QiitaにはQiita 表彰プログラムなるものがあります。
別に「いいね」稼ぎでQiita記事を書いているわけではないものの、何かしら定量目標があったほうが「がんばって書こう」とか「他人に意味あるものを書こう」とかそういう気になるなと思い、まずは10000ContributionのSilverを目指してみようと思いました。
まだ6%ちょっとですね。先は長い。
で、目指すうえでふと疑問に思ったのが、Silver受賞者はどのくらいの記事数を書いているんだろうということ。
上の画像のようにいまの自分の投稿が42(これを入れて43)。正直、バズり狙いの記事を書いて、少ない投稿数でContributionを稼ごうみたいなのはやる気が無いものの、「このくらいは書かねば」の目安があるといいなと思い、ちょうどQiita APIもあんまり触ったことないからなにかスクリプト書いて調べてみることにしました。
必要な準備
QiitaAPIの個人用アクセストークンを発行して認証
QiitaのAPIが使える状態にしなければなりません。
QiitaのAPIは認証なしでも使えるのですが、単位時間あたりのリクエスト数上限を考慮すると、今回の目的(=Silver受賞者がどのくらいの記事を書いているのか)には足りなさそうだなと思いまして。
認証の方法は以下記事が参考になりました。
Silver受賞者をリスト化
今回の対象となる、Silver受賞者をプログラム中で扱えるようにリスト化しました。頻繁に実行するプログラムではない&受賞者はそれほどリアルタイムに変化しないので、ソースコード中にベタ書きでいいでしょうと判断。
受賞者は以下ページに記載されています。
Qiita 表彰プログラム 受賞者一覧 - Qiita
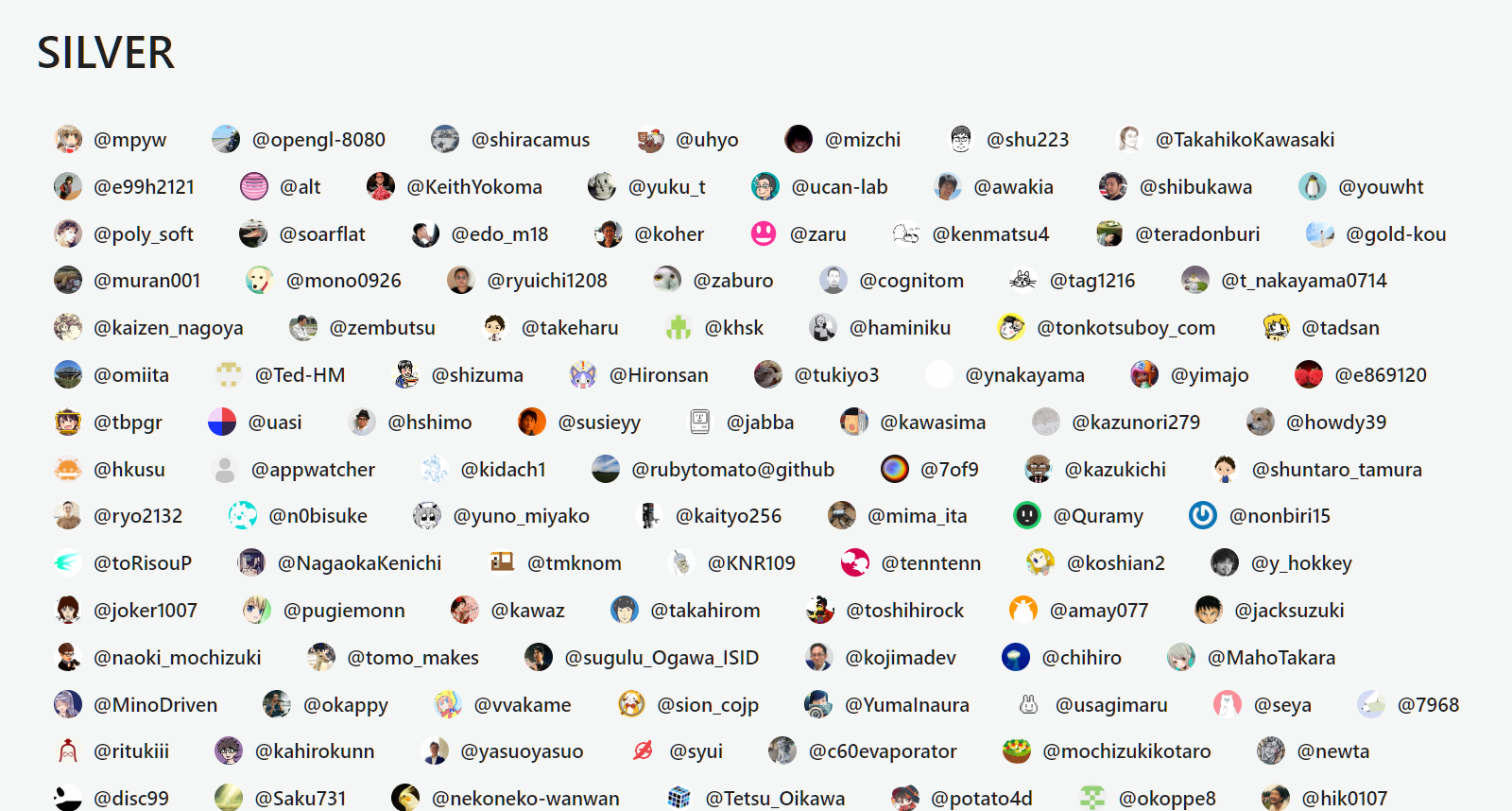
ここからまるっとコピーしてきて、改行やら先頭のアットマークやらを置換して、Pythonのリストにしました。
users = ["mpyw", "opengl-8080", "shiracamus", "uhyo", "mizchi", "shu223", "TakahikoKawasaki", "e99h2121", "alt", "KeithYokoma", "yuku_t", "ucan-lab", "awakia", "shibukawa", "youwht", "poly_soft", "soarflat", "edo_m18", "koher", "zaru", "kenmatsu4", "teradonburi", "gold-kou", "muran001", "mono0926", "ryuichi1208", "zaburo", "cognitom", "tag1216", "t_nakayama0714", "kaizen_nagoya", "zembutsu", "takeharu", "khsk", "haminiku", "tonkotsuboy_com", "tadsan", "omiita", "Ted-HM", "shizuma", "Hironsan", "tukiyo3", "ynakayama", "yimajo", "e869120", "tbpgr", "uasi", "hshimo", "susieyy", "jabba", "kazunori279", "kawasima", "howdy39", "hkusu", "appwatcher", "kidach1", "rubytomato@github", "7of9", "kazukichi", "shuntaro_tamura", "ryo2132", "n0bisuke", "yuno_miyako", "kaityo256", "mima_ita", "Quramy", "nonbiri15", "toRisouP", "NagaokaKenichi", "tmknom", "tenntenn", "koshian2", "KNR109", "y_hokkey", "joker1007", "pugiemonn", "kawaz", "takahirom", "toshihirock", "amay077", "jacksuzuki", "naoki_mochizuki", "tomo_makes",
