はじめに
Apache hadoop の公式イントロダクション "Hadoop Cluster Setup" まで完了していることを前提とします.
YARN クラスタを起動すると,http://[server IP]:[server port] でResource Manager の web UI が立ち上がります.YARN 上で Spark アプリケーションを動かす場合,基本的にの web UI 上でモニタリングすると思います.実行中は下図の「Tracking URL」から実行中のアプリケーションのモニタリング画面に行けます.
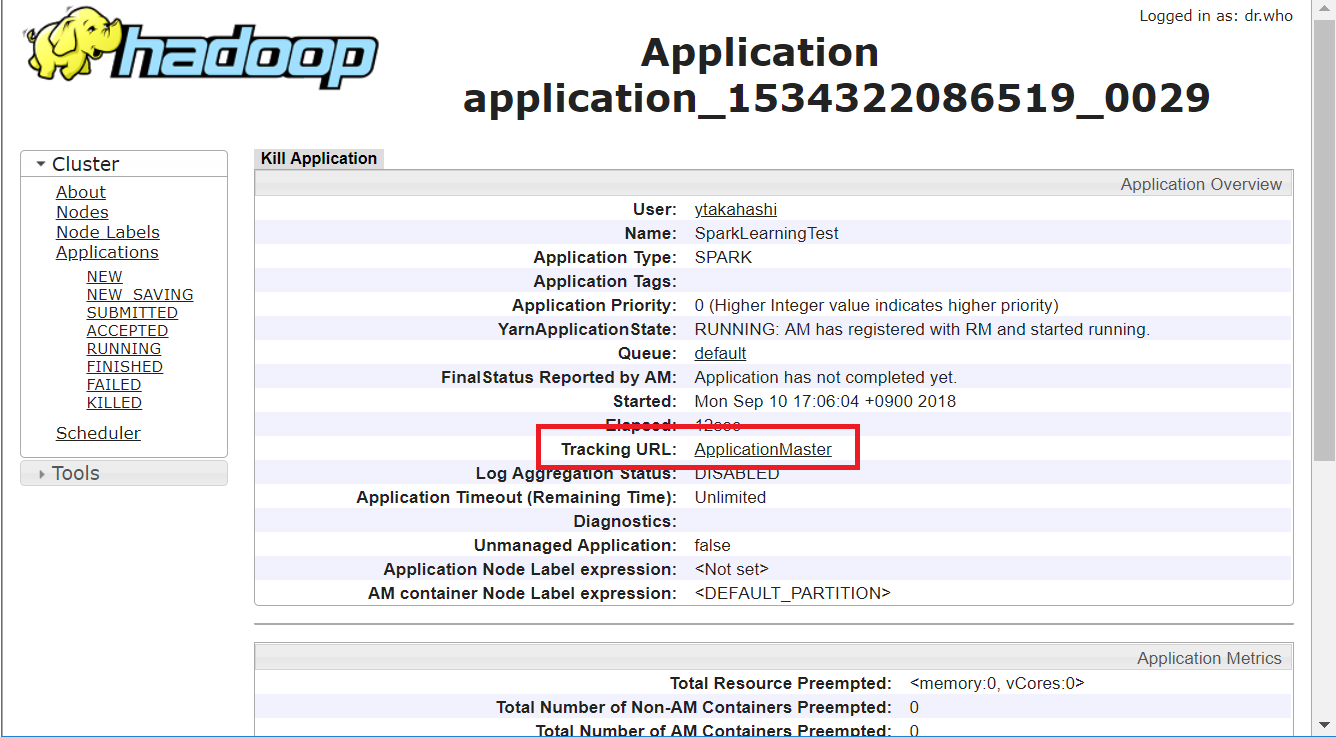
しかし,実行後は同じ「Tracking URL」を押してもモニタリングの画面に行けなくなります.デフォルトでは終了したアプリケーションのモニタリング画面を表示する機能を提供していないのです.ちなみに Hadoop Cluster Setupで紹介されている "MapReduce JobHistory server" というのは実は Spark アプリケーションの jobHistory server とは別物なんですね.なので spark の History server は自分で構築しなければなりません.本記事ではアプリケーション終了後に 「Tracking URL」のリンク先でアプリケーションのモニタリング画面に行ける方法を紹介します.
参考ウェブページ
次のページを参照すれば,本記事を読まなくとも解決できると思います.
設定方法
spark アプリケーションの History server を果たす機能は YARN ではなく,Spark のシステムに組み込まれています.どこかのノードで Spark History server を立ち上げて,これを "Tracking URL" の参照先にリンクさせるイメージで構築します.
Spark History server の立ち上げ
Apache Spark documentation : Monitoring and Instrumentation の "Viewing After the Fact" 項に従って構築します.
基本的には [spark dir]/conf/spark-defaults.conf に三つの項目を設定すればOK.
- spark.eventLog.enabled : 実行後のログを吐き出すか否か
- spark.eventLog.dir : 実行後のログをどこに吐き出すか
- spark.history.fs.logDirectory : history server がどのディレクトリにあるログを読み出すか
オプションで,ポート番号をデフォルトの 18080 から変更できます.
