はじめに
本記事は、JDLA E資格 認定プログラムのラビット・チャレンジに関する記事である。
日本ディープラーニング協会(JDLA)
ラビット★チャレンジ
第一章 線形代数
スカラーとベクトルの違い
スカラー
・だいたい、いわゆる普通の数
長さ、大きさ、物の数量などを数値で表現することができ、単純に1次元の計算が行える。
・+、−、×、÷の演算が可能
足し算、引き算では、同じ概念の数値を扱う。
例えば、長さと重さのような違うもの同士は足し引きができない。「仕事と私、どっちが大事なの?」と言われても天秤にかけられないようなもの。
かけ算は、ある数のものがあるセット数あるとき全部でいくつあるか、という計算を行う。
1袋3個入りのりんごが2袋あったら全部でりんごは6個。このとき1袋あたり3個が固定の場合、それを係数と呼ぶこともできる。
割り算は、ある数をある数で割ったら何セットできるか、という計算を行う。
割り切れるといいけど、りんごが5個あって2袋に分ける場合、素直に半分にしたら真っ二つに割られたりんごが出来てしまう。
お店で売るとしたらちょっと嫌だ。そういうときは、1袋あたり2個のりんごが2袋できて余りは1個になる。
・ベクトルに対する係数になれる
ベクトルの係数になるというのは、あるベクトルの大きさを変換(拡大・縮小)してるイメージ。
ベクトル
・「大きさ」と「向き」を持つ
・矢印で図示される
・スカラーのセットで表示される
格子状の道で例えるとある点から北東に1km進みたい場合、北に0.71km、東に0.71km進めば目的地に辿り着ける。
このとき北東(向き)に1km(大きさ)というのをベクトルとすると、「北」という要素と「東」という要素に分ければ、
それぞれ0.71kmというスカラーで表せるということである。
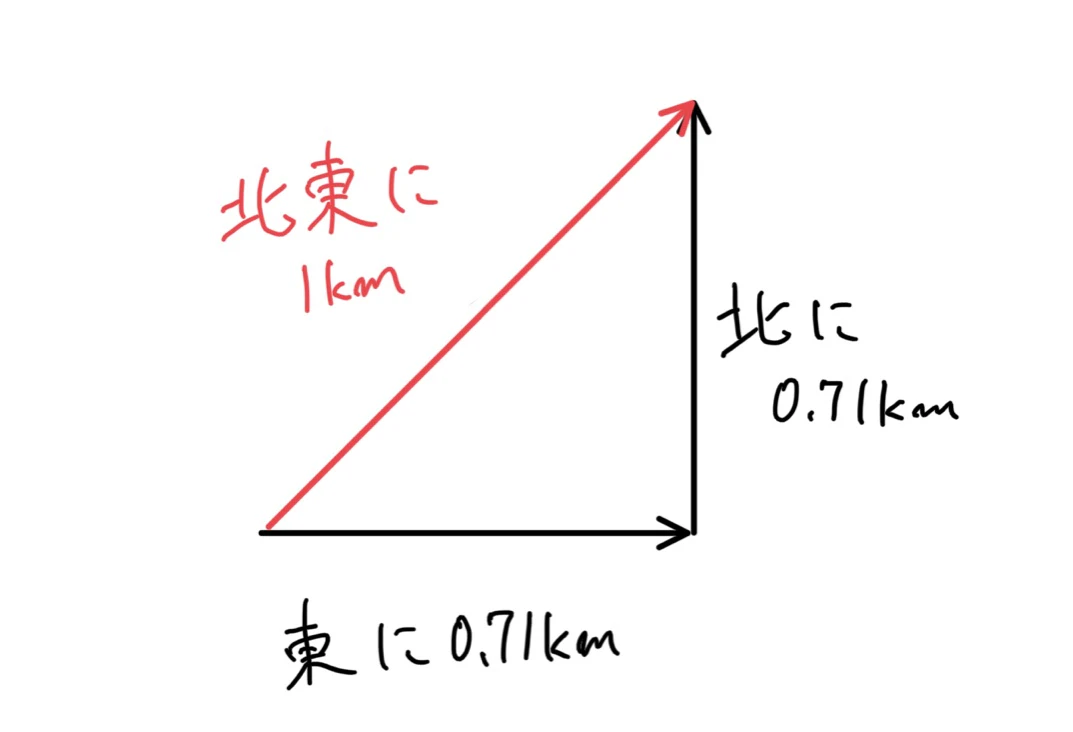
これをベクトルの式で表すと次のような感じ
\begin{pmatrix}
North\\East
\end{pmatrix}
=
\begin{pmatrix}
0.71\\0.71
\end{pmatrix}
ベクトルは、同じもの同士じゃなくても良い。
例えば身長と体重とか。ただし、関係性があるものの方が良い気がする。
風が吹けば桶屋が儲かるような関係性(相関性)が説明出来れば良い気がする。
行列
行列とは
・スカラーを表にしたもの
データとして扱う場合、行(横)方向には同じ概念のものが並ぶべきだし、列(縦)方向には同じ条件のものが並ぶべき。
・ベクトルを並べたもの
ベクトルはN行1列で表現されるので、行(横)方向に並べていく。そうすると前項と同じ意味になる。
・行列は何に使うのか?→ベクトルの変換
にも使えるよって話であって、ベクトルの変換にだけ使うわけではないのは前述の通り。
でも、ベクトルの変換に使うと便利なことがある。
行列とベクトルの積
ベクトルも行列として考えることができる。そして、行列の積は、行×列(横×縦)と考えると覚えやすい。
スカラーが「ベクトルに対する係数になれる」とあったが、それに対応して行列は、「ベクトルの各要素に対する係数」ということになる。
\begin{pmatrix}
\color{red}{6}&\color{red}{4}\\
\color{green}{3}&\color{green}{5}
\end{pmatrix}
\begin{pmatrix}
\color{orange}{1}\\
\color{blue}{2}
\end{pmatrix}
=
\begin{pmatrix}
\color{red}{6}\times\color{orange}{1}+\color{red}{4}\times\color{blue}{2}\\
\color{green}{3}\times\color{orange}{1}+\color{green}{5}\times\color{blue}{2}
\end{pmatrix}
=
\begin{pmatrix}
14\\
13
\end{pmatrix}
行列の積
行列の積は、計算の特性上、左側の行列の「列」と右側の行列の「行」が同じ数である必要がある。
