事の発端
Vtuber沼に落ちてかれこれ2年くらい経つんですが、Vtuberという配信媒体、手法がますます市民権を得ていて、最近は民放テレビやそれこそNHKの番組等にも出演したりしています。
他にもグループが提供を出して、ネットラジオの番組を持っていたりとその活動は多岐にわたります。
今回はそんなネットラジオの話。(ここでは便宜上ネットラジオとしていますが、その実態は超A&Gです。)
4/2の夜中「寝れないなー」と思ってTwitterを眺めていたら、下のツイートを見かけました。
【ラジオO.A情報】
— ホロスターズ【公式】 (@holostarstv) April 2, 2021
本日4月2日(金)深夜26時30分~『#小野友樹 と #夕刻ロベル のへんならじお』が文化放送 超!A&G+でスタート!
【視聴方法】
スマホ:超!A&G+アプリをダウンロード!
PC:ページ右上「ON AIR」をクリック!
⬇️詳しくはこちら⬇️https://t.co/9xiJU3D5wV #へんらじ#ホロスターズ
もともと4月の番組再編成で日曜夕方5時代にホロライブPresentsのラジオがあることは知っていたのですがまさか金曜の夜中にまであるとは正直知りませんでした。んで、昔は(自分が小学5年のときかな...)土曜の夜1時くらいに3時までの1時間半のラジオとその後の30分のラジオを聞いて寝るということをしていましたが正直今それをやるのはきついです。それからたかだか6年くらいしか経っていませんが。
ので、民放のラジオなら面倒だけどネットラジオなら録音かんたんにできるのでは?と色々考えて調べてみたのが今回の始まりです。
車輪の再発明は必要なかった
そもそもの話、ネットラジオの自動録音というのはすでに有名なソフトがある界隈です。別に自分で作る必要なんてなかったわけなんですが今回この記事を書いているということはわざわざ作ったということです。
