やりたいこと
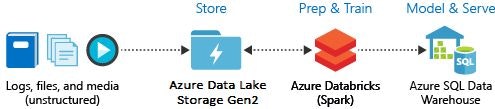
今回、Azure Databricks のチュートリアル「Azure Databricks を使用してデータの抽出、変換、読み込みを行う」を実際にやってみました。やりたいことは以下の図の通りで、Azure Data Lake Storage Gen2 に蓄積したファイルを Azure Databricks が読み取って、何らかの変換を加え、Azure SQL Data Warehouse に格納するというシナリオです。
ETL ツールでも同じことができるので、Azure Databricks を ETL ツールとして利用したシナリオになります。
Azure Databricks とは
Databricks は、UC Berkeley AMLab のメンバーで、Apache Spark の開発チームによって 2013 年に設立されました。これを Microsoft の 1st Party の PaaS として提供しているのが Azure Databricks となります。
つまり、Azure Databricks は、Microsoft Azure クラウドサービスプラットフォームに最適化された Apache Spark ベースの分析プラットフォームとなります。詳細はこちらを参照いただくのが良いですが、特長をいくつか紹介したいと思います。
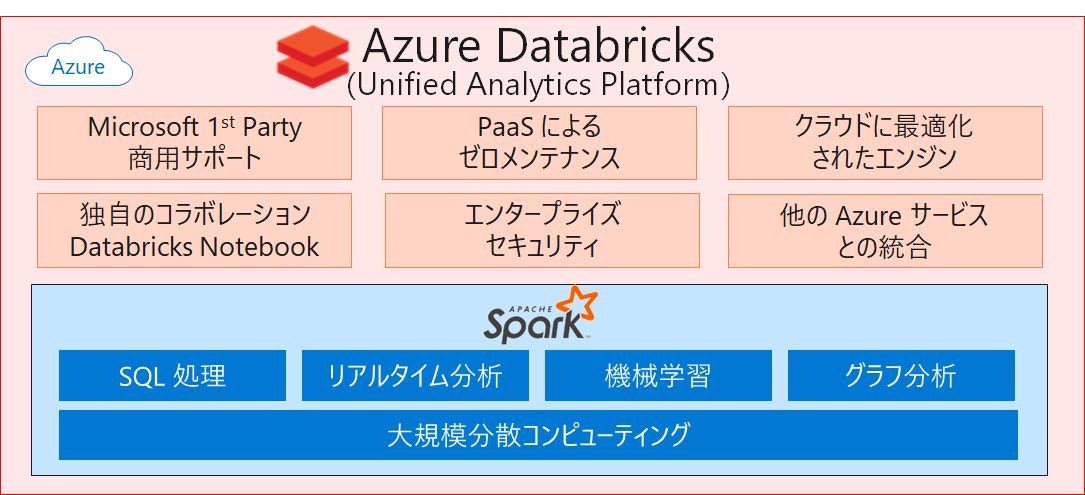
主な特長
- 使い慣れた言語が利用可能(Python、R、Scala、Java、SQL)
- 500 以上のビルトインされたライブラリが利用可能(TensorFlow、PYTORCH、Keras など)
- 環境構築にかかるコストと時間の大幅な削減(10分ほどでマルチクラスター環境の構築が可能)
- オートスケール/オートターミネーション
- Azure の各種サービスとの統合
Azure Databricks で実現できること
主な利用シナリオは以下の3つになると思います。
1) バッチ分析
限られた時間で大量データを処理したい場合に選択する。
数 GB から数百 PB におよぶデータを加工・集計して DWH システムへロードするようなケースで使用。
ETL 処理に近く、今回の内容はこのパターンになります。
2) 準リアルタイム分析
データの生成から遅延時間を最小限にした分析をしたい場合に選択する。
POS システム、EC サイト、IoT データなどのデータをストリームデータとして即座に収集し、データを加工・集計して可視化するようなケースで使用。
3) 高度な分析
蓄積された大量データを活用して高度な分析を実施したい場合に選択する。
機械学習や深層学習を行うようなケースで使用。
前提条件
- アクティブな Azure サブスクリプション
- SSMS(SQL Server Management Studio) が利用できること
- お持ちでない方はSSMS のダウンロードサイトよりダウンロードしてください
手順
今回は以下の5つの手順で実施します。
- Azure SQL Data Warehouse の作成
- Azure Blob Storage アカウントの作成
- Azure Data Lake Storage Gen2 ストレージアカウントの作成
- サービスプリンシパルの作成
- Azure Databricks の作成
それでは実際にはじめてみましょう。
1) Azure SQL Data Warehouse の作成
最初に Azure SQL Data Warehouse を作成します。
Azure Portal の画面が少し変わりましたが、左上にある三本の横線をクリックすると、メニューが出てくるので、「リソースの作成」をクリックします。
次に、「データベース」、「SQL Data Warehouse」をクリックします。
SQL Data Warehouse の基本情報を入力する画面が表示されます。
| 設定項目 | 設定値 |
|---|---|
| サブスクリプション | お持ちのサブスクリプションを選択。 |
| リソースグループ | 新規作成の場合は、下にある青字の「新規作成」を選択し、任意の名称を入力。既存のものがある場合は選択。 |
| データウェアハウス名 | 任意の名称を入力(ここでは「myDWH」とした)。(緑のチェックマークが出ればOK) |
| サーバー | 新規作成の場合は、下にある青字の「新規作成」を選択し、「新しいサーバー」を設定。既存のものがある場合は選択。 |
| パフォーマンスレベル | 適切なパフォーマンスレベルを選択。 |
新しいサーバーの設定項目と設定値は以下のとおり。入力後「OK」をクリックする。
| 設定項目 | 設定値 |
|---|---|
| サーバー名 | 任意の名称を入力(ここでは「mysqldwhserver」とした)。(緑のチェックマークが出ればOK) |
| サーバー管理者ログイン | 任意の名称を入力。(緑のチェックマークが出ればOK) |
| パスワード/パスワードの確認 | 任意のパスワードを入力。(緑のチェックマークが出ればOK) |
| 場所 | 任意の場所を選択。 |
| Azure サービスにサーバーへのアクセスを許可する | 「✔」(チェック)する。 |
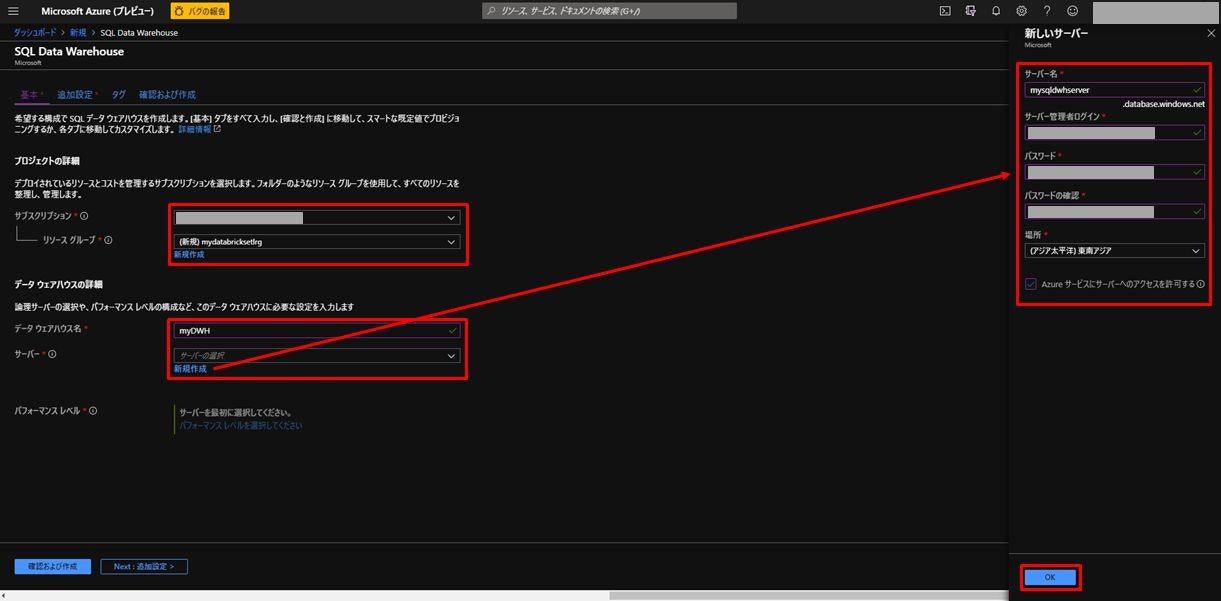
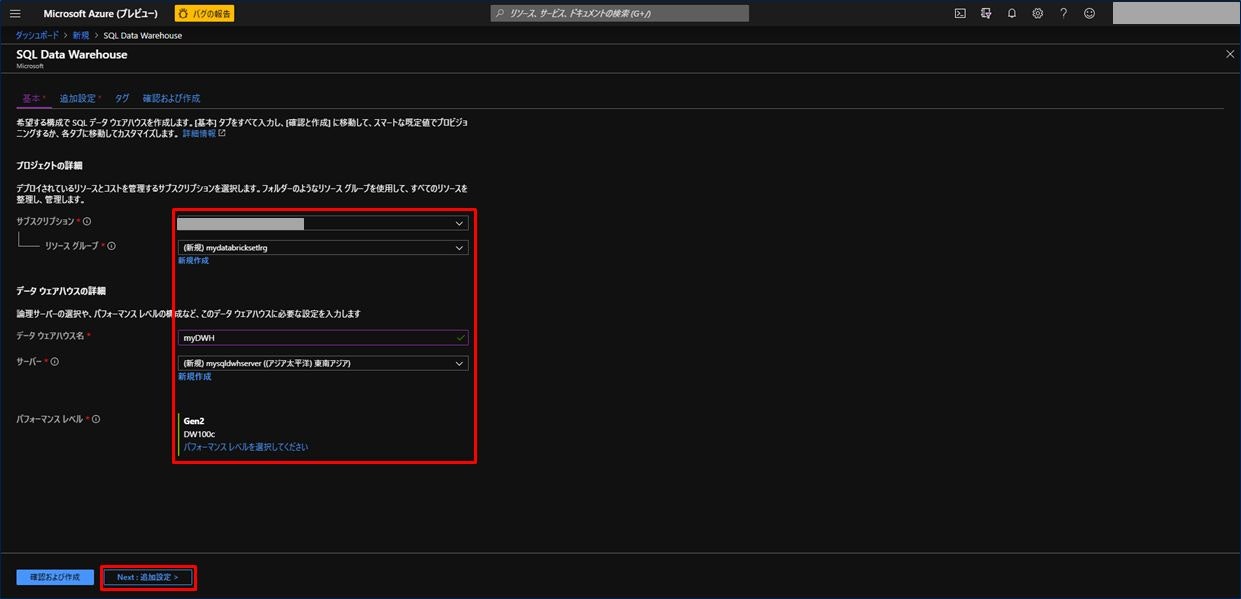
パフォーマンスレベルは、今回は最小の「DW100c」で設定。すべて入力後「Next : 追加設定 >」をクリックする。
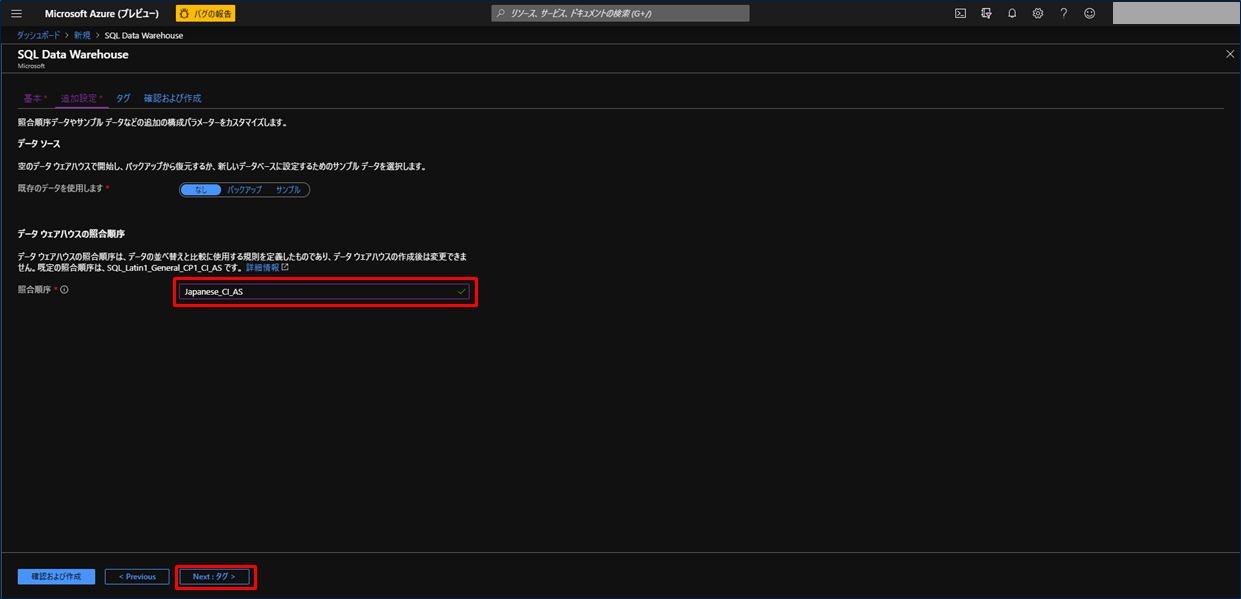
追加設定では照合順序の設定を行う。これは一度設定すると変更ができないので注意すること。
今回は「Japanese_CI_AS」とした。照合順序はこちらを参照してください。
すべて設定後「Next : タグ > 」をクリックする。
タグの画面ではデフォルトのままで良いので、「Next : 確認および作成 > 」をクリックする。
これまでの設定内容を確認し、問題なければ「作成」をクリックして SQL Data Warehouse を作成する。5分ほど時間がかかります。
作成が完了し、「すべてのリソース」を開くと以下の2つが作成されていることが確認できます。
複数サブスクリプションをお持ちの方は、SQL Data Warehouse を作成したサブスクリプションを選択してください。
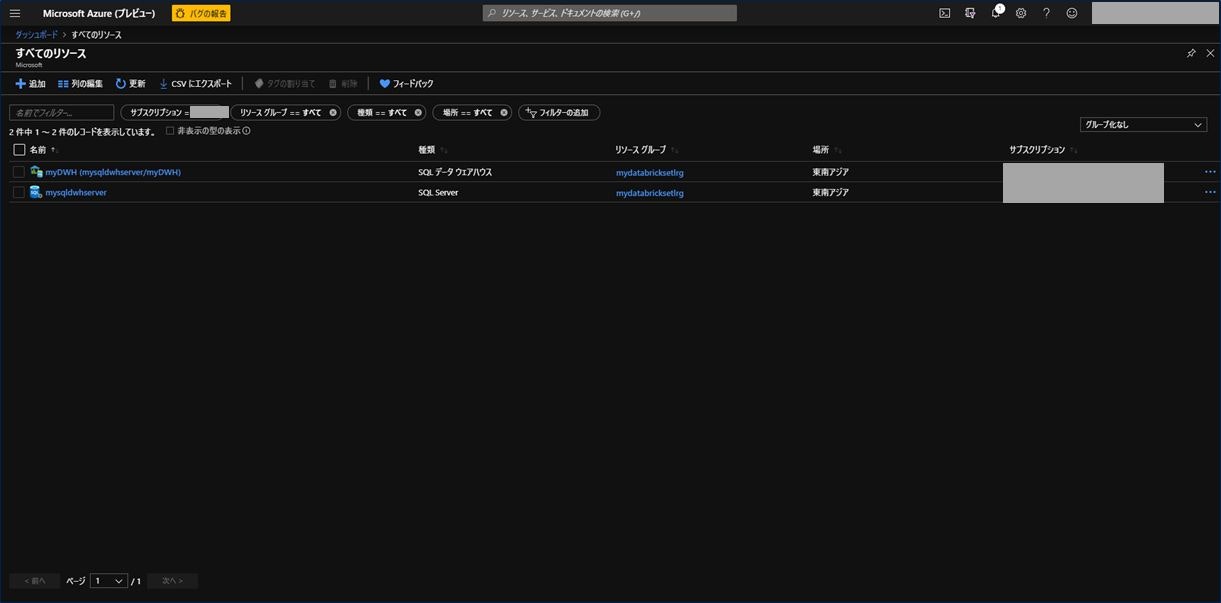
このあと、以下2つの手順を実施します。
1-1) サーバーレベルのファイアウォール規則を作成
1-2) データベースマスターキーを作成
1-1) サーバーレベルのファイアウォール規則を作成