これは「左側の行列が右側の行列の各要素に対する係数」と考えれば自然である。
行列が連立方程式の研究から生まれた(らしい)ということからも、この考えは正しいと思う。
\begin{pmatrix}
6&4\\
3&5
\end{pmatrix}
\begin{pmatrix}
1\\
2
\end{pmatrix}
\leftarrow これは解ける\\
\begin{pmatrix}
6&4\\
3&5
\end{pmatrix}
\begin{pmatrix}
1&
2
\end{pmatrix}
\leftarrow これは解けない\\
連立一次方程式の行列表現
次のような連立方程式が与えられたときについて考える。
\begin{cases}
a_{11}x_1+a_{12}x_2=b_1\\
a_{21}x_1+a_{22}x_2=b_2
\end{cases}
$x_1$,$x_2$をベクトル($x_1$,$x_2$)として表現すると連立方程式は以下のように表すことができる。
\begin{pmatrix}
a_{11}&a_{12}\\
a_{21}&a_{22}
\end{pmatrix}
\begin{pmatrix}
x_1\\
x_2
\end{pmatrix}
=
\begin{pmatrix}
b_1\\
b_2
\end{pmatrix}
この式をいわゆる普通の式($ ax=b $)のように表すと次のようになる。
A\vec{x} = \vec{b}\\
ここで行列Aとベクトルbに実際に値を入れてみると
\begin{pmatrix}
1&2\\
2&5
\end{pmatrix}
\begin{pmatrix}
x_1\\
x_2
\end{pmatrix}
=
\begin{pmatrix}
3\\
5
\end{pmatrix}
これは連立方程式で表すと次の通り。
\begin{cases}
\begin{align}
x_1+2x_2=3\\
2x_1+5x_2=5
\end{align}
\end{cases}
このときの$x_1,x_2$を行列で解いてみる。
$ax=b$の式であれば、$x=b/a$で簡単に求められるが、残念ながら行列の場合、割り算ができない。
そのため、行列Aを打ち消すような行列を考えてみる。(つまり左辺がベクトルxのみになる行列)
単位行列
その前に単位行列について説明する。
対角(左上から右下)に1が並び、それ以外の要素が0となる正方行列を単位行列Iと呼ぶ。
I=
\begin{pmatrix}
1&0&\cdots&0\\
0&1&&\vdots\\
\vdots&&\ddots&0\\
0&\cdots&0&1\\
\end{pmatrix}
単位行列は以下のような特性があることが知られている。
I\vec{x}=\vec{x}\hspace{3mm}I=\vec{x}\\
AA^{-1}=A^{-1}A=I\\
$A^{-1}$(Aインヴァース)をAの逆行列と呼ぶ。
逆行列
逆行列の求め方には掃き出し法というものがある。
結局何をしてるかというと、逆行列は、行列Aを単位行列に変換したときに
かけた行列を記録すれば求められる、ということ。
2x2の行列の場合、以下のように行列Aと単位行列を横に並べた行列から計算できる。
\begin{eqnarray}
\left(
\begin{array}{cc|cc}
a_{11}&a_{12}&1&0\\
a_{21}&a_{22}&0&1
\end{array}
\right)
\end{eqnarray}
1行目に$ 1/a_{11}$ 、2行目に$ 1/a_{21} $をかける。
\begin{eqnarray}
\left(
\begin{array}{cc|cc}
1&\frac{a_{12}}{a_{11}}&\frac{1}{a_{11}}&0\\
1&\frac{a_{22}}{a_{21}}&0&\frac{1}{a_{21}}
\end{array}
\right)
\end{eqnarray}
2行目から1行目を引く
\begin{eqnarray}
\left(
\begin{array}{cc|cc}
