Azure Cognitive SearchがAzure AI Searchにリブランドされ、AI機能に多くのアップデートがありました。
その中の一つに 「データのインポートとベクター化」 があります。
これは簡単に言うとデータをBlob Storageにおいておけば、生成AIアプリケーションには欠かせない「チャンク分割」と「ベクトル化」を自動で実行し、インデックスを作成してくれる機能です。
詳細な実施手順ついては既に解説されている記事があります。
本記事の内容も上記手順を実施したことを前提としています。
本題
上記の手順を自身の環境でも試している中で気になるチェックボックスを発見・・・
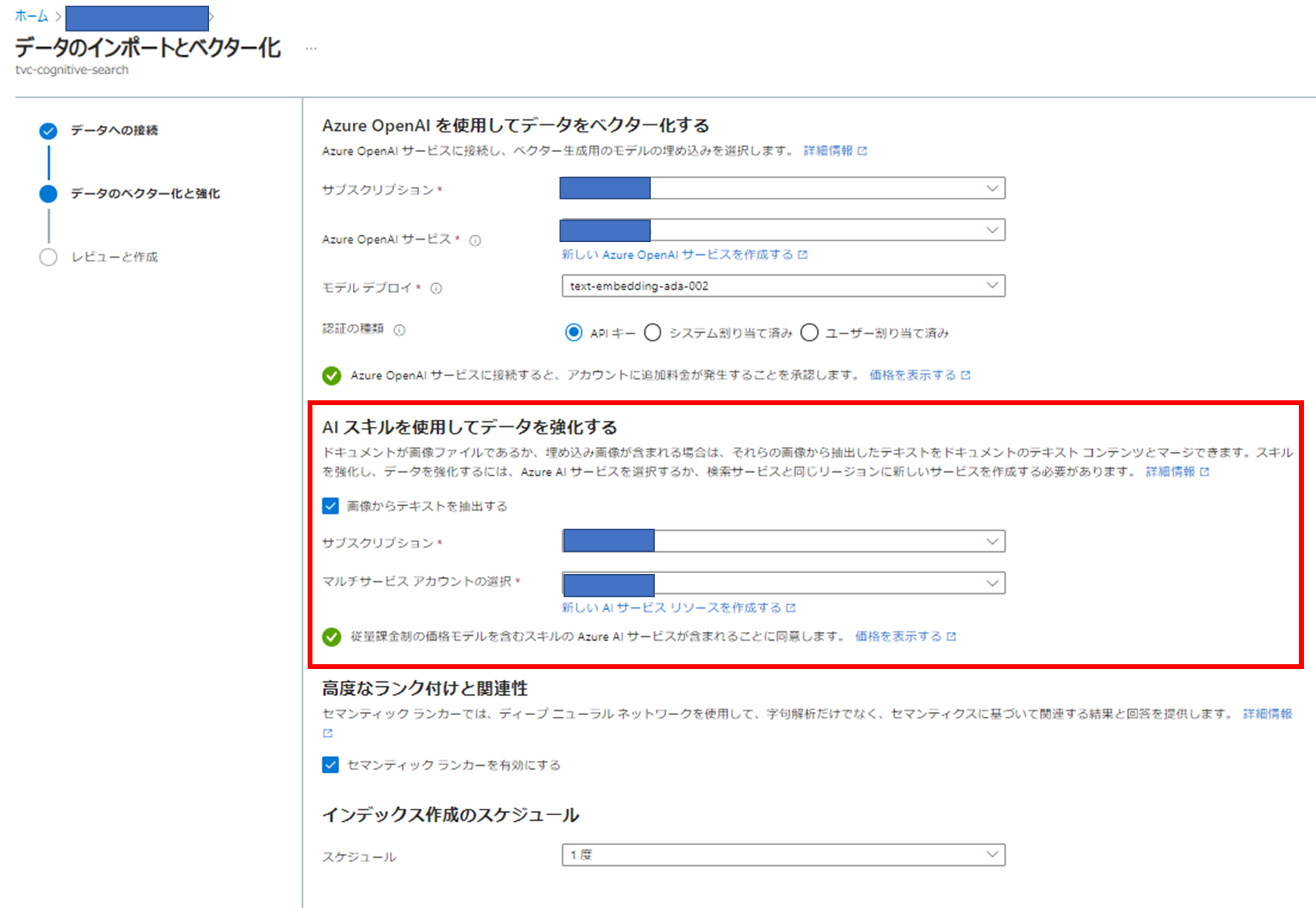
ドキュメントが画像ファイルであるか、埋め込み画像が含まれる場合は、それらの画像から抽出したテキストをドキュメントのテキスト コンテンツとマージできます。