「クイック スタート:Azure portal で Azure SQL Data Warehouse を作成し、クエリを実行する」を参照すると、以下の記載があります。そのため、クライアント端末からアクセスできるように、「クライアント IP の追加」を実施しておきます。
SQL Data Warehouse サービスでは、サーバーレベルでファイアウォールが作成されます。 このファイアウォールにより、外部のアプリケーションとツールはサーバーやサーバー上のすべてのデータベースに接続できなくなります。 接続できるようにするには、特定の IP アドレスに接続を許可するファイアウォール規則を追加します。
先ほど作成した SQL Data Warehouse のサーバーをクリックします。
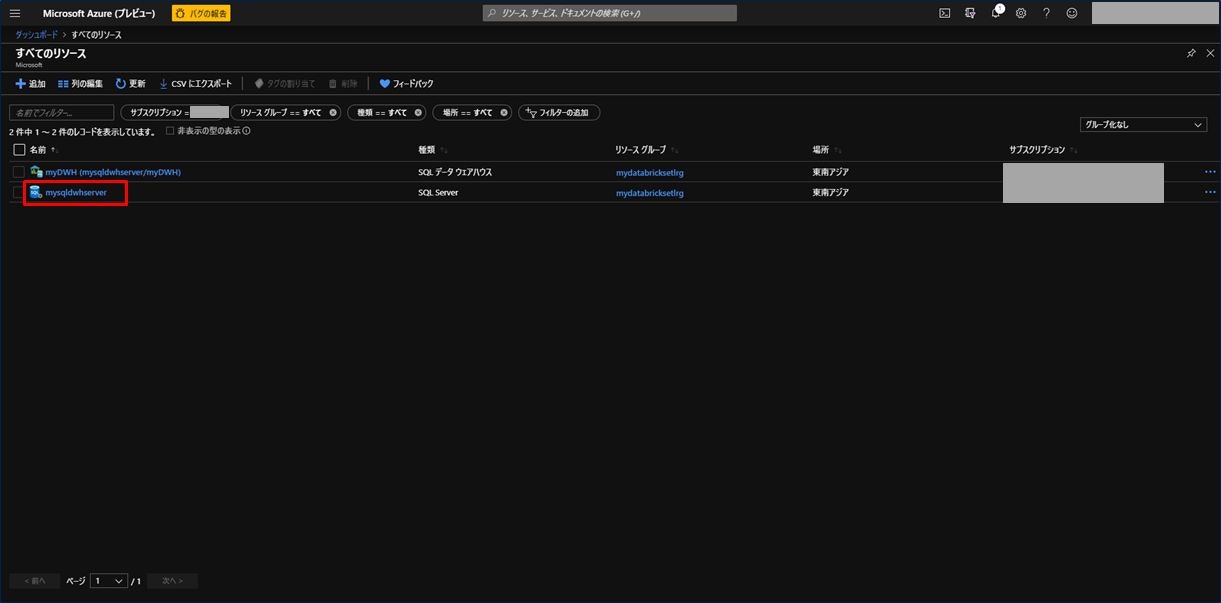
サーバーの概要ページが表示されます。右上のほうに青字で「ファイアウォール設定の表示」とあるので、これをクリックします。
画面中央上部に「+クライアント IP の追加」という項目があるので、ここをクリックし、その後「保存」をクリックします。
画面中央に「ClientIPAddress_・・・」という設定項目が保存されたら OK です。
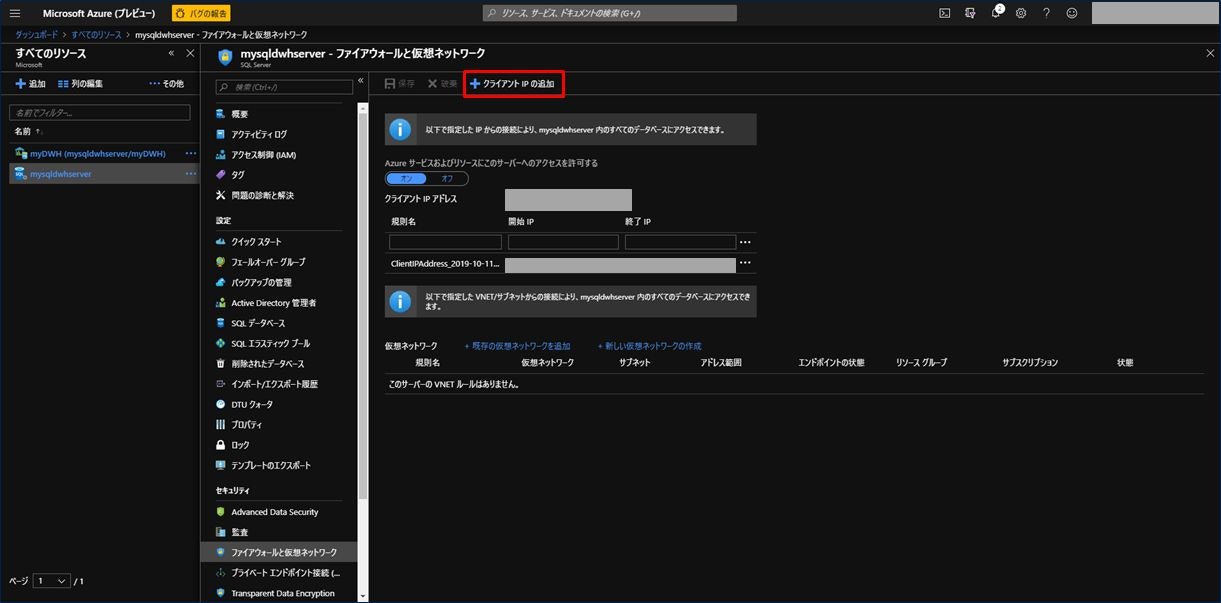
これでファイアウォールの設定ができたので、クライアント PC から SQL Data Warehouse に接続することができるようになりました。
1-2) データベースマスターキーを作成
次に、データベースマスターキーを作成します。ここでは SSMS(SQL Server Management Studio) を使って作業を行います。
SSMS をお持ちでない方は、こちらのSSMS のダウンロードサイトよりダウンロードしてください。
最初に接続する SQL Data Warehouse の完全修飾サーバー名を取得します。
「すべてのリソース」から「SQL Data Warehouse 名(ここでは myDWH)」をクリックします。
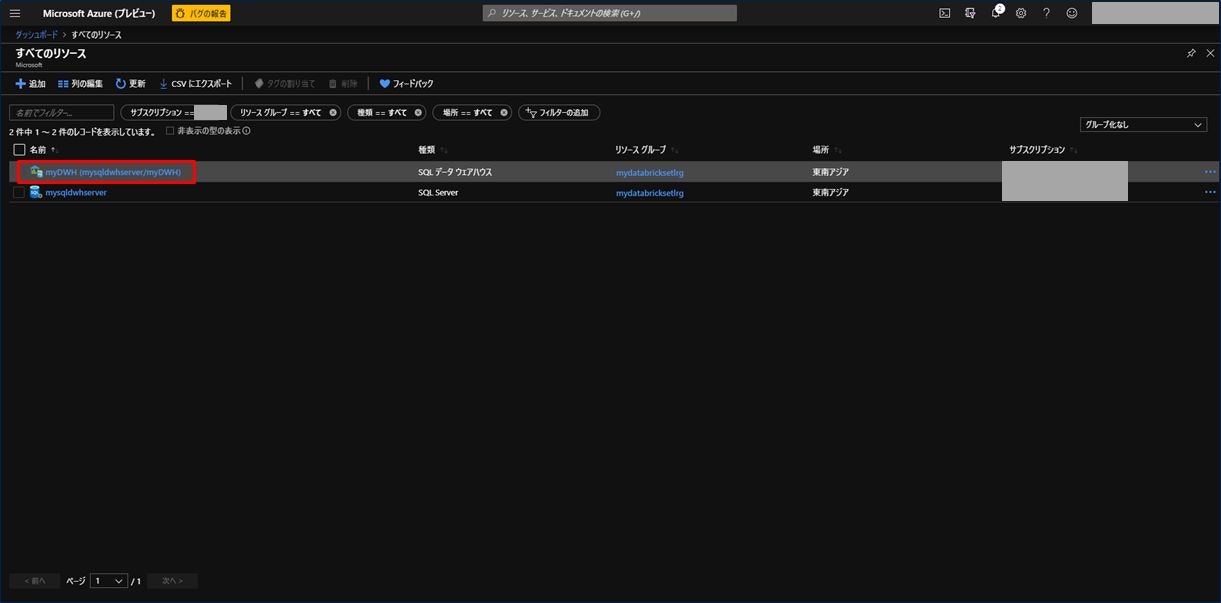
SQL Data Warehouse の概要ページが表示されます。右上にあるサーバー名「mysqldwhserver.database.windows.net」をコピーします。
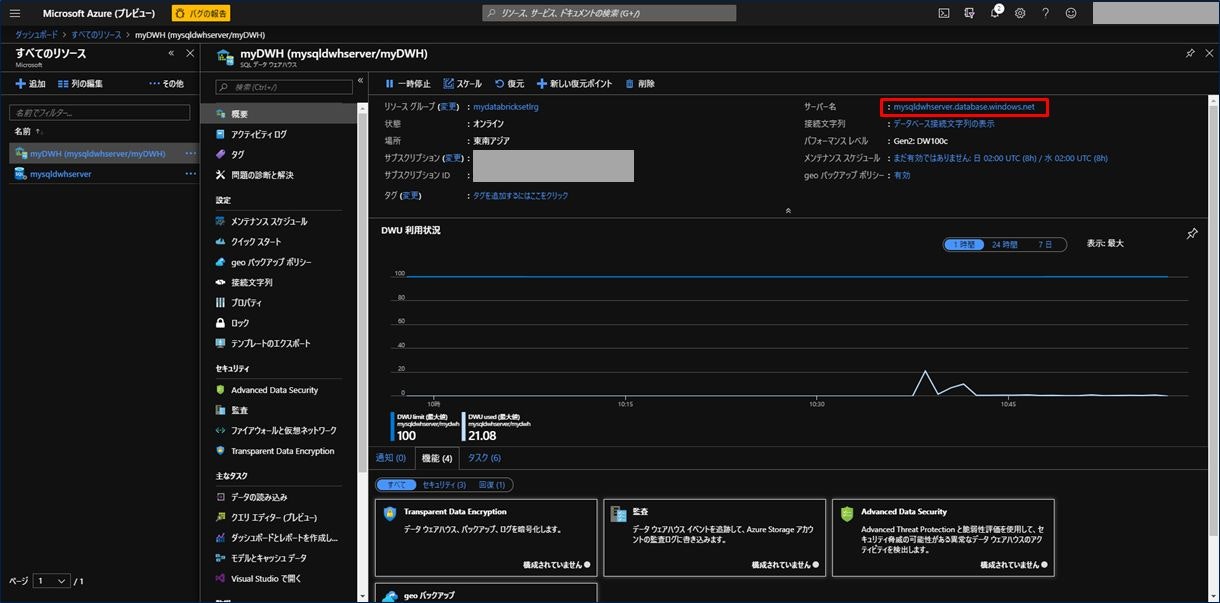
SSMS を起動し、サーバー名に「mysqldwhserver.database.windows.net」をコピーし、認証方法は「SQL Server 認証」を選択、ログインとパスワードは SQL Data Warehouse を作成した際に入力したものを使って「接続」します。
接続できると、左のメニューに、「データベース」と「セキュリティ」が表示されます。
データベースマスターキーを作成するためには、データベースに対する CONTROL 権限が必要になるので、まずは CONTROL 権限を付与するユーザを作成します。詳細はこちらを参照してください。
-- Connect to master database and create a login
CREATE LOGIN ApplicationLogin WITH PASSWORD = 'Str0ng_password';
CREATE USER ApplicationUser FOR LOGIN ApplicationLogin;
上記の「ApplicationLogin」と「ApplicationUser」を任意の名称に変更し、「PASSWORD」を任意のパスワードを設定します。変更した SQL 文を SSMS で実行します。
- SSMS の左メニューで、「データベース」→「システムデータベース」→「master」とクリックして開きます。
- 「master」上で右クリックし、「新しいクエリ(Q)」をクリックし、クエリ実行用の画面を表示します。
- ここに SQL 文をコピーし、上部のメニューバーの「実行」をクリックすると SQL 文が実行されます。
ここでは、「ApplicationLogin」は「nabeLogin」、「ApplicationUser」は「nabeUser」として実行しています。
SSMS の左メニューで「データベース」→「システムデータベース」→「master」→「セキュリティ」→「ユーザー」と開くと、「nabeUser」が作成されていることが確認できます。
同様に、「セキュリティ」→「ログイン」と開くと、「nabeLogin」が作成されていることが確認できます。
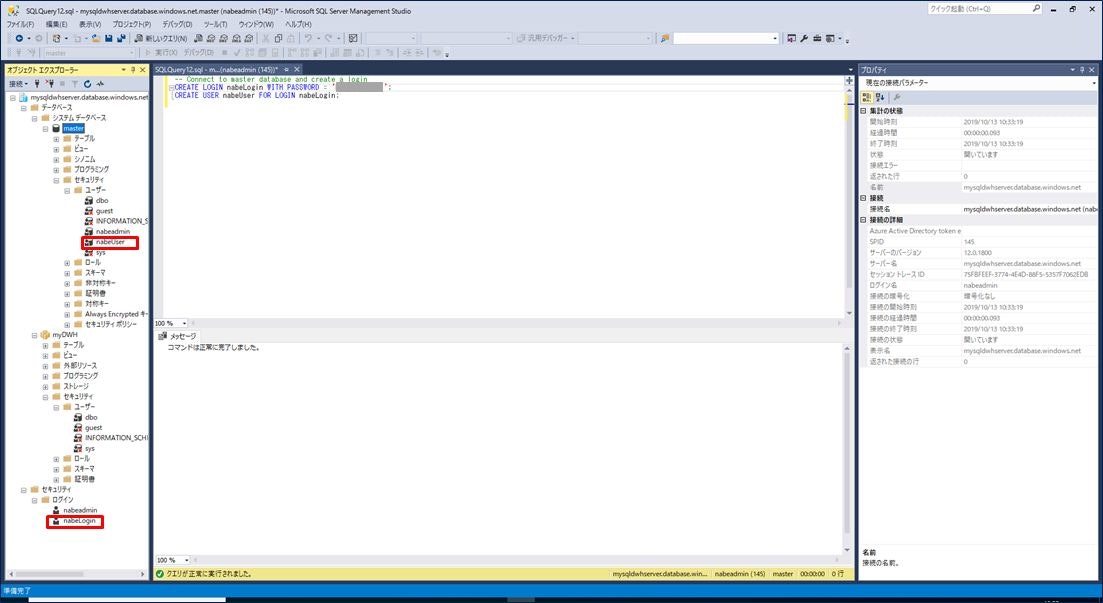
次に、SQL Data Warehouse データベースにユーザーを追加します。ユーザー追加の SQL 文は以下となります。
先ほどと同様で、「ApplicationLogin」と「ApplicationUser」を先ほど設定した値に変更して実行します。
-- Connect to SQL DW database and create a database user
CREATE USER ApplicationUser FOR LOGIN ApplicationLogin;
- SSMS の左メニューで、「データベース」→「myDWH」とクリックして開きます。
- 「myDWH」上で右クリックし、「新しいクエリ(Q)」をクリックし、クエリ実行用の画面を表示します。
- ここに SQL 文をコピーし、上部のメニューバーの「実行」をクリックすると SQL 文が実行されます。
SSMS の左メニューで「データベース」→「myDWH」→「セキュリティ」→「ユーザー」と開くと、「nabeUser」が作成されていることが確認できます。これで CONTROL 権限を付与するユーザが作成できました。
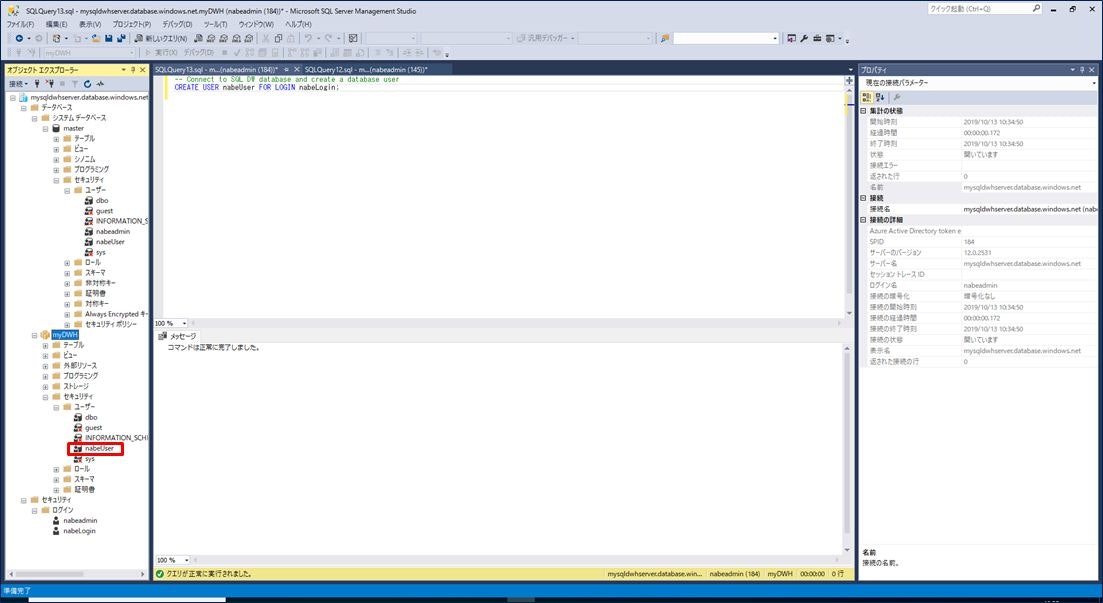
次に、CONTROL 権限を付与します。CONTROL 権限を付与する SQL 文は以下となります。
こちらのサイトに、「D.データベースユーザに CONTROL 権限を許可する」例がありますので参考にしてください。
GRANT CONTROL ON DATABASE::DatabaseName TO ApplicationUser;
GO
1つ前の手順で使った SSMS のクエリ画面に SQL 文をコピーし、上部のメニューバーの「実行」をクリックします。
ここでは、「DatabaseName」は「myDWH」、「ApplicationUser」は「nabeUser」として実行しています。
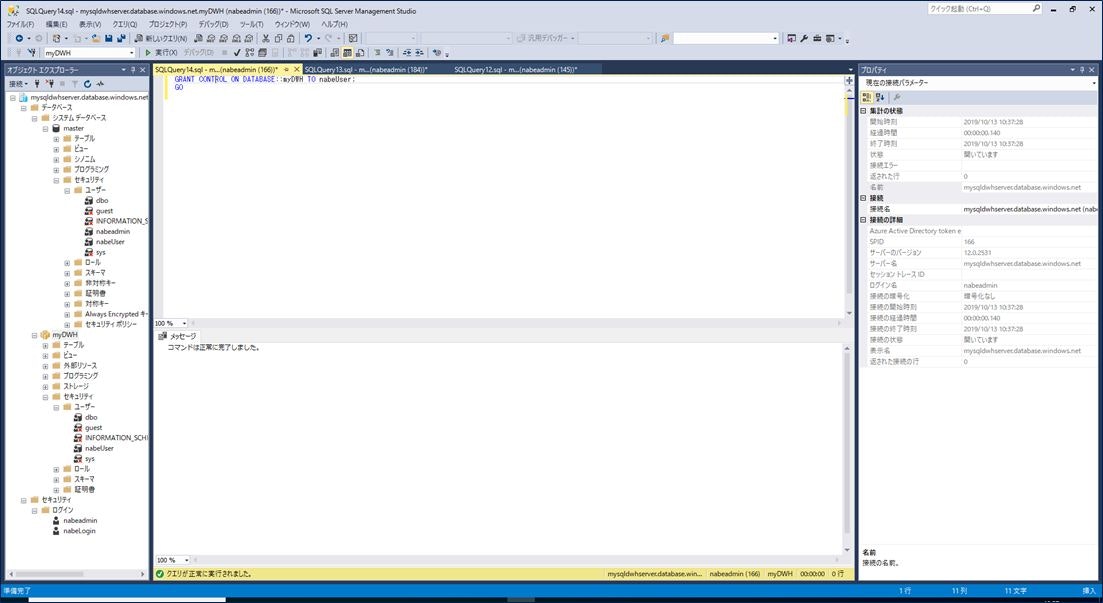
最後にマスターキーを作成します。詳細はこちらに例がありますので参考にしてください。
-- Creates the master key.