1&\frac{a_{12}}{a_{11}}&\frac{1}{a_{11}}&0\\
0&\frac{a_{11}a_{22}-a_{12}a_{21}}{a_{11}a_{21}}&-\frac{1}{a_{11}}&\frac{1}{a_{21}}
\end{array}
\right)\\
\end{eqnarray}
$a_{11}a_{22}-a_{12}a_{21}=|A|$ とし、 $a_{11}a_{21}/|A|\hspace{2mm}$ を2行目にかける。
\begin{eqnarray}
\left(
\begin{array}{cc|cc}
1&\frac{a_{12}}{a_{11}}&\frac{1}{a_{11}}&0\\
0&1&-\frac{a_{21}}{|A|}&\frac{a_{11}}{|A|}
\end{array}
\right)\\
\end{eqnarray}
2行目の$a_{12}/a_{11}$倍を1行目から引く
\begin{eqnarray}
\left(
\begin{array}{cc|cc}
1&0&\frac{1}{a_{11}}+\frac{a_{12}a_{21}}{a_{11}|A|}&-\frac{a_{12}}{|A|}\\
0&1&-\frac{a_{21}}{|A|}&\frac{a_{11}}{|A|}
\end{array}
\right)\\
\end{eqnarray}
\begin{eqnarray}
\left(
\begin{array}{cc|cc}
1&0&\frac{|A|+a_{12}a_{21}}{a_{11}|A|}&-\frac{a_{12}}{|A|}\\
0&1&-\frac{a_{21}}{|A|}&\frac{a_{11}}{|A|}
\end{array}
\right)\\
\end{eqnarray}
\begin{eqnarray}
\left(
\begin{array}{cc|cc}
1&0&\frac{a_{22}}{|A|}&-\frac{a_{12}}{|A|}\\
0&1&-\frac{a_{21}}{|A|}&\frac{a_{11}}{|A|}
\end{array}
\right)\\
\end{eqnarray}
このとき右側の2x2の行列が行列Aを単位行列に変換したときの処理を記憶したものである。
よって以下の式が成り立つ。
A^{-1}=
\frac{1}{|A|}
\begin{pmatrix}
a_{22}&-a_{12}\\
-a_{21}&a_{11}
\end{pmatrix}
また、この|A|を行列式と呼ぶ。
$$a_{11}a_{22}-a_{12}a_{21}=|A|$$
2x2の正方行列の場合、行列式は、その行列に含まれる2つの行ベクトルからなる平行四辺形の面積を求めているのと同義であり、2つの行ベクトルが平行する場合、行列式は0となる。行列式が0でないときその行列を正則であると言い、逆行列が存在するかの判定に用いられる。
連立方程式を行列で解いてみる
単位行列と逆行列の特性を使って以下の連立方程式を解いてみる。
\begin{pmatrix}
1&2\\2&5
\end{pmatrix}
\begin{pmatrix}
x_1\\x_2
\end{pmatrix}
=
\begin{pmatrix}
3\\5
\end{pmatrix}
このとき
A=
\begin{pmatrix}
1&2\\2&5
\end{pmatrix}
とすると、行列Aの逆行列は
A^{-1}=
\frac{1}{1\times5-2\times2}
\begin{pmatrix}
5&-2\\-2&1
\end{pmatrix}
=
\begin{pmatrix}
5&-2\\-2&1
\end{pmatrix}
である
よって、両辺の左にこの逆行列をかけると左辺の行列が単位行列となりベクトルxについて解くことが出来る。
\begin{pmatrix}
x_1\\x_2
\end{pmatrix}
=
\begin{pmatrix}
5&-2\\-2&1
\end{pmatrix}
\begin{pmatrix}