"sugulu_Ogawa_ISID", "kojimadev", "chihiro", "MahoTakara", "MinoDriven", "okappy", "vvakame", "sion_cojp", "YumaInaura", "usagimaru", "seya", "7968", "ritukiii", "kahirokunn", "yasuoyasuo", "syui", "c60evaporator", "mochizukikotaro", "newta", "disc99", "Saku731", "nekoneko-wanwan", "Tetsu_Oikawa", "potato4d", "okoppe8", "hik0107", "tatesuke", "ryounagaoka", "ukiuni@github", "yuya_presto", "simonritchie", "katsukii", "Jxck_", "KanNishida", "TsutomuNakamura", "bezeklik", "magicant", "kaiinui", "sensuikan1973", "tani_AI_Academy", "scivola", "akameco", "k0kubun", "arowM", "Kta-M", "etaroid", "shimajiri", "aosho235", "y-tsutsu", "koogawa", "jkr_2255", "mogulla3", "yoshizaki_91", "mserizawa", "gogotanaka", "colorrabbit", "erukiti", "saboyutaka", "raccy", "acro5piano", "nesheep5", "niisan-tokyo", "TsuyoshiUshio@github", "terrierscript", "karaage0703", "shtnkgm", "tutinoco", "hashrock", "kazu56", "omochimetaru", "shinmura0", "kohashi", "Hiraku", "gakuri", "nrslib", "okazuki", "yaotti", "daxanya1", "tomoyamachi", "ka215"]
ここでハマったというか、最初失敗した点があり・・・
ユーザー名先頭のアットマークが邪魔だなと思って一括置換で消したんです。そしたらなんと、ユーザー名中にアットマークが入っている人がいるということにあとから気づきました。(使えるんかい)
置換する際には気をつけてください。↑に書いたusers使えば一発ですが。
APIを使ってユーザごとの投稿数を取得する
レスポンスの使用はこちら参照。
Qiita API v2ドキュメント - Qiita:Developer
ほんとうはContributions数も欲しかったのですが、API仕様としてContributions数はとれないので、今回は記事数 items_countだけ。
コードはこんな感じ。
import requests
import json
token = "ご自分のトークン"
headers = {
"Authorization": "Bearer " + token
}
query_base = 'https://qiita.com/api/v2/users/'
users = ["mpyw", "opengl-8080", "shiracamus", "uhyo", "mizchi", "shu223", "TakahikoKawasaki", "e99h2121", "alt", "KeithYokoma", "yuku_t", "ucan-lab", "awakia", "shibukawa", "youwht", "poly_soft", "soarflat", "edo_m18", "koher", "zaru", "kenmatsu4", "teradonburi", "gold-kou", "muran001", "mono0926", "ryuichi1208", "zaburo", "cognitom", "tag1216", "t_nakayama0714", "kaizen_nagoya", "zembutsu", "takeharu", "khsk", "haminiku", "tonkotsuboy_com", "tadsan", "omiita", "Ted-HM", "shizuma", "Hironsan", "tukiyo3", "ynakayama", "yimajo", "e869120", "tbpgr", "uasi", "hshimo", "susieyy", "jabba", "kazunori279", "kawasima", "howdy39", "hkusu", "appwatcher", "kidach1", "rubytomato@github", "7of9", "kazukichi", "shuntaro_tamura", "ryo2132", "n0bisuke", "yuno_miyako", "kaityo256", "mima_ita", "Quramy", "nonbiri15", "toRisouP", "NagaokaKenichi", "tmknom", "tenntenn", "koshian2", "KNR109", "y_hokkey", "joker1007", "pugiemonn", "kawaz", "takahirom", "toshihirock", "amay077", "jacksuzuki", "naoki_mochizuki", "tomo_makes",
