注意
NoSQL初心者が自分の理解で書いているので間違ってるとこあったら教えてください。主にApache Cassandraの商用パッケージDatastax Enterpriseという前提で進め、オープンソースのものと異なる場合があります。
当記事のテーマはアーキテクチャーガイドを参考して分散DBであるCassandraではCRUDはどう動くのか解説していきます。
もしよろしければTwitterもフォローしていただけると。。。
My Twitter Account
INSERT
CassandraのINSERTを理解するためにはまずどのようにしてデータが書き込まれるのかというアーキテクチャーから確認していきます。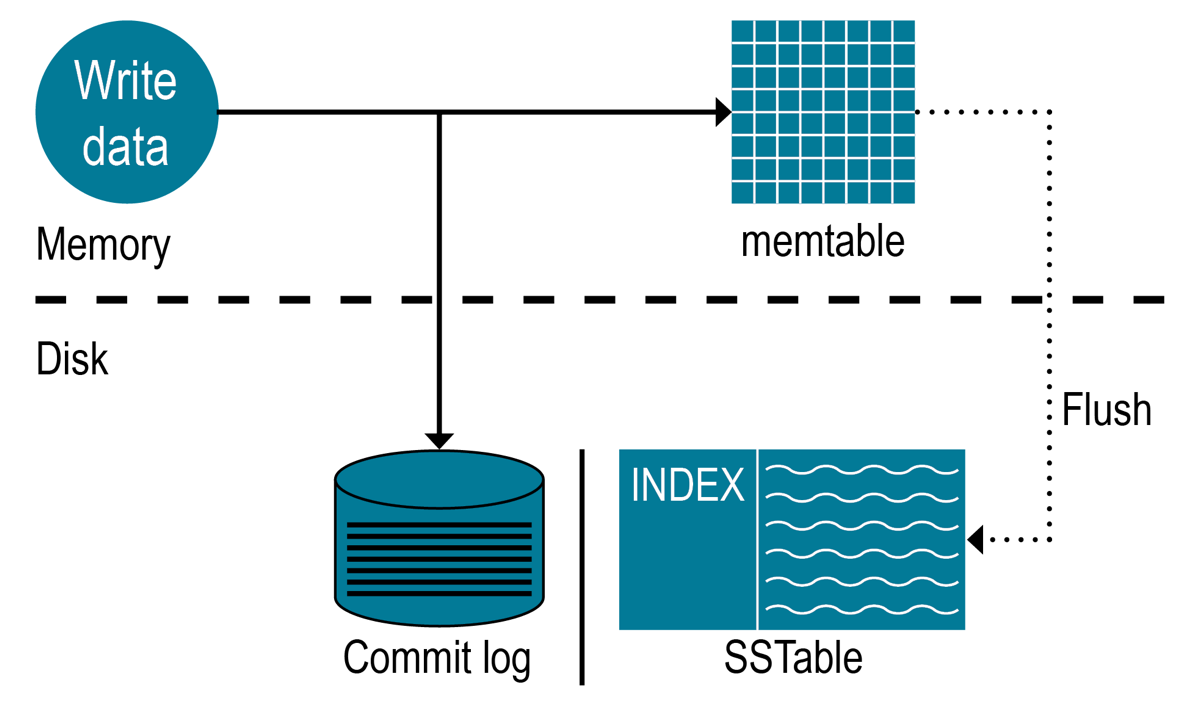 この画像を用いて説明します。
この画像を用いて説明します。1.コミットログへデータを書き込む
2.memtableへデータを書き込む
3.memtableをフラッシュして永続化する
4.ディスク上のSSTableへデータを格納する。
順を追って説明します。
まずノードにデータが入ってきてからはcommit_logへとデータが渡されます。
このコミットログに書き込むことによってmemtableがSSTableに書き込まれるまで保持される。起動時にリカバリも行われる
つまり、この時点で障害が起きてもリカバリ可能となります。
次にmemtableへ書き込み一定量を超えるとフラッシュされます。
memtableそもそもデータをパーティションキーやクラスタリングカラムでソートされた状態で保持されます。
nodetool flushコマンドやnodetool drainコマンドを利用することで主導でフラッシュできるのでノード再起動前に実施します。
そして各テーブル1つづつ持っているSStableへ保管されます。
これにてデータは不変のものとなりINSERTの流れとしては以上になります。
上記のコミットログの削除ですが、いくつか注意点があります。
commit logはcommitlog_segment_size_in_mbという閾値を超えると新しいセグメントが作成されます。
そして、セグメント内のデータすべてがフラッシュされた後にパージされます。
commit logの最大サイズを示すcommitlog_total_space_in_mbに到達すると最も古いセグメントがパージされ対象テーブルはフラッシュされてしまいます。
SELECT