3\\5
\end{pmatrix}
=
\begin{pmatrix}
5\times3+(-2)\times5\\
-2\times3+1\times5
\end{pmatrix}
=
\begin{pmatrix}
5\\-1
\end{pmatrix}
このように簡単に解くことができる。
3x3行列の逆行列
3x3行列の逆行列は次のようになる。
A^{-1}=
\frac{1}{|A|}
\begin{pmatrix}
a_{22}a_{33}-a_{23}a_{32} & -(a_{12}a_{33}-a_{13}a_{32}) & a_{12}a_{23}-a_{13}a_{22}\\
-(a_{21}a_{33}-a_{23}a_{31}) & a_{11}a_{33}-a_{13}a_{31} & -(a_{11}a_{23}-a_{13}a_{21}\\
a_{21}a_{32}-a_{22}a_{31} & -(a_{11}a_{32}-a_{12}a_{31}) & a_{11}a_{22}-a_{12}a_{21}
\end{pmatrix}\\
|A|=a_{11}a_{22}a_{33}+a_{12}a_{23}a_{31}+a_{13}a_{21}a_{32}-a_{11}a_{23}a_{32}-a_{12}a_{21}a_{33}-a_{13}a_{22}a_{31}
固有値分解
固有値と固有ベクトル
ある正方行列Aに対して、以下のような式が成り立つ特殊なベクトルx、スカラーλがある。
A\vec{x}=\lambda \vec{x}\\
つまり、行列Aに特殊なベクトルをかけるとスカラーとそのベクトルだけで表せるようになる、ということである。
このベクトルxとスカラーλを行列Aに対する固有ベクトル、固有値と呼ぶ。
固有値と固有ベクトルの求め方
$A\vec{x}=\lambda \vec{x}\hspace{2mm} $ より
$$(A-\lambda I )\vec{x}= 0$$
このとき、スカラー$ \lambda $がそのままではAと計算できないので$ \lambda I $と置き換える(先述の通り$ I\vec{x}=\vec{x}\hspace{2mm} $であるため)。
$ \vec{x} \neq 0 $より($ \vec{x} = 0 $だとそもそも$ \lambda $も0になってしまう)$| A-\lambda I| $が0になる。
|A-\lambda I|=0\\
(a_{11}-\lambda)(a_{22}-\lambda)-a_{12}a_{21}=0\\
\lambda^2-(a_{11}+a_{22})\lambda + (a_{11}a_{22}-a_{12}a_{21})=0\\
\lambda^2-(a_{11}+a_{22})\lambda + |A|=0\\
(二次方程式の解の公式より)\\
\lambda =\frac{((a_{11}+a_{22})\pm\sqrt{(a_{11}+a_{22})^2-4|A|}}{2}
\begin{cases}
a_{11}x_1+a_{12}x_2=\lambda x_1\\
a_{21}x_1+a_{22}x_2=\lambda x_2
\end{cases}\\
\begin{cases}
a_{11}x_1+\frac{a_{12}a_{21}}{a_{21}}x_2=\frac{a_{21}}{a_{21}}\lambda x_1\\
a_{11}x_1+\frac{a_{11}a_{22}}{a_{21}}x_2=\frac{a_{11}}{a_{21}}\lambda x_2
\end{cases}\\
1行目から2行目を引く
\frac{a_{12}a_{21}-a_{11}a_{22}}{a_{21}}x_2=\lambda \frac{a_{21}x_1-a_{11}x_2}{a_{21}}\\
-|A|x_2=\lambda(a_{21}x_1-a_{11}x_2) \hspace{10mm}
\because a_{11}a_{22}-a_{12}a_{21}=|A|\\
