はじめに
やりたかった。
適用するのはおなじみ、ポートフォリオ(llm_chat)だ
TODO: githubのアドレスがsoil_analysisになっているのでなおして
参考
OpenAI APIキーの作成
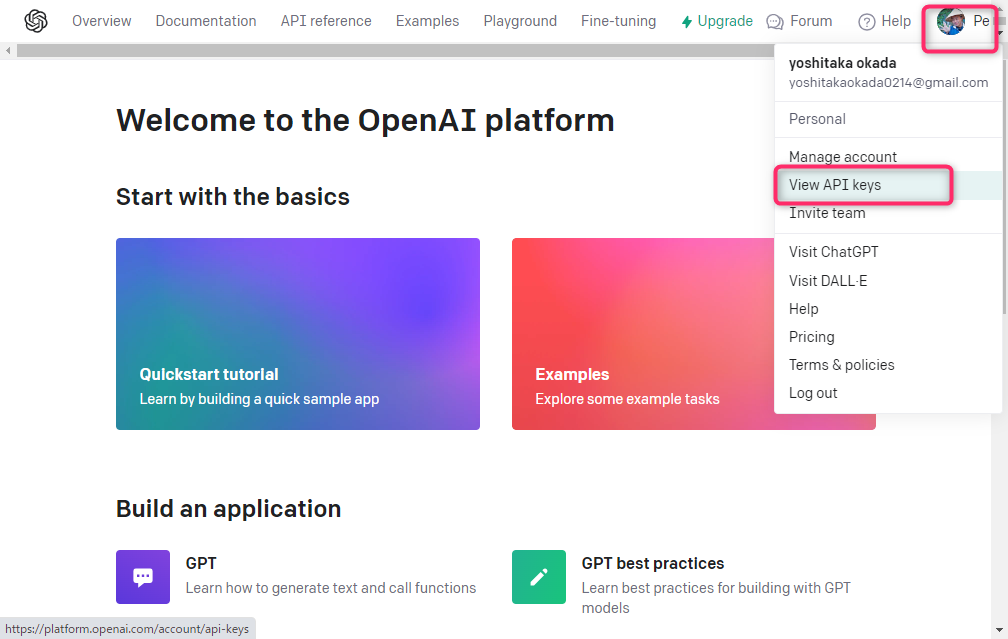
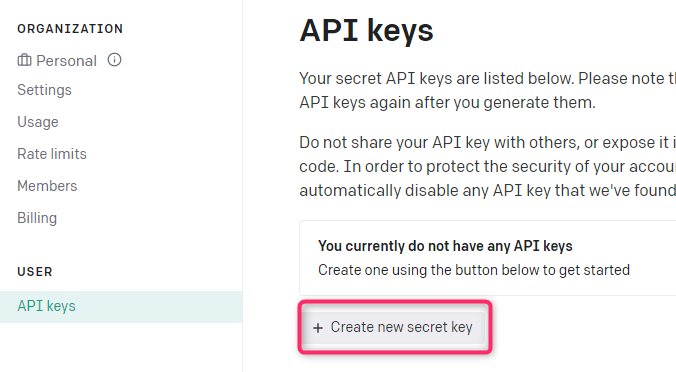
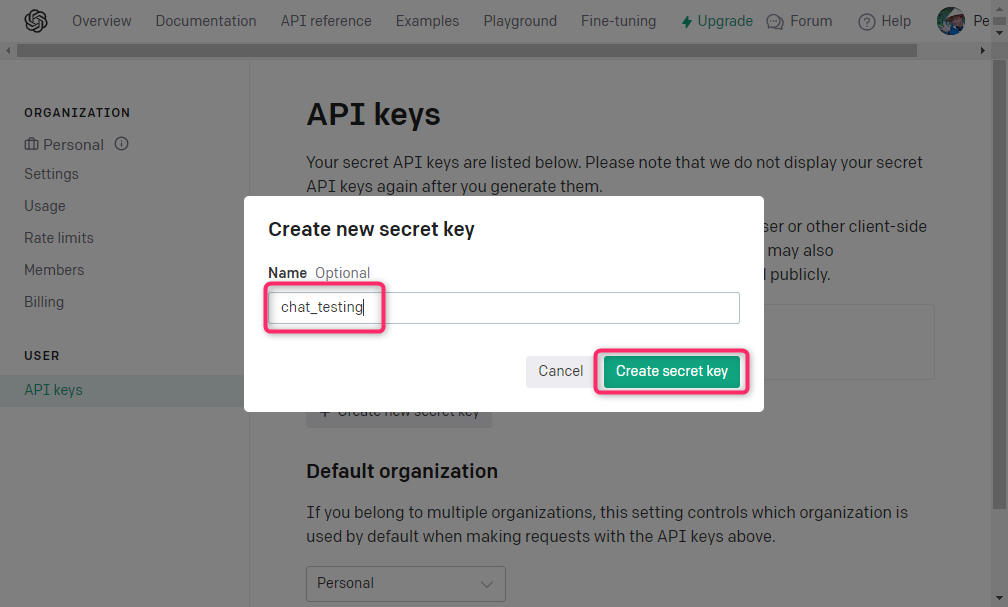
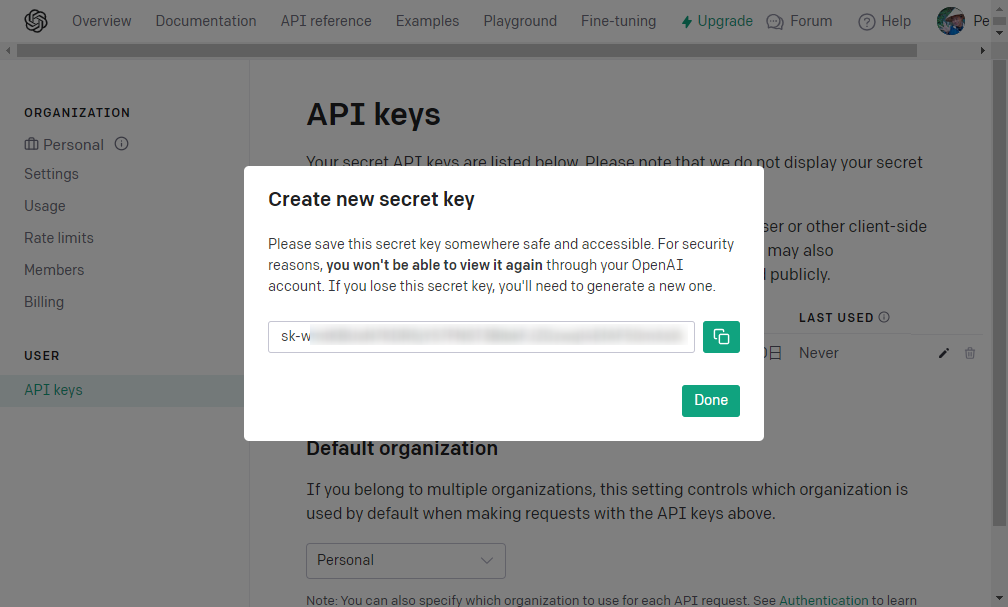
クレジットカード支払いの設定
非公開情報を.envに移す(GitGuardian対策)
llm_service.py
lib/llm/llm_service.py
:
from langchain.chains.qa_with_sources.retrieval import RetrievalQAWithSourcesChain
from langchain.prompts import (
ChatPromptTemplate,
)
from langchain_chroma import Chroma
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAIEmbeddings
:
from lib.llm.valueobject.rag import PdfDataloader
from llm_chat.domain.valueobject.chat import MessageDTO
:
class OpenAILlmRagService(LlmService):
def __init__(
self, config: OpenAIGptConfig, dataloader: PdfDataloader, n_results: int = 3
):
"""
See Also: https://python.langchain.com/docs/how_to/qa_sources/
"""
super().__init__()
self.config = config
self.dataloader = dataloader
self.n_results = n_results
self.system_template = """
以下の資料の注意点を念頭に置いて回答してください
・ユーザの質問に対して、できる限り根拠を示してください
・箇条書きで簡潔に回答してください。
---下記は資料の内容です---
{summaries}
Answer in Japanese:
"""
messages = [
("system", self.system_template),
("human", "{question}"),
]
self.prompt_template = ChatPromptTemplate.from_messages(messages)
@staticmethod
def _create_vectorstore(dataloader: PdfDataloader) -> Chroma:
"""
Note: OpenAIEmbeddings runs on "text-embedding-ada-002"
"""
embeddings = OpenAIEmbeddings()
return Chroma.from_documents(
documents=dataloader.data,
embedding=embeddings,
persist_directory=".",
)
def retrieve_answer(self, message: MessageDTO) -> dict:
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
docsearch = Chroma.from_texts(
texts=[x.page_content for x in self.dataloader.data],
embedding=embeddings,
metadatas=[x.metadata for x in self.dataloader.data],
)
chain = RetrievalQAWithSourcesChain.from_chain_type(
llm=ChatOpenAI(temperature=0, model_name=self.config.model),
chain_type="stuff",
reduce_k_below_max_tokens=True,
return_source_documents=True,
retriever=docsearch.as_retriever(),
chain_type_kwargs={"prompt": self.prompt_template},
)
return chain.invoke({"question": message.content})
test_rag_service.py
lib/llm/test_rag_service.py
from pathlib import Path
from unittest import TestCase
