この記事を読んでいただいている方の殆どはおそらくウマ娘のゲームをやった事があると思うのでわかるとは思いますが、ウマ娘の育成には「スキル」という概念が存在します。

主な目的は育成中のレースでの勝率を上げるためなのですが、いろいろ別の目的にスキルが使われることがあって「対人用」と言われる別プレイヤーとのレースのためのスキル構成や「評価用」と呼ばれる育成終了後の評価点のためにコスパのいいスキル構成をすることもあります。

ところで、「評価用」というスキルのとり方があるということはスキルにはそれぞれ評価点が割り当てられていることになります。
また、記事一番上の画像からわかるようにスキルを取るには「スキルポイント」というものが必要で、これは育成中に手に入れることができるポイントで手に入れたポイントの分だけたくさんスキルが取れたり、良いスキルが取れたりします。
ここでもう一度「評価用」のスキルのとり方を考えてみることにします。
- できるだけコスパのいい(安いかつ評価点が高い)ものを選びたい
- 使える評価点は限られている
- それぞれのスキルに取得にかかるコストとその評価点が割り振られている
- 以上の条件下でスキル取得による評価点を最大化する
これってとてもナップサック問題に似ていると思いませんか?
ナップサック問題とは?
すごく失礼なのですが個人的にナップサック問題のことを別名称として「泥棒問題」と読んでいます。
もとの問題は
- ある一定までの重さが入るナップサック(リュックサック)がある
- そのナップザックの中に「重さ」と「価値」が決まった商品を詰めていく
- 一定の重さを超えないかつ価値を最大化できるように商品を選んでナップサックに詰める
このとき獲得可能な価値の最大値はいくらかという問題です。
なんかやっていることが泥棒っぽいので「泥棒問題」と個人的に呼んでいます。
このナップサック問題は部分和問題といわれる問題に属していて、CSや競プロの知識がある人ならわかると思いますが、NP困難(高速に計算することが難しい(正確には有効な多項式時間アルゴリズムがないとされている))問題の一つでもあります。
ナップサック問題に対するアプローチ
「多項式時間で解決できない?こんなの価値が高いものから選んだらいいんじゃないの?」と思う方がいると思います。
そう思った人は以下の問題を解いてみてください。
AtCoder Beginner Contest 204 - D - Cooking
この問題も一見して時間が短いものからオーブンA, Bにそれぞれ割り当てていったほうが最適な気がします。というか上の問題(Cooking)の入力例はまさにそのタイプです。
しかし、反例はいくらでもあります。上の問題に対する反例ではなく実際のナップザック問題に対する貪欲法の反例を以下に示します。
商品 : 5
重さ制限 : 10
商品(重さ, 価値) : (7, 7), (3, 3), (2, 4), (3, 4), (2, 3)
これに対して価値が高い順にナップサックに詰めてみると、
(7, 7), (2, 4)
のグループか
(7, 7), (3, 4)
のペアが選ばれることになります。
しかし、これはこの問題の最適解ではありません。この問題の最適解は
(3, 3), (2, 4), (3, 4), (2, 3)
の一見すると選ぶ価値がなさそうなグループをまとめて選ぶことです。
ちょっとこの例では価値と重さの設定があからさますぎるのでパット見で最適解を選べる人もいるかも知れないのですが、世の中にはもっとギリギリで「こっちのグループを選んでおけばよかった...」となるような組み合わせも存在するわけです。
アプローチ1 : 組み合わせ全部試す
はい。そのままです。
実際にあり得る組み合わせをすべて試してみます。試してみて、重さが制限を超えないかつ価値が最大のペアの価値の総和を答えとします。
それぞれの品物に対して「選ぶ」、「選ばない」の通りを試すわけなのでプログラムは$2^n$($n$は商品の個数)通りの組み合わせを試します。要は$O$記法で表すと$O(2^n)$ということです。
これはある程度までなら現実的な計算時間でうまくいきます。(具体的には$n \leq 20$くらい)
Bit全探索という探索アルゴリズムを使うことで$2^n$をそのまま実装できますし、再帰関数を用いて深さ優先探索のようなことをしても良いです。
アプローチ2 : 動的計画法
Wikipediaでナップサック問題について調べていただくとわかりますが、
解法として、動的計画法を用いた擬多項式時間アルゴリズムや FPTAS の存在が知られており、実用的にはほぼ最適な解が得られる。
このような記載があります。
ここでは、この動的計画法(Dynamic Programming)を用いた解法を考えてみることにします。
というのも、もともとの話に立ち返ってみると「ウマ娘のスキルどうやって選ぼう?」だったわけで、スキルの選択肢は20を超えることが普通にあるからです。(キャラクターに適正がないスキルも含めたらの話ですが)
これについて詳しい話は下の記事を参照してください。ここでは軽く解説します(というかそこまで詳しく解説できませんAtCoder灰色で人権がない人なので...)