PDFなどのドキュメントでところどころ画像が挿入されているケースは比較的多いと思います。
特に社内の手順書系のドキュメントは実際の内容はスクリーンショットがほとんどを占めるなんてこともありますよね。
この機能を使えばドキュメント内の画像をOCRし、前後のテキストデータと合わせて取り込み、チャンク分割、ベクトル化まで実施してくれるということです。
必要な手順
Azure AI Serviceを作成しておく
本機能の実際の動きとしてはAzure AI Searchの「スキルセット」を使ってインデクサー実行時にAzure AI VisionのOCR機能を呼び出す形となります。
なので呼び出されるAzure AI Visionが利用できるようにリソースを作成しておく必要があります。
既存のAzure AI Visionの単体リソースではなく、最近追加されたマルチサービスリソース(単一のキー、エンドポイントで複数のAIサービスにアクセスできる)として作成する必要があります。
日本語化対応
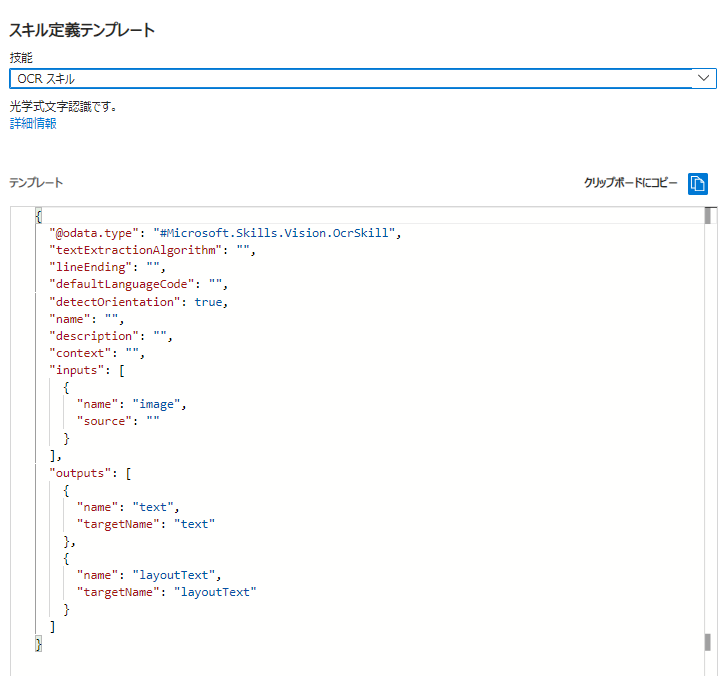
参考記事の(2/2)にもある通り、スキルセットの日本語化対応を実施します。
追加の対応として「Microsoft.Skills.Vision.OcrSkill」のdefaultLanguageCodeもenからjaに変更します。
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"name": "#4",
"description": null,
"context": "/document/normalized_images/*",
"textExtractionAlgorithm": null,
"lineEnding": "Space",
"defaultLanguageCode": "ja",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text",