from config.settings import BASE_DIR
from lib.llm.valueobject.rag import PdfDataloader
class TestPdfDataloader(TestCase):
def test_this_pdf_has_pages_en(self):
file_path = (
Path(BASE_DIR)
/ "lib/llm/pdf_sample/doj_cloud_act_white_paper_2019_04_10.pdf"
)
dataloader = PdfDataloader(str(file_path))
self.assertEqual(18, len(dataloader.pages))
print(dataloader.data)
def test_this_pdf_has_pages_jp(self):
file_path = (
Path(BASE_DIR)
/ "lib/llm/pdf_sample/令和4年版少子化社会対策白書全体版(PDF版).pdf"
)
dataloader = PdfDataloader(str(file_path))
self.assertEqual(6, len(dataloader.pages))
print(dataloader.data)
valueobject/rag.py
lib/llm/valueobject/rag.py
import os
from abc import ABC, abstractmethod
from langchain.schema import Document
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
class Dataloader(ABC):
pages: list[Document] = []
@property
@abstractmethod
def data(self) -> list[Document]:
pass
@abstractmethod
def __init__(self, chunk_size: int = 1000, chunk_overlap: int = 200):
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
@abstractmethod
def _load(self):
"""
See Also: https://python.langchain.com/docs/how_to/document_loader_pdf/
"""
pass
@abstractmethod
def _split(self):
"""
各ページに出典(ページ数)をつけます
"""
pass
def _shredder(self, source: str, attr: str) -> tuple:
"""
日本語PDFでトークンを多く消費するような場合、ページ単位ではAPIが処理できないので
さらに千切りにする
"""
all_splits = self.text_splitter.split_documents(self.pages)
all_text, all_metadata = [], []
for text_fragment in all_splits:
all_text.extend(text_fragment)
all_metadata.extend({"source": source, "attr": attr})
return all_text, all_metadata
class PdfDataloader(Dataloader):
@property
def data(self) -> list[Document]:
return self.pages
def __init__(self, file_path: str):
super().__init__()
self._file_path = file_path
self._load()
self._split()
def _load(self):
# TODO: 非同期化したいね https://python.langchain.com/docs/how_to/document_loader_pdf/#simple-and-fast-text-extraction
self.pages = PyPDFLoader(self._file_path).load()
def _split(self):
filename = os.path.basename(self._file_path)
for i, doc in enumerate(self.pages):
doc.page_content = doc.page_content.replace("\n", " ")
doc.metadata = {"source": f"{filename} {i + 1}ページ"}
class RetrievalQAWithSourcesChainAnswer:
def __init__(
self, question: str, answer: str, sources: str, source_documents: list[Document]
):