典型的な DP (動的計画法) のパターンを整理 Part 1 ~ ナップサック DP 編 ~
例えば最初のナップサック問題に立ち返ると、
重さの制限
商品の個数
それぞれの重さと価値
という4つの情報がありました。
それぞれを以下のように一般化してみます。
W = 重さの制限 \\
N = 商品の個数 \\
A_i = i(1 \le i \le N)番目の商品の重さ \\
B_i = i(1 \le i \le N)番目の商品の価値 \\
これに基づいて考えてみます。
めちゃくちゃ簡単に動的計画法を説明すると、ある条件に従って埋められるある表(DPテーブル)があって、その表をDP遷移式(漸化式のようなもの)というルールに従って埋めていくアルゴリズムのことを言います。
このナップザック問題に対しては二次元の配列をDPテーブルとして使います。
DP[i][w] = i(0 \le i \le N)個目までの商品を重さがwを超えないように選んだときの価値の最大値
として配列を定義することで実装することができます。
このときのDP遷移式は以下のようになります
DP[i+1][w] =
\begin{cases}
max(DP[i+1][w], \ \ DP[i][w - B_i] + A_i) & (w - B_i \ge 0)\\
max(DP[i+1][w], \ \ DP[i][w]) & (w - B_i < 0)
\end{cases}
また、0個の品物を選ぶときは問答無用で価値0なのでDPテーブルを以下の遷移式で初期化します
DP[0][w] = 0 \quad (0 \le w \le W)
これでDPの準備が整いました。
もとの問題を落とし込もう
ここまで読んでくれた方ならなんとなく察している方もいるかも知れませんがもともとの問題はナップサック問題と非常に似ています。
先程は
W = 重さ制限 \\
N = 商品の個数 \\
A_i = 商品の重さ \\
B_i = 商品の価値 \\
として扱っていましたがこれを
W = 使えるスキルポイント \\
N = 選べるスキルの個数 \\
A_i = 必要ポイント \\
B_i = スキルの評価点 \\
と置き換えてみるとナップサック問題に非常に似ていることがよく分かると思います。
というか、ナップサック問題に対する動的計画法のコードをそのまま流用することすら可能です。
どうしてこんなことを...?