なぜそんなことしたかという理由ですが、以前書いた記事 「初心者がPythonで1からVTuber通知Botを作った話」から実際になにか自分で実用的なソフトウェアを制作するということをしていなくて、久々に自分でものを作っておこうと思ったのが理由です。
それに録音したいならAudacityとかを使って録音すればいいのですが録音ボタンを押すワンクリックの手間が意外とでかいんですよね。(実際Mスペ(星街すいせいのMUSIC SPACE)のときはそれで「ひぇ~~~~~」ってなってたので)
あと別の理由として最近競プロやりすぎてたなと思ったのもあります。
取得までの道のり
今回は超A&Gだけ取得できればそれでいいので、他のサイトに対応させる必要とかなくて楽です。
作らなきゃいけないのは
- 番組表取得
- 番組がそもそもその週に放送されるのかをチェックします
- スケジュール機能
- 録画の停止、開始の管理に使います。
- 録音機能
- ここがメイン。放送されているラジオを取得して録音します。
この3つです。前回と比べたら少ないのでわりとぱっぱとできました。
なんなら作ろう!って思い立ったのが金曜の夜中で、日曜の夕方には完成してました。めちゃくちゃRush Projectでした。
01.番組表の取得
A&Gの番組表は静的なので最初はスクレイピングをしようかなーと思っていたのですが、みたら吐き気がしました。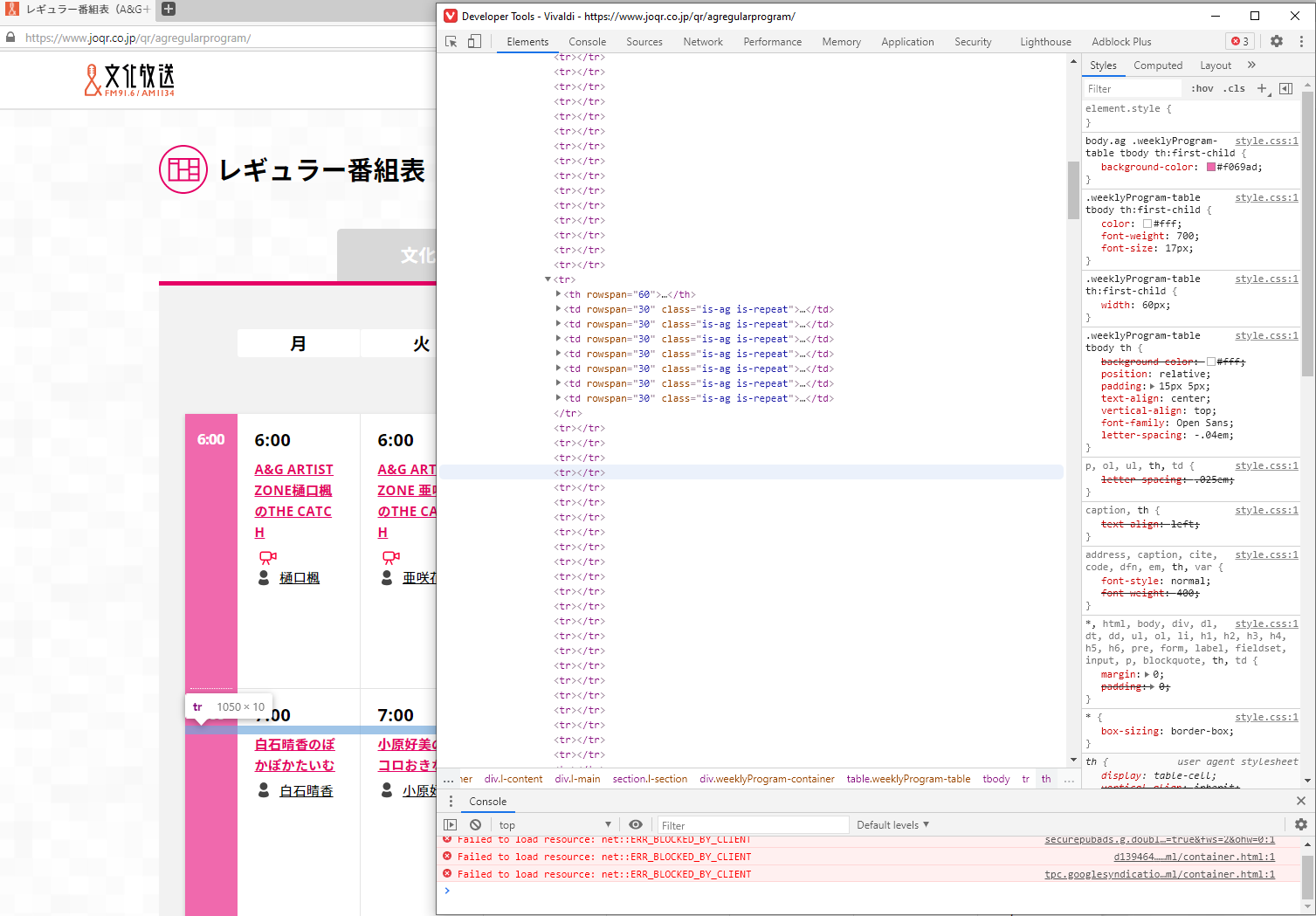
最近A&Gってサイトをflash配信終了に伴ってリニューアルしていて(遅くない?)番組表のHTMLも変わったのかなーと期待してみたらこれでした。
もちろん旧式サイトでもこうです。
どうして...
