2025-04-15
いいねとストックが入ったので2025版を作ります ![]()
Django + MySQL にはなっちゃうと思うけど
はじめに
興味深いAPI
ジェイソンとデータフレーム
最初に e-stat からデータを取ろうとしたときに、jsonでの取得まではすんなりいったけど、データフレームの入れ方が悪かった(JSONとデータフレームの関係がわかってなかった)ということがあった。
Syntax(構文)
pandas.read_json
Convert a JSON string to pandas object.
pandas.read_json(path_or_buf=None, orient=None)
path_or_buf : a valid JSON string or file-like, default: None
orient : string,
'records' : list like [{column -> value}, ... , {column -> value}]
result : Series or DataFrame, depending on the value of typ.
JSON試行錯誤
import urllib
import urllib.request
import pandas as pd
# Read appId
with open('api_setting/appid.txt', mode='r', encoding='utf-8') as f:
appId = f.read()
# stat url
url = r'http://api.e-stat.go.jp/rest/2.1/app/json/getStatsData?'
# Query param setting
keys = {
"appId" : appId,
"lang" : "J" ,
"statsDataId" : "0003143513" ,
"metaGetFlg" : "Y" ,
"cntGetFlg" : "N",
"sectionHeaderFlg" : "1"
}
# Get json data
query_param = urllib.parse.urlencode(keys)
df = pd.read_json(urllib.request.urlopen(url + query_param).read(), orient='records')
print(df)
>>> df
GET_STATS_DATA
PARAMETER {'LANG': 'J', 'STATS_DATA_ID': '0003143513', '...
RESULT {'STATUS': 0, 'ERROR_MSG': '正常に終了しました。', 'DATE...
STATISTICAL_DATA {'RESULT_INF': {'TOTAL_NUMBER': 13142278, 'FRO...
------------- データフレームてっぺんから最下層のリテラルを取るぞ! -------------
>>> print(df.columns)
Index(['GET_STATS_DATA'], dtype='object')
>>> print(df['GET_STATS_DATA'])
PARAMETER {'LANG': 'J', 'STATS_DATA_ID': '0003143513', '...
RESULT {'STATUS': 0, 'ERROR_MSG': '正常に終了しました。', 'DATE...
STATISTICAL_DATA {'RESULT_INF': {'TOTAL_NUMBER': 13142278, 'FRO...
>>> print(df['GET_STATS_DATA']['RESULT'])
{'STATUS': 0, 'ERROR_MSG': '正常に終了しました。', 'DATE': '2019-02-07T22:35:18.179+09:00'}
# ここまでで、1つの固有値を取得できた
>>> print(df['GET_STATS_DATA']['RESULT']['ERROR_MSG'])
正常に終了しました。
------------- Pandasで集計するぞ! -------------
# あれ、一段下がっただけでシリーズになっちまうのか...まぁそうか
>>> print(type(df['GET_STATS_DATA']))
<class 'pandas.core.series.Series'>
# ここから下は辞書になっちまうのか...
>>> print(type(df['GET_STATS_DATA']['STATISTICAL_DATA']))
<class 'dict'>
>>> print(df['GET_STATS_DATA']['STATISTICAL_DATA']['DATA_INF'].keys())
dict_keys(['NOTE', 'VALUE'])
????
>>> print(df['GET_STATS_DATA']['STATISTICAL_DATA']['DATA_INF']['VALUE'])
(・3・)アルェー?
とにかくデータフレームのまま操作したいのにできない。というハマりポイントがあった。ただこれ整理してみると、JSONデータであればデータフレームの入れ物にはスポッと入ってくれる。ただ、jsonの最初には大概ヘッダが入っている。つまり、データフレームに入れる時点で十分に階層を降りていないといけないということがわかった。
https://dev.classmethod.jp/etc/concrete-example-of-json/
[
{
"InstanceId": "i-XXXXXXXX",
"ImageId": "ami-YYYYYYYY",
"LaunchTime": "2015-05-28T08:30:10.000Z",
"Tags": [
{
"Value": "portnoydev-emr",
"Key": "Name"
},
{
"Value": "j-ZZZZZZZZZZZZ",
"Key": "aws:elasticmapreduce:job-flow-id"
},
{
"Value": "CORE",
"Key": "aws:elasticmapreduce:instance-group-role"
}
]
},
(略)
]
>>> df = pd.read_json(urllib.request.urlopen(url + query_param).read(), orient='records')
>>> df = pd.read_json(urllib.request.urlopen(url + query_param).read(), orient='records')['GET_STATS_DATA']['STATISTICAL_DATA']
>>> print(type(df))
<class 'dict'>
(・3・)アルェー?