-- The key is encrypted using the password "23987hxJ#KL95234nl0zBe."
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '23987hxJ#KL95234nl0zBe';
先ほどと同じ SSMS のクエリ画面に SQL 文をコピーし、上部のメニューバーの「実行」をクリックします。
「PASSWORD」は任意のものを設定してください。
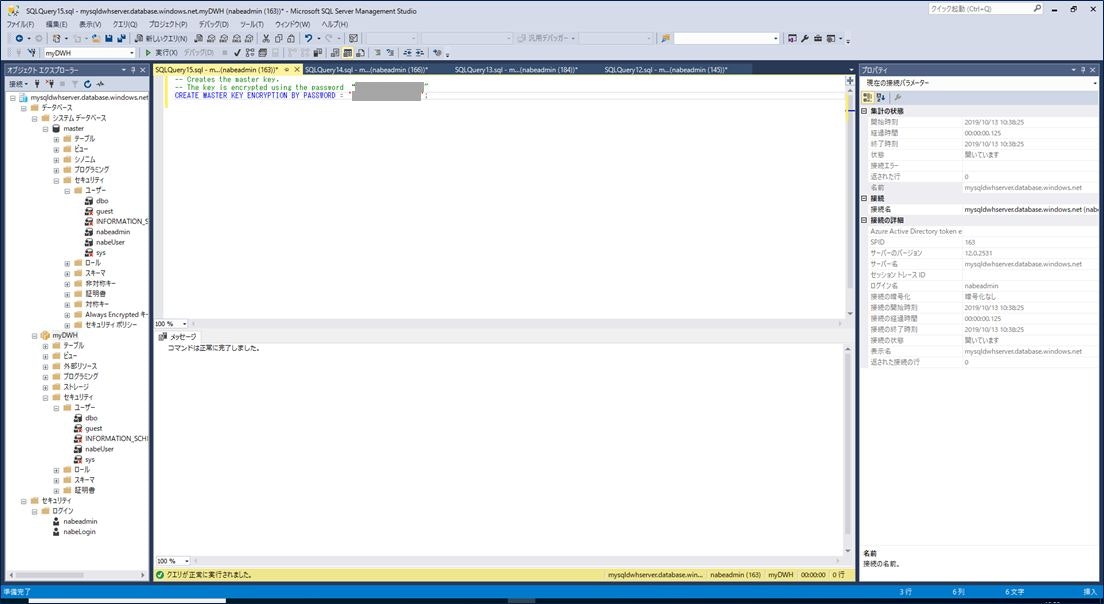
これでデータベースマスターキーを作成できました。
ここまでで SQL Data Warehouse の手順が完了です。
2) Azure Blob Storage アカウントの作成
2番目の手順は、Azure Storage アカウントの作成です。
左上の三本の横線から「リソースの作成」をクリックし、画面にある「ストレージアカウント」をクリックします。
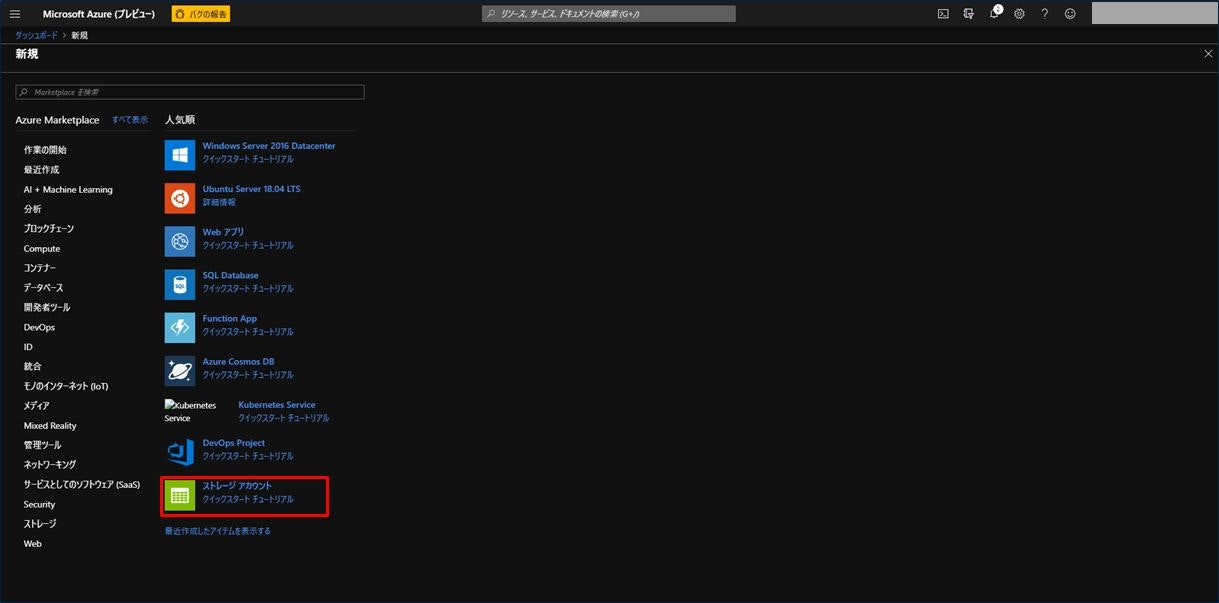
ストレージアカウントを作成するための基本情報入力画面が表示されます。項目を入力後、「次 : ネットワーク >」をクリックします。
Azure Storage アカウントについて詳細は、こちらを参照してください。
| 設定項目 | 設定値 |
|---|---|
| サブスクリプション | お持ちのサブスクリプションを選択。 |
| リソースグループ | 手順 1) で作成したリソースグループを選択。 |
| ストレージアカウント名 | 任意の名称を入力。(緑のチェックマークが出ればOK) |
| 場所 | 任意の場所を選択。可能な限り手順 1) で作成した場所と同じ場所を選択。 |
| パフォーマンス | Standard か Premium を選択。ここでは「Standard」を選択。 |
| アカウントの種類 | Storage2(汎用 v2) を選択。 |
| レプリケーション | ローカル冗長ストレージ(LRS) を選択。 |
| アクセス層(既定) | クール か ホット を選択。ここでは「ホット」を選択。 |
ネットワークの設定画面はデフォルトのままで良いです。「次 : 詳細 >」をクリックします。
次に詳細画面が表示されます。ここもデフォルトのままで良いです。「次 : タグ >」をクリックします。
タグの画面もデフォルトのままで良いので、「次 : 確認および作成 >」をクリックします。
これまで設定した内容を確認し、問題なければ「作成」をクリックします。
ストレージアカウントが作成されました。次に Blob コンテナ―を作成します。ストレージアカウントをクリックします。
画面中央に表示される「コンテナ―」をクリックします。
画面上部に表示される「+コンテナ―」をクリックします。
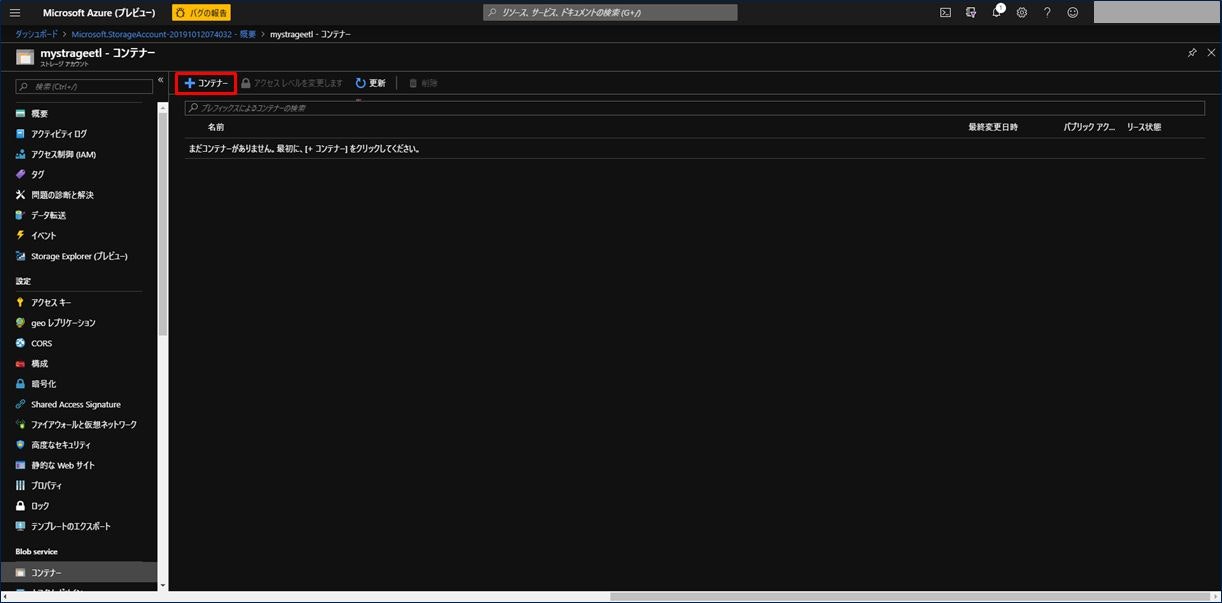
新しいコンテナ―の名前を入力し、「OK」をクリックします。
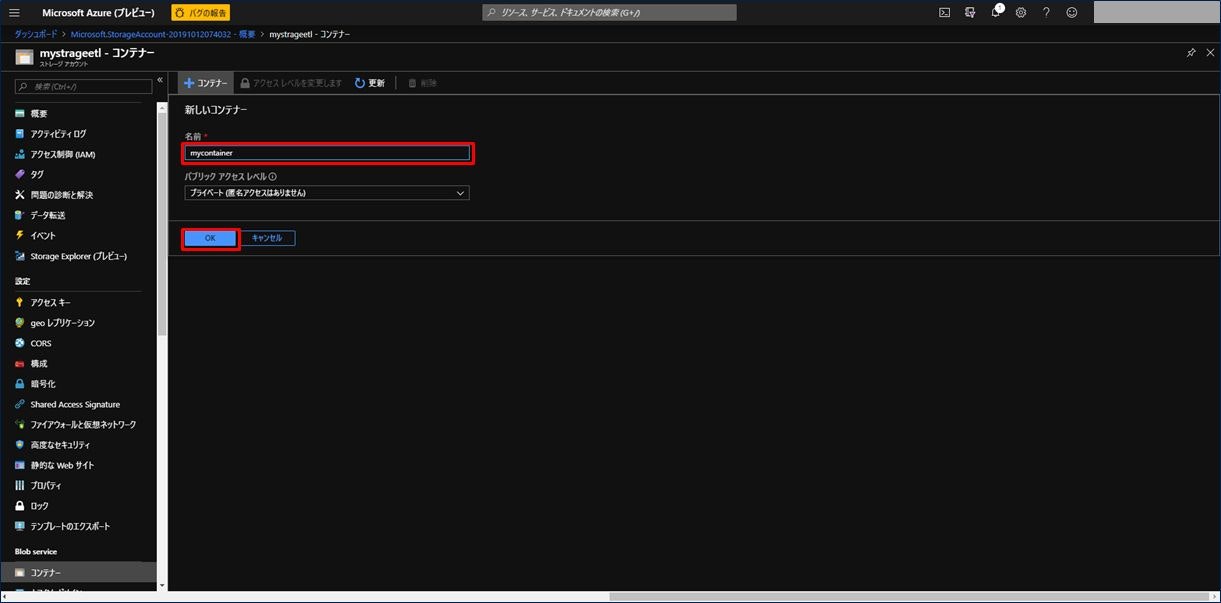
これで Blob コンテナ―が作成されました。Azure Blob Storage アカウントの作成手順は以上になります。
3) Azure Data Lake Storage Gen2 ストレージアカウントの作成
3番目の手順は、Azure Data Lake Storage Gen2 のストレージアカウントの作成になります。これは、2) の手順と重複する部分が多いですが、手順通りキャプチャーを掲載しておきます。
左上の三本の横線から「リソースの作成」をクリックし、画面にある「ストレージアカウント」をクリックします。
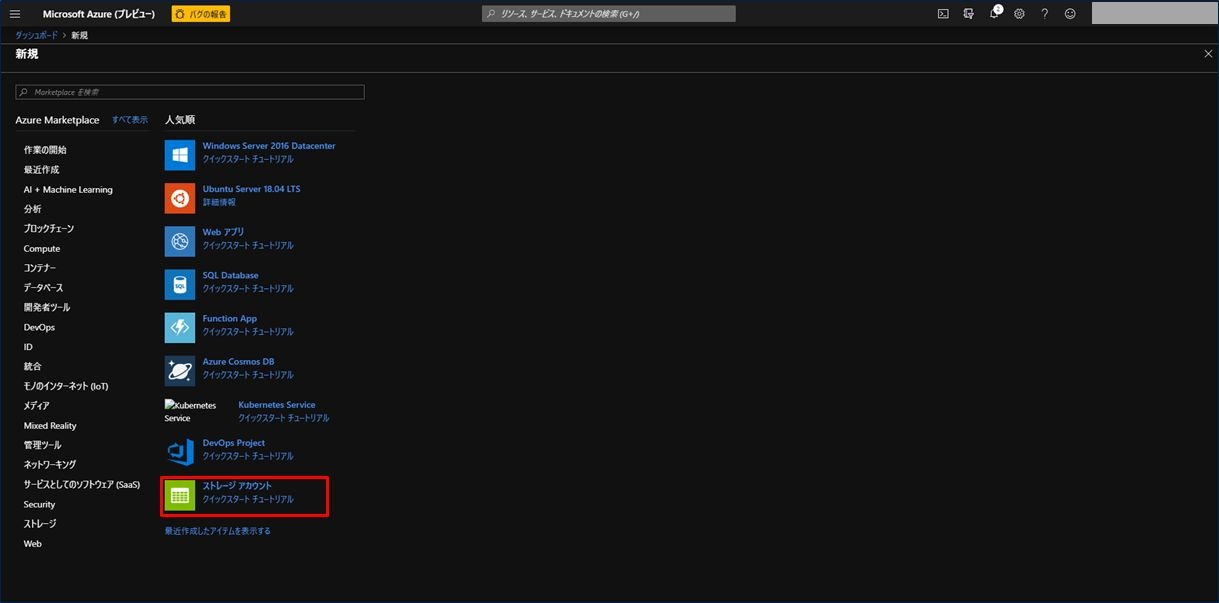
ストレージアカウントを作成するための基本情報入力画面が表示されます。項目を入力後、「次 : ネットワーク >」をクリックします。ここは、2) の手順と同様です。ストレージアカウント名は 2) と異なるものを設定してください。
| 設定項目 | 設定値 |
|---|---|
| サブスクリプション | お持ちのサブスクリプションを選択。 |
| リソースグループ | 手順 1) で作成したリソースグループを選択。 |
| ストレージアカウント名 | 任意の名称を入力。(緑のチェックマークが出ればOK) |
| 場所 | 任意の場所を選択。可能な限り手順 1) で作成した場所と同じ場所を選択。 |
| パフォーマンス | Standard か Premium を選択。ここでは「Standard」を選択。 |
| アカウントの種類 | Storage2(汎用 v2) を選択。 |
| レプリケーション | ローカル冗長ストレージ(LRS) を選択。 |
| アクセス層(既定) | クール か ホット を選択。ここでは「ホット」を選択。 |
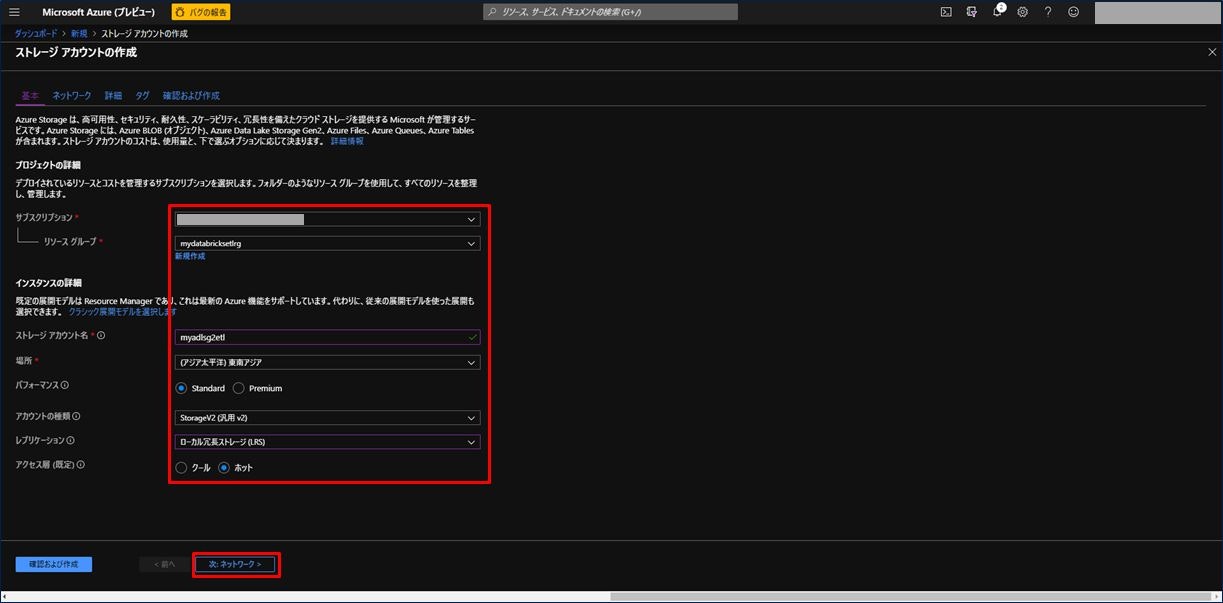
ネットワークの設定画面はデフォルトのままで良いです。「次 : 詳細 >」をクリックします。