READするときの順番はアーキテクチャーをもとに確認すると以下画像の通りです。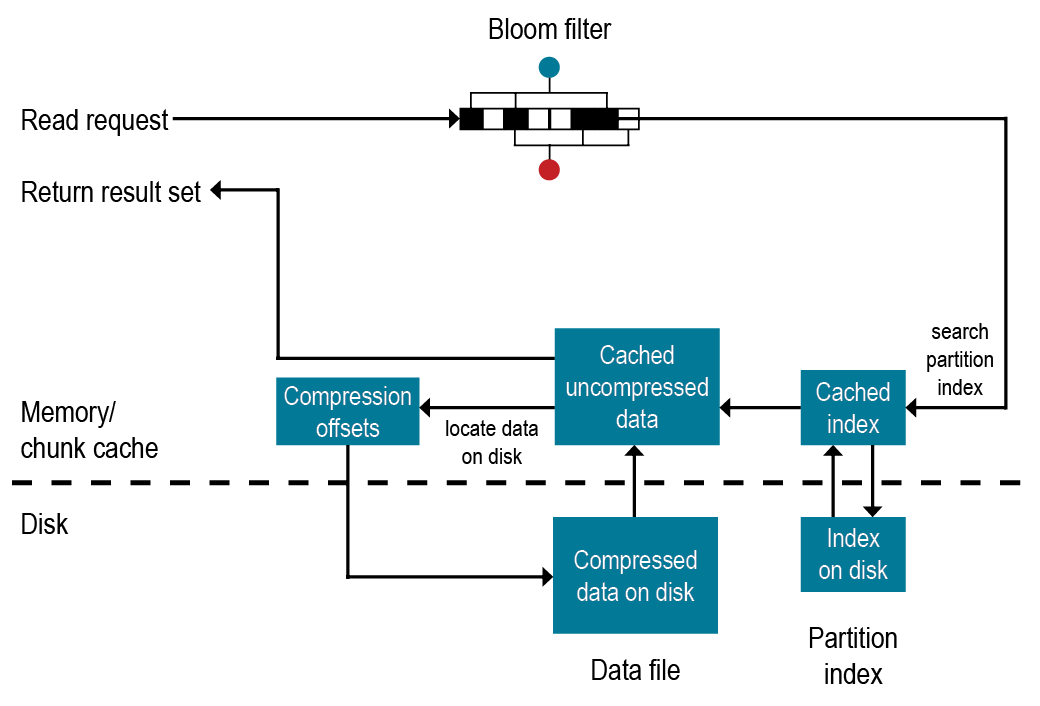
結構複雑なのでざっくりして説明します。
基本Cassandraのデータの読み込みには3種類の方法があります。
1.memtableから引っ張ってくる方法
2.Row Cacheを用いてデータがあるSStableから引っ張ってくる方法
3.Bloom FilterでどこのSStableにあるか引っ張ってくる方法
1は簡単でCassandraはデータを登録するときcommit_logに書き込んだ後memtableに書き込みますが、このmemtable上にあるものを取ってきます。なので一番早いです。
2はそもそもCassndraがどういった形でSStableに保存しているのか着目する必要があります。
Cassandraはデータを格納するときパーティションキーをハッシュ化してそのハッシュ化したいくつかのパーティションキーはこのバイトからこのバイトまでが領域といった風に別テーブルでソートして保持しています。
なのでRow Cacheを使うときはパーティションキーを別テーブルに問い合わせてそこからどのSStableのどのバイト数から始まっているか把握します。
この動作によってCassandraはSStableからデータを引っ張ってきます。
3はBloom Filterを使った方法です。
Bloom FilterとはパーティションキーのデータがどのSStableにあるかチャックするものです。この中には特殊な形でたくさんのパーティションキーとそのSStableの位置を覚えています。
ただし、これは100%正しいわけではなく、あくまで確率なので偽陽性を出すこともあります。
基本はこのような形になっていてこの中で索引を使用するといったことが行われます。
UPDATE
そもそもOracleのようなUPDATEは存在せず、UPDATEは書き込みする際にとりあえず書き込んでしまいます(=upsert)ただし、既存行と同じプライマリキーを持っている場合は既存行の更新になります。
とはいってもチェックをしないので古いのと新しいのが混在する可能性があります。
ではどうやって対処するのでしょうか??
そのためにはコンパクションを利用します。コンパクションの説明は下記サイトを参照
Compactionに関して
つまり、SSTableから一意の各行のバージョンをすべて収集し、各行のカラムの最新バージョン(タイムスタンプ順)を使用して1つの完全な行にまとめて古い物は固めて削除しちゃいます。
このコンパクションは単独のノードで行われていきます。