いろいろ調べていたら同じことを思った人が超A&Gの番組表を取得するapiを作っていました。(参考記事は最後にまとめて記載しています。)
ということで、ありがたく使わせていただくこととしました。
apiのサイトに「たくさんアクセスするのはやめてね」等のことが書いてありましたがまあ番組表なんて1週間に1回取得できればそれで十分です。
テレビの番組表ですらコンビニでかなり長期間分を一気に売ってるんですから大丈夫でしょう。
コードに関してはここでは一切してません。
02.録音機能
スケジュール機能が先では?と思われる方もいるかもしれませんが作ったのがこっちのほうが先なのです。
なのでこっちを先にやります。
まず超A&Gは16:9の180pの映像が配信されています。で、配信URLにアクセスするとサーバーの中のtsファイルを読み込んで再生するように公式の再生画面ではjsが組まれています。
その配信URLなのですが
https://fms2.uniqueradio.jp/agqr10/aandg1.m3u8
こんなURLになっていてあからさまにm3u8形式のファイルを読み込んでいることがわかります。
要は音楽プレイヤーの再生リストみたいな形式になっていて、ある一定時間経ったら次のtsファイルを読みに行くようになっているわけです。
録音の方法に関してはいろいろ調べたのですがffmpegを使うのが主流みたいです。
ので、ffmpegを使いました。
割といろいろなプログラムでffmpegが要求されることは多いのですがそこまで使っていなかったので今回始めてffmpegのパスを通しました。
これで、cmdからffmpegと打つだけでffmpeg.exeを呼び出せます。
基本的な方針としてはffmpegをサブプロセスで呼び出して録音するというのが今回やったことです。
import sys
import os
import subprocess
import random #Random is not needed, for test
URL = "https://fms2.uniqueradio.jp/agqr10/aandg1.m3u8"
def recode_hls(duration, file_name):
c = 'ffmpeg'
c += f' -i {URL}'
c += f' -t {duration} -movflags faststart -ar 48000 -c copy {file_name}.mp4'
code = subprocess.run(c.split())
ffmpegで超A&Gを録音するのに限ってはこの4行で十分です。
sysとosに関しては多分必要ないんですがテストのときに使ってたのでimportしたままにしています。
ここでやっていることは、ffmpegを呼び出すコマンドライン c を文字列合成で作り出して、それをサブプロセスに投げています。
超A&Gの配信URLって定期的に変わるらしいので今後の事も考えてURLという変数を宣言してそのなかに配信URLを入れています。
ffmpegには変換する秒数を指定する引数があって、それが**-tです。
他にもあるんですが-t**は開始からのn秒間処理をするという設定になるのでここにラジオ番組の長さを入れてやれば自動でラジオの長さ分だけ録音して、終わったら自動で終わるという処理ができます。基本的には30分ですがたまに1時間番組とかもあるのでdurationという引数を受け取って使うようにしています。
file_nameですが、これは出力先の指定と考えてもらえばいいです。
実際名前だけじゃなく絶対パスをメインのpythonファイルから渡しています。
上のコードを今回はモジュールとして読み込んで使っています。
03-1.スケジュール機能
01で取得した番組表はjsonになっていて、
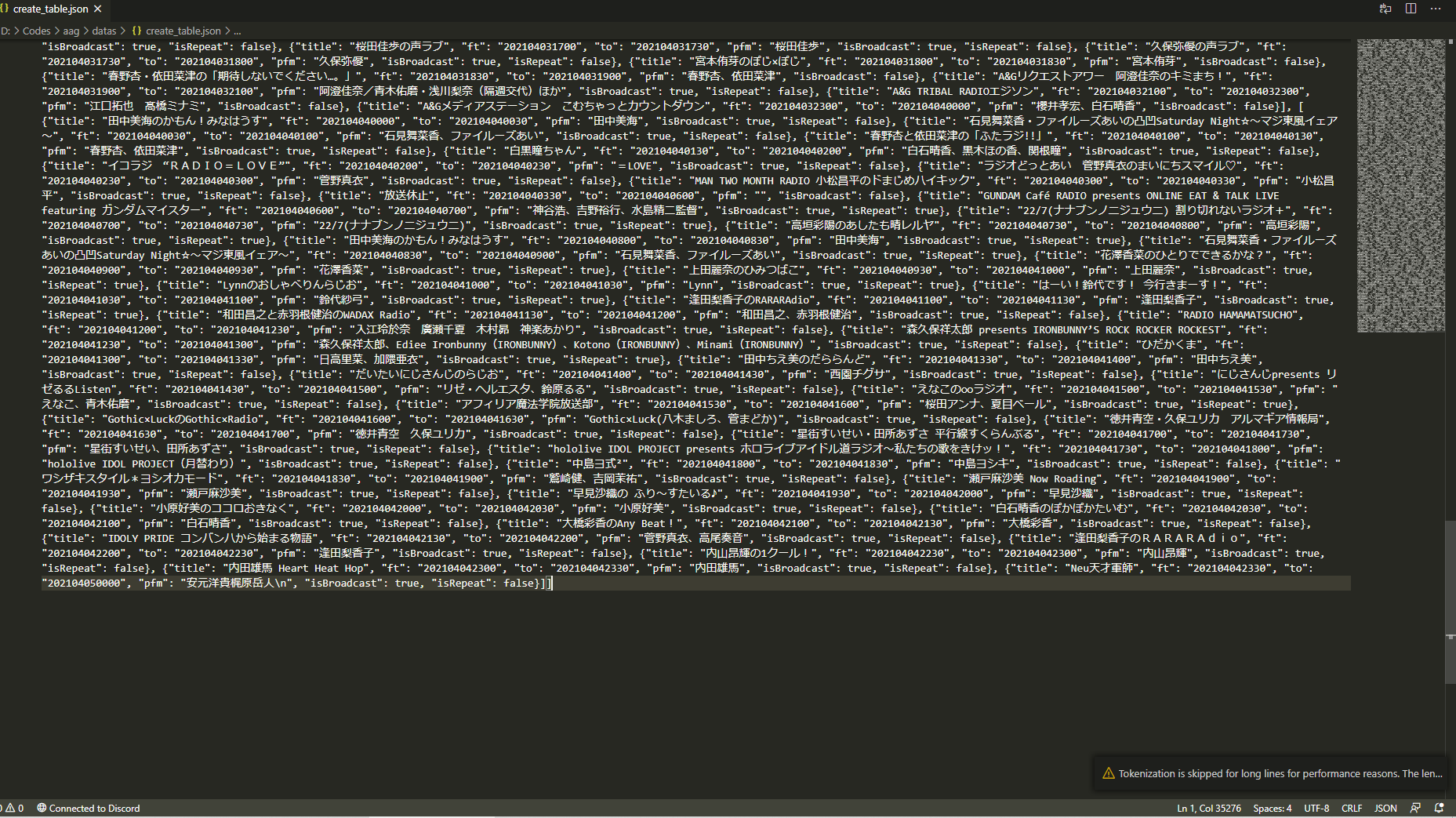
ここから指定した番組だけを取り出したいです。
前回からそうですが僕はjson好きなので今回もjsonを使って予約する番組を管理しています。

こんな感じ。dayの値が0スタートなのはapiから配信される番組表が月曜日を0として扱っているからです。