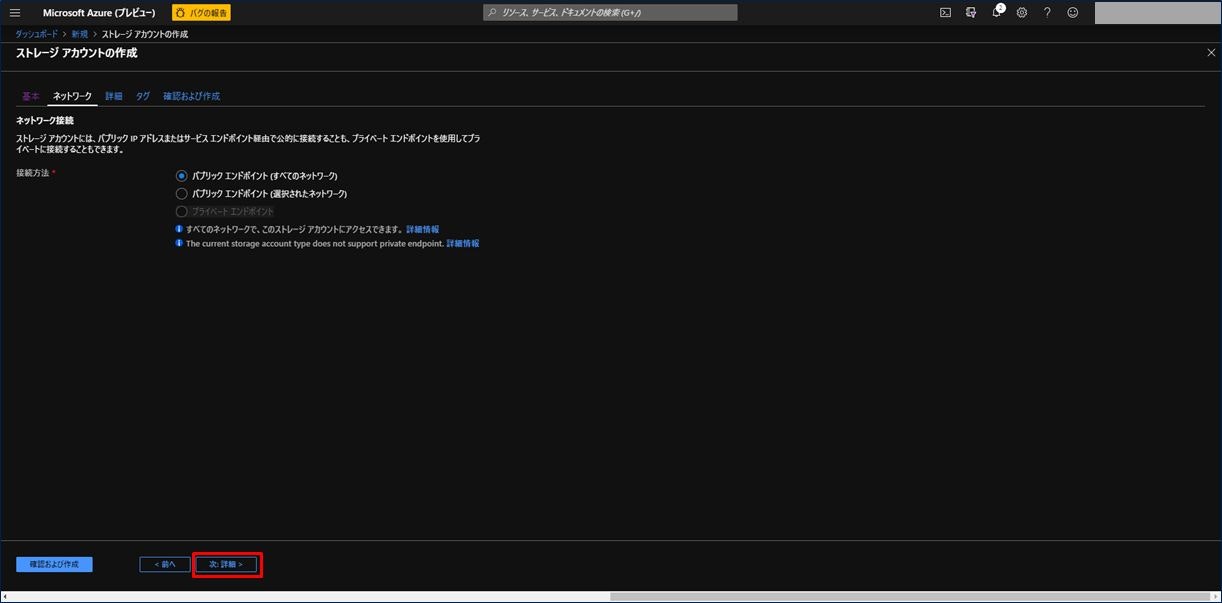
次に詳細画面が表示されます。ここで、3つ目の「Data Lake Storage Gen2」の項目で「有効」を選択します。この手順が 2) と違う点です。「次 : タグ >」をクリックします。
タグの画面はデフォルトのままで良いので、「次 : 確認および作成 >」をクリックします。
これまで設定した内容を確認し、問題なければ「作成」をクリックします。
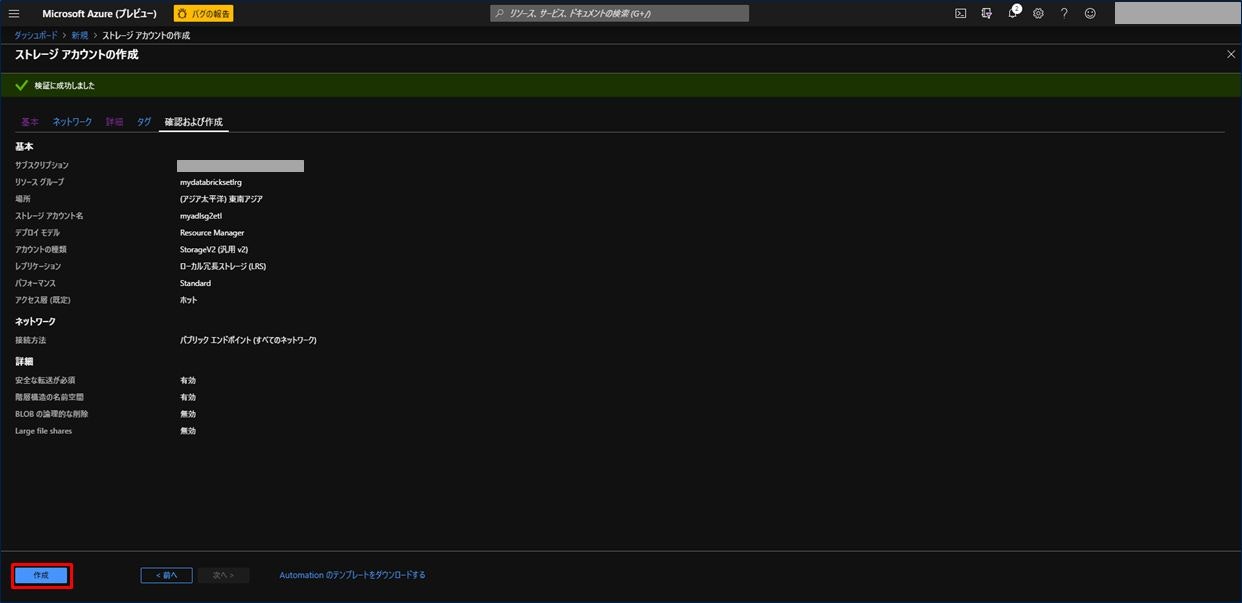
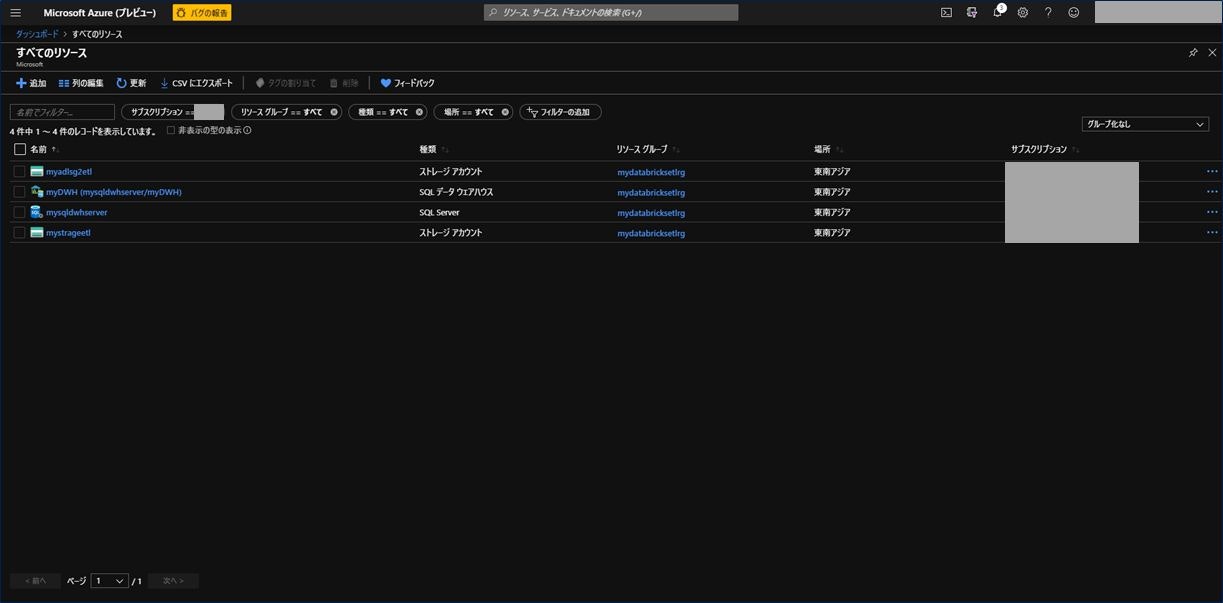
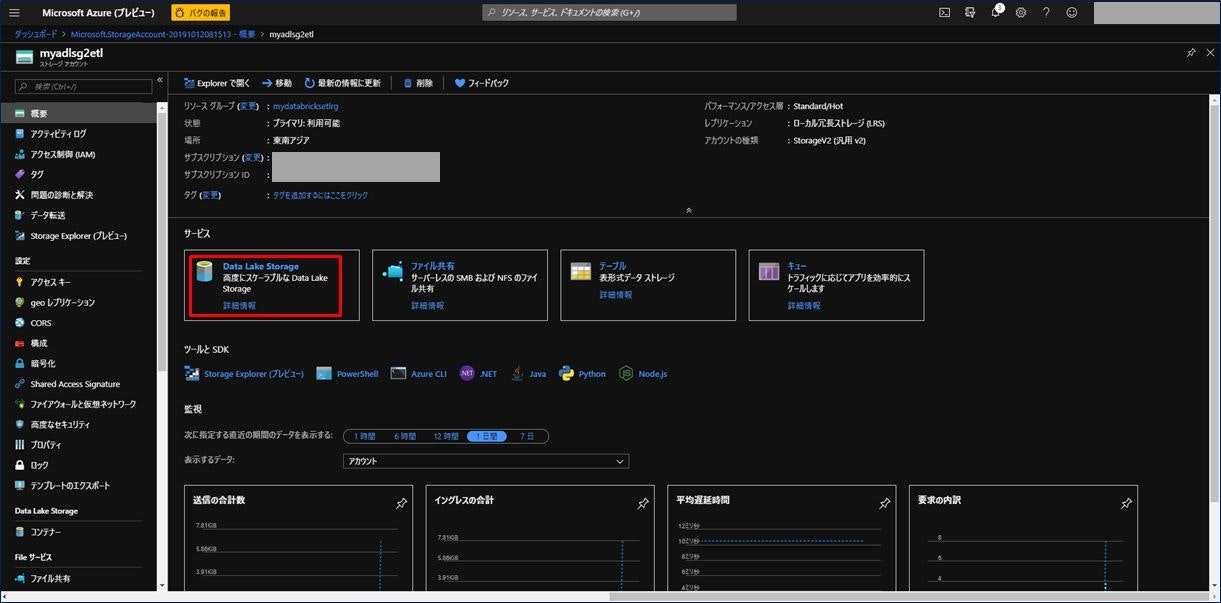
Azure Data Lake Storage Gen2 ストレージアカウントが作成されました。次にファイルシステムを作成します。Azure Data Lake Storage Gen2 ストレージアカウントをクリックします。
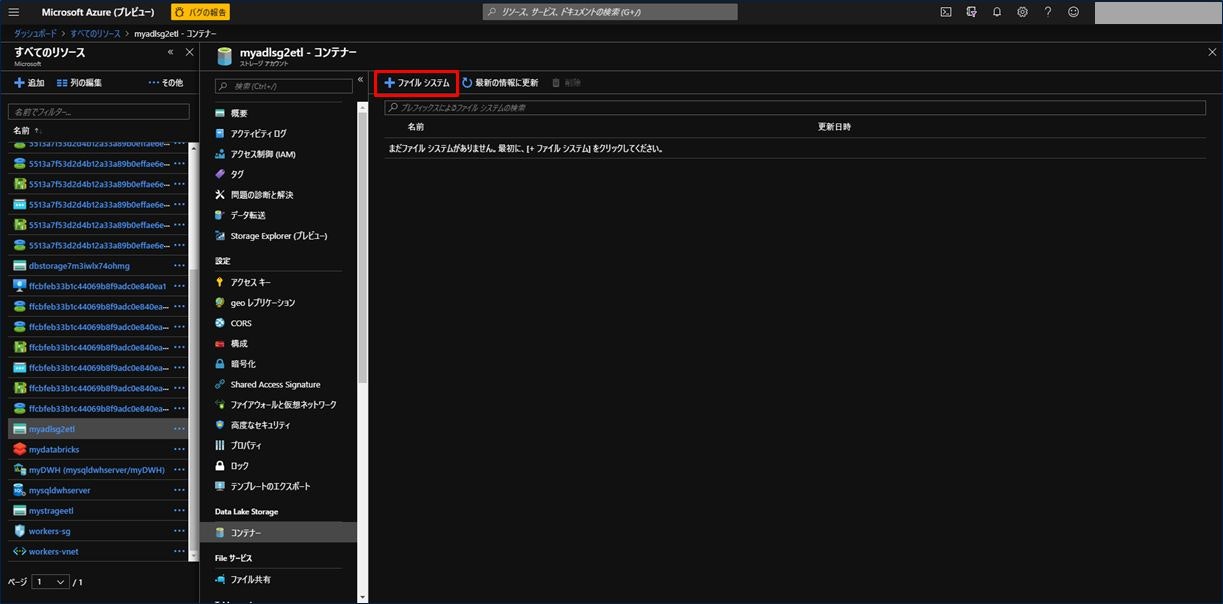
画面中央に表示される「Data Lake Storage」をクリックします。
画面上部に表示される「+ファイルシステム」をクリックします。
新しいファイルシステムの名前を入力し、「OK」をクリックします。
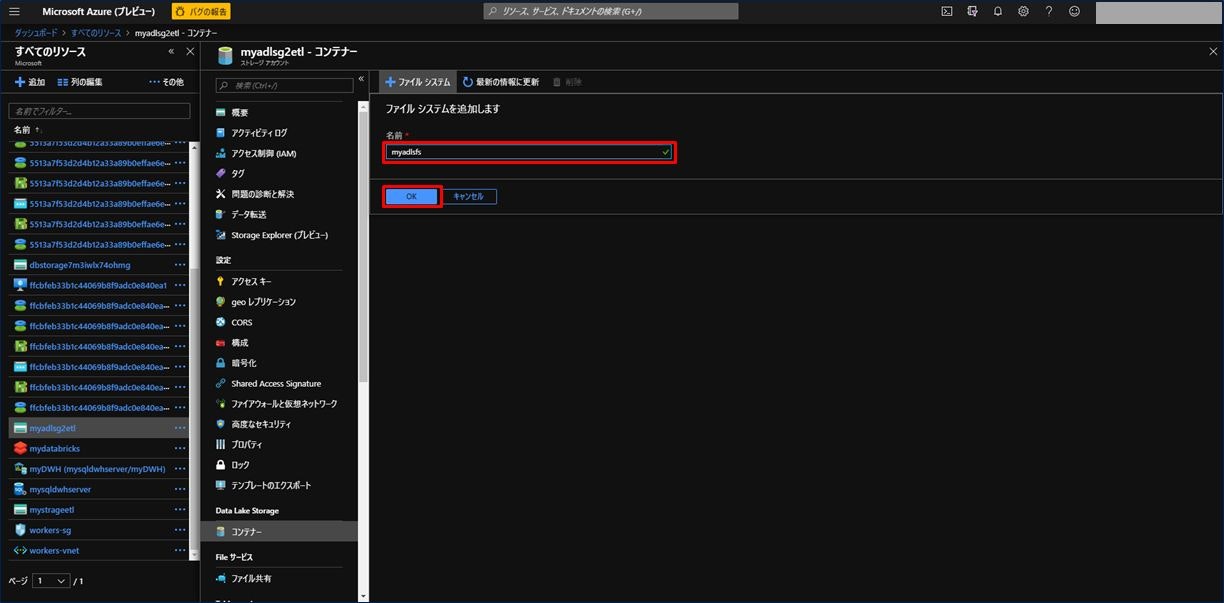
これでファイルシステムが作成されました。Azure Data Lake Storage Gen2 ストレージアカウントの作成手順は以上になります。
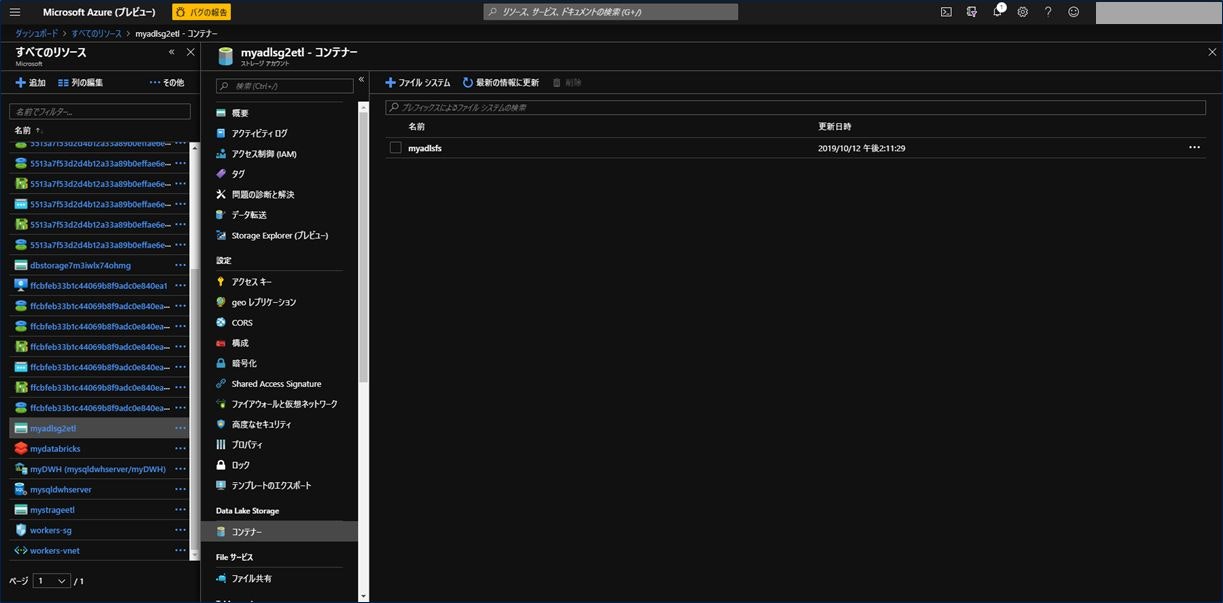
4) サービスプリンシパルの作成
4番目の手順はサービスプリンシパルの作成です。左上の三本の横線から「Azure Active Directory」をクリックします。
右にある「アプリの登録」をクリックします。
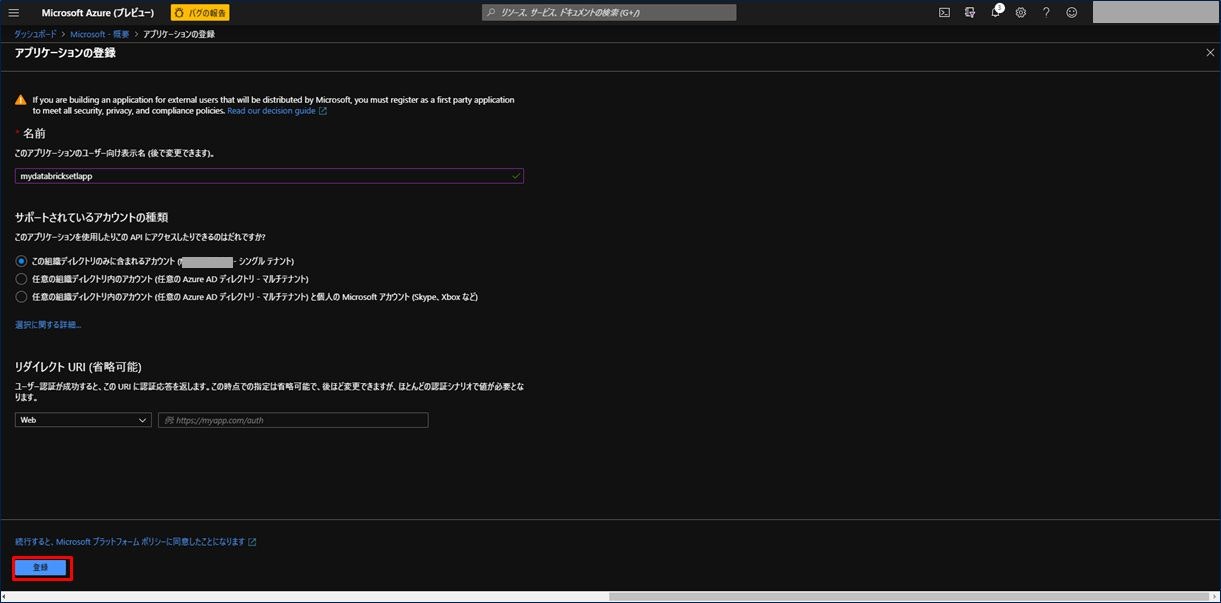
アプリケーションの名前を入力してください。緑のチェックマークが出れば OK です。「登録」をクリックします。
AAD にアプリケーションが登録されました。
「アプリケーション(クライアント…」と「ディレクトリ(テナント)ID」は次の Databricks の作成で使用するので控えておいてください。
次にアプリケーションをロールに割り当てます。ここでは、Azure Data Lake Storage Gen2 ストレージアカウントのスコープ内で「ストレージ BLOB データ共同作成者」ロールをサービスプリンシパルに割り当てます。
そのため、3) で作成した「Azure Data Lake Storage Gen2 ストレージアカウント」の画面を開きます。
左のメニューから「アクセス制御(IAM)」をクリックします。
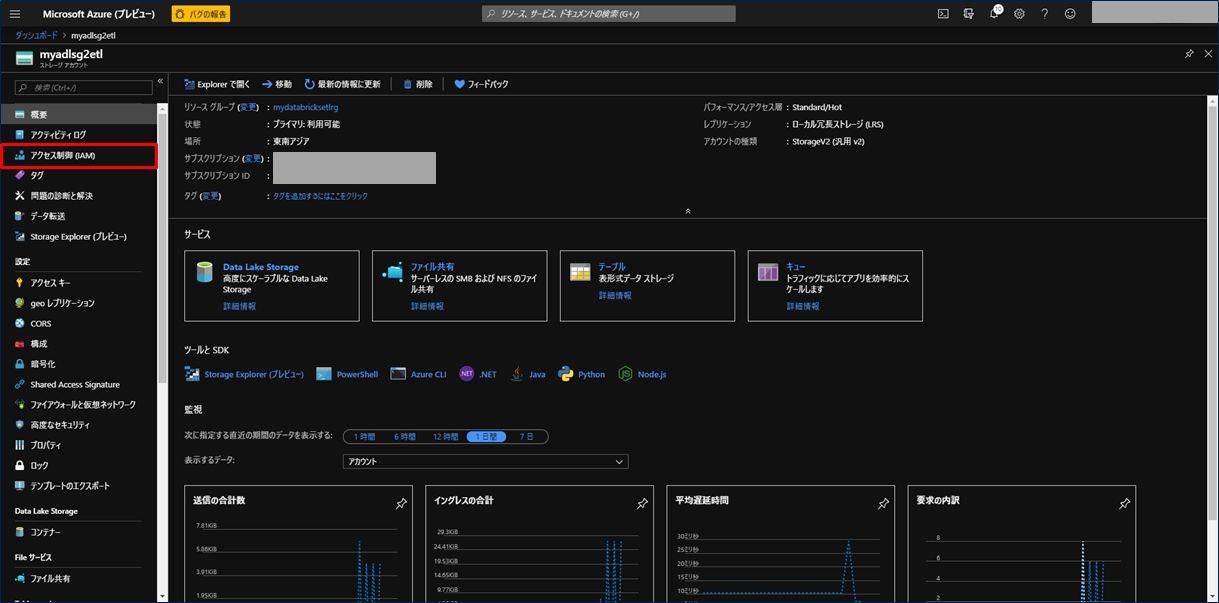
画面中央にある「ロールの割り当てを追加する」の項目にある「追加」をクリックします。
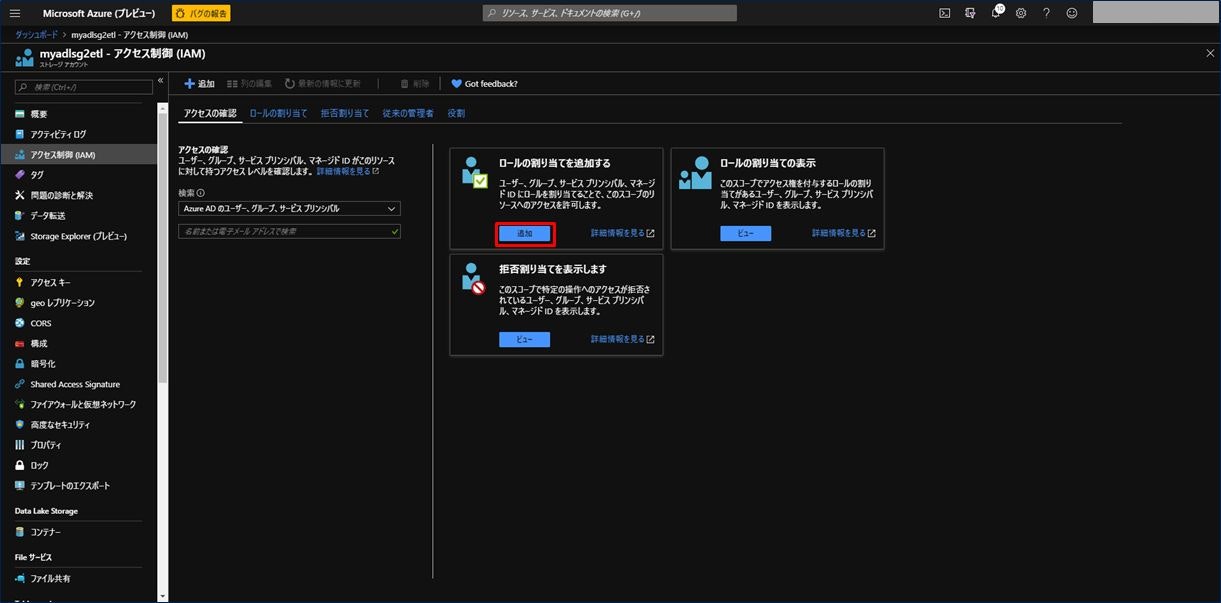
画面右側に「ロール割り当ての追加」が表示されるので、
- 「役割」に「ストレージ BLOB データ共同作成者」を選択
- 「選択」に先ほど登録したアプリを選択
してから「保存」をクリックします。
設定した内容が正しく保存されているか確認します。「ロールの割り当ての表示」の項目にある「ビュー」をクリックします。
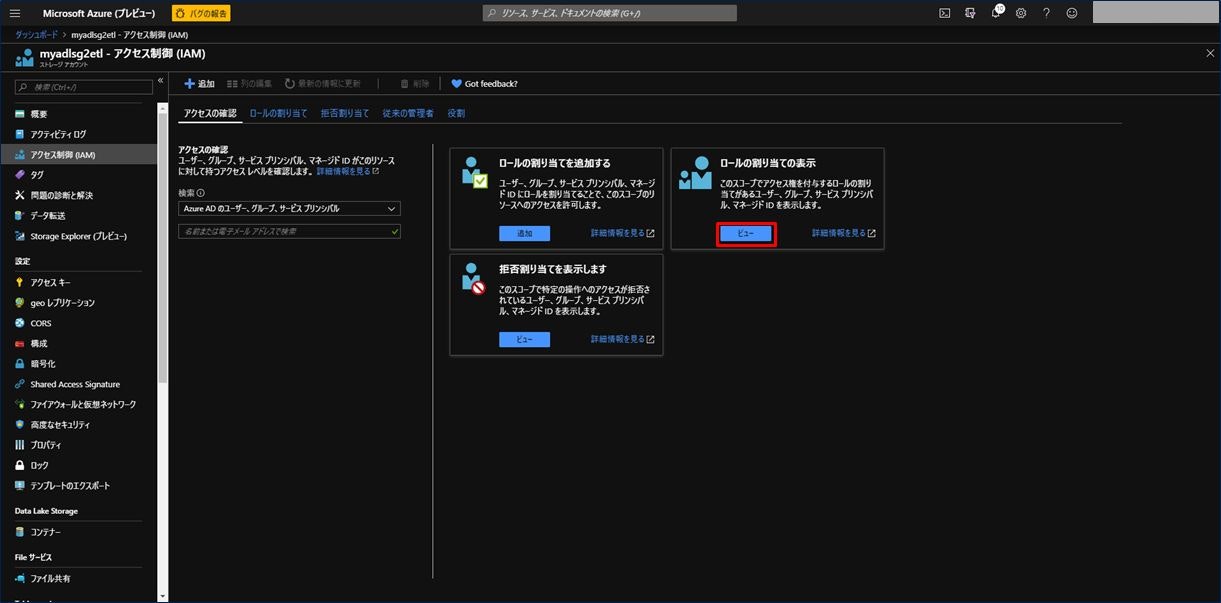
画面中央に、先ほど保存した「ストレージ BLOB データ共同作成者」のアイテムがあることが確認できます。これでアプリケーションをロールに割り当てることができました。
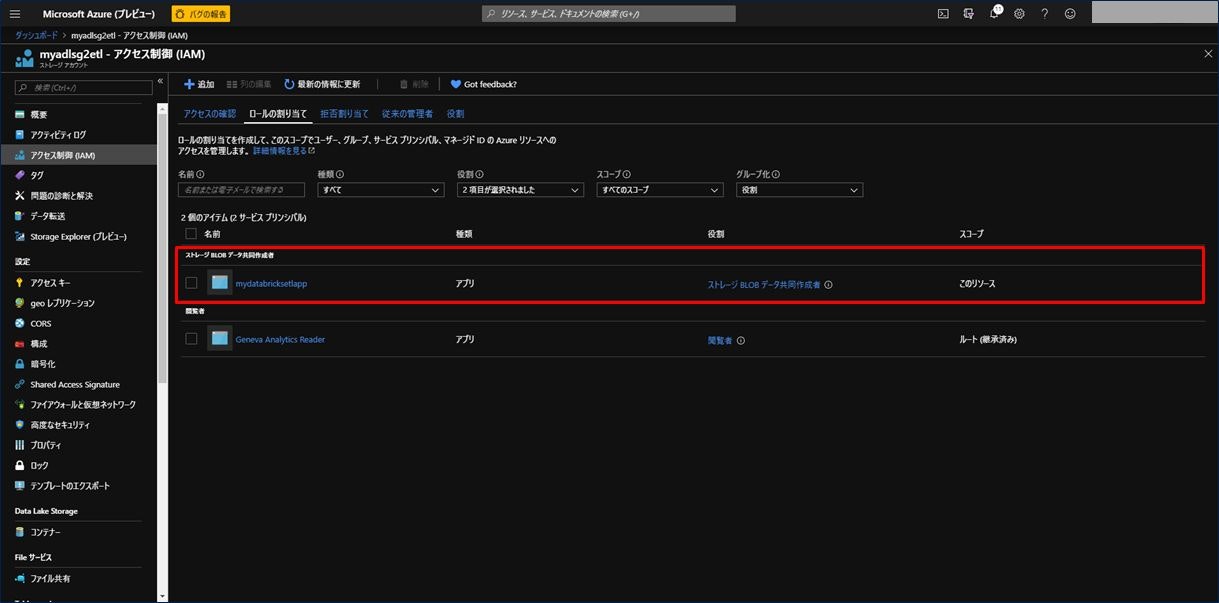
次にサインインするための値を取得します。左上の三本の横線から「Azure Active Directory」をクリックします。
右側にある検索ウィンドウにて、「アプリの登録」を選択し、下の窓に先ほど登録したアプリ名を入力します。ポップアップで入力窓の下に登録したアプリ名が表示されますので、これをクリックします。
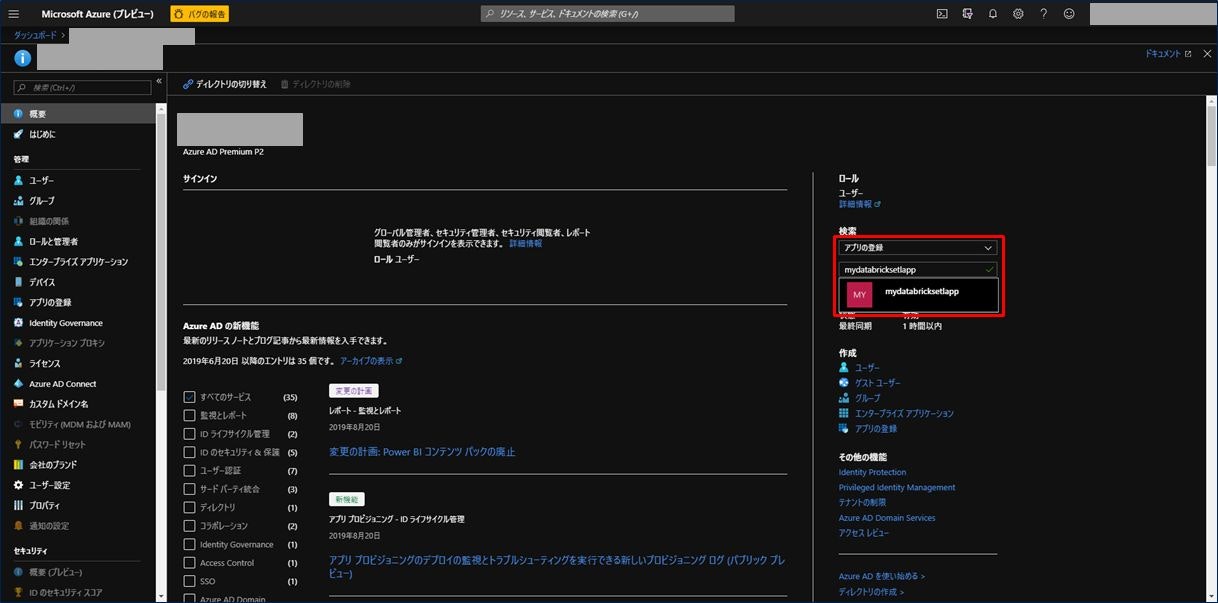
表示された画面の左にあるメニューから「証明書とシークレット」をクリックします。次に「+新しいクライアントシークレット」をクリックします。
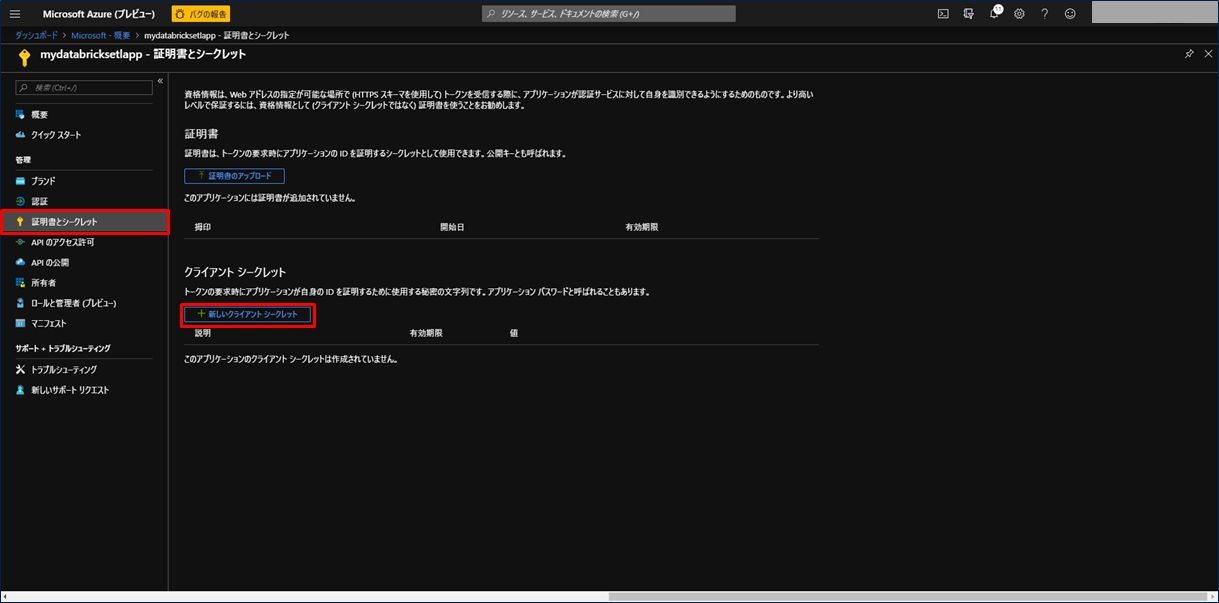
クライアントシークレットの追加画面が表示されます。「説明」には任意の説明を入力し、有効期限を選択(ここでは「1年」を選択)し、「追加」をクリックします。
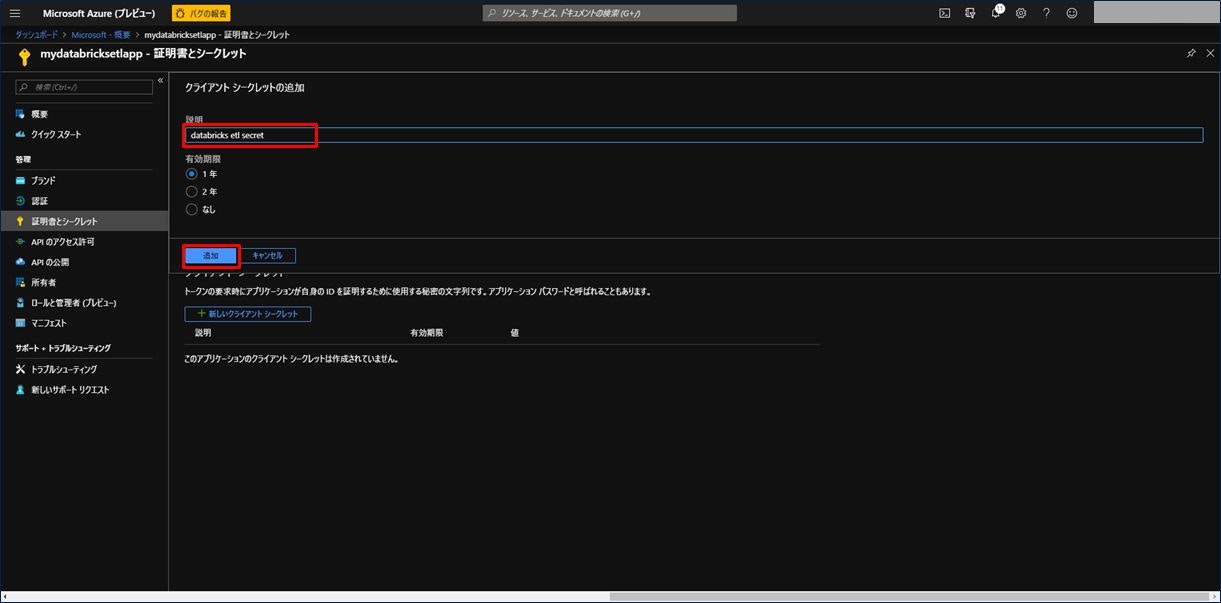
シークレットが追加されましたので、値をコピーして控えておきます。次の手順で使用します。