\lambda a_{21}x_1=(\lambda a_{11}-|A|)x_2\\
x_1=\frac{1}{a_{21}}
\left (
a_{11}-\frac{|A|}{\lambda}
\right )
x_2
固有値分解
固有値を対角に並べてそれ以外を0とした行列$ \Lambda $と
固有ベクトルを横に並べた行列$V$を用意すると次のような関係で表せる。
$$AV=V\Lambda$$
これを$A$について解くと
$$A=V\Lambda V^{-1} \hspace{3mm}$$
となる。
つまり、正方行列$A$は、固有値と固有ベクトルによって分解することができる。
このメリットとしては、$A$を複数回かける(行列を累乗する)場合、
固有値分解をすることで$V$と$V^{-1} \hspace{5mm}$が打ち消しあい、
$\Lambda$は対角行列のため、計算を単純化することができる。
例えば、$A^3$の場合、
A^3=(V \Lambda V^{-1})^3
=V \Lambda V^{-1} V \Lambda V^{-1} V \Lambda V^{-1}
=V \Lambda^3 V^{-1}\\
\because VV^{-1}=I
このとき$\Lambda^3$は、
\Lambda^3=
\begin{pmatrix}
\lambda_1^3&0&\cdots&0\\
0&\lambda_2^3&&\vdots\\
\vdots&&\ddots&0\\
0&\cdots&0&\lambda_n^3
\end{pmatrix}
となる。よって、$ \lambda_n $を3乗したものを対角行列にするだけで良いことになる。
特異値分解
特異値分解
固有値分解は、正方行列のみ可能だが、正方行列以外でも似たことができる。それが特異値分解である。
次の式は、単位ベクトル $\vec{v}$ を行列 $M$ で変換すると単位ベクトル $\vec{u}$ を $\sigma$ 倍したのと同じになるイメージ。
(単位ベクトルとは、大きさが1のベクトル)
$$M\vec{v}=\sigma\vec{u}$$
例えば、ベクトル $\vec{v}$ が3次元の単位ベクトルのとき、2次元に変換(1次元を0に)できる2x3の行列$M$があるとする。
これを2次元の単位ベクトル $\vec{u}$で表したら$\sigma$倍で表現できるということである。
また、上式を変換すると以下のようになる。
$$M^\top\vec{u}=\sigma\vec{v}$$
このような特殊な単位ベクトル $\vec{v},\vec{u}$ があれば特異値分解が可能である。
いくつかの $\vec{v}$ と $\vec{u}$ を用意しそれぞれ正方行列になるように横に並べた行列を作ると
以下の式のように表すことができる。
MV=US,\quad M^\top U=VS^\top\\
M=USV^{-1},\quad M^\top = VS^\top U^{-1}
これらの積より
$$MM^\top = USV^{-1}VS^\top U^{-1}=USS^\top U^{-1}$$
よって、$MM^\top$を固有値分解すれば、左特異ベクトル$U$と特異値$S$の2乗が求められる。
反対に、$M^\top M$を固有値分解すると、右特異ベクトル$V$と特異値$S$の2乗が求められる。
$$M^\top M = VS^\top U^{-1}USV^{-1}=VSS^\top V^{-1}$$
特異値分解の例
M=
\begin{pmatrix}
1&2&3\\
3&2&1
\end{pmatrix}
$MM^\top, M^\top M$について固有値分解する。
\begin{align}
MM^\top &=
\begin{pmatrix}
1&2&3\\
3&2&1
\end{pmatrix}
\begin{pmatrix}
1&3\\
2&2\\
3&1
\end{pmatrix}
=
\begin{pmatrix}
14&10\\
10&14
\end{pmatrix}\\
&=
\begin{pmatrix}
1/\sqrt{2}&-1/\sqrt{2}\\