余談ですが、おそらくやってる人はいるんじゃないのかなと思って色々調べてみたんですが特に検索結果にヒットすることもなかったので作ってみることにしました。
スキル評価点計算機のようなものはあったのですが取るべきスキルをリコメンドしてくれるわけではなく自分でスキルを選んで「どれくらいの評価点が取れるのかなー」というのを確認するだけでした。
正直スキルの取得で悩んでいるのに自分で取るスキルの組み合わせを一部固定してその残りをすべて試すみたいなことはしたくないです。
それなら自動で選んでくれたほうが楽だろうなーと思って作りました。
あと、単純にDPを学びたかったというのもあります。(AtCoderで解法が見えてもDPの実装ができずに敗北したので)
実装してみる
スキルの評価点をソースコードの中に埋め込むわけには行かないので事前にjsonとして用意しておくことにします。
{
"Skill": [
{
"name": "Pride of KING",
"score": 180
},
{
"name": "カッティング×DRIVE!",
"score": 180
},
{
"name": "シューティングスター",
"score": 180
}
]
}
このjsonを読み込んで処理をしていきます。
獲得可能なスキルを取得する
完全に個人用のプロジェクトなのでGUIを実装するわけではなくCUIで実装してしまうことにします。
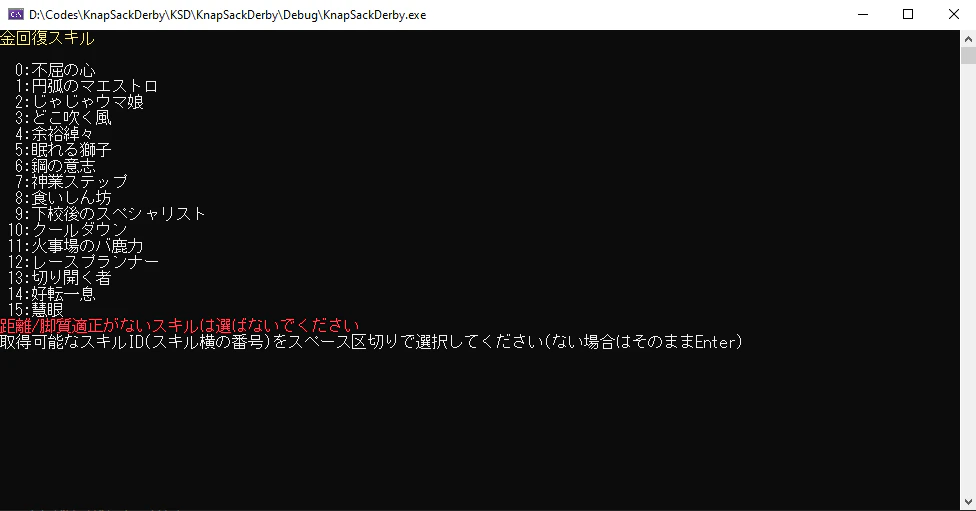
こんな感じ
using json = nlohmann::json
void input_avail(){
json jdata;
std::fstream* iifs = new std::fstream;
iifs->open("../Library/ccharacter.json");
if (iifs->is_open()) {
jdata = json::parse(*iifs);
Yconsole::ConsoleWrite(Console, "固有スキル\n", CON_LYELLOW);
for (auto& x : jdata["Skill"].items()) {
std::cout << Yourein::strs::strformat(x.key(), ' ', 3, true);
std::cout << ":" << Yourein::strs::strformat(x.value()["name"], ' ', 60) << std::endl;
}
Ginput_warning();
availgetter(jdata);
}
}
正直Qiitaに乗せてはいけないレベルでクソコードなので一部分だけを載せます。
本当のコードはこれがあと6,7回くらい(すべてのスキルジャンルをカバーするために)くり返されています。
Yconsole::ConsoleWrite()
Yourein::strs::strformat()
などの関数は完全に自前のやつです。基本的にこの記事でstd名前空間以外の場所にある関数はjson以外すべて自分が作ったライブラリだったりです。
ここまではスキルの一覧表示のような処理で実際に入力を受け取るところは別関数になっています。
void availgetter(json& jdata) {
std::string in;
std::vector<std::string> formatedinput;