(eg. 月曜日の番組はすべての要素をまとめるリストの中で0番目のリストに入っています。A&Gでは深夜27時くらいまであるんですがapi側では24時になったら自動的に翌日のリストにまとめられるので1つ目の小野友樹と夕刻ロベルのへんならじおは金曜日の26時30開始にも関わらずday:5になっています。
一方で、星街すいせい・田所あずさ 平行線すくらんぶるとhololive IDOL PROJECT presents ホロライブアイドル道ラジオ~私たちの歌をきけッ!は日曜日の17時からと17:30からなので日曜日のday:6に格納されています。)
この2つのjsonを使って番組表から欲しいデータだけを抜き取ります
import json
reservelist = []
def make_reserves():
gettable()
ftt = json.load(open(f"{FILE_PATH}/datas/create_table.json", "r"))
f = json.load(open(f"{FILE_PATH}/datas/checklist.json", "r"))
cl = f["programs"]
print(cl)
for i in range(len(cl)):
day = int(cl[i]["day"])
for j in range(len(ftt[day])):
if cl[i]['title'] in ftt[day][j]['title']:
appends = ftt[day][j]
appends['flag'] = False
reservelist.append(appends)
グローバル変数(pythonってグローバル変数って言葉使いますか...?) reservelistを使って予約している番組を管理します。
こちらで用意したdayの値とapiが返したjsonの曜日はイコールなのでその曜日だけを探索することで探す量を減らしています。
これのいいところは単純に探索量を減らせるだけではなく、曜日指定なのでリピート放送を判定しなくていいということです。(一応apiのjsonにもisRepeatというリピート放送を判定するキーと要素が格納されていますが...)ただ、曜日変更が入ったときは自分で処理しなくてはだめなので番組の動向は追っておく必要があります。
そもそも録音とかしてる時点でその情報を見逃すとかいう想定はしてないんですけど。
さて、探索された曜日に該当する番組(用意したjsonのtitleと番組表に格納されているtitleが部分一致した番組)をreservelistにapiの情報そのままイコールでつないで格納しています。また、録音時に使うboolキー flag をfalseで格納しています。
部分一致なので人名とかを入れておけばそれでも録音できます。
03-2.スケジュールされた録音
import json
import requests
from timetable import createtable
import os
import datetime
import time
from HLSgetter import HLSGetter
MULTI_FOR_MINUTE = int(60)
MULTI_FOR_HOUR = int(3600)
MULTI_FOR_DAY = int(86400)
FILE_PATH = os.getcwd()
RECORD_THRESHOLD = 20
def loop():
make_reserves()
print(reservelist)
#202104041700
while(1):
for i in range(len(reservelist)):
starttime_str = str(reservelist[i]['ft'])
starttime_int = (int(starttime_str[6:8]) * MULTI_FOR_DAY) + (int(starttime_str[8:10]) * MULTI_FOR_HOUR)+ (int(starttime_str[10:12]) * MULTI_FOR_MINUTE)
finishtime_str = str(reservelist[i]['to'])
