Webページをスクレイピングしたい!
必要なもの
- Pythonのrequestsライブラリ
- BeautifulSoup4
上記2つがなければあらかじめインストールしておきましょう。
Pythonのrequestsライブラリとは
- このライブラリでウェブページをダウンロード可能。
- ウェブサーバーに対してGETリクエストを出す (HTMLコンテンツをダウンロード)
リクエストを走らせると、Responseオブジェクトが来ます。このオブジェクトはstatus_codeプロパティを持ち、ウェブページがきちんとダウンロードされたかどうかを判断するのです。
scraping_test.py
from bs4 import BeautifulSoup
import requests
page = requests.get("http://dataquestio.github.io/web-scraping-pages/simple.html")
print(page.status_code)
この時点での$ python scraping_test.py実行結果
200となりました。status_codeが200ということは、ダウンロード成功です。
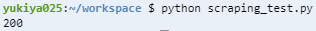
content プロパティを使えばHTMLコンテンツを表示します。
scraping_test.py
from bs4 import BeautifulSoup
import requests
page = requests.get("http://dataquestio.github.io/web-scraping-pages/simple.html")
# print(page.status_code)
print(page.content)
この時点での$ python scraping_test.py実行結果
b'<!DOCTYPE html>\n<html>\n <head>\n <title>A simple example page</title>\n </head>\n <body>\n <p>Here is some simple content for this page.</p>\n </body>\n</html>'
ここまでrequestsライブラリの説明をしました。このライブラリのプロパティとしてはstatus_codeとcontentを覚えておきましょう。
BeautifulSoupライブラリとは
取得したHTMLドキュメントを解析し、テキストを抽出するライブラリです。
ドキュメントを解析するためにBeautifulSoupクラスのインスタンスを作成します。
HTMLパーサー: HTMLのテキストや特定タグの内容を抽出。python標準のhtml.parserでOK。
prettify()メソッド: ソースコードを見やすく表示
scraping_test.py
soup = BeautifulSoup(page.content, 'html.parser')
print(soup.prettify())
参考ページ: dataquest