>>> print(type(result['GET_STATS_DATA']['STATISTICAL_DATA']))
<class 'dict'>
>>> stats = pd.DataFrame(result['GET_STATS_DATA']['STATISTICAL_DATA'])
>>> print(type(stats))
<class 'pandas.core.frame.DataFrame'>
>>> stats
RESULT_INF ... DATA_INF
@id NaN ... NaN
CLASS_OBJ NaN ... NaN
CYCLE NaN ... NaN
FROM_NUMBER 1.0 ... NaN
GOV_ORG NaN ... NaN
MAIN_CATEGORY NaN ... NaN
NEXT_KEY 100001.0 ... NaN
NOTE NaN ... {'@char': '***', '$': '該当データがない場合を示す。'}
OPEN_DATE NaN ... NaN
OVERALL_TOTAL_NUMBER NaN ... NaN
SMALL_AREA NaN ... NaN
STATISTICS_NAME NaN ... NaN
STATISTICS_NAME_SPEC NaN ... NaN
STAT_NAME NaN ... NaN
SUB_CATEGORY NaN ... NaN
SURVEY_DATE NaN ... NaN
TITLE NaN ... NaN
TITLE_SPEC NaN ... NaN
TOTAL_NUMBER 13142278.0 ... NaN
TO_NUMBER 100000.0 ... NaN
UPDATED_DATE NaN ... NaN
VALUE NaN ... [{'@tab': '1', '@cat01': '0001', '@area': '13A...
[22 rows x 4 columns]
>>> stats = pd.DataFrame(result['GET_STATS_DATA']['STATISTICAL_DATA']['VALUE'])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'VALUE'
たしかにそこにいるはずなんだが...![]()
なんかもう昔のゲームやってるみたいだわ、3次元以上の配列って...(この感じわかるひといる?)

ん?
>>> stats.columns
Index(['RESULT_INF', 'TABLE_INF', 'CLASS_INF', 'DATA_INF'], dtype='object')
>>> stats['DATA_INF']
@id NaN
CLASS_OBJ NaN
CYCLE NaN
FROM_NUMBER NaN
GOV_ORG NaN
MAIN_CATEGORY NaN
NEXT_KEY NaN
NOTE {'@char': '***', '$': '該当データがない場合を示す。'}
OPEN_DATE NaN
OVERALL_TOTAL_NUMBER NaN
SMALL_AREA NaN
STATISTICS_NAME NaN
STATISTICS_NAME_SPEC NaN
STAT_NAME NaN
SUB_CATEGORY NaN
SURVEY_DATE NaN
TITLE NaN
TITLE_SPEC NaN
TOTAL_NUMBER NaN
TO_NUMBER NaN
UPDATED_DATE NaN
VALUE [{'@tab': '1', '@cat01': '0001', '@area': '13A...
Name: DATA_INF, dtype: object
# これやるとデータがずばーっと出てくるので
>>> stats['DATA_INF']['VALUE']
# 5レコードにおさえる
>>> stats['DATA_INF']['VALUE'][0:5]
[{'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2019000101', '$': '101.2'}, {'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2018001212', '$': '101.2'}, {'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2018001111', '$': '101.4'}, {'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2018001010', '$': '101.7'}, {'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2018000909', '$': '101.4'}]
>>> stats['DATA_INF']['VALUE'][0:5]
[
{'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2019000101', '$': '101.2'},
{'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2018001212', '$': '101.2'},
{'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2018001111', '$': '101.4'},
{'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2018001010', '$': '101.7'},
{'@tab': '1', '@cat01': '0001', '@area': '13A01', '@time': '2018000909', '$': '101.4'}
]
>>> print(type(stats['DATA_INF']['VALUE']))
<class 'list'>
# あっ!なんかキタぞ!めっちゃ試行錯誤いるなぁ...JSON...
>>> df = pd.DataFrame(stats['DATA_INF']['VALUE'])
>>> df
$ @area @cat01 @tab @time
0 101.2 13A01 0001 1 2019000101
1 101.2 13A01 0001 1 2018001212
2 101.4 13A01 0001 1 2018001111
3 101.7 13A01 0001 1 2018001010
4 101.4 13A01 0001 1 2018000909
... ... ... ... ... ...
