20011年度夏の院試の解答例です
※記載の内容は筆者が個人的に解いたものであり、正答を保証するものではなく、また東京大学及び本試験内容の提供に関わる組織とは無関係です。
出題テーマ
- 正規表現
問題文
※ 東京大学側から指摘があった場合は問題文を削除いたします。
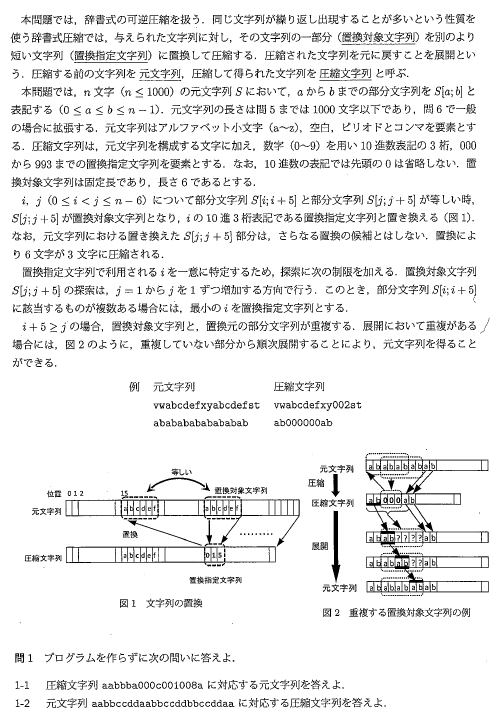
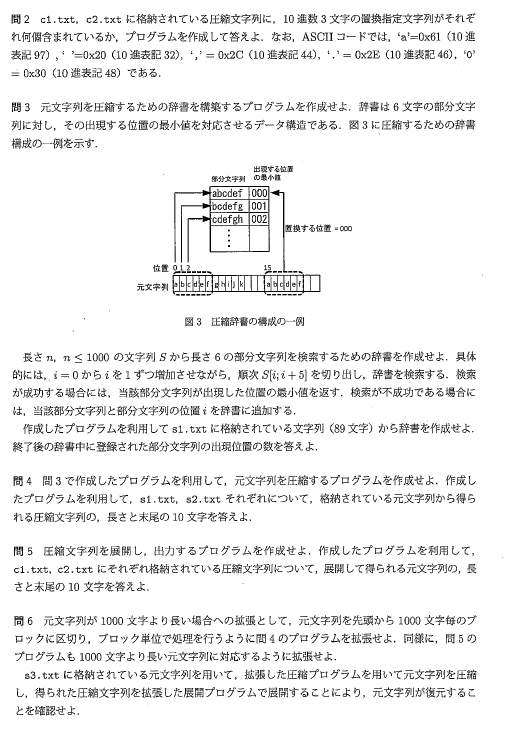
(1)
1-1
aabbbaaabbbacabbbaabbbacaa
1-2
aabbccdd000dd002aa
(2)
import re
def get_row_text(file_path):
with open(file_path, 'r') as f:
return f.read()
def get_compressions(text):
return re.findall(r'[0-9]{3}', text)
def solve2(file_path):
row_text = get_row_text(file_path)
compressions = get_compressions(row_text)
print(len(compressions))
(3)
def get_row_text(file_path):
with open(file_path, 'r') as f:
return f.read()
def make_dic(text):
n = len(text)
dic = {}
key_set = set([])
for i in range(n - 5):
si = text[i:i+6]
if not(si in key_set):
str_num = str(i)
str_num = '0' * (3 - len(str_num)) + str_num
dic[si] = str_num
key_set.add(si)
return dic
def solve3(file_path):
row_text = get_row_text(file_path)
dic = make_dic(row_text)
print(dic)
(4)
def get_row_text(file_path):
with open(file_path, 'r') as f:
return f.read()
def compress_text(text):
text_array = list(text)
dic = make_dic(text)
key_set = set(dic.keys())
n = len(text)
j = 0
memo = []
while j < n - 5:
sj = text[j:j+6]
if sj in key_set:
v = dic[sj]
int_v = int(v)
if int_v == j:
j += 1
continue
tmp = ['9', '9', '9']
tmp.extend(list(v))
text_array[j:j+6] = tmp
j += 6
else:
j += 1
return ''.join(text_array).replace('999', '')
def solve4(file_path):
row_text = get_row_text(file_path)
compressed_text = compress_text(row_text)
print(compressed_text)
(5)
def get_row_text(file_path):
with open(file_path, 'r') as f:
return f.read()
def get_content(text):
size = len(text)
ret = ''
ret += (text * ((6+size-1)//size))
return ret[:6]
def decode(compressed_text):
text = compressed_text
codes = re.findall(r'[0-9]{3}', compressed_text)
for code in codes:
m = re.search(code, text)
i = int(code)
j = m.span()[0]
tmp = min(6, j - i)
rep = get_content(text[i:i+tmp])
text = text[:j] + rep + text[j+3:]
return text
def solve5(file_path):
compressed_text = get_row_text(file_path)
text = decode(compressed_text)
print('size: {0}, last10: {1}'.format(len(text), text[-10:]))
(6)
import re
def get_row_text(file_path):
with open(file_path, 'r') as f:
return f.read()
def get_compressions(text):
return re.findall(r'[0-9]{3}', text)
def make_dic(text):
n = len(text)
dic = {}
key_set = set([])
for i in range(n - 5):
si = text[i:i+6]
if not(si in key_set):
str_num = str(i)
str_num = '0' * (3 - len(str_num)) + str_num
dic[si] = str_num
key_set.add(si)
return dic
def compress_text(text):
text_array = list(text)
dic = make_dic(text)
key_set = set(dic.keys())
n = len(text)
j = 0
memo = []
while j < n - 5:
sj = text[j:j+6]
if sj in key_set:
v = dic[sj]
int_v = int(v)
if int_v == j:
j += 1
continue
tmp = ['9', '9', '9']
tmp.extend(list(v))
text_array[j:j+6] = tmp
j += 6
else:
j += 1
return ''.join(text_array).replace('999', '')
def compress_text_mt1000(text):
block_nums = 0
rest_num = len(text)
text_block = []
while rest_num > 0:
if rest_num >= 1000:
text_block.append(text[block_nums*1000:(block_nums+1)*1000])
block_nums += 1
rest_num -= 1000
else:
text_block.append(text[block_nums*1000:])
block_nums += 1
rest_num -= 1000
compressed_text_block = []
for text in text_block:
compressed_text_block.append(compress_text(text))
return ''.join(compressed_text_block)
def get_content(text):
size = len(text)
ret = ''
ret += (text * ((6+size-1)//size))
return ret[:6]
def decode(compressed_text):
text = compressed_text
codes = re.findall(r'[0-9]{3}', compressed_text)
for code in codes:
m = re.search(code, text)
i = int(code)
j = m.span()[0]
tmp = min(6, j - i)
rep = get_content(text[i:i+tmp])
text = text[:j] + rep + text[j+3:]
return text
def decode_mt1000(compressed_text):
decode_text_size = 0
s = 0
i = 0
compressed_text_blocks = []
while i < len(compressed_text):
ch = compressed_text[i]
if ch.isnumeric():
decode_text_size += 6
i += 3
else:
decode_text_size += 1
i += 1
if decode_text_size % 1000 == 0 or i == len(compressed_text):
compressed_text_blocks.append(compressed_text[s:i])
s = i
ret = ''
for compressed_text in compressed_text_blocks:
ret += decode(compressed_text)
return ret
def solve6(file_path):
row_text = get_row_text(file_path)
compressed_text = compress_text_mt1000(row_text)
text = decode_mt1000(compressed_text)
print(text)
感想
- 今まで避けてきたけどさすがに正規表現使いました笑。
- 後は特にすごく難しい部分はないと思います。ただ、文字列を切りはりしているので計算量はちょっと微妙なところはあると思います。