1[2] #要素の取得
#出力:3
#2×3行列
arr2 = np.array([[1,2,3],[4,5,6]])
array([[1, 2, 3],
[4, 5, 6]])
arr2[1,1] #要素の取得
#出力:5
arr2.shape
#出力:(2, 3)
arr1 + arr2 #行列の足し算
#出力:
array([[2, 6, 6],
[5, 9, 9]])
dot()関数で行列の積を計算してみましょう
a = np.array([[1,2],[3,4]])
b = np.array([[5,6],[7,8]])
np.dot(a,b)
#出力
array([[19, 22],
[43, 50]])
できる方は手計算して、行列の積の結果が一致するかどうか確認してみましょう。
ちなみにさっきの行列(arr1,arr2)の積は、、
np.dot(arr1,arr2)
ValueError Traceback (most recent call last)
<ipython-input-62-e5b6075b8937> in <module>()
----> 1 np.dot(arr1,arr2)
<__array_function__ internals> in dot(*args, **kwargs)
ValueError: shapes (3,) and (2,3) not aligned: 3 (dim 0) != 2 (dim 0)
arr1の列数とarr2の行数が一致せず、行列の積が定義できないのでエラーです。
2.2 Matplotlibでグラフ描画
描画にはデータ可視化のためのライブラリであるMatplotlibを使います。
今回は、Matplotlibライブラリのpyplotモジュールをimportし、pyplotモジュール内のplot関数を用います。
まずは直線を描いてみましょう。
措定した範囲を分割した点を複数用意し、それらを線で結ぶイメージです。
import matplotlib.pyplot as plt
# Matplotlibパッケージのpyplotモジュールをインポート
import numpy as np
x = np.linspace(0,10,100) # 変数xにNumPyの関数linspaceを使用し0から10までの数字を100分割したものを代入
y = x
plt.plot(x,y) #xとyをプロット
plt.show() #グラフを表示
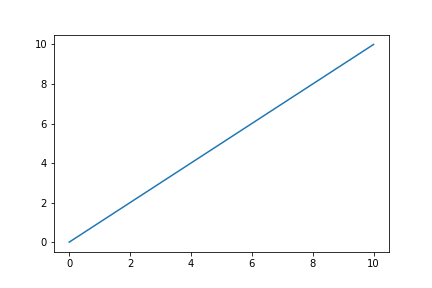
次は2次曲線を描いてみます。
また、matplotlibで日本語フォントを使うためのライブラリ(japanize-matplotlib)をインストールしてimportで呼び出せるようにします。
!pip install japanize-matplotlib
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
x = np.linspace(-5,5,300) #変数xにNumPyの関数linspaceを使用し-5から5までの数字を300分割したものを代入
y = x**2
plt.plot(x,y,color = "r") #色を赤に指定
plt.xlabel('y=x^2のグラフ') #x軸のラベルを設定
plt.show()
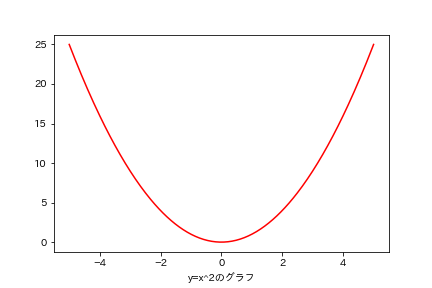
最初の直線の描画の際にも書いたように、滑らかな曲線のように見えるこの放物線は実際は直線の集合です。
分割を粗くしてみましょう。
x = np.linspace(-5,5,10) #10分割にしてみる
y = x**2
plt.plot(x,y,color = "r")
plt.xlabel('y=x^2のグラフ')
plt.show()
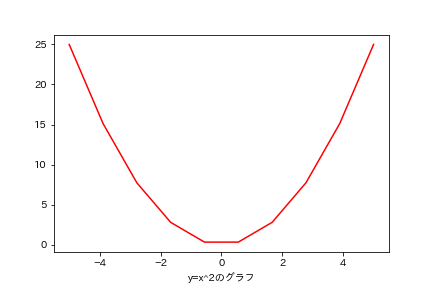
さっきより少しカクカクしていますね。
もうちょっとグラフを練習しましょう。次はNumpyの関数を用いて三角関数のグラフ描画します。
import math
x = np.linspace(-np.pi, np.pi) #-πからπまで
plt.plot(x, np.cos(x), color='r', ls='-', label='cos') #線の種類や色、ラベルを指定
plt.plot(x, np.sin(x), color='b', ls='-', label='sin')
plt.plot(x, np.tan(x), color='c', marker='s', ls='None', label='tan')
#表示する座標の範囲を指定
plt.xlim(-np.pi, np.pi)