std::getline(std::cin, in);
formatedinput = Yourein::strs::pinput(in, ' ');
std::sort(formatedinput.begin(), formatedinput.end());
formatedinput.erase(std::unique(formatedinput.begin(), formatedinput.end()), formatedinput.end());
for (int i = 0; i < formatedinput.size(); i++) {
int ind = stoi(formatedinput[i]);
avail.push_back(jdata["Skill"][ind]["name"]);
skillscore.push_back(jdata["Skill"][ind]["score"]);
}
}
スペース区切りで入力を要求していますが、getlineで一つのstd::string型として取ってきていて、そのstring型を自作の関数で適当にパースしてstring型のvectorに格納しています。例えば
1 2 3 4 5
という入力をすると自動で
{1, 2, 3, 4, 5}
というstd::vector<std::string>にパースしてリターンしてくれるようにしています。
後にsortとerase処理を入れていますが、これは同じスキルを間違って複数入力してしまったとき用にstd::unique関数を用いて重複した入力を消しています。
sortを入れる必要性ですが、入れないと隣り合った重複しか消してくれません。
{0, 0, 1, 2, 1}
この入力が例えばされたとして、sortがされていない場合は0の重複は消えますが1の重複は解消されません(隣接要素でないので)。
一方、sortされた状態であれば0と1の重複両方が解消されます。
詳しくはC++のリファレンスを見てください。
こんな感じで取得可能なスキルを受け取ったら次に必要なコストと優先度の入力が求められます。
コストの入力と優先度付け
もともと入力のときにキャラクターに適正のないスキルは選ばないように要求しているのですが適正があっても「これはいらないなぁ...」というスキルがあると思います。「鋼の意志」とか。
その反対にコストは高いし評価も他と比べたら見劣るかもしれないけど欲しいスキルがあると思います。
例えば「登山家」などのスキルは少し前に「意外と強いんじゃね?ほぼ必ず(全レースで)発動するし」みたいなことがありました。(今はどうなのか知りませんが)
なので、コストの入力と同時にそのスキルの優先度の入力を求めるようにしています。
優先度をどのようにして計算するかですが、もとのスキルの評価点に50点上乗せします
「えぇ...」となるかもしれないですが、これでうまく行きます。
しかも、もとの評価点に足すだけなのでめちゃくちゃ処理が楽です。足した分はメモしておいてすべて選び終わったあとに評価点の総和から引けばいいだけなので
一方優先度が低いスキルの方ですがそっちは逆に50点引きます。
このとき、こっちはメモしません。なぜなら点数を引いたものはほとんど選ばれないからです。これは金スキルなどの評価点がもともと高いスキルでも同様です。
void cost_getter() {
int len = avail.size();
cost.assign(avail.size(), 0);