99995 100.9 00049 0003 1 2011000808
99996 100.8 00049 0003 1 2011000707
99997 99.6 00049 0003 1 2011000606
99998 99.9 00049 0003 1 2011000505
99999 99.4 00049 0003 1 2011000404
[100000 rows x 5 columns]
>>> df['$']
0 101.2
1 101.2
2 101.4
3 101.7
4 101.4
...
99995 100.9
99996 100.8
99997 99.6
99998 99.9
99999 99.4
Name: $, Length: 100000, dtype: object
>>> df['@time']
0 2019000101
1 2018001212
2 2018001111
3 2018001010
4 2018000909
...
99995 2011000808
99996 2011000707
99997 2011000606
99998 2011000505
99999 2011000404
Name: @time, Length: 100000, dtype: object
補足:見てるオライリーはこれ
オライリーって無骨だけど読みやすいよね

JSONコンソール操作まとめ
res(=Full JSON) が返ってきてから、dfに入れる直前までの間に、単純なタテヨコの一般的な(?)2元配列になるところまで十分にJSON配列(?)を潜ってからデータフレームに渡すんや。...というよりは、dfに代入してデータフレーム手に入ったー!って思ってたのはただのナマJSONだった(pd.DataFrame(...)の漏れ)
>>> import urllib
>>> import urllib.request
>>> import pandas as pd
>>> appId = '****************************'
>>> url = r'http://api.e-stat.go.jp/rest/2.1/app/json/getStatsData?'
>>> keys = {
"appId" : appId,
"lang" : "J" ,
"statsDataId" : "0003143513" ,
"metaGetFlg" : "Y" ,
"cntGetFlg" : "N",
"sectionHeaderFlg" : "1"
}
>>> query_param = urllib.parse.urlencode(keys)
>>> res = pd.read_json(urllib.request.urlopen(url + query_param).read(), orient='records')
>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['DATA_INF']['VALUE'])
>>> df
$ @area @cat01 @tab @time
0 101.2 13A01 0001 1 2019000101
1 101.2 13A01 0001 1 2018001212
2 101.4 13A01 0001 1 2018001111
3 101.7 13A01 0001 1 2018001010
4 101.4 13A01 0001 1 2018000909
... ... ... ... ... ...
99995 100.9 00049 0003 1 2011000808
99996 100.8 00049 0003 1 2011000707
99997 99.6 00049 0003 1 2011000606
99998 99.9 00049 0003 1 2011000505
99999 99.4 00049 0003 1 2011000404
[100000 rows x 5 columns]
>>> df['$']
0 101.2
1 101.2
2 101.4
3 101.7
4 101.4
...
99995 100.9
99996 100.8
99997 99.6
99998 99.9
99999 99.4
Name: $, Length: 100000, dtype: object
>>> df['@time']
0 2019000101
1 2018001212
2 2018001111
3 2018001010
4 2018000909
...
99995 2011000808
99996 2011000707
99997 2011000606
99998 2011000505
99999 2011000404
Name: @time, Length: 100000, dtype: object

ようやく僕が知ってるデータフレームまできたぁ~![]()
いっかい寝よ...
つべこべいわずにJSON整形サイトに流し込め!
http://tm-webtools.com/Tools/JsonBeauty
元のデータを知らない(作ってない)んだから試行錯誤になるのはあたりまえ!
