はじめに
AWS re:Invent 2022 が開催されており、様々なサービスの情報が公開されております。
今回は、AWS Glue for Ray の情報が公開されたので、記事の内容をまとめてみました。
AWS Glue for Ray の詳細については、下記リンクを参照ください。
■リンク
- Announcing AWS Glue for Ray (Preview)
- Introducing AWS Glue for Ray: Scaling your data integration workloads using Python
AWS Glue
AWS Glue の特徴
AWS Glue は以下の特徴を持つ AWS サービスです。
- サーバレスなデータ統合サービス
- 複数のソースからデータを検出、準備、移動、統合することが可能
- 分析、機械学習 (ML)、アプリケーション開発が可能
AWS Glue のメリット
AWS GLue を使うメリットとして、以下の点が挙げられます。
- AWS などのクラウド環境は大規模なデータの保存や利用に適しているため、データ分析に向いた環境
- AWS Glue はデータ分析時の各種 AWS サービスとの連携を一括で管理することが可能
- サーバレスなのでインフラ環境の整備・システム管理が不要
AWS Glue for Ray
AWS Glue for Ray とは
Ray は AWs Glue の新しいジョブタイプで、統合化されたオープンソースのコンピュートフレームワークです。
Ray の主な特徴は以下です。
■AWS Glue for Ray の特徴
- Pythonの分散並列処理のフレームワークで、AI や Python のワークロードを簡単にスケール可能
- Python で書かれたアプリケーションであれば、マルチノード環境の分散クラスターで Ray を用いてスケールさせることが可能
- AWS SDK for pandasと組み合わせて、データ分析やMLワークロード実行のためのデータ準備・統合・変換を行うことが可能
- Glue Studio Notebooks、SageMaker Studio Notebook、そしてローカルノートブックや IDE で利用が可能
また、ユーザは AWS Glue job と AWS Glue interactive session primitives それぞれを使うことが可能です。
それぞれの特徴は以下となります。
-
AWS Glue job
- Rayコードを AWS Glue ジョブ API に送信すると、AWS Glue が自動的に必要な計算資源をプロビジョニングしてジョブを実行する、ファイア・アンド・フォーゲットなシステム
-
AWS Glue interactive session primitives
- ジョブ開発を目的としたデータのインタラクティブな探索を可能にする
AWS Glue for Rayは、大きく2つのコンポーネントで構成されています。
Ray Core - 分散コンピューティングフレームワーク
Ray Dataset - Apache Arrowをベースとした分散データフレームワーク
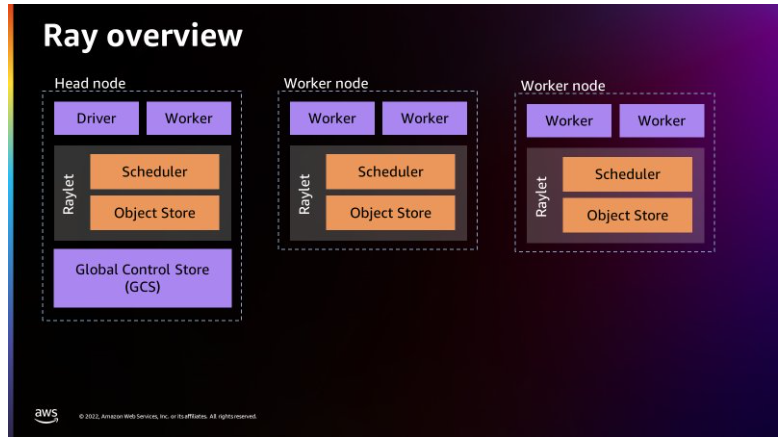
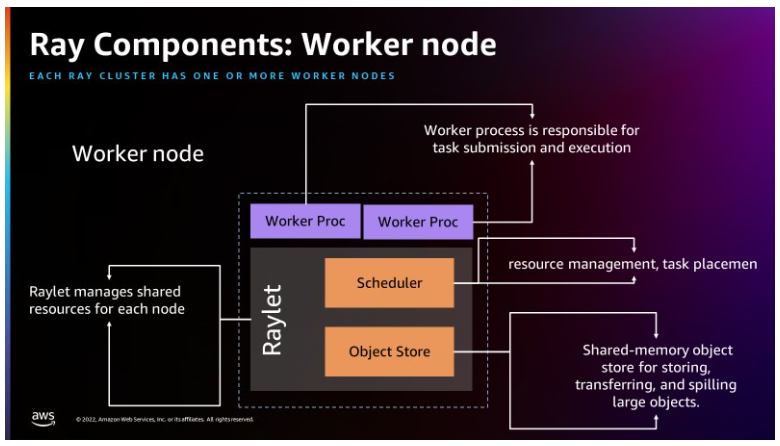
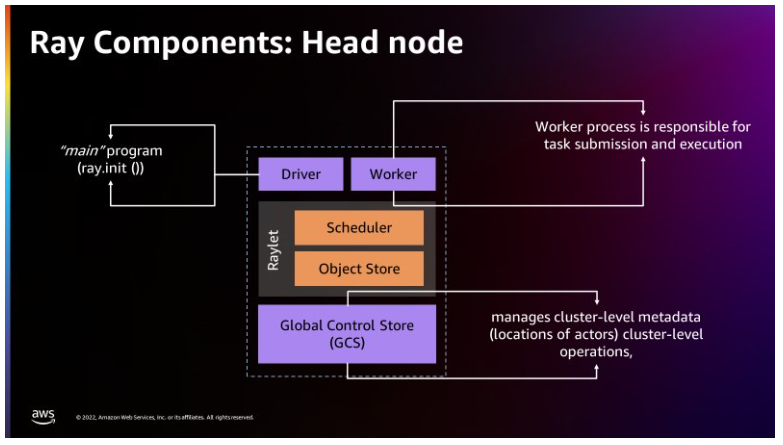
下図は、Rayのアーキテクチャを紹介したもので、Raylet と呼ばれるプロセスを通じて Ray がどのようにジョブをスケジューリングできるかを説明しています。
ワーカーノードと共有メモリ型オブジェクトストアの構成要素を表しています。
ヘッドノードには Global Control Store が存在し、Apache Spark がワーカーをノードとして扱うのと同様に、各個別のマシンをノードとして扱うことができます。 下図は、ヘッドノードのコンポーネントと、クラスタレベルのメタデータを管理する Global Control Store を表しています。
まとめ
AWS Glue for Ray では、ユーザがこれまで培ってきたスキル・パラダイム・フレームワーク・ライブラリを AWS Glue に持ち込み、最小限のコード変更で大規模なデータセットを扱えるように拡張することを可能にします。
AWS Glue for Rayは、以下のようなユースケースを想定しています。
■ユースケース
- タスク並列アプリケーション(例えば、複数の変換を並列に適用したい場合など)
- Pythonネイティブライブラリの利用だけでなく、Pythonワークロードを高速化する。
- 数百のデータソースにまたがって同じワークロードを実行する。
- MLインジェストとデータへの並列バッチ推論
おわりに
AWS Glue for Rayについてのまとめは以上となります。
より詳しい情報などについては、本記事をご参照ください。