
みなさん、こんにちは。
本記事は株式会社ポーラ・オルビスホールディングス Advent Calendar 2024 11日目の記事としてSnowflakeを使った実機検証について記載いたします。
データ基盤を構築、運用している皆さんにとって、効率的なテーブル設計は欠かせない課題の一つですよね。
私たちも同じ課題に直面しており、Snowflakeを中心にデータ基盤の設計について日々試行錯誤しています。
今回は社内で「Snowflakeの内部テーブルと外部テーブル、実際どちらがいいのか?」という疑問から始まった検証結果を、この記事で共有します。
この記事が皆さまの設計や議論のインプットとしてご活用いただければ幸いです。
免責事項
- 2024年10月時点の機能を利用しております
- 文章の拙さや抜け漏れがあるかもしれません。ご指摘いただければ励みになります!
本記事に書くこと
- Snowflakeにおける外部テーブル/内部テーブルの定義からデータ取得までの処理速度の比較
- 処理速度だけで見た比較見解
本記事に書かないこと
- Snowflakeのコスト(ストレージコストおよびウェアハウスコスト)
- AWS S3コスト
なぜ記事にするのか
Snowflakeに触れていて公式ドキュメントの読込みや机上計算だけでは感じ取れない側面があるなと感じていました。
それは弊社だけでなくデータ界隈に属する方の中にも同じ考えを持っているエンジニアさんがいらっしゃるのではと考え、検証や設計に向けた一助となれば嬉しいなと思った次第です。
また弊社ではテックブログとしてQiitaに様々な記事を投稿しております。
私たち化粧品企業がどのような技術を扱って日々取り組んでいるかを外部発信しております。
今回のSnowflakeについても外部発信することで私たちへの解像度が上がり、興味を持っていただければ嬉しいです。
検証の背景
弊社では2024年度より新しいデータ基盤の構築に向けての活動が開始されました。
データ基盤の中核となるDWHとしてSnowflakeを選定いたしました。(製品選定の記事はまた別途どこかで)
各種データソースからSnowflakeにデータ連携する際、どういった構成が我々の組織にベストなのかを考える中で、下図のようなアーキテクチャ構成を設計しました。
