はじめに
機械学習を自分なりに消化するために、記事にしてまとめていきたい。シリーズ化する予定で基礎から始まり、徐々に発展的な内容を扱っていく。背景にある理論⇨コードという流れですすめる。質問は歓迎。
強化学習
強化学習とは、いわゆる教師あり学習とは違い、事前に与えられたデータセットに”答え”が与えられていない中で、最適解を模索していくアプローチ法である。 例えば、目の前にブラックジャックの台が2つあるとしよう(ここでは特異的にディーラーによって勝率が変わるものとする)。 当然ながら勝率が高い方でプレイし続ければ、それだけ利益も最大化できる。 しかし、最初のうちは、それぞれの台がどれだけのお金をリターンしてくれるかわからないわけで、回数を重ねてどっちが優れているかを”学習”する。これが強化学習の基本理念である。


ここで、のちに詳しく見る(Explore-Exploit dillemma)と呼ばれる大事になる2つの”拮抗”するファクターは、
Exploit (~Greedy)
利益を最大化しようとする力
Explore (~Epsilon)
(直近の)利益の最大化を犠牲にしたうえでの、より大きな利益を”求める”力
である。次に具体的なモデルのひとつEpsilon-Greedy Algorithmをみてみよう。
Epsilon-Greedy Algorithm
端的に言うと、「基本的にはリターンが高い方をチョイスするが(Greedy)、たまに(Epsilonくらい小さい確率で)気分を変えてランダムにチョイス」すると言う戦法である。上のブラックジャックの例だと、合計N回ブラックジャックをプレイするとして、仮に最初に男性ディーラー(以下M)に勝利したとする。すると、リターンつまりMに対する勝率(MW)は1、一方女性ディーラー(W)に対してはわからないので仮に勝率(WW)0とすると、次にプレイする台は再びMとなる。さて、この2度目のプレイにおいて、勝利しようが負けようが勝率は、MW>WWである。このようにひたすらその時々で勝率が高い方つまりMとばかりプレイ(Complete Greedy)していると、一方のディーラーとしかプレイすることはなく、Wに対する勝率がわからないままプレイを永遠と続けてしまう。そこで、持ち出されたのが後半のEpsilonの確率(通常5〜10%)で全ての選択肢からランダムでチョイスすると言う箇所である。これによって十分大きなNを取れば、勝率が更新されないディーラーはいなくなり全ての勝率を推しはかることができる。
さて、ここで大切なのはEpsilon、つまり「ランダムにプレイする確率」である。かりにこれが大きな値、50%とした場合どうなるかと言うと、半分の確率で適当にプレイすると言うことなので2人ディーラーと同数程度プレイすることになり早い段階で二人に対する勝率を知れる。と同時に、相対的にGreedyの戦略が弱まってしまい、トータルでのリターンが小さくなってしまう。今度は逆にEpsilonを小さく撮りすぎてしまった場合はどうなるか。答えは、その逆で早くから勝率が高いディーラーを決めつけてしまい(本当に合ってるとは限らない)、そのディーラーとしかプレイしなくなる。つまり、バランスが大切と言うこと(人生もそう)。ちなみに、私の人生はEpsilon小さめ(余談)。
これらのことを次で実装しよう。
実装
python3.x で書いた。
まずは、libraryとのちに使う引数を代入。
import numpy as np
import matplotlib.pyplot as plt
Num_try = 1000
Eps =0.05
Bandit_prob = [0.1,0.45,0.75]
ここで、Bandit_probに入っている数字は、各ディーラーに対する「本当の勝率」であるが、これを学習によって求めるのがこのアルゴリズムの目標である(よって、プレイヤー側は本来知り得ない情報であることに注意)。
次に、核となるアルゴリズムを実装。
class Bandit():
def __init__(self,p): # p:winning rate- pretend not to know what these are
self.p = p
self.p_estimate = 0
self.N = 0
def pull(self): # return a 1 with p
return np.random.random() < self.p # random takes [0,1] randomly
def update(self, x):
self.N +=1
self.p_estimate = (1/self.N)*(x + self.p_estimate*(self.N-1))
# Using the formula below
# <p>_n*N = p_n(=x) + <p>_(n-1)*(N-1)
def experiment():
bandits = [Bandit(p) for p in Bandit_prob] # we don't know what are in Bandit_prob
rewards = np.zeros(Num_try)
num_explored = 0
num_exploited = 0
num_opt = 0
opt_j = np.argmax([b.p for b in bandits]) # # in bandit_prob
for i in range(Num_try):
# follow epsilon-greedy algorythm
if np.random.random() < Eps:# explore
num_explored += 1
# j is index
j = np.random.choice(list(range(len(bandits))))
else: # greed
num_exploited += 1
j = np.argmax([k.p_estimate for k in bandits])
if j == opt_j:
num_opt += 1
x = bandits[j].pull() #the chosen one can get reward or not?
rewards[i] = x
bandits[j].update(x)
return bandits, rewards, num_explored, num_exploited, opt_j
はじめのBanditないのメソッドpullによって、対戦結果(win:1、Lose:0)を返す。その結果に応じて、その都度、updateによって各ディーラーに対する勝率を更新していく。ここで言う勝率と言うのは、プレイヤー側として対戦する中で、計算して得られたものであって、ディーラーが本来持つものと異なる(それに近づけていくのが学習)ことに注意する。
結果
さて、これを複数のEpsilonの下でプロットしよう。横軸はプレイ数、縦軸は勝率、黒い横線は最大の勝率である75%だ。
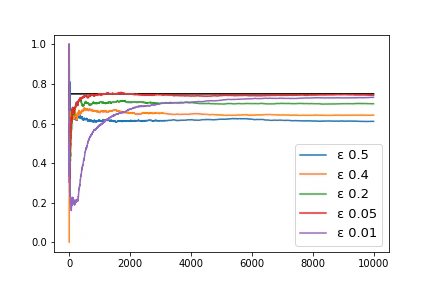
このプロットには多くの知見が詰まっている。プラトーまでの速さ、その高さ、なぜ75%まで到達しないのか、、、次回はそこら辺を見つつ、進んでいこう。
サマリー
- 強化学習とは、答えがない中リターン(報酬)を基に選択肢の確率分布を修正していくモデル
- Epsilon-Greedy モデルは、その代表のひとつであり
- Epsilonの大きさによって大きく様相が異なってくる。
References
Udemy- Artificial Intelligence: Reinforcement Learning in Python (めちゃめちゃ良い)