2008年度夏の院試の解答例です
※記載の内容は筆者が個人的に解いたものであり、正答を保証するものではなく、また東京大学及び本試験内容の提供に関わる組織とは無関係です。
出題テーマ
- グラフ問題
- unionfind
- 二分探索
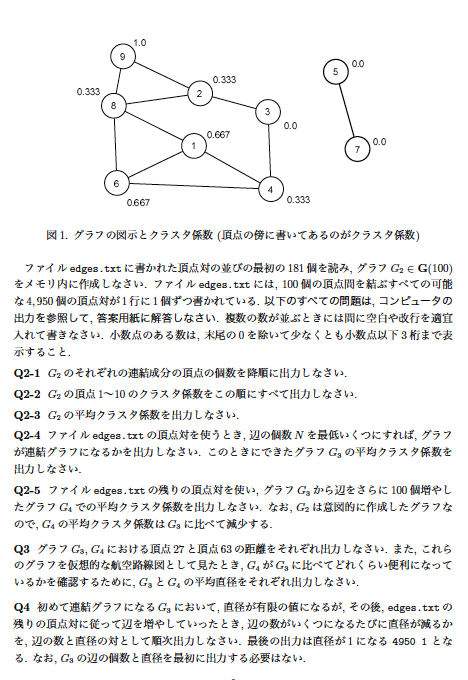
問題文
※ 東京大学側から指摘があった場合は問題文を削除いたします。

配布ファイル
リンクからdownloadできます。
(1)
グラフ書くだけなので省略
(2)
2-1, 2-2, 2-3
from collections import deque
from Unionfind import Unionfind
class Edge(object):
def __init__(self, v1, v2):
self.v1 = v1 - 1
self.v2 = v2 - 1
def __repr__(self):
return '{0} - {1}'.format(self.v1 + 1, self.v2 + 1)
def inputdata(file_path, line = 181):
with open(file_path, 'r') as f:
edges = []
for i in range(line):
txt = f.readline()
if txt[-1] == '\n':
txt = txt[:-1]
txt_array = txt.split(' ')
edge = Edge(int(txt_array[0]), int(txt_array[1]))
edges.append(edge)
return edges
def all_inputdata(file_path):
with open(file_path, 'r') as f:
text_array = f.readlines()
edges = []
for txt in text_array:
if txt[-1] == '\n':
txt = txt[:-1]
txt_array = txt.split(' ')
edge = Edge(int(txt_array[0]), int(txt_array[1]))
edges.append(edge)
return edges
edges = inputdata('test001.txt')
all_edges = all_inputdata('test001.txt')
def make_n_list(edges):
ret = [[] for _ in range(100)]
for edge in edges:
ret[edge.v1].append(edge.v2)
ret[edge.v2].append(edge.v1)
return ret
def make_n_array(edges):
ret = [[0 for _ in range(100)] for _ in range(100)]
for edge in edges:
ret[edge.v1][edge.v2] = 1
ret[edge.v2][edge.v1] = 1
return ret
n_list = make_n_list(edges)
n_array = make_n_array(edges)
# print(n_list)
# print(n_array)
def get_connections(n_list):
node_num = 100
# 0: 未発見, 1: 発見, 2: 到達
color = [0 for _ in range(node_num)]
connections = []
for s in range(node_num):
connection = []
if color[s] == 2:
continue
q = deque([s])
color[s] = 1
while len(q) > 0:
u = q.popleft()
color[u] = 2
connection.append(u)
for v in n_list[u]:
if color[v] == 0:
q.append(v)
color[v] = 1
if len(connection) > 0:
connections.append(connection)
return connections
connections = get_connections(n_list)
def solve2_1(connections):
ret = []
for connection in connections:
ret.append(len(connection))
ret.sort()
return ret[::-1]
def get_all_cluster(n_list, n_array):
ret = [0.0 for _ in range(100)]
for index, neighbor_nodes in enumerate(n_list):
size = len(neighbor_nodes)
maximum = size * (size - 1) // 2
if size < 2:
continue
cnt = 0
for i in range(len(neighbor_nodes) - 1):
u = neighbor_nodes[i]
for j in range(i+1, len(neighbor_nodes)):
v = neighbor_nodes[j]
if n_array[u][v] != 0:
cnt += 1
ret[index] = (cnt / maximum)
return ret
all_cluster = get_all_cluster(n_list, n_array)
def solve2_2(all_cluster):
for i in range(10):
print(all_cluster[i])
def get_cluster_average(all_cluster):
total = 0.0
for cluster in all_cluster:
total += cluster
return total / len(all_cluster)
def solve2_3(all_cluster):
print(get_cluster_average(all_cluster))
2-4, 2-5
from collections import deque
from Unionfind import Unionfind
class Edge(object):
def __init__(self, v1, v2):
self.v1 = v1 - 1
self.v2 = v2 - 1
def __repr__(self):
return '{0} - {1}'.format(self.v1 + 1, self.v2 + 1)
def all_inputdata(file_path):
with open(file_path, 'r') as f:
text_array = f.readlines()
edges = []
for txt in text_array:
if txt[-1] == '\n':
txt = txt[:-1]
txt_array = txt.split(' ')
edge = Edge(int(txt_array[0]), int(txt_array[1]))
edges.append(edge)
return edges
all_edges = all_inputdata('test001.txt')
def get_minimum_N(all_edges):
N = -1
unionfind = Unionfind(100)
for index, edge in enumerate(all_edges):
N = index + 1
unionfind.unite(edge.v1, edge.v2)
if unionfind.treeNum == 1:
break;
return N
def solve2_4(all_edges):
print(get_minimum_N(all_edges))
def solve2_5():
all_edges = all_inputdata('test001.txt')
minimum_N = get_minimum_N(all_edges)
N = minimum_N + 100
edges = all_edges[:N]
n_list = make_n_list(edges)
n_array = make_n_array(edges)
all_cluster = get_all_cluster(n_list, n_array)
print(get_cluster_average(all_cluster))
(3)
def floyd(edges):
inf = 50000
dist = [[inf for _ in range(100)] for _ in range(100)]
for i in range(100):
dist[i][i] = 0
for edge in edges:
dist[edge.v1][edge.v2] = 1
dist[edge.v2][edge.v1] = 1
for i in range(100):
for j in range(100):
for k in range(100):
dist[j][k] = min(dist[j][k], dist[j][i] + dist[i][k])
return dist
def get_average_diameter(dist):
total = 0
mom = len(dist) * (len(dist) - 1) // 2
for i in range(len(dist)-1):
for j in range(i+1, len(dist)):
total += dist[i][j]
return total / mom
def solve3():
all_edges = all_inputdata('test001.txt')
minimum_N = get_minimum_N(all_edges)
N = minimum_N + 100
g3_edges = all_edges[:minimum_N]
g4_edges = all_edges[:N]
g3_n_list = make_n_list(g3_edges)
g4_n_list = make_n_list(g4_edges)
g3_n_array = make_n_array(g3_edges)
g4_n_array = make_n_array(g4_edges)
g3_dist = floyd(g3_edges)
g4_dist = floyd(g4_edges)
g3_average_diameter = get_average_diameter(g3_dist)
g4_average_diameter = get_average_diameter(g4_dist)
print('G3: 27 - 63: {0}'.format(g3_dist[26][62]))
print('G4: 27 - 63: {0}'.format(g4_dist[26][62]))
print('G3 average diameter: {0}'.format(g3_average_diameter))
print('G4 average diameter: {0}'.format(g4_average_diameter))
(4)
def get_diameter(n_list):
dist = []
for s in range(len(n_list)):
color = [0 for _ in range(100)]
d = [0 for _ in range(100)]
q = deque([s])
color[s] = 1
while len(q) > 0:
u = q.popleft()
color[u] = 2
for v in n_list[u]:
if color[v] == 0:
q.append(v)
color[v] = 1
d[v] = d[u] + 1
dist.append(d)
ret = 0
for i in range(len(dist)-1):
for j in range(i+1, len(dist)):
ret = max(ret, dist[i][j])
return ret
def binary_search(diameter, ok, ng, all_edges):
while abs(ok - ng) > 1:
mid = (ok + ng) // 2
n_list = make_n_list(all_edges[:mid])
if get_diameter(n_list) == diameter:
ok = mid
else:
ng = mid
return ok
def solve4():
all_edges = all_inputdata('test001.txt')
minimum_N = get_minimum_N(all_edges)
g3_edges = all_edges[:minimum_N]
g3_n_list = make_n_list(g3_edges)
g3_diameter = get_diameter(g3_n_list)
# diameter = 2 ~ (minimum_N - 1)を二分探索
ok = minimum_N
ng = 4950
ans_set = set([])
for diameter in range(2, g3_diameter+1):
N = binary_search(diameter, ok, ng, all_edges) + 1
ng = N + 1
ans_set.add(N)
ans = [i for i in ans_set]
ans.sort()
for N in ans:
print('{0}: {1}'.format(N, get_diameter(make_n_list(all_edges[:N]))))
感想
- 以下V(node数), E(edge数)
- アルゴリズムがてんこ盛りな年で、個人的には好きです。(大変だけど笑)
- 2-3までは隣接リストと隣接行列を組み合わせれば比較的簡単に整理できると思います。
- 2-4でまさかのunionfindの実装が求められます笑。
- しかし、最低のNさえ求めることができればいいのでunionfindを知らなくても、一応毎回bfsなりして見つけることもできます。その場合の計算量は毎回V * Eですが,幸いN=202(E=202)で連結グラフになるので一応なんとかなります。(さすがに試験なのでunionfindできないだけでここから全部詰みになるようにはしてないですね笑)
- (3)は全点間最短距離なのでとっさにフロイドを使ってしまいましたが重みも向きもなしなのでbfsの方がO(V*E)なのでフロイドのO(V^3)より早いですね
- (4)は腕のみせどころでしたね。計算量を詳しく考えてみると普通にN=202から4950まで毎回直径を求めるやり方だと計算量が約EVEになります。v=100と固定ですがEが平均2500くらいですので計算量は約10^9 ~ 10^10くらいになると思います。これは十数分か、下手したらもっとかかると思います。そこでN=202の直径を見てみるとこの段階ですでに12です。そして直径はNが増加するごとに単調減少して行くので12,11,...,2,1となるはずです。ここで単調性に注目できると二分探索を使う方法が思いつくでしょう。直径がギリギリ=1,2,...12の時を二分探索によって求めればいいので、計算量は12VE*logEと大幅に削減できます。(さらに探索範囲はますます小さくなって行きますのでEの値がどんどん小さくなって行きます)
- 全体としてすごく競技プログラミングっぽい年だと思いました。