"targetName": "text"
}
]
}
変更後はインデクサーのリセットと再実行を忘れずに
動作確認
まずは適当なテキストと画像が混じったPDFファイルを用意します。
ChatGPTにアメリカ、中国、日本の紹介を500字でしてもらいました。
そして日本の紹介文だけ画像化し、PDF化しました。
Githubにアップしておいたので検証の際はご利用ください。
このファイルをデータソースとして登録したBlob Storageにアップロードし、インデクサーを実行します。
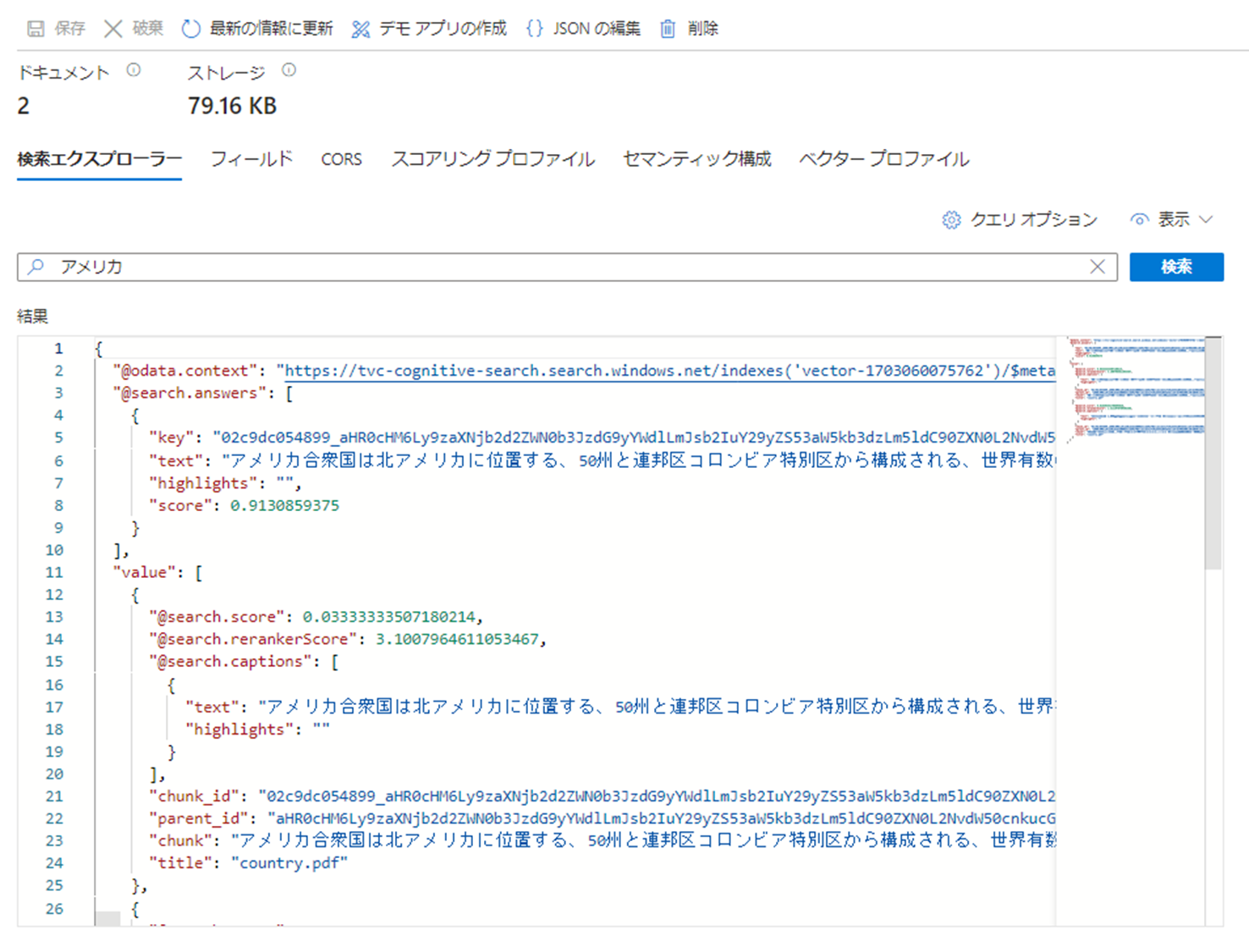
作成されたインデックスに対して検索をかけてみます。
まずはアメリカを検索しますが元々テキスト形式だったので問題なく検索できます。
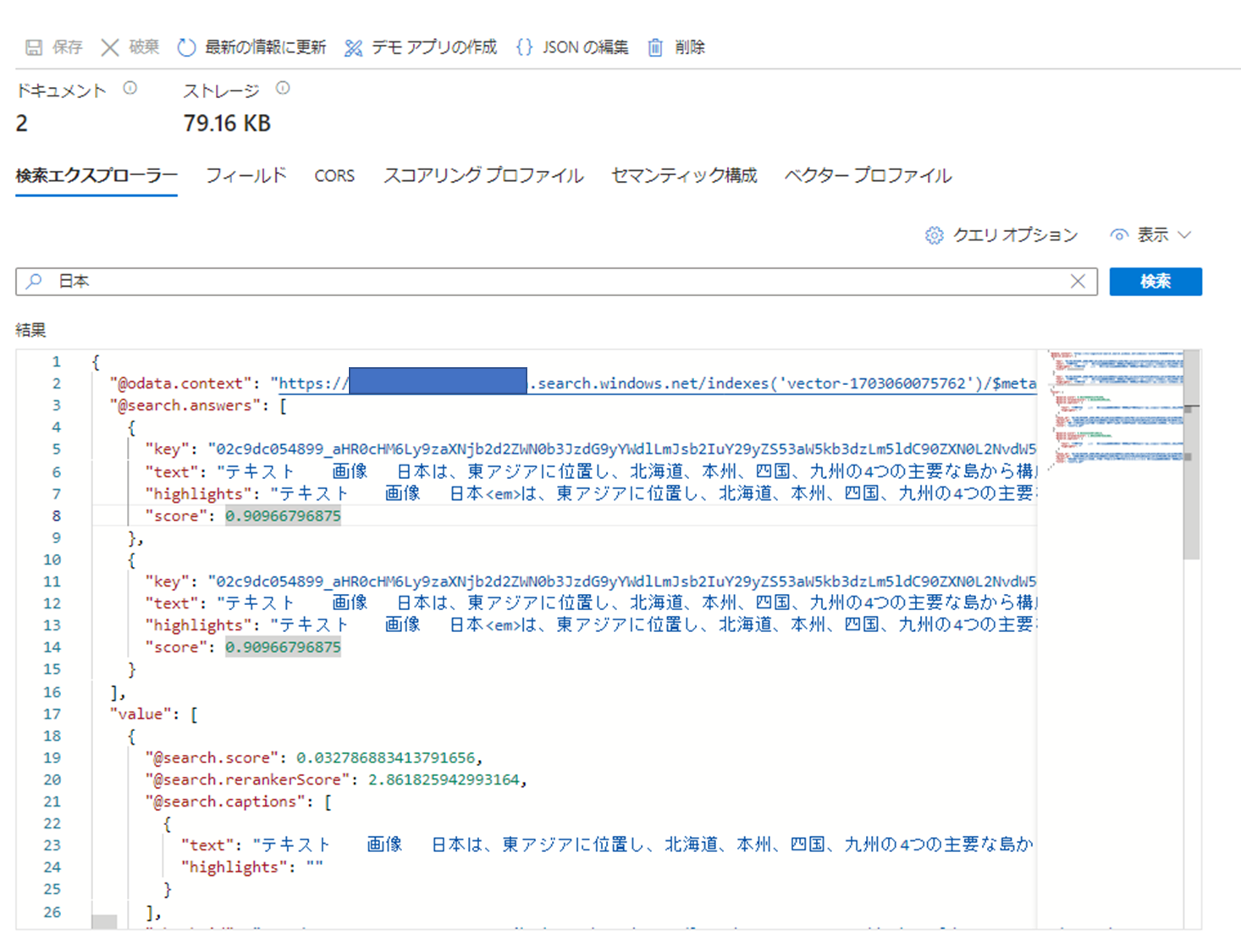
次に日本について検索してみます。
画像だった内容がしっかりOCRされて検索できることが確認できました!