finishtime_int = (int(finishtime_str[6:8]) * MULTI_FOR_DAY) + (int(finishtime_str[8:10]) * MULTI_FOR_HOUR)+ (int(finishtime_str[10:12]) * MULTI_FOR_MINUTE)
duration = finishtime_int - starttime_int
t_now = datetime.datetime.now()
now_in_seconds = int(t_now.day * MULTI_FOR_DAY) + int(t_now.hour * MULTI_FOR_HOUR) + int(t_now.minute * MULTI_FOR_MINUTE)
print(f"now : {now_in_seconds}, abs = {t_now.day}/{t_now.hour}:{t_now.minute}") #Debug
title = f"{t_now.month}_{t_now.day}_{t_now.year}_{t_now.hour}-{t_now.minute}"
name = reservelist[i]['title']
if (starttime_int - now_in_seconds) < RECORD_THRESHOLD and (starttime_int - now_in_seconds) >= 0:
print(f"{name} is about to begin!")
if reservelist[i]['flag'] == False:
HLSGetter.recode_hls((duration + (starttime_int - (now_in_seconds + t_now.second))), f"{FILE_PATH}/Output/{title}_{t_now.month}-{t_now.day}-{t_now.year}")
reservelist[i]['flag'] = True
elif (starttime_int - now_in_seconds) < 0 and (-1 * (starttime_int - now_in_seconds)) < duration:
print("streaming radio found")
if reservelist[i]['flag'] == False:
HLSGetter.recode_hls((duration - (-1 * (starttime_int - now_in_seconds))), f"{FILE_PATH}/Output/{title}_{t_now.month}-{t_now.day}-{t_now.year}")
reservelist[i]['flag'] = True
elif (starttime_int - now_in_seconds) < 0 and (-1 * (starttime_int - now_in_seconds)) >= duration:
#print("paststream found")
if reservelist[i]['flag'] == True:
reservelist[i]['flag'] = False
print(f"Until {name} start : {starttime_int - (now_in_seconds + t_now.second)}")
print(f"{name}'s starttime in sec : {starttime_int}seconds") #Debug
print(f"{name}'s finishtime in sec : {finishtime_int}seconds") #Debug
print(f"{name}'s duration in sec : {duration}seconds\n") #Debug
time.sleep(20) #Wait a 20 sec for next check
if __name__ == "__main__":
#Use main function only for debug or start loops.