- spark.history.ui.port
設定例
spark.eventLog.enabled true
spark.eventLog.dir file:/work1/ytakahashi/tmp/spark-events
spark.history.fs.logDirectory file:/work1/ytakahashi/tmp/spark-events
サーバを立ち上げます.基本的な使い方ならサーバは1台だけで問題ないと思います.
./[spark dir]/sbin/start-history-server.sh
これにより,アプリケーション終了後に,ウェブブラウザから http://[history server IP]:18080 に接続することでログの一覧を確認できるようになります.
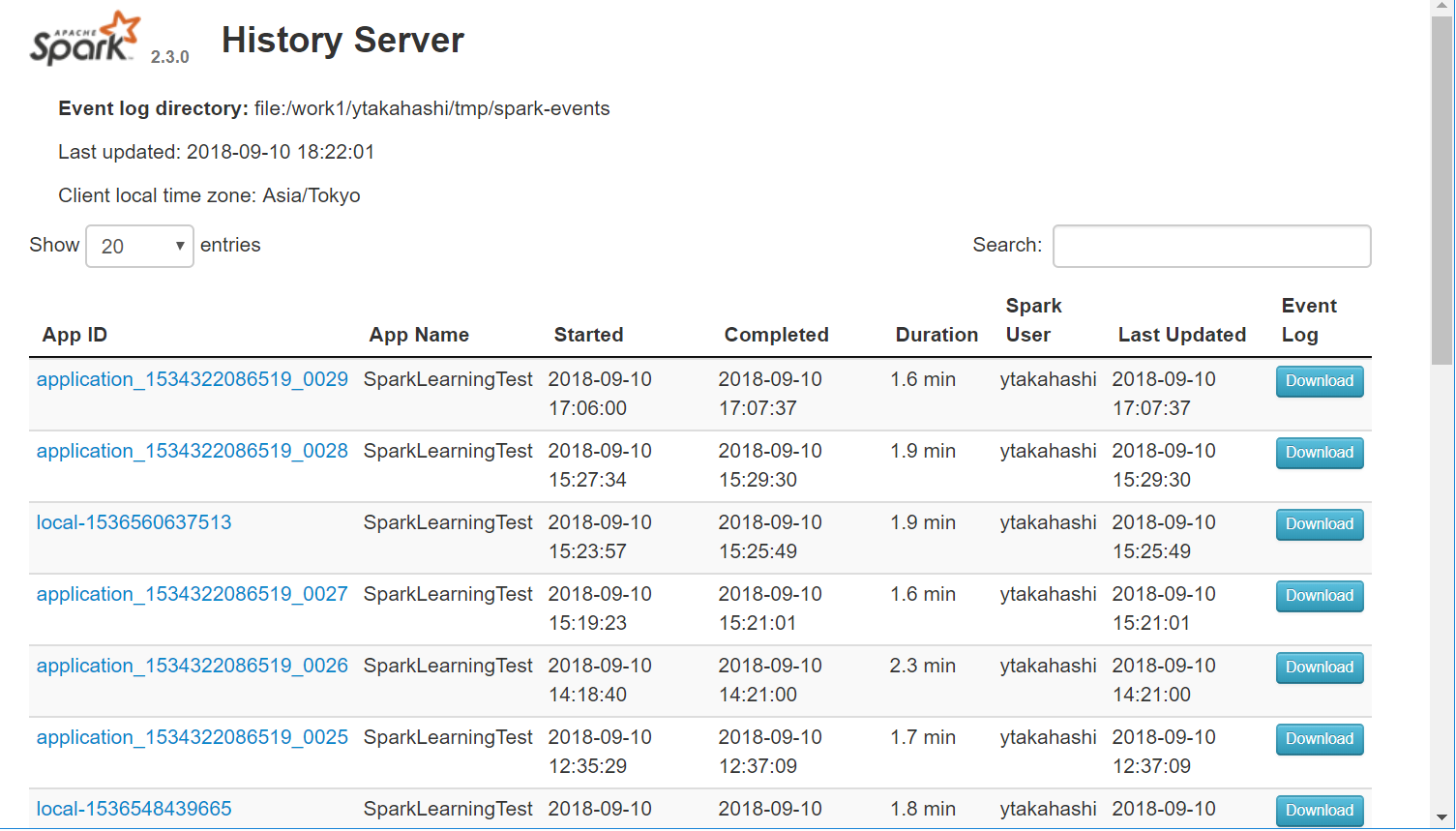
"Tracking URL" の参照先を Spark History server にリンクさせる
Spark History server を立ち上げるだけだとまだ Resource Manager の "Tracking URL" から接続することができません. [spark dir]/conf/spark-defaults.conf を修正することで,Spark から YARN Resource Manager に history server のリンク先を教えてあげることができます.
( cf. cloudera documentation)
spark.yarn.historyServer.address=http://[history server IP]:18080
これで,終了したアプリケーションのモニタリング画面を "Tracking URL" から見れるようになります. http"//[history server IP]:18080 から直接見ることも出来ます.