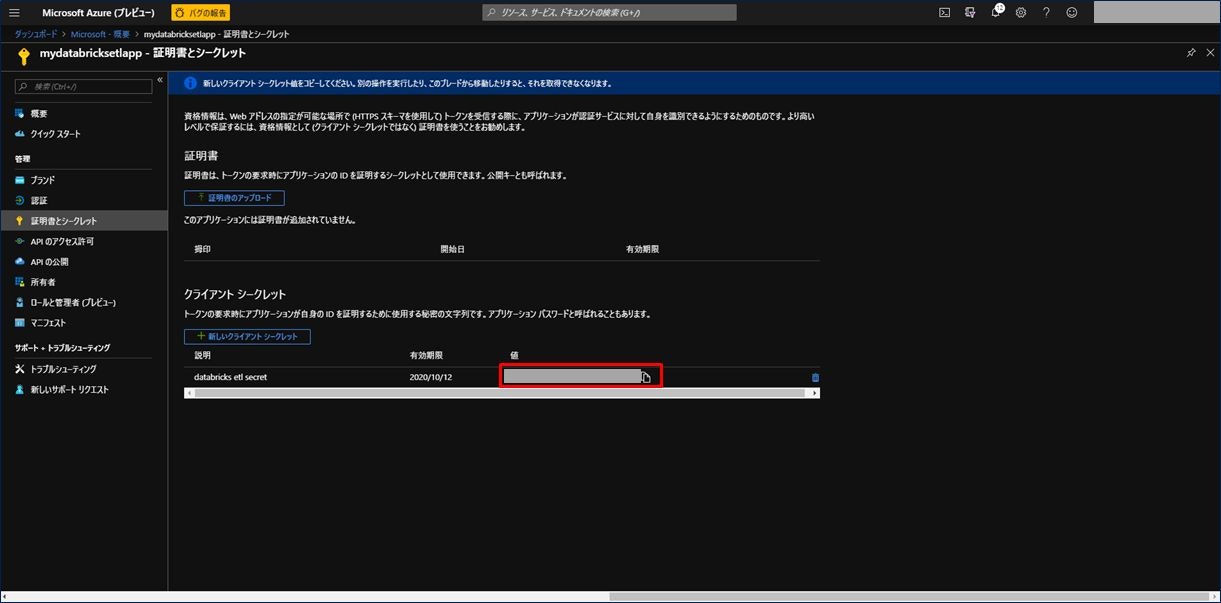
5) Azure Databricks の作成
最後の手順は Azure Databricks の作成となります。
ここで、Databricks を作成する前に、これまでの作業で作成した各サービスから Databricks が必要とする情報をまとめておきたいと思います。あらかじめ以下の項目の値を控えておくことをお勧めします。
| サービス名 | 項目 | 値 |
|---|---|---|
| Azure SQL Data Warehouse | データウェアハウス名 | 手順 1) で作成したデータウェアハウス名。 |
| データベースサーバ名 | 手順 1) で作成したデータベースサーバー名。XXXX.database.windows.net のような形式。 | |
| ユーザー名 | 手順 1) で設定したサーバー管理者名。 | |
| パスワード | 手順 1) で設定したサーバー管理者のパスワード。 | |
| BLOB Storage アカウント | ストレージアカウント名 | 手順 2) で設定したストレージアカウント名。 |
| コンテナ―名 | 手順 2) で設定したコンテナ―名。 | |
| アクセスキー | Azure Blob Storage アカウント画面の左メニューにある「アクセスキー」から取得。 | |
| Azure Data Lake Storage Gen2 | ストレージアカウント名 | 手順 3) で設定したストレージアカウント名。 |
| ファイルシステム名 | 手順 3) で設定したファイルシステム名。 | |
| サブスクリプション | テナント ID | 手順 4) で AAD にアプリ登録した際のディレクトリ(テナント)ID。 |
| AAD に登録したアプリ | アプリケーション ID | 手順 4) で AAD にアプリ登録した際のアプリケーションID。 |
| アプリの認証キー | 手順 4) で AAD にアプリ登録し、その後作成したクライアントシークレットの値。 |
それでは Azure Databricks を作成します。
左上の三本の横線から「リソースの作成」をクリックし、左メニューにある「分析」→「Azure Databricks」をクリックします。
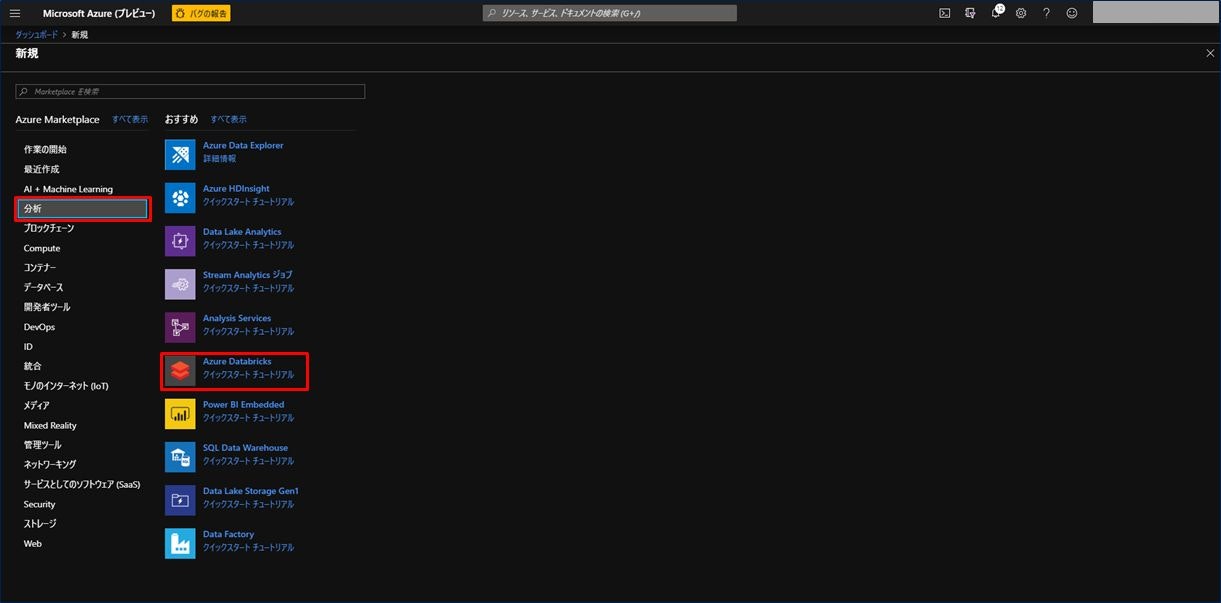
Azure Databricks を作成するための入力画面が表示されます。項目を入力後、「作成」をクリックします。
| 設定項目 | 設定値 |
|---|---|
| Workspace name | 任意の名称を入力。(緑のチェックマークが出ればOK) |
| サブスクリプション | お持ちのサブスクリプションを選択。 |
| リソースグループ | 手順 1) で作成したリソースグループを選択。 |
| 場所 | 任意の場所を選択。可能な限り手順 1) で作成した場所と同じ場所を選択。 |
| Pricing Tier | 「Standard」を選択。 |
| Deploy Azure Databricks workspace in your own Virtual Network (VNet) | 今回は「No」を選択。 |
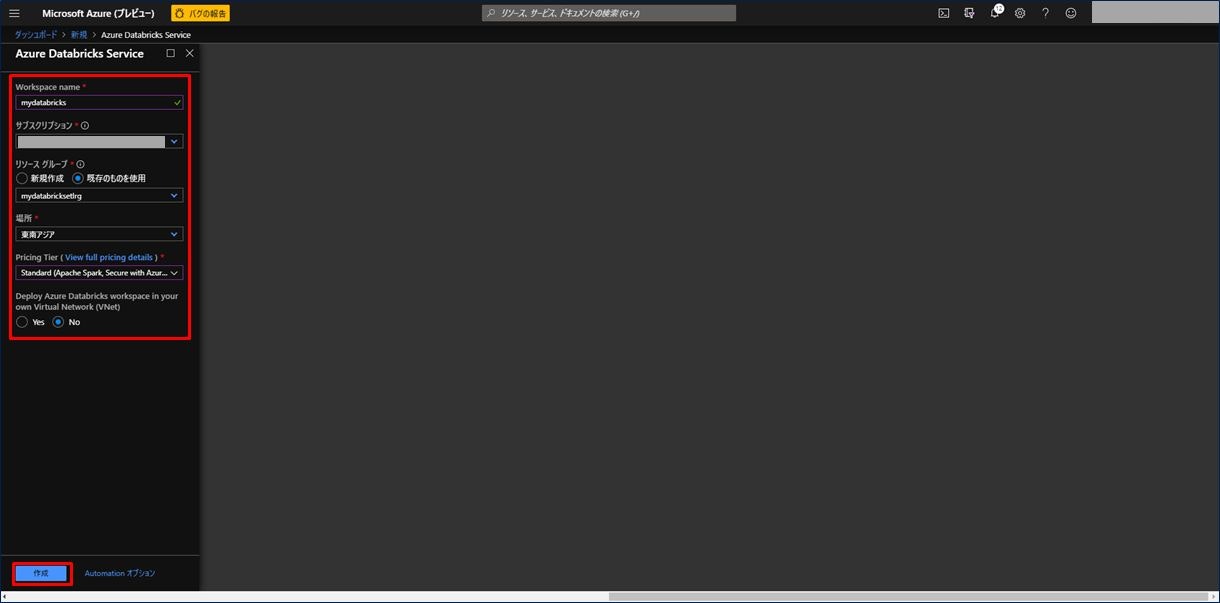
Azure Databricks が作成されました。次にクラスターを作成しますので、Azure Databricks をクリックします。
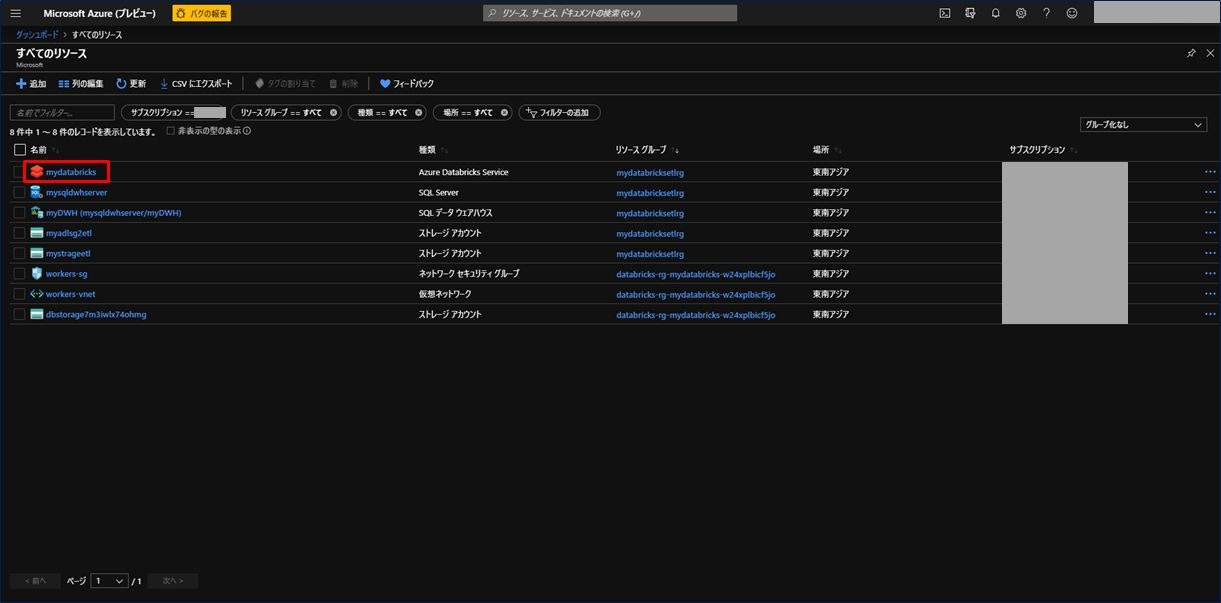
表示された画面の中央にある「Launch Workspace」をクリックします。
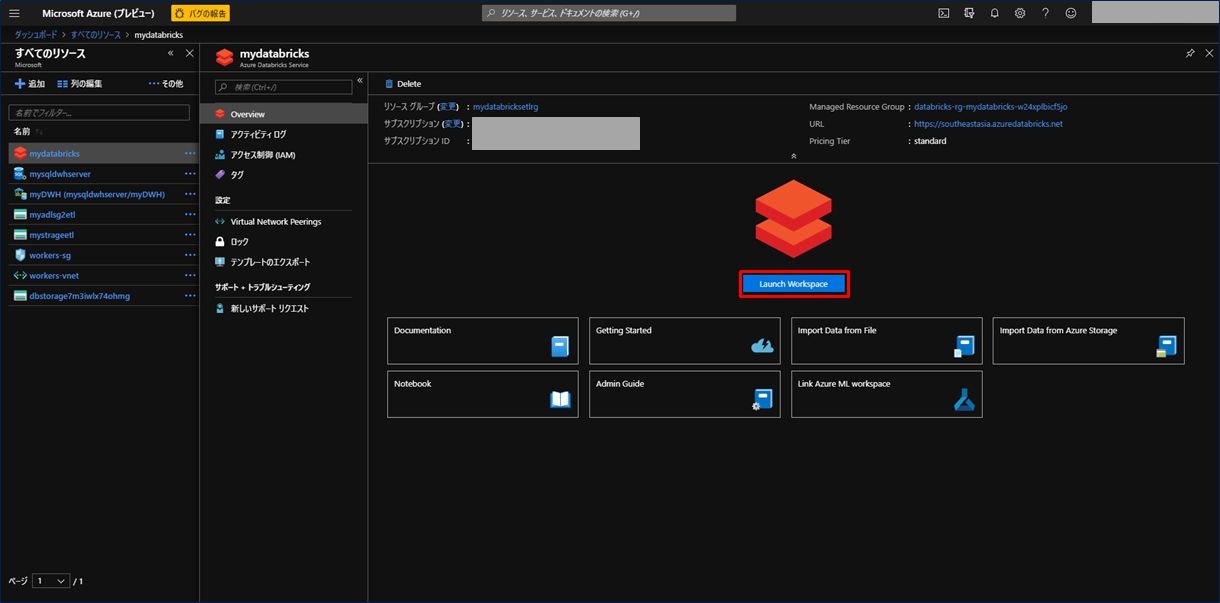
別のウィンドウが起動し、Azure Databricks の Workspace にアクセスします。
画面左下にある「New Cluster」をクリックします。
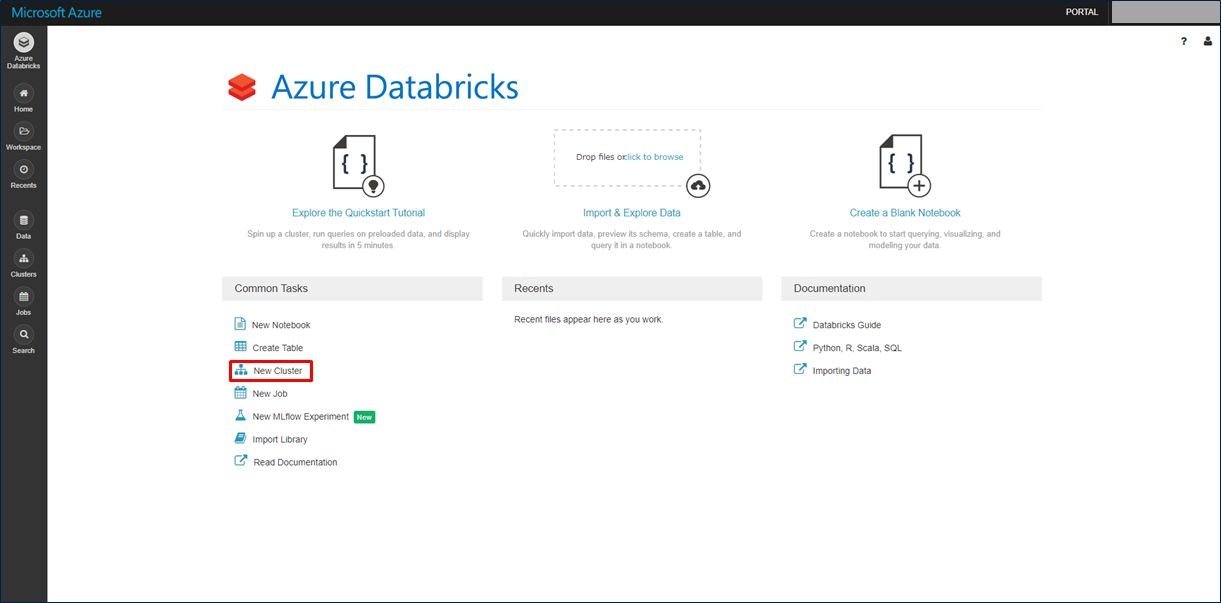
クラスターの情報入力画面が表示されます。項目を入力後、画面上部にある「Create Cluster」をクリックします。
今回は、「Cluster Name」と「Terminate after XX minutes of inactivity」の2か所を設定します。
「Terminate after XX minutes of inactivity」はデフォルトでは「120」分の設定になっていますが、今回は「60」分にしています。
この項目は、「アクティビティがXX分ない場合は終了する」というオプションで、クラスターが使われていないときは自動でクラスターを終了してくれます。クラスターが使われていない時間を設定するのがこの項目です。無駄なリソースを終了してくれるので、必ずチェックをしておきましょう。
クラスターの準備が整いました。それでは Azure Databricks Workspace に Notebook を作成します。
