背景
- これまでの画像認識タスク
- 深く大きい畳み込みニューラルネット
- 数十億FLOPSの計算
- Shuffle Netは
- 限られた計算量で性能を求めるCNN architecture
- 数十~数百MFLOPSの計算
- Channel Shuffle + Group Convolution
- Xception とResNeXtの1x1Convの非効率さからアイデアを得る
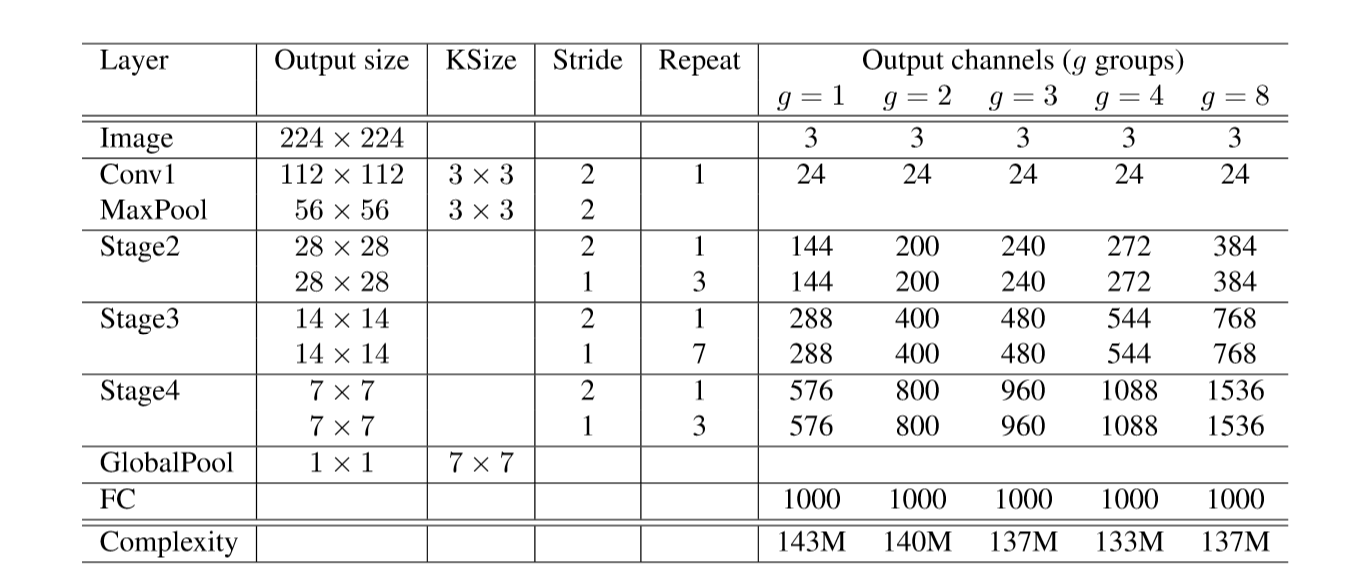
ShuffleNet
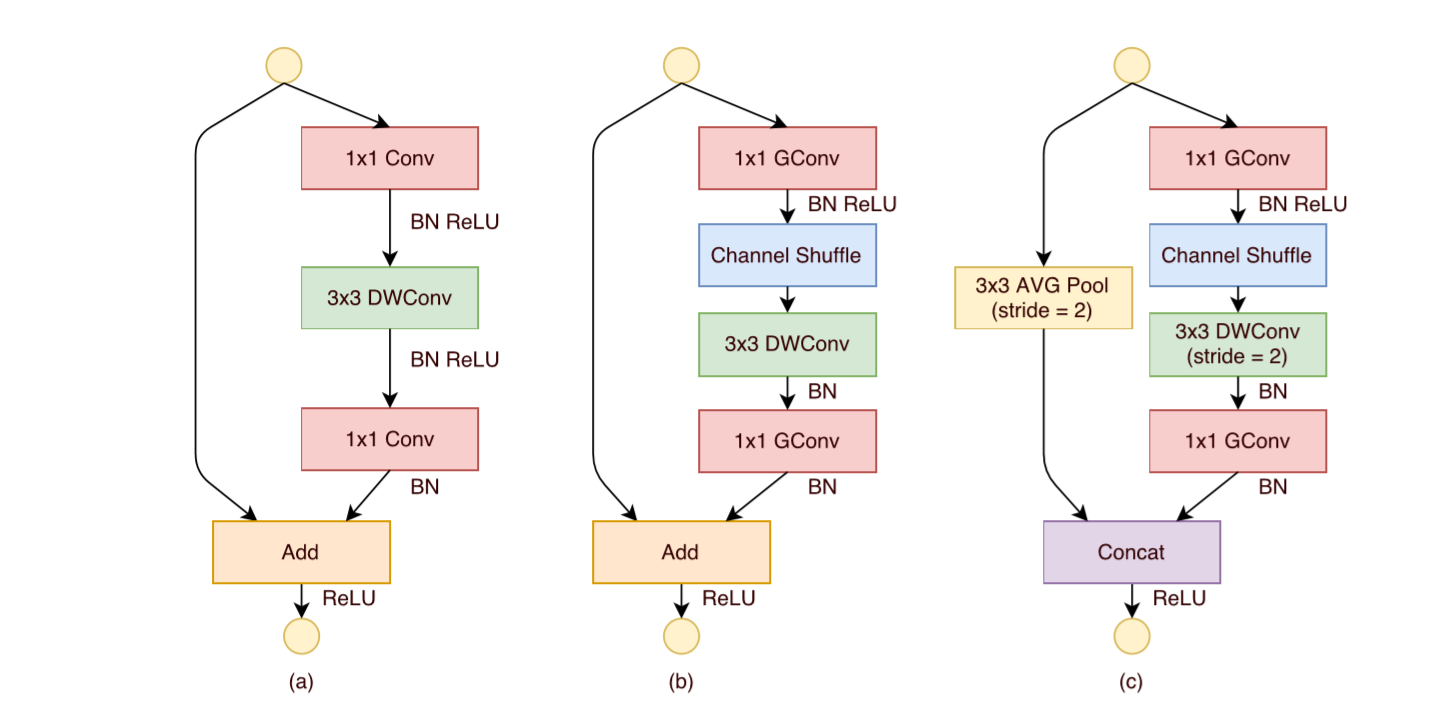
Figure2: Shuffle Net Unit
a) bottleneck unit with depth-wise convolution
b) ShuffleNet unit with pointwise group convolution
c) ShuffleNet unit with stride = 2
Group Convolutions
それぞれのConvolutionの計算量 (B)