{
"GET_STATS_DATA": {
"RESULT": {
"STATUS": 0,
"ERROR_MSG": "正常に終了しました。",
"DATE": "2019-02-08T21:16:05.801+09:00"
},
"PARAMETER": {
"LANG": "J",
"STATS_DATA_ID": "0003143513",
"DATA_FORMAT": "J",
"START_POSITION": 1,
"METAGET_FLG": "Y",
"CNT_GET_FLG": "N",
"SECTION_HEADER_FLG": 1
},
"STATISTICAL_DATA": {
"RESULT_INF": {
"TOTAL_NUMBER": 13142278,
"FROM_NUMBER": 1,
"TO_NUMBER": 100000,
"NEXT_KEY": 100001
},
"TABLE_INF": {
"@id": "0003143513",
"STAT_NAME": {
"@code": "00200573",
"$": "消費者物価指数"
},
"GOV_ORG": {
"@code": "00200",
"$": "総務省"
},
"STATISTICS_NAME": "2015年基準消費者物価指数",
"TITLE": {
"@no": "1",
"$": "消費者物価指数(2015年基準)"
},
"CYCLE": "-",
"SURVEY_DATE": 0,
"OPEN_DATE": "2019-01-25",
"SMALL_AREA": 0,
"MAIN_CATEGORY": {
"@code": "07",
"$": "企業・家計・経済"
},
"SUB_CATEGORY": {
"@code": "03",
"$": "物価"
},
"OVERALL_TOTAL_NUMBER": 13142278,
"UPDATED_DATE": "2019-01-24",
"STATISTICS_NAME_SPEC": {
"TABULATION_CATEGORY": "2015年基準消費者物価指数"
},
"TITLE_SPEC": {
"TABLE_NAME": "消費者物価指数(2015年基準)"
}
},
"CLASS_INF": {
"CLASS_OBJ": [
{
"@id": "tab",
"@name": "表章項目",
"CLASS": [
{
"@code": "1",
"@name": "指数",
"@level": ""
},
{
"@code": "2",
"@name": "前月比・前年比・前年度比",
"@level": "",
"@unit": "%"
},
{
"@code": "3",
"@name": "前年同月比",
"@level": "",
"@unit": "%"
},
{
"@code": "4",
"@name": "ウエイト(実数)",
"@level": ""
},
{
"@code": "5",
"@name": "ウエイト(万分比)",
"@level": ""
}
]
},
{
"@id": "cat01",
"@name": "2015年基準品目",
"CLASS": [
{
"@code": "0001",
"@name": "0001 総合",
"@level": "1"
},
{
"@code": "0002",
"@name": "0002 食料",
"@level": "1"
},
{
"@code": "0003",
"@name": "0003 穀類",
"@level": "3",
"@parentCode": "0002"
},
(略)
]
}
]
},
"DATA_INF": {
"NOTE": {
"@char": "***",
"$": "該当データがない場合を示す。"
},
"VALUE": [
{
"@tab": "1",
"@cat01": "0001",
"@area": "13A01",
"@time": "2019000101",
"$": "101.2"
},
{
"@tab": "1",
"@cat01": "0001",
"@area": "13A01",
"@time": "2018001212",
"$": "101.2"
},
{
"@tab": "1",
"@cat01": "0001",
"@area": "13A01",
"@time": "2018001111",
"$": "101.4"
},
(略)
]
}
}
}
}
e-Stat
(JSONの試行錯誤は上のセクションにまとめたので、それ以外を書きます)
参考ページ
e-Stat(政府統計)のAPI機能をつかってpythonでグラフを書いたりしてみる
APIの使い方 how_to_use
前準備情報等
・ユーザー登録
・ログインしてマイページ→API機能(アプリケーションID発行)
・名称は「開発用」
・URLは「ttp://localhost/」(※Qiitaだとリンクになっちゃうから先頭の h は削除)
消費者物価指数 2015年基準消費者物価指数(公開日:2019-01-25)
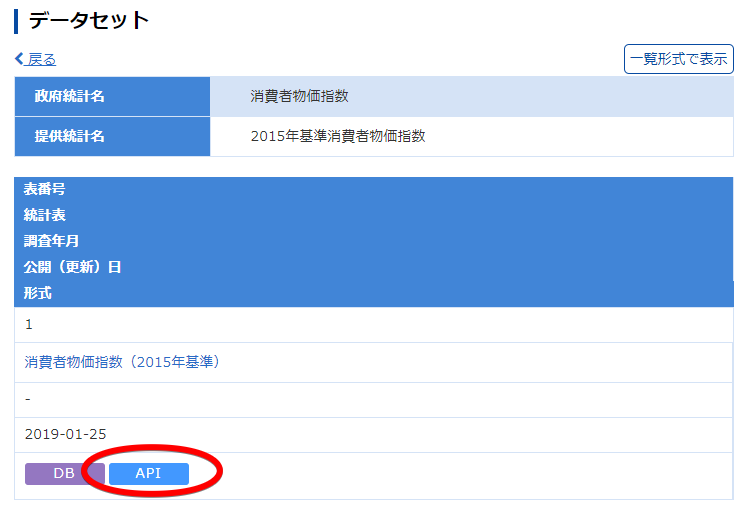
http://api.e-stat.go.jp/rest/2.1/app/json/getStatsData?appId=&lang=J&statsDataId=0003143513&metaGetFlg=Y&cntGetFlg=N§ionHeaderFlg=1
データについて
db形式で表示されるページがあるなら先に構造を見ておけってのは、まぁあたりまえっちゃあたりまえだったね![]()
このへんかな?
https://www.e-stat.go.jp/api/api-info/e-stat-manual#api_3_4
cdArea 地域事項?
lvCat01 分類事項01?
cdTab 表章事項?
lvTime 時間軸事項?