#Do NOT write any meaningful code here.
loop()
最近、高校生ものづくりコンテストなるものの練習でマイコンを扱っているのですがこれはそこで得た知見です。
while無限ループなんて1年ぶりくらいに使ったかもしれません。
if __name__ == "__main__":
をC言語のmain関数と同等に扱うみたいなあれがPython界隈にはあるっぽいのでそれに従っています。
一応仕組みに関しては海外のYoutubeの動画を見て理解しました。
番組表の取得はpythonファイル起動時の1回のみ行うようにしていますが、常時起動を考えるとなると再読み込みのイベントを作ったほうがいい気がします。
予約を増やしたいときは用意したjsonを書き換えることになりますがその再読み込みのために再起動することにもなるので。
今回はとりあえず1日半で完成させるという目標があったために自分が良ければそれでいい。で開発しているのでやっぱりちょっと粗いです。
さて、while文は20秒ごとに実行されています。
for文でreservelistに登録されている番組の開始時刻と終了時刻を使って録音の判定をしています。
あと、管理が楽なのでjson及びリストに登録されている時刻は 「YYMMDDhhmm」という形式ですが、DD以下をすべて秒数に変換してプログラム内では計算しています。
超A&Gではだいたい番組が30分なのでラジオの長さを秒数に変換したところで 3600/2。要は1800程度にしかなりません。
途中でtitleという変数があってそこで日付とかいろいろいじってますがこれはffmpegに投げる用の名前です。
なんでラジオの名前じゃないのかというと日本語投げるとエラー吐かれたからです。
別に時間がわかればなんのラジオかはぱっとわかるので問題ないかなーということでこれにしてますがなにか方法があればラジオのタイトルを使えるようにしたいですね。(個人的にはタイトルに利用不可の文字やスペースが入ってるからでは?と思っていますが)
if文だらけの場所では録音の是非を判定してもらっています。
現在時刻を日付から分まですべて秒に変換して、先程変換したラジオの開始時刻と比較します。
開始20秒前(RECORD_THRESHOLDという変数がそれを管理しています。)かつ開始時刻前だった場合は
ラジオの長さ(秒) + (開始時刻 - 現在時刻)
をffmpegに投げて録音しています。このif文で30分の番組を録音しようとした場合長さの最大値は1820秒。最小値は1800秒になります。
またif文の中で更にif文がありますがそこで、先程追加したflagを判定しています。すでに録音が開始したものはflagがtrueになって多重で録音されることを防いでいます。
一方、もうラジオが始まっている!というときには途中から録音を開始してくれます。
ここでは 開始時刻と現在時刻の差が負(マイナス)かつ、番組終了時間よりも差の絶対値が小さい(まだ番組が終わっていない) ときに録音を開始するようにしています。
このとき、番組の長さをffmpegに投げると次の番組まで録音されるので
ラジオの長さ(秒) - 経過時間
を投げて録音しています。ここでの録音時間の長さの最大値は30分番組の場合は1799秒、最小値は1秒です。
また、番組終わったよ?ってときはなにもしていません。正常に録音されていた場合はflagがtrueになっているのでfalseに戻しています。
4(追記). - 通知機能
Discordへの通知機能をつけました。
通知機能つけた pic.twitter.com/vQII9e8DMY
— Yourein (@Yourein1) April 11, 2021
以前作った通知BOTと同じチャンネルにWebhookを作ってWebhookを録音開始と終了後に投げています。
以前のBOTのようにたくさんのデータを投げるならしっかりDeveloper PortalからBOTを作ってトークンを作って...みたいなことをしたほうがいですが、今回くらいのあれならただただURLに投げるだけで十分です。
import requests
import json
WHURL = "blah blah blah" #CEO of Rabbit hole
def dcwebhook(streamurl, programname, mode):
if mode == 1:
maincontent = {
"username": f"CEO of rabbit hole",
"embeds":[{
"title": f"{programname}",
"url": f"{streamurl}",
"description": f"{programname} is recorded"
}]
}
else:
maincontent = {
"username": f"CEO of rabbit hole",
"embeds":[{
"title": f"{programname}",
"url": f"{streamurl}",
"description": f"{programname} is now recording!"