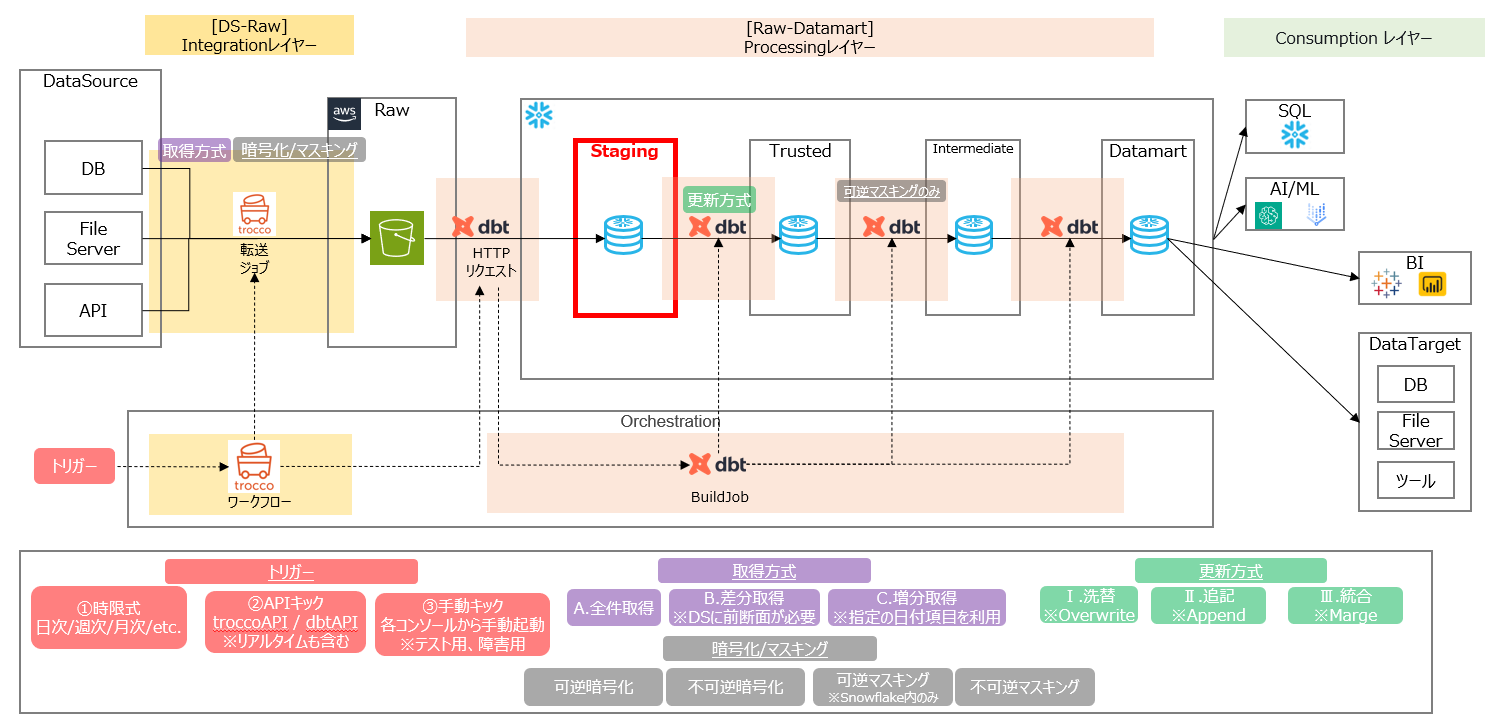
上記アーキテクチャの中央部に赤枠で記載した「Staging」レイヤーについて議論になりました。
思想としてデータソースにあるデータをS3(図でいうRawレイヤー)に出力し、その後Stagingとして定義するのですが、ここをSnowflakeの内部テーブルとするか、外部テーブルとするかが焦点となり、先ずは処理スピードを比較してみようとのことで検証する流れになりました。
検証方法
- データをS3に配置してある状態から内部/外部テーブルに対し抽出処理を実行し、抽出完了までの処理時間を計測
- 偶発性による処理低下/向上を拾わないよう計測は同じケースで最低3ショットは実行
- キャッシュを使わないよう明示的なキャッシュ利用の停止
ALTER SESSION SET USE_CACHED_RESULT = FALSE;
- 実施シナリオイメージ

内部テーブルの「①テーブルデータの除去」は弊社のデータ基盤における本番運用時に組込想定の前処理です。
バルクコピーを実行する上で必ず必要な処理ではございませんのであしからず。
事前準備
- Snowflakeアカウントの準備
-プラットフォーム:AWS
-エディション:Business Critical - 2種類のデータの準備
-50万行のトランザクションデータ
-100万行のトランザクションデータ - 2種類のテーブルの準備
-外部テーブル
-内部テーブル - 3種類のウェアハウスの準備
- X-small
- Small
- Medium - 各テーブルごとの実行クエリ
-外部テーブル
-A-①全件取得(select)
SELECT * FROM "スキーマ"."外部テーブル";
-内部テーブル
-B-①テーブルクリア
truncate table "スキーマ"."内部テーブル";
-B-②データロード
COPY INTO "スキーマ"."内部テーブル"
FROM @S3_EXT_STAGE_POC FILE_FORMAT = (TYPE = 'CSV' FIELD_DELIMITER = '\t' skip_header = 1 )ON_ERROR = 'CONTINUE';
- B-③全件取得
SELECT * FROM "スキーマ"."内部テーブル";
検証結果
50万レコード