VALUE 統計数値(セル)の情報です。データ件数分だけ出力されます。
属性として表章事項コード(tab)、分類事項コード(cat01 ~ cat15)、地域事項コード(area)、時間軸事項コード(time)、単位(unit)を保持します。全ての属性はデータがある場合のみ出力されます。
単語:表章 https://www.stat.go.jp/data/kokusei/2010/users-g/pdf/mikata.pdf
うーん、例えば地域コード 13A01 はどこだよ!?マスタは?みたいな感じになるよなぁ~??
>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['DATA_INF']['VALUE'])
>>> df
$ @area @cat01 @tab @time
0 101.2 13A01 0001 1 2019000101
1 101.2 13A01 0001 1 2018001212
2 101.4 13A01 0001 1 2018001111
3 101.7 13A01 0001 1 2018001010
4 101.4 13A01 0001 1 2018000909
... ... ... ... ... ...
99995 100.9 00049 0003 1 2011000808
99996 100.8 00049 0003 1 2011000707
99997 99.6 00049 0003 1 2011000606
99998 99.9 00049 0003 1 2011000505
99999 99.4 00049 0003 1 2011000404
[100000 rows x 5 columns]
>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'])
>>> df
@id @name CLASS
0 tab 表章項目 [{'@code': '1', '@name': '指数', '@level': ''}, ...
1 cat01 2015年基準品目 [{'@code': '0001', '@name': '0001 総合', '@level...
2 area 地域(2015年基準) [{'@code': '13A01', '@name': '13100 東京都区部', '@...
3 time 時間軸(年・月) [{'@code': '2019000101', '@name': '2019年1月', '...
整形サイト http://tm-webtools.com/Tools/JsonBeauty でJSONとにらめっこだな。
わかってきたのは...
>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][0]['CLASS'])
>>> df
@code @level @name @unit
0 1 指数 NaN
1 2 前月比・前年比・前年度比 %
2 3 前年同月比 %
3 4 ウエイト(実数) NaN
4 5 ウエイト(万分比) NaN
>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][1]['CLASS'])
>>> df
@code @level @name @parentCode
0 0001 1 0001 総合 NaN
1 0002 1 0002 食料 NaN
2 0003 3 0003 穀類 0002
3 0004 5 0004 米類 0003
4 1000 6 1000 うるち米 0004
.. ... ... ... ...
793 0905 1 0905 食料(酒類を除く)及びエネルギーを除く総合(季節調整済) NaN
794 0921 1 0921 財(季節調整済) NaN
795 0922 1 0922 半耐久消費財(季節調整済) NaN
796 0923 1 0923 生鮮食品を除く財(季節調整済) NaN
797 0906 1 0906 生鮮食品及びエネルギーを除く総合(季節調整済) NaN
[798 rows x 4 columns]
>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][2]['CLASS'])
>>> df
@code @level @name
0 13A01 1 13100 東京都区部
1 00000 1 全国
2 00011 1 人口5万以上の市
3 00012 1 大都市
4 00013 1 中都市
.. ... ... ...
67 14A02 1 14130 川崎市
68 14A03 1 14150 相模原市
69 22A02 1 22130 浜松市
70 27A02 1 27140 堺市
71 40A01 1 40100 北九州市
[72 rows x 3 columns]
>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][3]['CLASS'])
>>> df
@code @level @name @parentCode
0 2019000101 4 2019年1月 2019000103
1 2018001212 4 2018年12月 2018001012
2 2018001111 4 2018年11月 2018001012
3 2018001010 4 2018年10月 2018001012
4 2018000909 4 2018年9月 2018000709
.. ... ... ... ...