}]
}
print(json.dumps(maincontent))
requests.post(WHURL, json.dumps(maincontent), headers={"Content-Type":"application/json"})
json作ってPOSTでapplication/jsonを指定して投げています。
これだけ。
あと、main.pyのファイルに変更があります。
if (starttime_int - now_in_seconds) < RECORD_THRESHOLD and (starttime_int - now_in_seconds) >= 0:
print(f"{name} is about to begin!")
if reservelist[i]['flag'] == False:
dcnotf.dcwebhook(URL, name, 0)
HLSGetter.recode_hls((duration + (starttime_int - (now_in_seconds + t_now.second))), f"{FILE_PATH}/Output/{title}_{t_now.month}-{t_now.day}-{t_now.year}")
reservelist[i]['flag'] = True
elif (starttime_int - now_in_seconds) < 0 and (-1 * (starttime_int - now_in_seconds)) < duration:
print("streaming radio found")
if reservelist[i]['flag'] == False:
dcnotf.dcwebhook(URL, name, 0)
HLSGetter.recode_hls((duration - (-1 * (starttime_int - now_in_seconds))), f"{FILE_PATH}/Output/{title}_{t_now.month}-{t_now.day}-{t_now.year}")
reservelist[i]['flag'] = True
elif (starttime_int - now_in_seconds) < 0 and (-1 * (starttime_int - now_in_seconds)) >= duration:
#print("paststream found")
if reservelist[i]['flag'] == True:
dcnotf.dcwebhook(URL, name, 1)
reservelist[i]['flag'] = False
スケジューリングのif文に通知のモジュールに投げる部分を作りました。
-1.番組表の定期取得
しないことにしました。
今の所、金土日だけ動いてればいいので月曜日はソフト落としてます。
して金曜の夜に起動してます。
なので問題ないです。
デプロイ環境ですが、最初はサーバーを想定していましたが結局は自分のメインPCで使ったほうがよさそうなのでそちらで運用していくことにします。
フォルダ構造
root/
┝ datas
│ ┝ create_table.json
│ └ checklist.json
┝ HLSgetter
│ └ HLSGetter.py
┝ Output
│ └ Outputされたmp4達
┝ timetable
│ └ createtable.py
└ main.py
初めて個人開発でファイルを分けて作ってみましたが想像以上に関数の単体テストが楽でした。(前回のDiscordBOT開発では関数が複雑に絡まりすぎて単体テストがほぼほぼ不可能なレベルだった) というわけで、今後はpython以外でも積極的にファイルを分けて開発していこうと思います。
実際に動かしてみる
お試しで自動録音ソフト放置したままお菓子食べに行こうと思います。
— Yourein (@Yourein1) April 4, 2021
これで成功してたらもうこれ起動したままで行く pic.twitter.com/u8Ao2rQMk1
まだお試し段階のときのツイートなので完成品じゃないですがこんな感じで動きます。
アウトプットファイルはこんな感じ

ちゃんと録音できてます。(録音じゃなくね?録画じゃね?と言われたらたしかにそうです。一応コーデックを用意してffmpegの出力設定をmp3にしてしまえばmp3にもできます。今回は超A&Gの配信画質とビットレートからして別にいいやってことでmp4にしました。)
やっぱり開発は楽しい(あとがき)
作業時間1日以下で完成させた割にはちゃんとうごいてくれたなーというのが感想です。
ここまでRush Projectなのも久々ですがそれができる技術が身についているのかもしれないという少しの自信には繋がりました。
今後に関してですが、以前開発したDiscordBOTが動いているPCに追加でデプロイして常時起動の形式を取ろうかなと思います。
とするとエラーの発生などを通知できるようにしたいわけですが、それこそDiscordにWebhookで投げるとかそういう感じにしようかなと思います。
やっぱりライブラリや外部api, ソフトなどは使っていますが自分で0から(今回は1から?)システムを組み上げるのは楽しいです。
また機会があればなにかやりたいですね。
あと一応これでもC++メインなのでいい加減python以外の記事をQiitaで書きたいです。
参考記事等
以下が今回の参考記事になります。
各記事の筆者様。大変参考にさせていただきました。ありがとうございました。
- Python3でradikoと超A&Gと音泉と響を自動検索・録音するソフトを作った
- 超A&G+の番組表をapi化する(配信編)
- 上の記事のapi
- Python 3でのファイルのimportのしかたまとめ
- Subprocess management
- subprocess – プロセスを生成して連携する
- Pythonで文字列を比較
- FFmpegでM3U8ビデオをダウンロードする方法(HLSビデオ) (これ多分機械翻訳なんで日本語怪しいんですが正直コードさえ読めれば日本語とかどうでもいいので参考にしました。)