"sugulu_Ogawa_ISID", "kojimadev", "chihiro", "MahoTakara", "MinoDriven", "okappy", "vvakame", "sion_cojp", "YumaInaura", "usagimaru", "seya", "7968", "ritukiii", "kahirokunn", "yasuoyasuo", "syui", "c60evaporator", "mochizukikotaro", "newta", "disc99", "Saku731", "nekoneko-wanwan", "Tetsu_Oikawa", "potato4d", "okoppe8", "hik0107", "tatesuke", "ryounagaoka", "ukiuni@github", "yuya_presto", "simonritchie", "katsukii", "Jxck_", "KanNishida", "TsutomuNakamura", "bezeklik", "magicant", "kaiinui", "sensuikan1973", "tani_AI_Academy", "scivola", "akameco", "k0kubun", "arowM", "Kta-M", "etaroid", "shimajiri", "aosho235", "y-tsutsu", "koogawa", "jkr_2255", "mogulla3", "yoshizaki_91", "mserizawa", "gogotanaka", "colorrabbit", "erukiti", "saboyutaka", "raccy", "acro5piano", "nesheep5", "niisan-tokyo", "TsuyoshiUshio@github", "terrierscript", "karaage0703", "shtnkgm", "tutinoco", "hashrock", "kazu56", "omochimetaru", "shinmura0", "kohashi", "Hiraku", "gakuri", "nrslib", "okazuki", "yaotti", "daxanya1", "tomoyamachi", "ka215"]
for username in users:
res = requests.get(query_base + username, headers=headers)
jsondata = json.loads(res.text)
print(jsondata['id'], jsondata['items_count'])
結果を標準出力からコピペ。
mpyw 314
opengl-8080 283
shiracamus 84
uhyo 90
mizchi 268
shu223 218
TakahikoKawasaki 58
e99h2121 433
alt 0
KeithYokoma 143
yuku_t 206
ucan-lab 239
awakia 156
(以下略)
データを整理
Excel使って平均値などを出しました。

6000記事とか4500記事とか書いている人はすぐにマネできないのでアレとしても、平均で213記事くらいでSilver受賞=10000Contributionになっているようでした。
Silverになっても、Gold=50000ContributionにならなければSilverとしてカウントされているので、実際には10000~49999Contributionの人が含まれているわけですが・・・
それはそれとして、Qiita表彰プログラムを受賞しようと思ったら、数百記事は書く必要がありそうです。先は長い。
でもポエムとかお気持ちをQiitaに書くのはポリシーに反する(そういうのは個人ブログに書く)ので、なんらか技術的な内容を積み重ねていくしかないですね。継続継続。
残った疑問
usersをユーザーごとにリクエスト投げていてビミョウなので、もうちょっと減らせないものか。ユーザーに対するOR検索のようなものは見当たらなかった。