1/\sqrt{2}&1/\sqrt{2}
\end{pmatrix}
\begin{pmatrix}
24&0\\
0&4
\end{pmatrix}
\begin{pmatrix}
1/\sqrt{2}&-1/\sqrt{2}\\
1/\sqrt{2}&1/\sqrt{2}
\end{pmatrix}
^{-1}
\end{align}
\begin{align}
M^\top M &=
\begin{pmatrix}
1&3\\
2&2\\
3&1
\end{pmatrix}
\begin{pmatrix}
1&2&3\\
3&2&1
\end{pmatrix}
=
\begin{pmatrix}
10&8&6\\
8&8&8\\
6&8&10
\end{pmatrix}\\
&=
\begin{pmatrix}
1/\sqrt{3}&1/\sqrt{2}&1/\sqrt{6}\\
1/\sqrt{3}&0&-2/\sqrt{6}\\
1/\sqrt{3}&-1/\sqrt{2}&1/\sqrt{6}
\end{pmatrix}
\begin{pmatrix}
24&0&0\\
0&4&0\\
0&0&0
\end{pmatrix}
\begin{pmatrix}
1/\sqrt{3}&1/\sqrt{2}&1/\sqrt{6}\\
1/\sqrt{3}&0&-2/\sqrt{6}\\
1/\sqrt{3}&-1/\sqrt{2}&1/\sqrt{6}
\end{pmatrix}
^{-1}
\end{align}
これより
\begin{align}
M &=
\begin{pmatrix}
1&2&3\\
3&2&1
\end{pmatrix}\\
&=
\begin{pmatrix}
1/\sqrt{2}&-1/\sqrt{2}\\
1/\sqrt{2}&1/\sqrt{2}
\end{pmatrix}
\begin{pmatrix}
24&0&0\\
0&4&0\\
0&0&0
\end{pmatrix}
\begin{pmatrix}
1/\sqrt{3}&1/\sqrt{2}&1/\sqrt{6}\\
1/\sqrt{3}&0&-2/\sqrt{6}\\
1/\sqrt{3}&-1/\sqrt{2}&1/\sqrt{6}
\end{pmatrix}
\end{align}
第二章 確率・統計
確率
頻度確率(客観確率)
・ある事象が発生する頻度
例:「ガリガリ君を買って当たりが出る確率を調べてみたら3.1%だった」という事実
→N回試行して得られた事実(ガリガリ君1箱32本につき当たり1本)
ベイズ確率(主観確率)
・信念の度合い
例:「今日の降水確率は40%だ」という予報
→これまで傾向から考えられる予測(これまでこうだったから今回もこうだっていう思い)
条件付き確率
・ある事象X=xが与えられた下で、Y=yとなる確率
例:洗濯物を干していたとき(X=x)に雨が降る(Y=y)確率
$$P(Y=y|X=x)=\frac{P(Y=y,X=x)}{P(X=x)}$$
独立な事象の同時確率
・お互いの発生には因果関係のない事象X=xと事象Y=yが同時に発生する確率
例:宝くじが当たる(X=x)のと台風が発生する(Y=y)のが同時に起きる確率
$$P(X=x, Y=y)=P(X=x)P(Y=y)=P(Y=y, X=x)$$
ベイズ則
ある街の男どもは毎日1/4の確率でビールを飲むことができ、ビールを飲むと1/2の確率でつまみを買うという。
その街のつまみを買った男がビールを飲んでいる確率を求めたい。
(ただし、その街の男たちがつまみを買う確率は1/3である。)
一般的に事象X=x, 事象Y=yに対して以下が成り立つ。
$$P(X=x|Y=y)P(Y=y)=P(Y=y)|X=x)P(X=x)$$
例題で置き換えると、
P(ビール)=1/4, P(つまみ|ビール)=1/2, P(つまみ)=1/3\\
P(ビール,つまみ)=P(つまみ|ビール)\times P(ビール)=1/2\times 1/4=1/8\\
P(ビール,つまみ)=P(つまみ,ビール)\\
P(つまみ,ビール)=P(ビール|つまみ)\times P(つまみ)\\