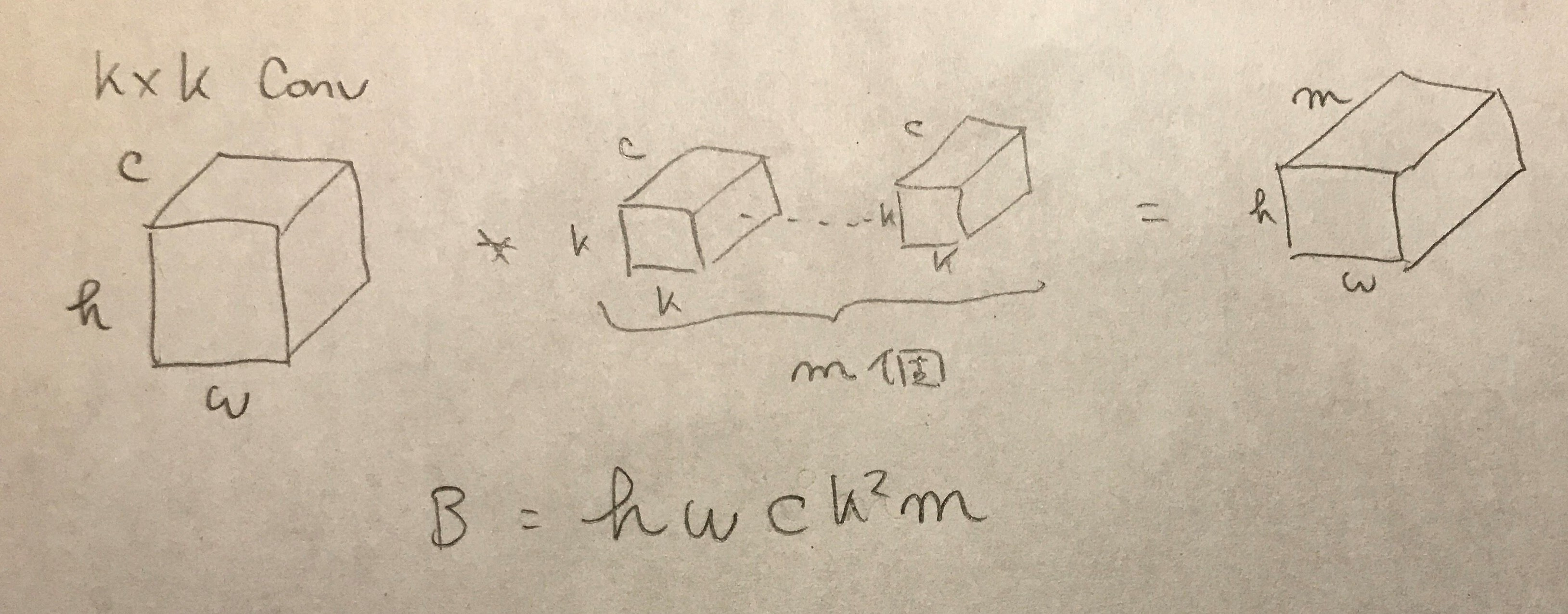
Xception とResNeXtの1x1Convの非効率さ
1x1Conv, 3x3depth-wise, 1x1Conv の計算量
$B = hwm(c + k^2 + c)$
ResNet(1x1conv, 3x3conv, 1x1convの計算量)
$B = hw(cm + 9m^2 + cm) = hw(2cm+9m^2)$
- $B_{1\times1conv} = hwcm$
- $B_{3\times3 conv} = hwcmk^2$
- $B_{1\times1conv} = hwcm$
ResNeXt(1x1conv, 3x3Gconv, 1x1convの計算量)
$B = hw(cm + \frac{9m^2}{g} + cm) = hw(2cm+\frac{9m^2}{g})$
- $B_{1\times1conv} = hwcm$
- $B_{3\times3 Gconv} = \frac{hwm^2k^2}{g}$
- $B_{1\times1conv} = hwcm$