for (int i = 0; i < len; i++) {
Yconsole::CLEAR();
std::cout << avail[i] << "の必要コストを入力してください : ";
std::string costtemp;
std::cin >> costtemp;
bool only_digit = true;
for (auto d : costtemp) {
if (d > '9' || d < '0') only_digit = false;
}
if (!only_digit) {
Yconsole::ConsoleWrite(Console, "数字のみを入力してください!", CON_LRED);
system("PAUSE");
i--;
}
else {
cost[i] = stoi(costtemp);
}
int priority;
std::cout << avail[i] << "の優先度はどの程度ですか? [1:欲しい, 2(1,3以外):普通, 3:そこまで] : ";
std::cin >> priority;
if (priority == 1) {
editedsum += 50;
skillscore[i] += 50;
}
else if (priority == 3) {
skillscore[i] -= 50;
}
}
Yconsole::CLEAR();
}
なぜこれが上手くいくのかという話ですが、DP遷移式に立ち返ってみると直感でわかると思います。
いま動的計画法を用いて解いている問題は「全体的に見て今コスパが一番いいものを選ぶ問題」だからです。(この動作がまさに動的計画法という名前の通りな気がしますが...)
もともとの「スキル取得にかかるコストが高いけど選ぶ価値はある...」という状態から「スキル取得にかかるコストが高いくせにそこまで評価が高くない」という状態になったら、価値の総和を最大化する問題では選択肢から省かれるということは自明だと思います。
通常スキルでも50点足してあげることで普通の通常スキルから頭一つ抜けた「高コスパスキル」になるわけなので選ばれやすくなる。ということです。
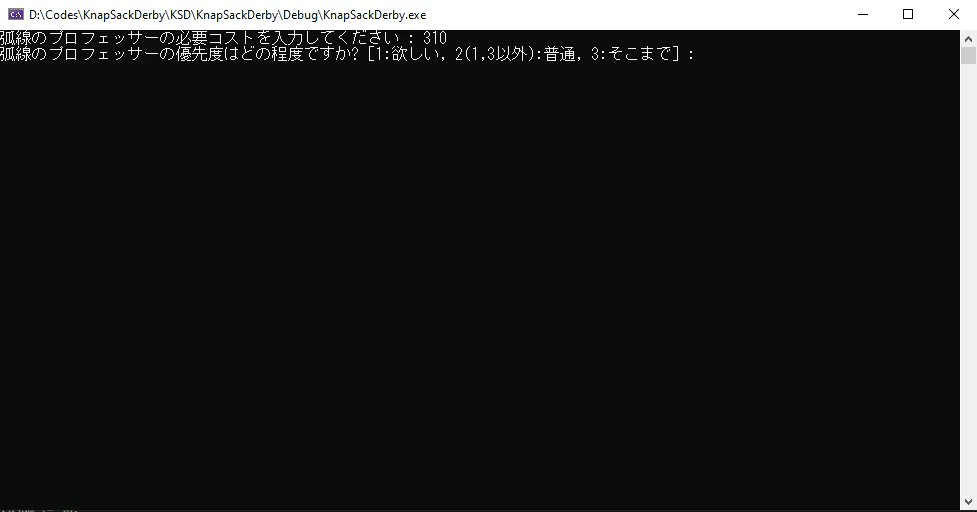
計算部分
void solve() {
int N = avail.size();
int Skillpoint = 0;
std::cout << "現在使用可能なスキルポイントを入力してください : ";
std::cin >> Skillpoint;
std::vector<std::vector<long long>> dp(avail.size() + 1, std::vector<long long>(Skillpoint + 1, 0));
std::vector<std::vector<std::vector<std::string>>> skills(N + 1, std::vector<std::vector<std::string>>(Skillpoint + 1));
for (int i = 0; i < N; i++) {
for (int w = 0; w <= Skillpoint; w++) {
if (w - cost[i] >= 0) {
dp[i + 1][w] = std::max(dp[i + 1][w], dp[i][w - cost[i]] + skillscore[i]);