plt.ylim(-1.5, 1.5)
#x=0とy=0に補助線を引く
plt.axhline(0, ls='-', c='b', lw=0.5) #horizontal(水平)だからhline
plt.axvline(0, ls='-', c='b', lw=0.5) #vertical(垂直)だからvline
plt.legend()
plt.xlabel('x軸')
plt.ylabel('y軸')
plt.title('三角関数のグラフ')
plt.show()
2.3 Pandasでデータ操作
データの前処理は主にこのPandasを使います。分析対象のデータをDataFrame(データの格納庫のようなもの)に保存し、必要に応じて加工します。
分析に使えるデータはいつも綺麗だとは限りません。
データ分析や機械学習で費やす時間のほとんどはこの前処理です。前処理を制するものがデータ分析を制します。まずは、簡単なDataFrameを2つ作成してみましょう。
import pandas as pd
df1 = pd.DataFrame({
'名前':['sato','ito','kato','endo','naito'],
'学生番号':[1,2,3,4,5],
'体重':[92,43,58,62,54],
'身長':[178,172,155,174,168]
})
df1
| 名前 | 学生番号 | 体重 | 身長 | |
|---|---|---|---|---|
| 0 | sato | 1 | 92 | 178 |
| 1 | ito | 2 | 43 | 172 |
| 2 | kato | 3 | 58 | 155 |
| 3 | endo | 4 | 62 | 174 |
| 4 | naito | 5 | 54 | 168 |
DataFrameにはインデックスが付与されます(0から始まる一番左の数字)
df2 = pd.DataFrame({
'学生番号':[1,2,3,5,6,9],
'数学':[50,60,70,80,90,100],
'英語':[95,85,80,75,70,65],
'理科':[40,55,60,65,50,75],
'クラス':['A組','B組','A組','C組','B組','C組']
})
df2
| 学生番号 | 数学 | 英語 | 理科 | クラス | |
|---|---|---|---|---|---|
| 0 | 1 | 50 | 95 | 40 | A組 |
| 1 | 2 | 60 | 85 | 55 | B組 |
| 2 | 3 | 70 | 80 | 60 | A組 |
| 3 | 5 | 80 | 75 | 65 | C組 |
| 4 | 6 | 90 | 70 | 50 | B組 |
| 5 | 9 | 100 | 65 | 75 | C組 |
2つのデータフレームを作成しました。
df1には名前と体重などの情報、df2には成績などの情報が格納されています。また、2つのデータフレームは一意の学生番号で紐づいているとします。
データの抽出
特定の列を呼び出す際は[ ]で列名を指定します。
df2['数学']
0 50
1 60
2 70
3 80
4 90
5 100
Name: 数学, dtype: int64
複数列を抽出する際は[ ]を二重にして呼び出します。
df2[['英語','クラス']]
| 英語 | クラス | |
|---|---|---|
| 0 | 95 | A組 |
| 1 | 85 | B組 |
| 2 | 80 | A組 |
| 3 | 75 | C組 |
| 4 | 70 | B組 |
| 5 | 65 | C組 |
ソート
まずは特定のカラムだけソート(並び替え)します。
sort_values()関数を用います。デフォルトでは昇順となります。
df1['身長'].sort_values()
#出力:
2 155
4 168
1 172
3 174
0 178
Name: 身長, dtype: int64
体重でソートしてdf1全体を表示する場合はsort_values()関数のbyの引数を設定します。
df1.sort_values(by=["体重"], ascending=False) #ascending=True なら昇順
| 名前 | 学生番号 | 体重 | 身長 | |
|---|---|---|---|---|
| 0 | sato | 1 | 92 | 178 |
| 3 | endo | 4 | 62 | 174 |
| 2 | kato | 3 | 58 | 155 |
| 4 | naito | 5 | 54 | 168 |
| 1 | ito | 2 | 43 | 172 |
体重について降順に並んでます。
データの結合