ShuffleNet(1x1Gconv, 3x3dwconv, 1x1Gconvの計算量)
$B = hw(\frac{cm}{g} + 9m + \frac{cm}{g}) = hw(\frac{2cm}{g}+9m)$
- $B_{1\times1Gconv} = \frac{hwcm}{g}$
- $B_{3\times3 dwconv} = hwk^2m$
- $B_{1\times1conv} = hwcm$
Channel Shuffle
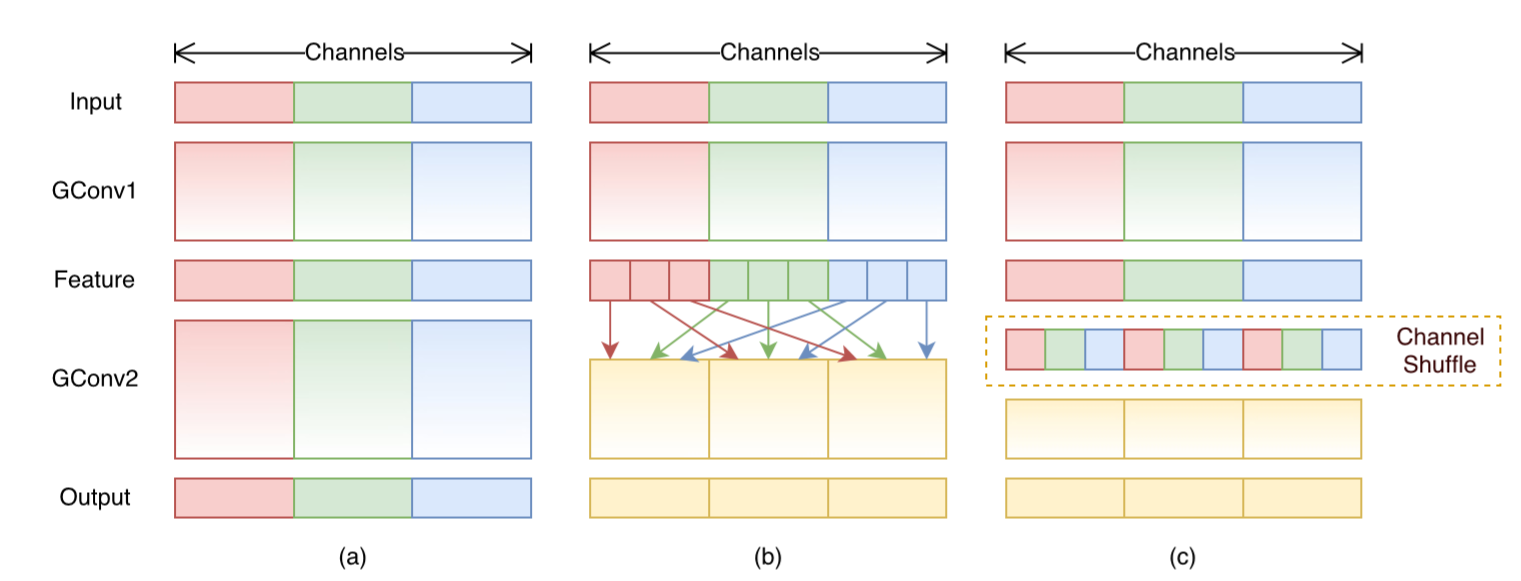
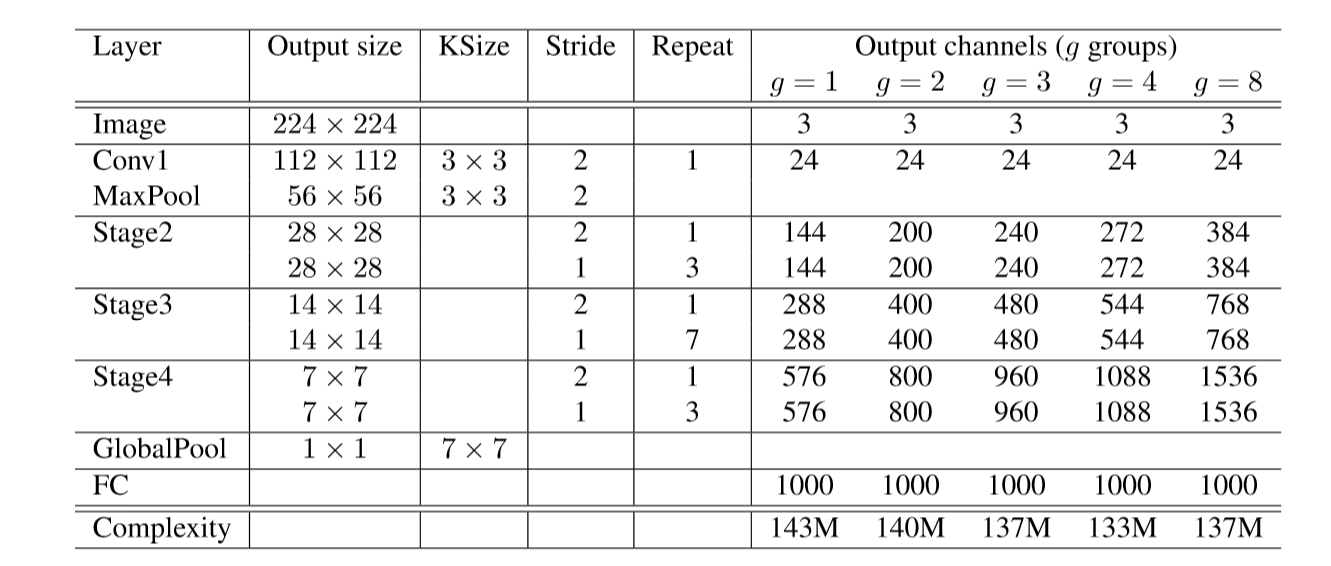
Table1: ShuffleNet architecture
モデル評価
Pointwise Group Convolution

Table2: Classification error vs. number of groups g
- gが増えることでclassification errorが減っていることがわかる
- 0.5x : g=8の時飽和している