1/8=P(ビール|つまみ)\times 1/3\\
\therefore P(ビール|つまみ)=3/8
確率変数と確率分布
確率変数
・事象と結び付けられた数値
・事象そのものを指すと解釈する場合も多い
確率分布
・事象の発生する確率の分布
・離散値であれば表(テーブル)に示せる
例えば、コインを4回投げて表が出た回数を確率変数とし、1200回試行したとき、以下のように示せる。
| 事象 | 表:4回/裏:0回 | 表:3回/裏:1回 | 表:2回/裏:2回 | 表:1回/裏:3回 | 表:0回/裏:4回 |
|---|---|---|---|---|---|
| 確率変数 | 4 | 3 | 2 | 1 | 0 |
| 事象が発生した回数 | 75 | 300 | 450 | 300 | 75 |
| 事象と対応する確率 | 1/16 | 4/16 | 6/16 | 4/16 | 1/16 |
期待値
この分布における確率変数の平均値、あるいは「ありえそう」な値
| 事象X | $X_1\qquad$ | $X_2\qquad$ | ・・・ | $X_n\qquad$ |
|---|---|---|---|---|
| 確率変数$f(X)$ | $f(X_1)$ | $f(X_2)$ | ・・・ | $f(X_n)$ |
| 確率$P(X)$ | $P(X_1)$ | $f(X_2)$ | ・・・ | $f(X_n)$ |
$$\displaystyle 期待値E(f)=\sum_{k=1}^{n} P(X=x_k)f(X=x_k)$$
連続値の場合
$$期待値E(f)=\int P(X=x)f(X=x)dx$$
分散と共分散
分散
・データの散らばり具合
・データの各々の値が期待値からどれだけズレてるのか平均したもの
\begin{align}
分散Var(f)
&= E((f_{(X=x)}-E_{(f)})^2)\\
&= E(f_{(X=x)}^2-2f_{(X=x)}E_{(f)}+E_{(f)}^2)\\
&= E(f_{(X=x)}^2)-E(2f_{(X=x)}E_{(f)})+E(E_{(f)}^2)\\
&= E(f_{(X=x)}^2)-E(2f_{(X=x)})E_{(f)}+E_{(f)}^2\\
&= E(f_{(X=x)}^2)-(E_{(f)})^2
\end{align}
共分散
・2つのデータ系列の傾向の違い
・正の値を取れば似た傾向
・負の値を取れば逆の傾向
・ゼロを取れば関係性に乏しい
\begin{align}
共分散Cov(f,g)
&= E((f_{(X=x)}-E(f))(g_{(Y=y)}-E(g))\\
&= E(f_{(X=x)}g_{(Y=y)}-f_{(X=x)}E(g)-g_{(Y=y)}E(f)+E(f)E(g))\\
&= E(f_{(X=x)}g_{(Y=y)})-E(f_{(X=x)})E(g)-E(g_{(Y=y)})E(f)+E(f)E(g)\\
&= E(f_{(X=x)}g_{(Y=y)})-E(f)E(g)-E(f)E(g)+E(f)E(g)\\
&= E(f_{(X=x)}g_{(Y=y)})-E(f)E(g)
\end{align}
標準偏差
分散は2乗してしまっているので元のデータと単位が違う。
平方根をとって元のデータと単位を合わせたものを標準偏差$\sigma$と呼ぶ。
$$\sigma=\sqrt{Var(f)}=\sqrt{E((f_{(X=x)}-E_{(f)})^2)}$$
様々な確率分布
ベルヌーイ分布
・コイントスのイメージ
・裏と表で出る割合が等しくなくとも扱える
→可能性が2通り(0か1と)あるときに1回試行したときの分布
表を$x=1$、裏を$x=0$として、N回試行したときの$x$の平均を$\mu$とする。
平均値$\mu$を持つコインを投げたときに$x$が出る確率$P(x|\mu)$は、以下の式で表せる。
$$P(x|\mu)=\mu^x(1-\mu)^{1-x}$$
また、期待値と分散は以下の通り。
E(X)=\sum_{x=0}^{1}xP(x|\mu)=0\times(1-\mu)+1\times\mu=\mu\\