merge関数を用いると、いろんな種類のデータ結合ができます。
df1とdf2を学生番号をキーに結合させてみます。
内部結合(inner join)
data_inner = pd.merge(df1,df2, on='学生番号', how='inner')
data_inner
| 名前 | 学生番号 | 体重 | 身長 | 数学 | 英語 | 理科 | クラス | |
|---|---|---|---|---|---|---|---|---|
| 0 | sato | 1 | 92 | 178 | 50 | 95 | 40 | A組 |
| 1 | ito | 2 | 43 | 172 | 60 | 85 | 55 | B組 |
| 2 | kato | 3 | 58 | 155 | 70 | 80 | 60 | A組 |
| 3 | naito | 5 | 54 | 168 | 80 | 75 | 65 | C組 |
2つのデータフレームに共通するデータのみ結合されました。
ちなみに、df1とdf2は共通するカラムが学生番号のみなので、わざわざ指定しなくてもデフォルトで学生番号がキーとなります。
外部結合(outer join)
data_outer = pd.merge(df1, df2, how = 'outer')
data_outer
| 名前 | 学生番号 | 体重 | 身長 | 数学 | 英語 | 理科 | クラス | |
|---|---|---|---|---|---|---|---|---|
| 0 | sato | 1 | 92 | 178 | 50 | 95 | 40 | A組 |
| 1 | ito | 2 | 43 | 172 | 60 | 85 | 55 | B組 |
| 2 | kato | 3 | 58 | 155 | 70 | 80 | 60 | A組 |
| 3 | endo | 4 | 62 | 174 | nan | nan | nan | nan |
| 4 | naito | 5 | 54 | 168 | 80 | 75 | 65 | C組 |
| 5 | nan | 6 | nan | nan | 90 | 70 | 50 | B組 |
| 6 | nan | 9 | nan | nan | 100 | 65 | 75 | C組 |
outer joinの場合はどちらかのデータフレームにしか存在しないものも取得します。
左外部結合(left join)
data_left = pd.merge(df1,df2,how = 'left')
data_left
| 名前 | 学生番号 | 体重 | 身長 | 数学 | 英語 | 理科 | クラス | |
|---|---|---|---|---|---|---|---|---|
| 0 | sato | 1 | 92 | 178 | 50 | 95 | 40 | A組 |
| 1 | ito | 2 | 43 | 172 | 60 | 85 | 55 | B組 |
| 2 | kato | 3 | 58 | 155 | 70 | 80 | 60 | A組 |
| 3 | endo | 4 | 62 | 174 | nan | nan | nan | nan |
| 4 | naito | 5 | 54 | 168 | 80 | 75 | 65 | C組 |
left joinでは結合先(df1)に存在するものは残ります。inner joinの時とは違い、欠損値を含めてendoさんのデータが表示されています。
右外部結合 (right join)
data_right = pd.merge(df1,df2,how = 'right')
data_right
| 名前 | 学生番号 | 体重 | 身長 | 数学 | 英語 | 理科 | クラス | |
|---|---|---|---|---|---|---|---|---|
| 0 | sato | 1 | 92 | 178 | 50 | 95 | 40 | A組 |
| 1 | ito | 2 | 43 | 172 | 60 | 85 | 55 | B組 |
| 2 | kato | 3 | 58 | 155 | 70 | 80 | 60 | A組 |
| 3 | naito | 5 | 54 | 168 | 80 | 75 | 65 | C組 |
| 4 | nan | 6 | nan | nan | 90 | 70 | 50 | B組 |
| 5 | nan | 9 | nan | nan | 100 | 65 | 75 | C組 |
left joinと同様に、結合先(今度はdf2)のデータは残されます。outer joinの時とは違い、endoさんのデータは表示されません。
それぞれの結合の違いについてよく理解できましたか?