- gが増えるにつれ、畳み込みフィルタの入力チャネルが少なくなってしまうため?
- 0.25x : gが大きいほど性能が良い
- 小さいモデルでは広い特徴マップを取ることで良い結果が出る
Channel Shuffle vs No Shuffle
- cross-group information interchange
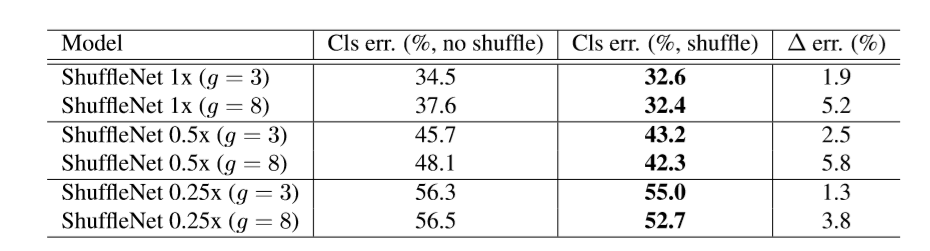
Table3: ShuffleNet with/withoutchannel shuffle
- 全体的にShuffleした方が良い結果が出たといえる
- gが大きい方が良い結果が出ている
- gを増やすことでシャッフルがよりたくさん行われる
Comparison with Other Structure Units
-
Stage 2-4のShuffleNet unitsをそれぞれ他のstructureに置き換える
-
channel数を調節してcomplexityを調節

table 4: classficiation error vs various structure