if (dp[i + 1][w] == dp[i][w - cost[i]] + skillscore[i]) {
skills[i + 1][w] = skills[i][w - cost[i]];
skills[i + 1][w].push_back(avail[i]);
}
}
dp[i + 1][w] = std::max(dp[i + 1][w], dp[i][w]);
if (dp[i + 1][w] == dp[i][w]) {
skills[i + 1][w] = skills[i][w];
}
}
}
for (auto x : skills[N][Skillpoint]) {
std::cout << x << " ";
}
std::cout << std::endl;
std::cout << "上のスキル獲得で " << dp[N][Skillpoint] - editedsum << " 程度の評価点が獲得可能です。\n(実際の評価点から±50くらいすることがあります。)" << std::endl;
}
競技プログラマなら幾度となく書いたことのあるコードかもしれません。
あからさまにDPをしています。
普通のDPならDPテーブルは一つで良いのですが、今回は**スキルをレコメンドする。**という目的があるので、テーブルのどの時点でどのスキルを選択しているのかを記録しておく必要があるので二次元vectorのdpテーブルの他に三次元vectorのskillsというテーブルを作成しています。
なんで三次元なの?という話ですが、dpテーブルの対象のところにstringを複数入れていくために三次元vectorになっています。
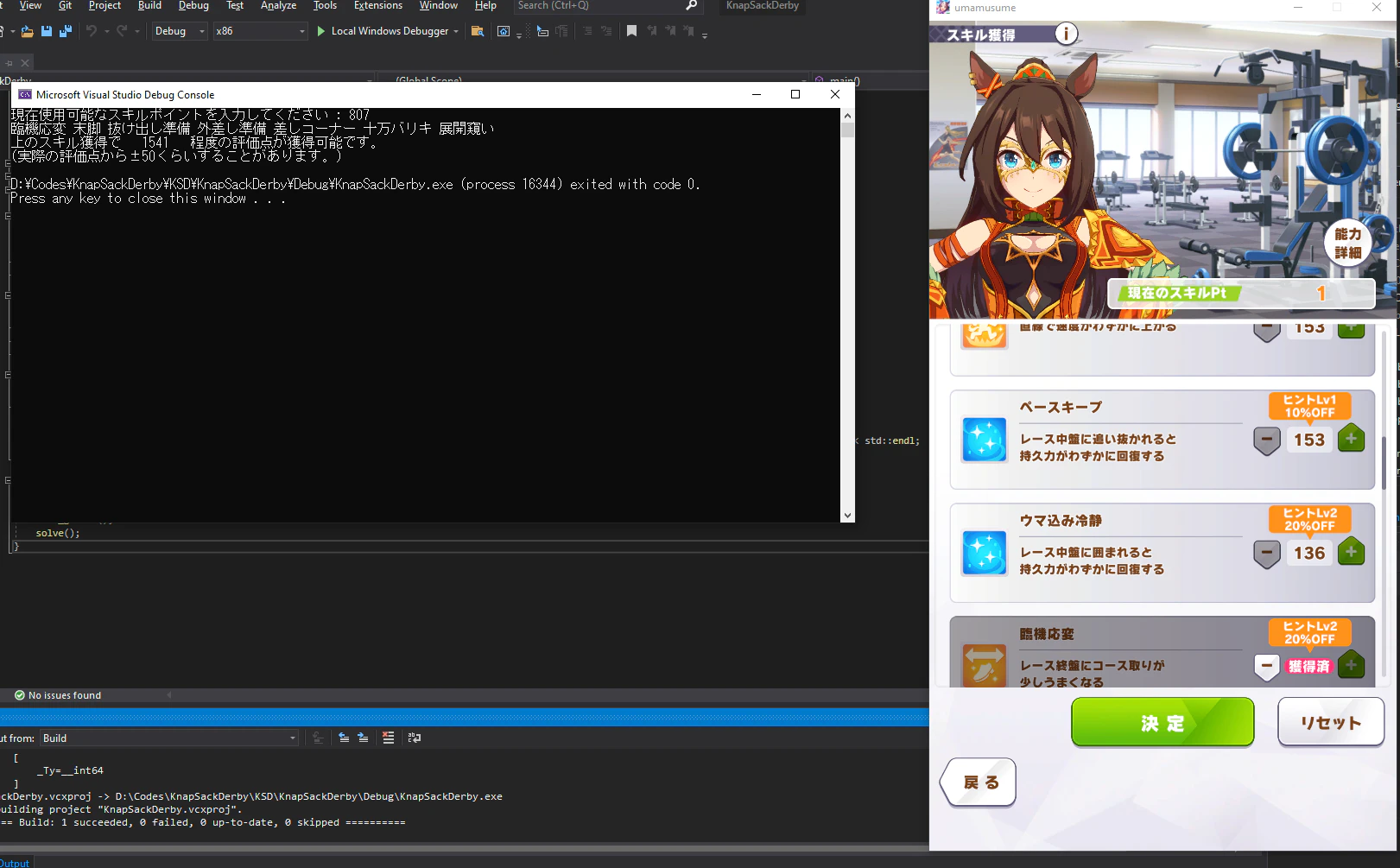
最終的に上のような感じでスキルを表示してくれます。
詳しくは...
今まで部分的にコードを切り取ってきましたが、コード全体はGitHubの方にアップロードしています。
もし詳しくは知りたい方はGitHubの方を見てみてください。
作ってみて思ったこと
面白いのが、意外と人間が思う通りに選ぶだけでプログラム側の最適解と似たものが出てくることがわかりました。(もしかしたら実装をミスっているだけかもしれない...)
ただ、自分が適当に考えて選んだスキル構成ではスキルポイントを50以上(60くらいの緑スキルがちょうど取れないくらい)残して育成を終了してしまうことがありましたが、このソフトだとほんとにギリギリまで使い切ってくれるので10回くらい試してみてスキルポイントが50ないし20以上余ることがないのでこのソフトの目標は十分に達成していると思います。(もともと余ったスキルポイントもったいないなーというところから始まっているので)
しかしまあ、ただウマ娘を普通にやっていて育成終わりになんとなく思いついたことを実装してみたら結構いい結果が得られたので良かったです。
こういう一見すると難しそうな問題に対して実際にアプローチを仕掛けられるところがアルゴリズムを学ぶおもしろさだと思っているので学びを活かせて良かったなぁと思いました。(AtCoderでは負けましたが。)
現段階でもう十分なレベルなのですがGitHubにはまだBetaリリースとしてコードを乗っけているので今後暇があればスキル優先度だったり、ファイルの読み込み部分などをもうちょっと真面目に考えてみて実装していこうと思っています。
ところで石貯めてるけどいつ出せばいい?ハーフアニバ?