681 1970000404 4 1970年4月 1970000000
682 1970000303 4 1970年3月 1970000000
683 1970000202 4 1970年2月 1970000000
684 1970000101 4 1970年1月 1970000000
685 1970000000 1 1970年 NaN
[686 rows x 4 columns]
つまり...どういうことだってばよ
データフレームに SQL:Where を適用する
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.where.html
まぁ4つのマスタはそれぞれ違うデータフレームに受け取るのがわかりやすいとは思うけど
>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['DATA_INF']['VALUE'])
>>> df
$ @area @cat01 @tab @time
0 101.2 13A01 0001 1 2019000101
>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][2]['CLASS'])
>>> df['@name'].where(df['@code'] == '13A01')[0]
'13100 東京都区部'
>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][1]['CLASS'])
>>> df['@name'].where(df['@code'] == '0001')[0]
'0001 総合'
>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][0]['CLASS'])
>>> df['@name'].where(df['@code'] == '1')[0]
'指数'
>>> df = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][3]['CLASS'])
>>> df['@name'].where(df['@code'] == '2019000101')[0]
'2019年1月'
# translation to dataframe from json-data
data = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['DATA_INF']['VALUE'])
area = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][2]['CLASS'])
category = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][1]['CLASS'])
tab = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][0]['CLASS'])
time = pd.DataFrame(res['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][3]['CLASS'])
複数のデータフレームをInnerJoinする
If we want to join using the key columns, we need to set key to be the index in both df and other. The joined DataFrame will have key as its index.
キー列を使って結合したい場合は、keyをdfとotherの両方のインデックスになるように設定する必要があります。結合されたDataFrameはそのインデックスとしてキーを持ちます。
>>> df.set_index('key').join(other.set_index('key'))
A B
key
K0 A0 B0
K1 A1 B1
K2 A2 B2
K3 A3 NaN
K4 A4 NaN
K5 A5 NaN
ここから先は結合するにあたって項目名がカブってくるので列名を変更する。
data以外のデータフレームの「@name」だけでいいんじゃないかな
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.rename.html#pandas.DataFrame.rename
# 確認:
>>> data.columns
Index(['$', '@area', '@cat01', '@tab', '@time'], dtype='object')
>>> area.columns
Index(['@code', '@level', '@name'], dtype='object')
>>> category.columns
Index(['@code', '@level', '@name', '@parentCode'], dtype='object')
>>> tab.columns
Index(['@code', '@level', '@name', '@unit'], dtype='object')
# 調整1: 列名変更
>>> area = area.rename(columns={'@name': 'area_name'})
>>> category = category.rename(columns={'@name': 'category_name'})
>>> tab = tab.rename(columns={'@name': 'tab_name'})
# 調整2: くっつけるとカブる列とか不要列の削除(レベルは、「全国」と「都道府県」を分けるみたいな深さ情報みたい)
# エラーを出しながら判断
>>> area = area.drop(columns=['@level'])
>>> category = category.drop(columns=['@level','@parentCode'])
>>> tab = tab.drop(columns=['@level','@unit'])
# 結合: Inner Join
>>> joined = data.set_index('@area').join(area.set_index('@code'))
>>> joined = joined.set_index('@cat01').join(category.set_index('@code'))
>>> joined = joined.set_index('@tab').join(tab.set_index('@code'))
# 確認: たぶんこれ「指数」以外もあるんだよね(「:10」で、10件だけ表示)
>>> joined[:10]
$ area_name category_name tab_name time_name
1970000000 31.5 全国 0001 総合 指数 1970年
1970000000 31.7 人口5万以上の市 0001 総合 指数 1970年
1970000000 31.7 大都市 0001 総合 指数 1970年
1970000000 31.8 中都市 0001 総合 指数 1970年
1970000000 31.2 小都市A 0001 総合 指数 1970年
1970000000 33.2 北海道地方 0001 総合 指数 1970年
1970000000 30.6 東北地方 0001 総合 指数 1970年
1970000000 31.5 関東地方 0001 総合 指数 1970年
1970000000 31.5 北陸地方 0001 総合 指数 1970年
1970000000 31.5 東海地方 0001 総合 指数 1970年
データの加工
これ最初さー、「2019年1月」とか日本語入ってるとあとから取り回し悪くて仕方ないから int で年月項目にしようとしたんだけど13行目と14行目見て?![]()
年度!?いらないよー。かんべんしてくださいよこれ。で、@levelって 1 と 4 以外にあるのかな?って思ってみるも、Pythonコンソールってデータを省略して見せてくるので、しかたなくcsv出力をして確認。 1 と 4 しかないことを確認できたので 1 のレコードを消しましょう。そうすれば ym にできるはず。
>>> time
@code @level @name @parentCode
0 2019000101 4 2019年1月 2019000103
1 2018001212 4 2018年12月 2018001012
2 2018001111 4 2018年11月 2018001012
3 2018001010 4 2018年10月 2018001012
4 2018000909 4 2018年9月 2018000709
5 2018000808 4 2018年8月 2018000709
6 2018000707 4 2018年7月 2018000709
7 2018000606 4 2018年6月 2018000406
8 2018000505 4 2018年5月 2018000406
9 2018000404 4 2018年4月 2018000406
10 2018000303 4 2018年3月 2018000103
11 2018000202 4 2018年2月 2018000103
12 2018000101 4 2018年1月 2018000103
13 2018000000 1 2018年 NaN
14 2017100000 1 2017年度 NaN
15 2017001212 4 2017年12月 2017001012
16 2017001111 4 2017年11月 2017001012
17 2017001010 4 2017年10月 2017001012
# edit text to '201901' from '2019年1月'
time['yyyy'] = time['time'].str.split('年', expand=True)[0]
time['mm'] = time['time'].str.split('年', expand=True)[1].str.strip('月').str.zfill(2)
time['yyyymm'] = time['yyyy'] + time['mm']
# If there is 'A' in the middle, it means 'city'
area['city_flag'] = area['@code'].str.contains('..A..')