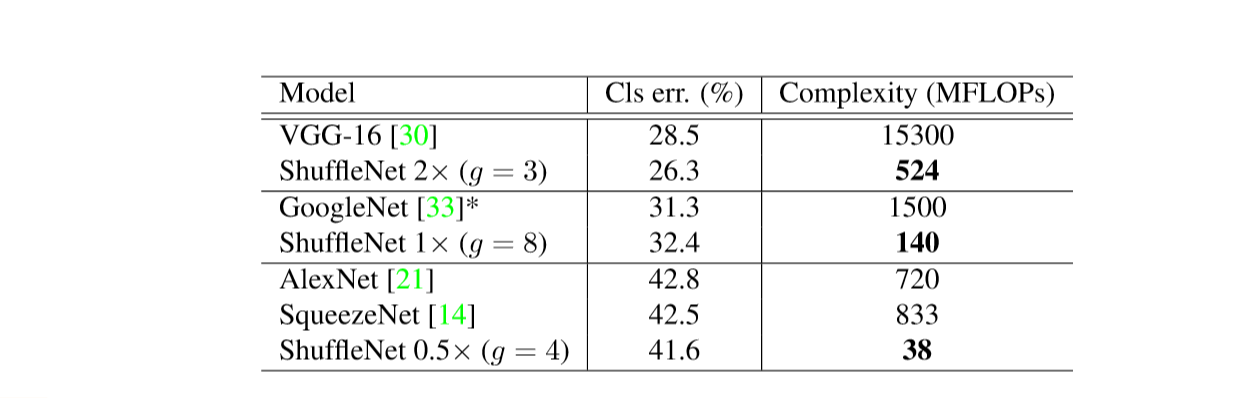
table 6: Complexity comparison
- 圧倒的に小さいcomplexityで同じような性能を出すことができる
Comparison with MobileNets and Other Frameworks
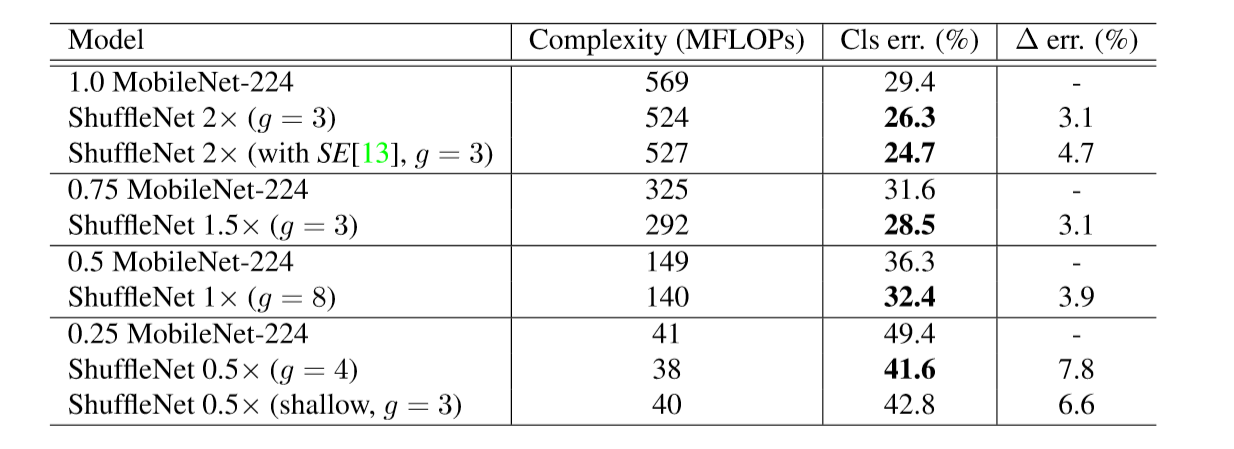
table 5: ShuffleNet vs. MobileNet on ImageNet Classification
- Shuffle Net > MobileNet for all complexities
- Shuffle Netは深さではなく効率の良い構造で良い精度を出している

table 7: Object detection results on MS COCO
推論時間
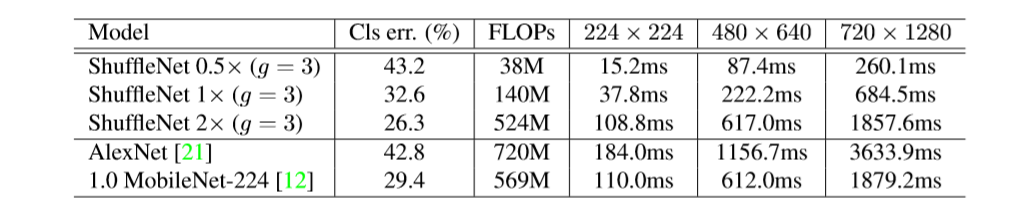
table 8: actual inference time on a mobile device