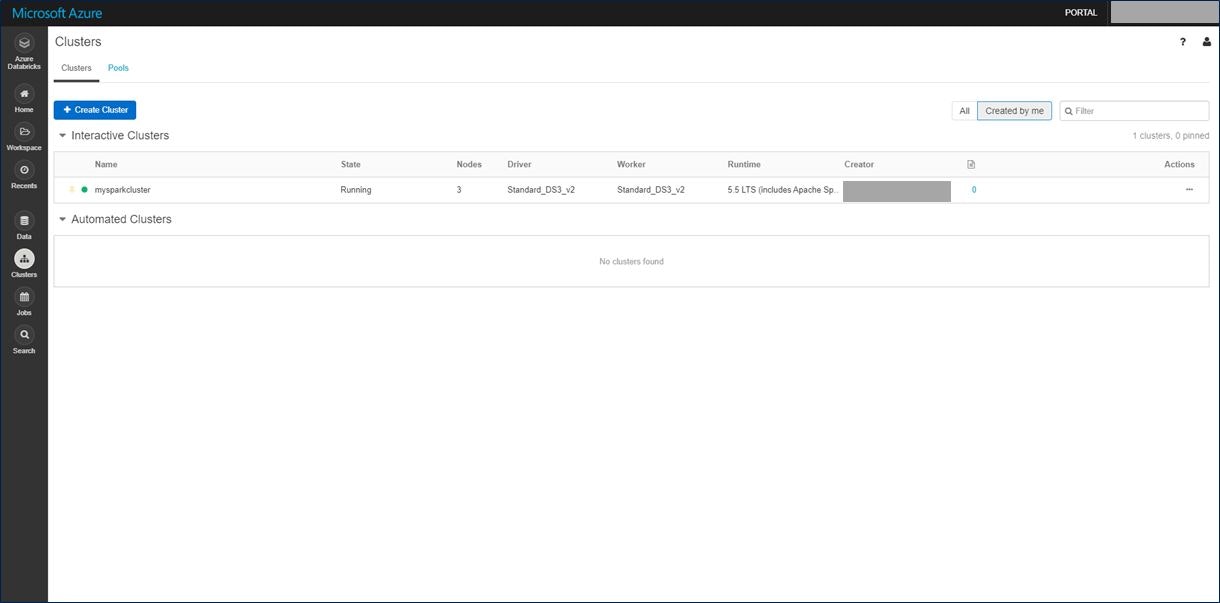
左のメニューから「Workspace」を選択し、表示されたメニューの上部にある「Workspace」という文字の横にある下向きの矢印をクリックします。「Create」→「Notebook」をクリックします。
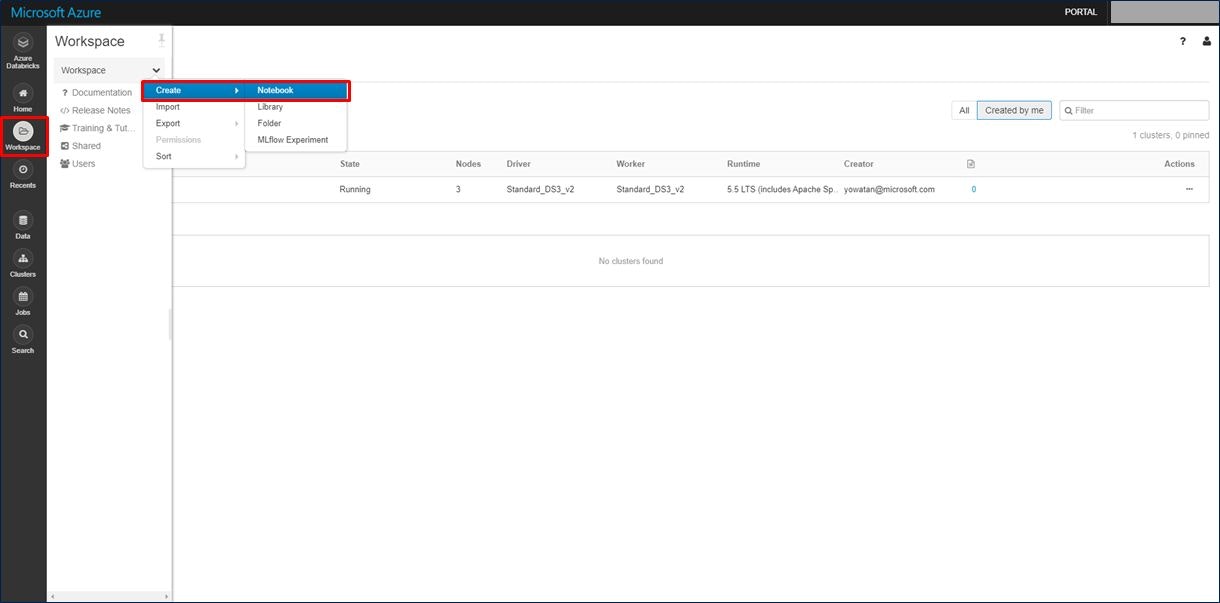
Notebook の名前(任意の名称)、利用する言語(ここでは Scala)、先ほど作成したクラスターを選択し、「Create」をクリックします。
これで Notebook が利用可能になりました。
最初のセルに以下をコピーします。最初の5行には、先ほど控えておいた各値で置き換えます。
「Shift + Enter」でセルのコードを実行できます。
| 項目 | 値 |
|---|---|
| storageAccountName | 手順 3) で設定した Azure Data Lake Storage Gen2 ストレージアカウント名。 |
| appID | 手順 4) で AAD にアプリ登録した際のアプリケーションID。 |
| password | 手順 4) で AAD にアプリ登録し、その後作成したクライアントシークレットの値。 |
| fileSystemName | 手順 3) で設定したファイルシステム名。 |
| tenantID | 手順 4) で AAD にアプリ登録した際のディレクトリ(テナント)ID。 |
val storageAccountName = "<storage-account-name>"
val appID = "<app-id>"
val password = "<password>"
val fileSystemName = "<file-system-name>"
val tenantID = "<tenant-id>"
spark.conf.set("fs.azure.account.auth.type." + storageAccountName + ".dfs.core.windows.net", "OAuth")
spark.conf.set("fs.azure.account.oauth.provider.type." + storageAccountName + ".dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set("fs.azure.account.oauth2.client.id." + storageAccountName + ".dfs.core.windows.net", "" + appID + "")
spark.conf.set("fs.azure.account.oauth2.client.secret." + storageAccountName + ".dfs.core.windows.net", "" + password + "")
spark.conf.set("fs.azure.account.oauth2.client.endpoint." + storageAccountName + ".dfs.core.windows.net", "https://login.microsoftonline.com/" + tenantID + "/oauth2/token")
spark.conf.set("fs.azure.createRemoteFileSystemDuringInitialization", "true")
dbutils.fs.ls("abfss://" + fileSystemName + "@" + storageAccountName + ".dfs.core.windows.net/")
spark.conf.set("fs.azure.createRemoteFileSystemDuringInitialization", "false")
次に、Azure Data Lake Storage Gen2 にサンプルデータを取り込みます。次のセルに以下のコードをコピーし、「Shift + Enter」で実行します。これでいったんクラスター内に「small_radio_json.json」というファイルをダウンロードします。
%sh wget -P /tmp https://raw.githubusercontent.com/Azure/usql/master/Examples/Samples/Data/json/radiowebsite/small_radio_json.json
次のセルに、以下のコードをコピーし、「Shift + Enter」で実行します。
これで、ダウンロードした「small_radio_json.json」を Azure Data Lake Storage Gen2 に格納します。
dbutils.fs.cp("file:///tmp/small_radio_json.json", "abfss://" + fileSystemName + "@" + storageAccountName + ".dfs.core.windows.net/")