V(X)=E(X^2)-E(X)^2=\mu-\mu^2=\mu(1-\mu)
確率変数$x$は、0か1しかとらないため、$E(X^2)=E(X)=\mu$となる。
マルチヌーイ(カテゴリカル)分布
・サイコロを転がすイメージ
・各面の出る割合が等しくなくとも扱える
→可能性がK通りあるときに1回試行したときの分布
K個の事象$x_k$となるそれぞれの確率$\lambda_k$において、1回試行したときの確率を以下のように表す。
$$P(x|\lambda)=\prod_{k=1}^{K}\lambda_k^{[x=k]}$$
ここで$[x=k]$は$x$が$k$のとき1、それ以外は0となる。
二項分布
ベルヌーイ分布の多試行版
$$P(x|\lambda, n)=\frac{n!}{x!(n-x)!}\lambda^x(1-\lambda)^{n-x}$$
ガウス分布
釣鐘型の連続分布
正規分布とも呼ばれる
$$N(x;\mu,\sigma^2)=\sqrt{\frac{1}{2\pi\sigma^2}} exp(-\frac{1}{2\sigma^2}(x-\mu)^2)$$
第3章 情報理論
情報量
ある年のにんじんの収穫数がある農家Aでは10本、ある農家Bでは100本だったとする(生きていけないとかは置いといて)。
その次の年の収穫数がどちらも10本多くなったとした場合、どちらの方がより珍しいか。
これを数値化したものが情報量である。
増加量で言えばどちらも10本であるが、比率で考えたとき農家Aの方がより珍しい(情報量が多い)ということがわかる。
つまり、農家Aの方は、前年とは違う手法を取り入れたんじゃないか?という予測ができるということである。
\begin{align}
情報量_A&=\frac{\Delta w}{w_A}=\frac{10}{10}=\frac{1}{1}\\
情報量_B&=\frac{\Delta w}{w_B}=\frac{10}{100}=\frac{1}{10}
\end{align}
自己情報量
・確率$P(x)$を対数で表したもの
・確率が低いほど情報量が大きいのでマイナスをかける($P(x)$の逆数$W(x)$の対数をとる)
・対数の底が2のとき、単位はビット(bit)
・対数の底がネイピア数$e$のとき、単位はナット(nat)
$$I(x)=-\log(P(x))=\log(W(x))$$
シャノンエントロピー
・自己情報量の期待値
$$H(x)=E(I(x))=-E(\log(P(x))=-\sum(P(x)\log(P(x))$$
カルバック・ライブラー・ダイバージェンス
・同じ事象・確率変数における異なる確率分布$P,Q$の違いを表す
\begin{align}
D_{KL}(P||Q)&=\mathbb{E}_{x\sim P}[\log\frac{P(x)}{Q(x)}]=\mathbb{E}_{x\sim P}[\log(P(x))-\log(Q(x))]\\
&=\sum_{x}P(x)(-\log(Q(x))-(-\log(P(x)))\\
&=\sum_{x}P(x)\log\frac{P(x)}{Q(x)}
\end{align}
つまり、$P(x)$と$Q(x)$のそれぞれの自己情報量の差(距離)を$P(x)$の分布で平均している。
イメージとしては、最初$P(x)$として与えられていた事象について、観測したところ$Q(x)$となったとき、
$P(x)$からどれだけズレてるかを評価することができる。
$Q(x)$が$P(x)$と一致すると0となり、ズレが大きいほど値は大きくなる。
交差エントロピー
・KLダイバージェンスの一部を取り出したもの
・$Q(x)$についての自己情報量を$P(x)$で平均している
\begin{align}
D_{KL}(P||Q)&=\sum_{x}P(x)(-\log(Q(x))-(-\log(P(x)))=H(P,Q)-H(P)\\
H(P,Q)&=H(P)+D_{KL}(P||Q)\\
H(P,Q)&=-\mathbb{E}_{x\sim P}\log(Q(x))=-P(x)\log(Q(x))
\end{align}