カラムの追加
df2で、理系科目の合計点を表すカラムを追加しましょう。
以下のように新しいカラム名を指定して代入すればOKです。
df2['理系科目'] = df2['数学'] + df2['理科']
df2
| 学生番号 | 数学 | 英語 | 理科 | クラス | 理系科目 | |
|---|---|---|---|---|---|---|
| 0 | 1 | 50 | 95 | 40 | A組 | 90 |
| 1 | 2 | 60 | 85 | 55 | B組 | 115 |
| 2 | 3 | 70 | 80 | 60 | A組 | 130 |
| 3 | 5 | 80 | 75 | 65 | C組 | 145 |
| 4 | 6 | 90 | 70 | 50 | B組 | 140 |
| 5 | 9 | 100 | 65 | 75 | C組 | 175 |
集計関数
クラスごとでテストの平均点を知りたいとします。groupby関数を用います。
以下では、クラスごとに集計したあと、mean関数で平均をとっています。
df2[['数学','英語','理科','クラス']].groupby(['クラス']).mean().reset_index()
#インデックスをリセット(表のずれがなくなる)
| クラス | 数学 | 英語 | 理科 |
|---|---|---|---|
| A組 | 60 | 87.5 | 50 |
| B組 | 75 | 77.5 | 52.5 |
| C組 | 90 | 70 | 70 |
groupbyで集計し、そのあとの関数でグループごとに演算します。
mean関数の他にも、max関数、median関数、min関数なども使えます。
# 各クラスの科目別最低点を抽出
df2[['数学','英語','理科','クラス']].groupby(['クラス']).min().reset_index()
| クラス | 数学 | 英語 | 理科 |
|---|---|---|---|
| A組 | 50 | 80 | 40 |
| B組 | 60 | 70 | 50 |
| C組 | 80 | 65 | 65 |
CSV出力
作成したデータフレームをcsv形式で出力するには、to_csv関数を用います。
data_right.to_csv('sample.csv')
CSVデータの読み込み
今回はDataFrameを一から作りましたが、本来はcsv形式でデータを読み込む場面が多いです。
CSV形式のファイルをpandasで読み込むには read_csv() 関数を使います。
ただしこれはカンマ区切りのcsvの場合に使用します。タブ区切りの場合は read_table() 関数を使用します。
先ほど出力したsample.csvを読み込んで、改めてDataFrameとして表示してみましょう。
sample = pd.read_csv('sample.csv', index_col=0) #indexは無視
sample
| 名前 | 学生番号 | 体重 | 身長 | 数学 | 英語 | 理科 | クラス | |
|---|---|---|---|---|---|---|---|---|
| 0 | sato | 1 | 92 | 178 | 50 | 95 | 40 | A組 |
| 1 | ito | 2 | 43 | 172 | 60 | 85 | 55 | B組 |
| 2 | kato | 3 | 58 | 155 | 70 | 80 | 60 | A組 |
| 3 | naito | 5 | 54 | 168 | 80 | 75 | 65 | C組 |
| 4 | nan | 6 | nan | nan | 90 | 70 | 50 | B組 |
| 5 | nan | 9 | nan | nan | 100 | 65 | 75 | C組 |
ここまでで、Pythonでデータ分析をする際の基本的な操作は一通り学ぶことができました。
最後に、練習問題を解いてみましょう。
練習問題
df2のデータを用いて、クラスごとで科目の合計点の平均を求め、それを棒グラフで図示してください。
※ヒント:棒グラフの描画にはmatplotlib.pyplotのbar関数を用います。
解答例
import matplotlib.pyplot as plt
import japanize_matplotlib
df2['合計点'] = df2['数学'] + df2['英語'] +df2['理科']
sum_score = df2[['クラス','合計点']].groupby(['クラス']).mean().reset_index()
x = sum_score['クラス']
y = sum_score['合計点']
plt.bar(x,y)
plt.xlabel('クラス')
plt.ylabel('平均合計点')
plt.title('クラス別平均合計点')
plt.show()
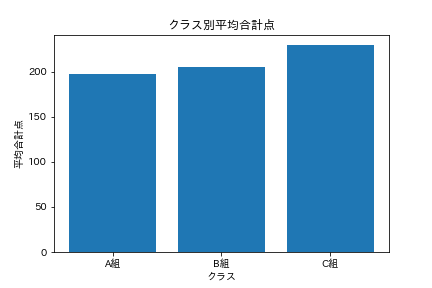
試験の合計点の平均はC組が一番高いですね。
#3. さらに学びたい人へ
ここまで何気に長くなってしまいました。取り組んでくれた方、お疲れ様です。
もっと深めたい人には以下の本をオススメします。
Pythonについてもっと知りたい人
みんなのPython 第4版
基本をマスターした後に読むといいでしょう。辞書的に使うのも○です。
Pythonでのデータ分析をもっと深めたい人
Pythonによるデータ分析入門 第2版 ―NumPy、pandasを使ったデータ処理
データの前処理に強くなりたい人
前処理大全[データ分析のためのSQL/R/Python実践テクニック]
実務でよく参照します。Python以外にも、RのdplyrやSQLでの前処理についても学べます。
Python実践データ分析100本ノック
名前に「データ分析」とありますが、pandasによるデータの前処理について多くページが割かれています。データ分析は前処理が8割という事実(?)に即した書籍といえます。
pandasの基本的な操作はこれで十分身に付けられます。
Pythonで機械学習をやってみたい人
オライリーの機械学習本2冊を紹介します。
Pythonではじめる機械学習 ―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎
機械学習のアルゴリズムの仕組みを勉強したい人
機械学習のエッセンス -実装しながら学ぶPython,数学,アルゴリズム
代表的な機械学習のアルゴリズムについて、一からPythonで実装します。機械学習に用いる数学についても学べます。