Azure Data Lake Storage Gen2 に格納されたことを確認しましょう。Data Lake Storage に格納したファイルは Storage Explorer を利用しないとみることができません。こちらからダウンロードして利用してください。
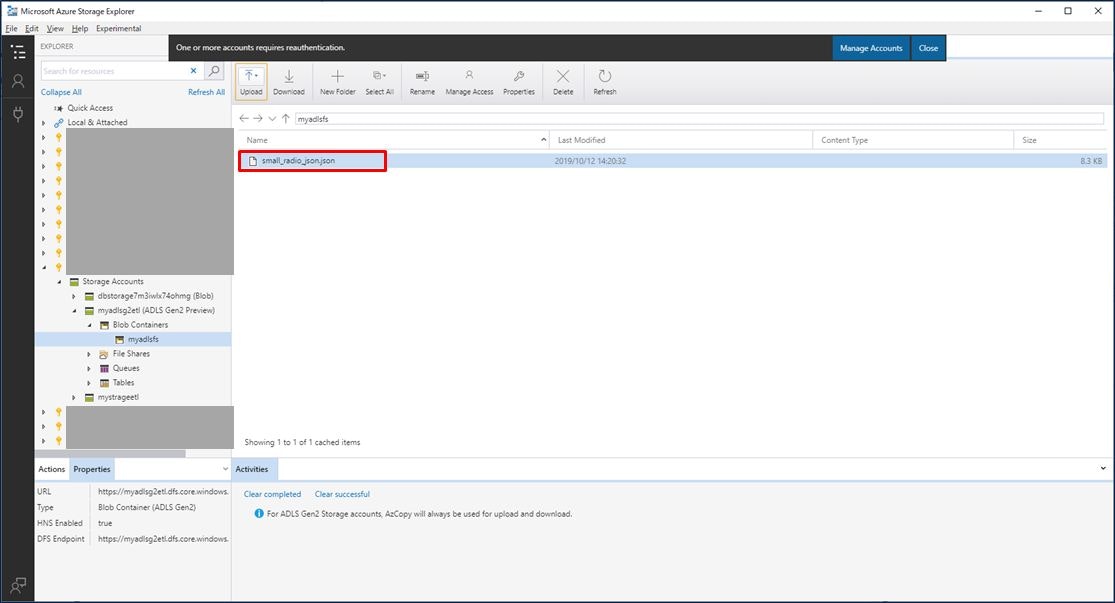
または、Azure Portal 画面で Azure Data Lake Storage Gen2 を選択し、左メニューの「Storage Explorer (プレビュー)」をクリック、「ファイルシステム」を開くと、右画面にダウンロードした「small_radio_json.json」が表示されることを確認できます。
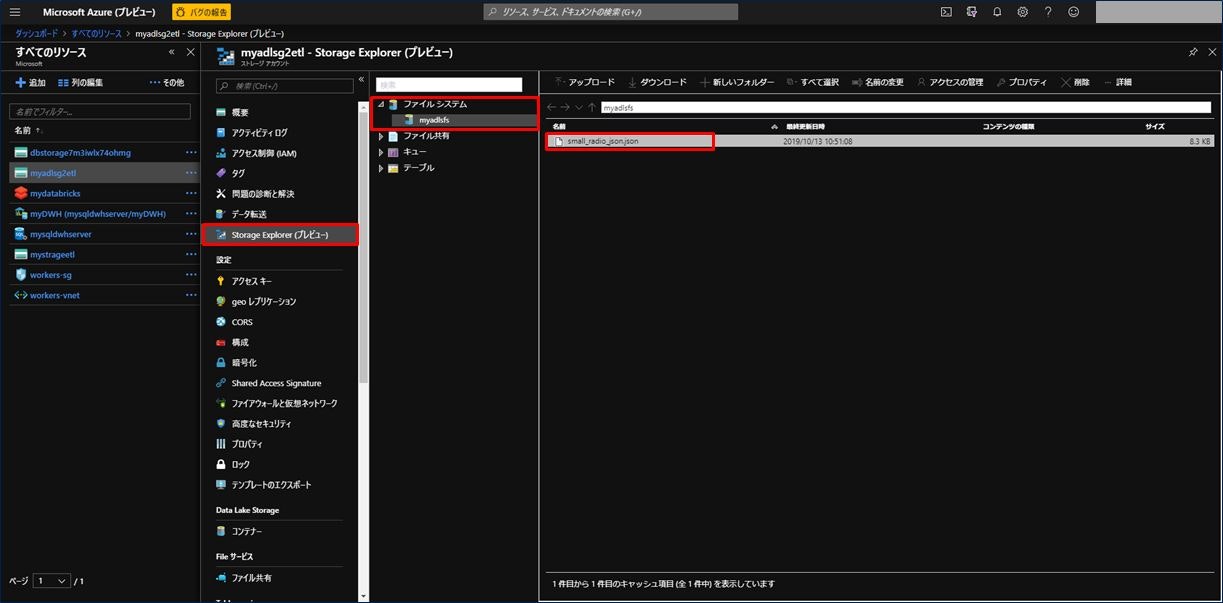
それでは次に Azure Data Lake Storage Gen2 からデータを抽出します。
Notebook の次のセルに以下のコードをコピーし、「Shift + Enter」で実行します。
val df = spark.read.json("abfss://" + file-system-name + "@" + storage-account-name + ".dfs.core.windows.net/small_radio_json.json")
取り込んだデータを確認します。次のセルに以下のコードをコピーし、「Shift + Enter」で実行します。
df.show()
実行した結果は以下となります。
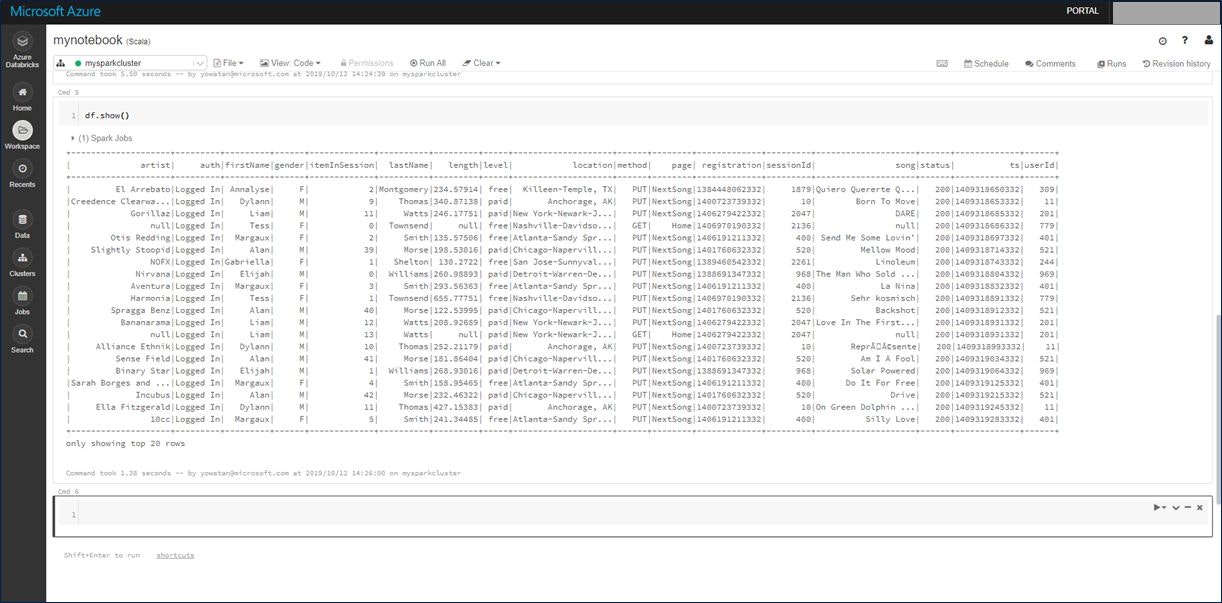
Azure Databricks にデータを取り込むことができたので、今度はデータを加工します。
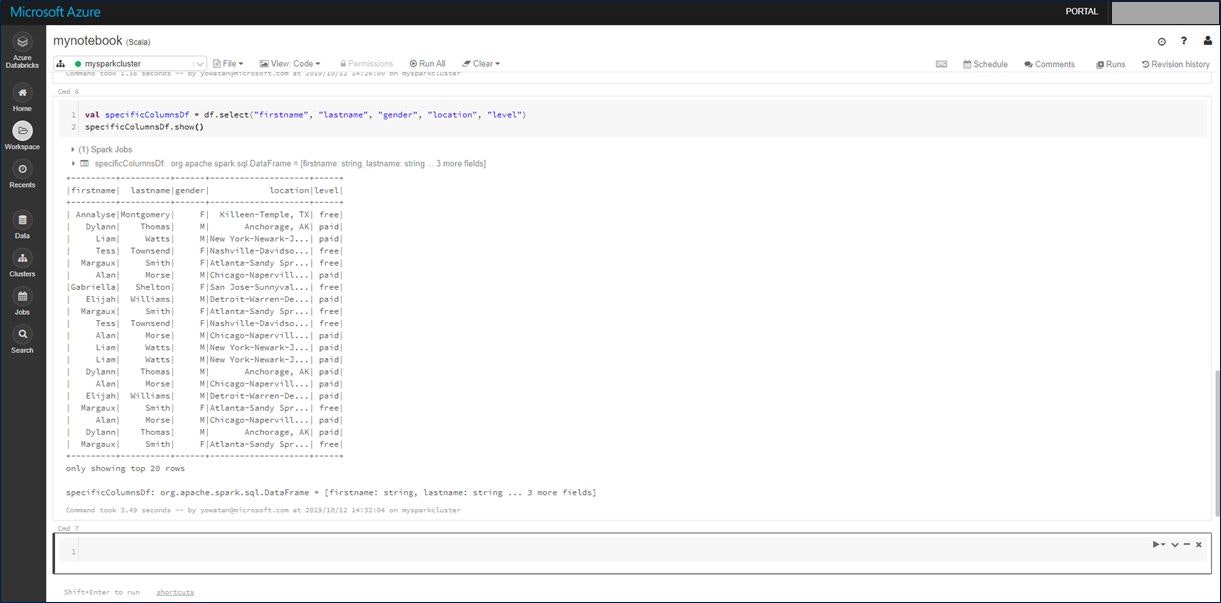
サンプルデータファイル「small_radio_json.json」は、ラジオ局のリスナー情報を収集したものであり、さまざまな列を含んでいます。 このデータを変換して、データセットから特定の列だけを取得します。作成したデータフレームから、firstName、lastName、gender、location、level の各列だけを取得します。
次のセルに以下のコードをコピーし、「Shift + Enter」で実行します。
val specificColumnsDf = df.select("firstname", "lastname", "gender", "location", "level")
specificColumnsDf.show()
実行した結果は以下となります。指定した特定の列だけ取得できたことが確認できます。
次に、最後の「level」列の名前を「subscription_type」に変更します。
次のセルに以下のコードをコピーし、「Shift + Enter」で実行します。
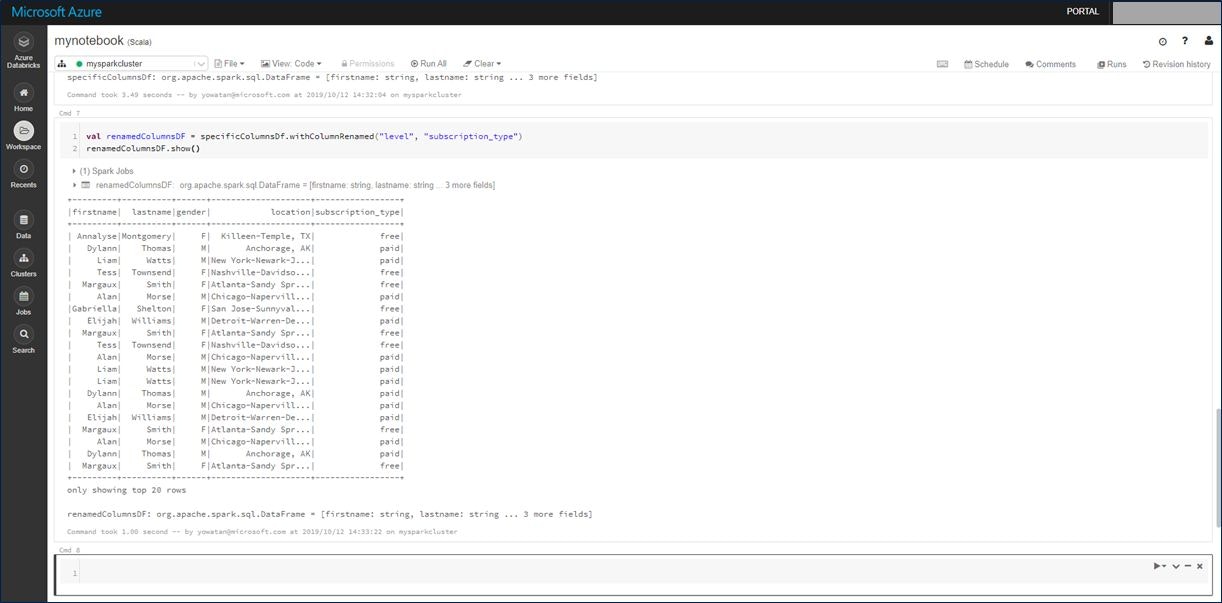
val renamedColumnsDF = specificColumnsDf.withColumnRenamed("level", "subscription_type")
renamedColumnsDF.show()
実行した結果は以下となります。最後の「level」列の名前が「subscription_type」に変更されたことが確認できます。
今回は列名の変更ですが、このように Azure Databricks 上でデータの変換を行うことが可能です。
最後、このデータを Azure SQL Data Warehouse に格納します。
Azure Databricks のデータを一度 Azure Blob Storage にテンポラリデータとして格納し、そこから Azure Data Warehouse に書き出します。これは、PolyBase という仕組みを利用しています。PolyBase の詳細については、こちらを参照ください。
最初の3行は、先ほど控えておいた各値で置き換えます。
次のセルに以下のコードをコピーし、「Shift + Enter」でセルのコードを実行できます。
| 項目 | 値 |
|---|---|
| blobStorage | 手順 2) で設定したストレージアカウント名。 |
| blobContainer | 手順 2) で設定したコンテナ―名。 |
| blobAccessKey | Azure Blob Storage アカウント画面の左メニューにある「アクセスキー」から取得。 |
val blobStorage = "<blob-storage-account-name>.blob.core.windows.net"
val blobContainer = "<blob-container-name>"
val blobAccessKey = "<access-key>"