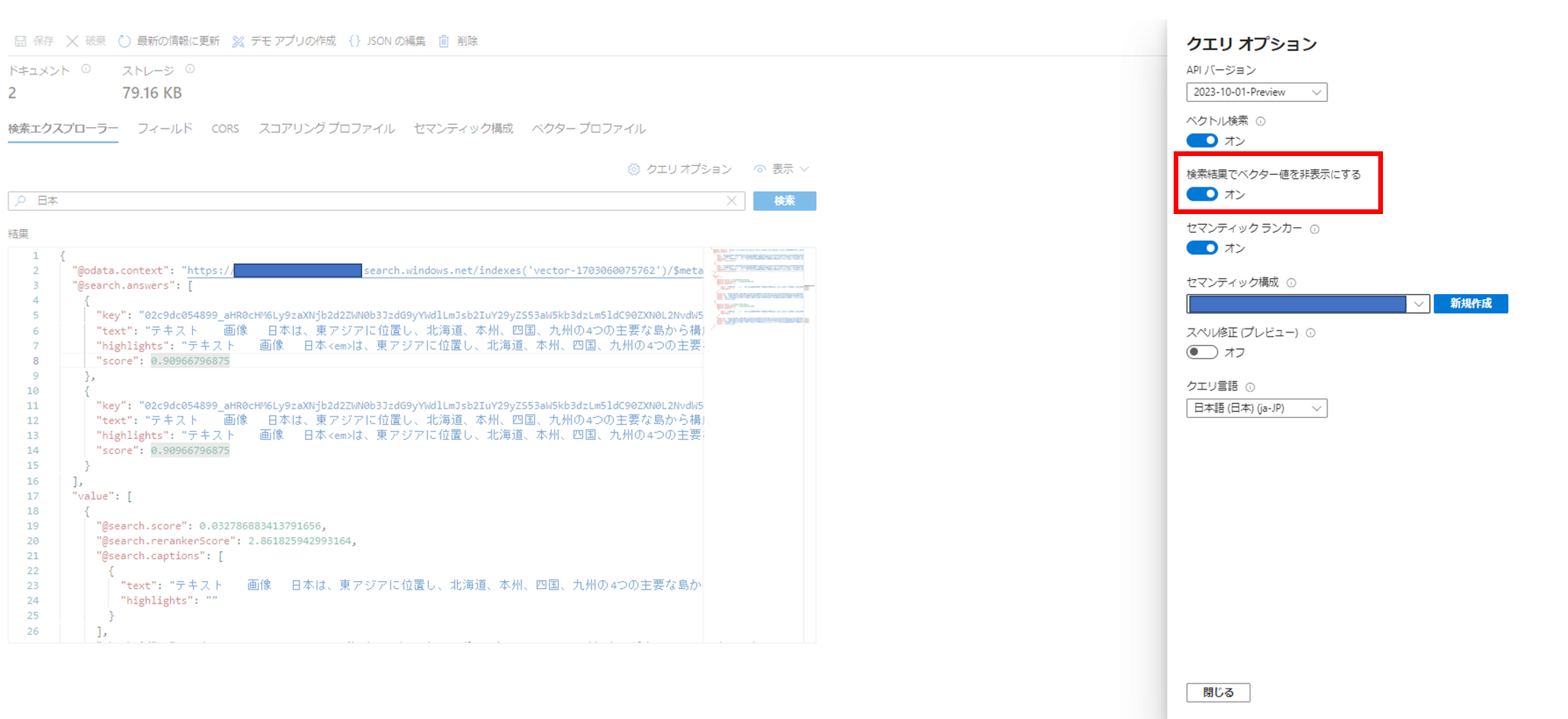
※余談
インデックスのクエリオプションで「検索結果でベクター値を非表示にする」にチェックを入れると検索結果がスッキリします。
おわりに
データインポート時のOCR機能については元々Cognitive Search時代からスキルセットで設定することが可能でしたが、スキルセットの追加画面からJSON追加して設定するといったとっつきにくいものでした(そもそもインデクサーやスキルセットの概念を理解するのが大変だった、、)
この辺りを単純に意識する必要が減ったというだけでも便利なったと感じますし、生成AIとの組み合わせ、RAGアプリケーションの構築を検討されている方には活用できる可能性がある機能だと思いました。
ただし、すべての画像がOCRしてテキスト抽出できるものではないと思いますので、引き続き社内のスクショだらけの手順書をどう生成AIと連携するかは課題になってくるでしょう。
以上、少しでも参考になれば幸いです。