self.question = question
self.answer = answer
self.sources = sources
self.source_documents = source_documents
service/chat.py
llm_chat/domain/service/chat.py
:
from config.settings import MEDIA_ROOT, BASE_DIR
from lib.llm.llm_service import (
:
OpenAILlmRagService,
)
:
from lib.llm.valueobject.rag import PdfDataloader, RetrievalQAWithSourcesChainAnswer
:
class OpenAIRagChatService(ChatService):
def __init__(self):
super().__init__()
self.config = OpenAIGptConfig(
api_key=os.getenv("OPENAI_API_KEY"),
temperature=0.5,
max_tokens=4000,
model="gpt-4o-mini",
)
def generate(self, message: MessageDTO):
# Step1: User の質問を保存
self.save(message)
# Step2: langchainからの回答を保存
file_path = (
Path(BASE_DIR)
/ "lib/llm/pdf_sample/令和4年版少子化社会対策白書全体版(PDF版).pdf"
)
answer_dict = OpenAILlmRagService(
config=self.config,
dataloader=PdfDataloader(str(file_path)),
).retrieve_answer(message)
message.role = RoleType.ASSISTANT
message.content = RetrievalQAWithSourcesChainAnswer(**answer_dict).answer
self.save(message)
def save(self, message: MessageDTO) -> None:
message.to_entity().save()
usecase/chat.py
llm_chat/domain/usecase/chat.py
:
OpenAIRagChatService,
)
:
class OpenAIRagUseCase(UseCase):
def execute(self, user: User, content: str | None):
"""
RagServiceを利用し、Pdfをソースに。
contentパラメータは必ずNoneであること。
Args:
user (User): DjangoのUserモデルのインスタンス
content (str | None): この引数は現在利用されていません。
Raises:
ValueError: contentがNoneでない場合
Returns:
音声をテキストに変換した結果
"""
if content is None:
raise ValueError("content cannot be None for OpenAIRagUseCase")
chat_service = OpenAIRagChatService()
message = MessageDTO(
user=user,
role=RoleType.USER,
content=content,
invisible=False,
)
return chat_service.generate(message)
views.py
llm_chat/views.py
:
OpenAIRagUseCase,
)
from llm_chat.forms import UserTextForm
:
if use_case_type == "Gemini":
use_case = GeminiUseCase()
content = form_data["question"]
:
elif use_case_type == "OpenAIRag":
use_case = OpenAIRagUseCase()
content = form_data["question"]
:
まとめ
大事なことは「ChatGPTは一度に扱えるテキストの量に限界がある」ということ。これがために、ページ単位にわけたドキュメントをさらに千切りにする。その千切りにしたデータは、自然言語1に対するmetadata1というかたちで、単に辞書で取り扱われていて、pdfのどこから引用したかというのを紐づけることができる chat/domain/valueobject/pdfdataloader.py のあたりの処理。今回はページでしか割っていないがうまくいったのは英文だったからなのかも。そしたらページ単位に割った後、さらに千切りする必要が出てくるが自然言語とmetadataをペアにして「文書のどこから考えたのか」を人間に示すことができる。
Next Action