val tempDir = "wasbs://" + blobContainer + "@" + blobStorage +"/tempDirs"
val acntInfo = "fs.azure.account.key."+ blobStorage
sc.hadoopConfiguration.set(acntInfo, blobAccessKey)
次に格納先の SQL Data Warehouse の設定です。最初の4行は、先ほど控えておいた各値で置き換えます。
| 項目 | 値 |
|---|---|
| dwDatabase | 手順 1) で作成したデータウェアハウス名。 |
| dwServer | 手順 1) で作成したデータベースサーバー名。XXXX.database.windows.net のような形式。 |
| dwUser | 手順 1) で設定したサーバー管理者名。 |
| dwPass | 手順 1) で設定したサーバー管理者のパスワード。 |
//SQL Data Warehouse related settings
val dwDatabase = "<database-name>"
val dwServer = "<database-server-name>"
val dwUser = "<user-name>"
val dwPass = "<password>"
val dwJdbcPort = "1433"
val dwJdbcExtraOptions = "encrypt=true;trustServerCertificate=true;hostNameInCertificate=*.database.windows.net;loginTimeout=30;"
val sqlDwUrl = "jdbc:sqlserver://" + dwServer + ":" + dwJdbcPort + ";database=" + dwDatabase + ";user=" + dwUser+";password=" + dwPass + ";$dwJdbcExtraOptions"
val sqlDwUrlSmall = "jdbc:sqlserver://" + dwServer + ":" + dwJdbcPort + ";database=" + dwDatabase + ";user=" + dwUser+";password=" + dwPass
最後に Azure SQL Data Warehouse に「SampleTable」というテーブルを作成し、先ほどのデータを格納します、
次のセルに以下のコードをコピーし、「Shift + Enter」でセルのコードを実行できます。
spark.conf.set(
"spark.sql.parquet.writeLegacyFormat",
"true")
renamedColumnsDF.write.format("com.databricks.spark.sqldw").option("url", sqlDwUrlSmall).option("dbtable", "SampleTable").option( "forward_spark_azure_storage_credentials","True").option("tempdir", tempDir).mode("overwrite").save()
Azure SQL Data Warehouse に SSMS で接続し、作成されたテーブルと格納されたデータを確認します。
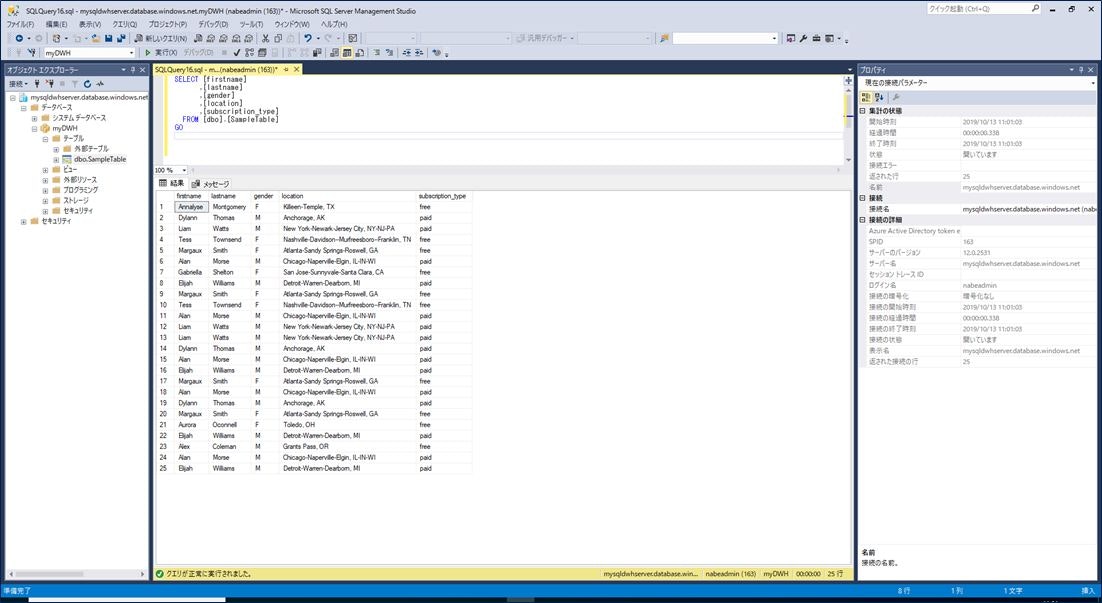
これで、Azure Data Lake Storage Gen2 に蓄積したファイルを Azure Databricks が読み取って、何らかの変換を加え、Azure SQL Data Warehouse に格納するというシナリオが実現できました。
まとめ
いかがでしたでしょうか?
今回は、Azure Databricks でもよく使われそうなシナリオであるバッチ処理を Azure Databricks のチュートリアル「Azure Databricks を使用してデータの抽出、変換、読み込みを行う」を参考に実際にやってみました。以下3点はご理解できたのではないでしょうか。
- Azure Databricks が Azure Data Lake Storage Gen2 からファイルを読み込むことができる
- Azure Databricks にてデータを変換することができる
- Azure Databricks から Azure SQL Data Warehouse にデータを格納することができる(PolyBase を利用)
皆様がお持ちの大量データを活用する際、上記のシナリオで Azure SQL Data Warehouse にデータを格納し、Power BI などのツールを使って可視化することでヒントを得ることができるのではと考えます。大量データの可視化はローカル PC 環境ではなかなか性能的に厳しい場合があると思いますので、Azure をうまく活用いただければと思います。