Replication_factorが1以上(いや、基本みんな1以上なんだけど、、)なら読み取り中にタイムスタンプを比較して一番新しいのを返してGossipの技術で古いものを新しいものへ置き換えてしまいます。
DELETE
こいつがやばい。Oracleと比べて考えることが多すぎる。。。初回じゃ理解できない。初回見たときの自分の図
そもそも削除を理解するためにはtombstoneを理解する必要があります。
Cassandraの削除はOracleのようにすぐに消してくれるわけではなくパラメータgc_grace_second(10日)デフォルトによって制御されています。
このtombstoneっていうのはシンプルにDELETE操作の時だけ作成されるものじゃなくて、、、
ドキュメントを参照すれば多分わかるけど、一応簡単に、、
tombstoneに関して
1.DELETE文を打ったとき
2.Time to Liveで有効期限が切れてしまったとき
3.マテリアライズドビューの使用などによる内部操作
4.nullを使用したINSERTないしはUPDATE操作←めっちゃ大事
期限が切れたtombstoneは削除対象になってコンパクションの中で削除されてしまう。
Cassandraはノードがいくつもあるので削除プロセスが結構複雑になりがち、、、
ある特定のノードがレコードの登録を行い、別ノードに伝搬した後削除を受け取ってtombstoneを立てる。
この時にもし、受け取ったノードがダウンしててこの間に最初に削除を受け取ったノードがデータを削除してしまう
zombieができて復活してきてしまう。(・ω・)ノシ
これを防ぐためにはtombstoneに猶予、つまりtombstoneを回復して正常に処理する時間を与える必要がある。
この時もタイムスタンプが一番新しいものが上書きされることになる。
幸いgc_grace_secondは10日あるのでこの間にノードを復活させないといけない。じゃないと一貫性が保てない。
zombieを防ぐためにはgc_grace_second内にノードを復活させnodetool repairコマンドを使って主導でリペアして行くことが大事
最後に
今までOracleを触ってきましたが、Cassandraになると異なることばかりで驚くことばかりです。。今後もこんな感じで週1ペースでCassandraで分かりにくくないかと主観で思ったところをまとめていきます。
*今回コード等も準備しておりましたが、参照先のドキュメントのほうにも豊富にありましたのでカットさせていただきました*