area['area'] = area['area'].str.split(' ', expand=True)[1]
API取得制限に注意な
なんかデータ足りなくない??って思って、例えばカテゴリーが「総合」か「食料」か「穀物」までしかないんだよなぁ~、くっつけかた間違えたかなぁ~??とか思ってたけどこれだったか。data の時点のデータフレームでは100,000レコードであることを確認できました。URLをクエリパラメータ作ってひっぱるときにレコード減らす工夫するしかないね。
Q7 : 【統計データ取得機能】10万件を超えるデータを取得できません。
A7 : API機能は、一度に最大で10万件のデータを返却します。そのため、統計データが一度に取得できない場合には、継続データの取得開始位置をレスポンスのタグの値として出力します。継続データを要求する場合は、データ取得開始位置パラメータ(startPosition)にこの値を指定することで、取得できます。
SQLServerでテーブルを作る
CREATE TABLE e_Stat (
yyyymm INT NOT NULL
, category NVARCHAR(50) NULL
, area NVARCHAR(50) NULL
, amount NUMERIC(5,1) NULL
);
プログラムを流してみる
あーできたー... 解散!解散ー!おつかれー
うまいもんくって寝ましょ![]()
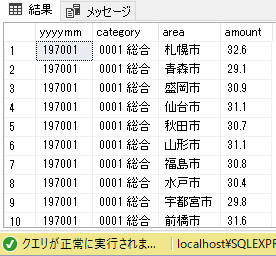
basic_connect-api-e_stat> python main.py
197002,0002 食料,岡山市,30.4
197004,0002 食料,福井市,29.6
197006,0002 食料,盛岡市,30.0
197008,0001 総合,山口市,32.9
197010,0001 総合,長野市,32.7
197012,0001 総合,秋田市,32.2
197101,0002 食料,松山市,33.0
197103,0002 食料,名古屋市,33.3
197105,0002 食料,水戸市,31.7
197107,0001 総合,北九州市,32.6
197109,0001 総合,大津市,34.9
197112,0001 総合,奈良市,35.4
197202,0001 総合,横浜市,34.4
197205,0002 食料,松江市,31.1
197209,0002 食料,青森市,32.8
197301,0001 総合,甲府市,35.5
197304,0002 食料,高松市,38.9
197308,0002 食料,福島市,37.7
197312,0001 総合,津市,41.6
197402,0002 食料,富山市,45.1
197402,0002 食料,金沢市,46.3
197402,0002 食料,福井市,44.7
197402,0002 食料,甲府市,46.1
197402,0002 食料,長野市,48.4
197402,0002 食料,岐阜市,45.0
197402,0002 食料,静岡市,44.6
197402,0002 食料,名古屋市,48.0
197402,0002 食料,津市,44.2
197402,0002 食料,大津市,51.6
197402,0002 食料,京都市,49.9
ソースコード
ソースをgithubにしとくとあとがラクねぇ~
https://github.com/duri0214/Python/tree/master/basic_connect-api-e_stat
改修履歴
・1回あたり取得量100,000レコードを突破するべくループを組んで全量取得可能にしました