- 外部テーブル
| WHサイズ | AVG | MEDIAN |
|---|---|---|
| X-Small | 0:00:14 | 0:00:14 |
| Small | 0:00:15 | 0:00:15 |
| Medium | 0:00:15 | 0:00:15 |

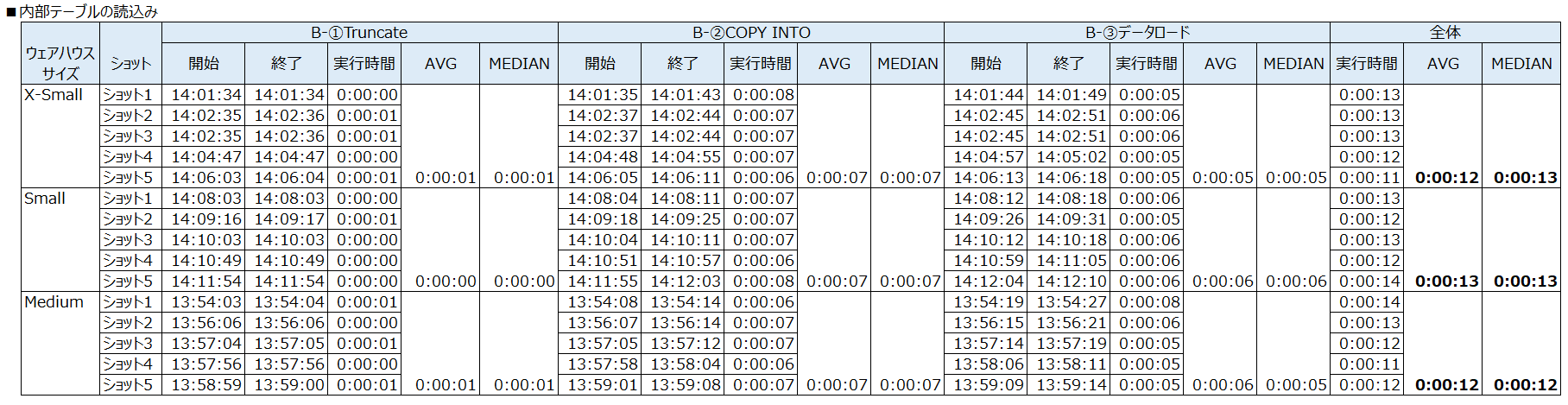
- 内部テーブル(B-①~B-③までの通し)
| WHサイズ | AVG | MEDIAN |
|---|---|---|
| X-Small | 0:00:12 | 0:00:13 |
| Small | 0:00:13 | 0:00:13 |
| Medium | 0:00:12 | 0:00:12 |
100万レコード
- 外部テーブル
| WHサイズ | AVG | MEDIAN |
|---|---|---|
| X-Small | 0:00:28 | 0:00:28 |
| Small | 0:00:28 | 0:00:28 |
| Medium | 0:00:30 | 0:00:30 |
- 内部テーブル(B-①~B-③までの通し)
| WHサイズ | AVG | MEDIAN |
|---|---|---|
| X-Small | 0:00:22 | 0:00:22 |
| Small | 0:00:22 | 0:00:22 |
| Medium | 0:00:23 | 0:00:23 |
検証結果まとめ
- 同じデータでも外部テーブルから読み込みより内部テーブルから読み込む方が速度は出る
- データボリュームが大きいほど、内部テーブルの優位性が高まる、差が大きくなる
- 本検証の範囲ではウェアハウスサイズによる違いは見られなかった(分散処理させるボリュームや同時実行時に発揮するものと思料)
- 本結果だけをみるとStagingレイヤーは内部テーブルを採用した方がよいが、運用面での差異やS3側のデータ形式(今回はcsvだがParquetはどうか)も考慮した検証を今後も継続する
最後に
私たちの取り組みに共感してくださる仲間を募集中です!
現在、多様な職種を募集しています。興味のある方はぜひお気軽にカジュアル面談でお話ししましょう。お待ちしています!
募集内容等詳細は、是非採用サイトをご確認ください。