記事概要
この記事は、オライリーの「推薦システム実践入門」について、私含めた弊社Ubiqの社員がより理解しやすいようにまとめたものです。ひいては弊社社員だけではなく、レコメンド機能に興味がある方全てのひとのためになればと思います。私が機械学習エンジニアなので、エンジニア寄りからの視点になっていると思うので、特に同じ機械学習エンジニアの方や、データサイエンティストの方に特に気をつけるべき部分を記載しております。
また、この記事は随時更新していくものになっており、全8章ある「推薦システム実践入門」ですが毎週1章ずつ更新していこうと思うので、それまでお待ちいただければと思います。
目次
第1章 推薦システム
第2章 推薦システムのプロジェクト
第3章 推薦システムのUI/UX
第4章 推薦アルゴリズムの概要
第5章 推薦アルゴリズムの詳細
第6章 実システムへの組み込み
第7章 推薦システムの評価
第8章 発展的なトピック
本編
第1章 推薦システム
そもそも推薦システムとは?
推薦システムとは、「複数の候補から価値あるものを選び出し、意思決定を支援するシステム」 であり、
「複数の候補から価値あるものを選び出し、」 というのは、レコメンドの手法についてのことを指している。例えば単に最近サイトを訪れるユーザーたちからの閲覧数が多いものを選ぶ方法であるとか、ユーザーの購入履歴を元に次に買ってもらえそうなものを探すという方法などがある。
「意思決定を支援するシステム」 というのは、上に挙げた手法によって得られたアイテムの候補をいかにしてユーザーに伝えるかという手段である。単にレコメンドすべきものの候補を得られただけでは何にもならず、ちゃんとそれをユーザーに表示して初めて意味を成すのである。例えば、Amazonの「あなたへのおすすめタイトル」、「この商品を見た後に買っているのは?」というような直接サイトに表示するものや、推薦すべきものをスマホのプッシュ通知で知らせるのか、メールを使うのかといった種類がある。
推薦システムの種類
推薦システムというものは種類分けすると
インプット × プロセス × アウトプット
というように分解できる。
インプットについては、ユーザーの年齢や性別、住所といったユーザーのプロフィールであるユーザーアイテムのコンテンツ情報、ユーザーがそのサービス内で何をしたかを表す、ユーザーとアイテムのインタラクション情報に二分することができる。
プロセスについては、新着順や人気順など全ユーザーに共通に提示するアイテムを提示する概要推薦(パーソナライズなし)、あるアイテムからアイテム間の類似度を用いて関連したアイテムを提示する関連アイテム推薦、ユーザーのプロフィールやインタラクションデータ、あるいはその両方を用いて推薦するパーソナライズ推薦というものに分けられる。
アウトプットについては、サイトのトップページや閲覧しているページに表示したり、メールで配信したり、郵送で推薦するアイテムのクーポン券を送るなど様々な方法が考えられる。
検索システムとは何が違うのか?
推薦システムと似たようなシステムに、検索システムがあるが、これらは
- ユーザーがあらかじめ欲しいアイテムを知っているか知っていないか
- キーワード入力があるかないか
- 表示するアイテムの推測に、検索のキーワードを使うかユーザーのプロフィールや過去の行動を使うか
- ユーザーが能動的か受動的か
- パーソナライズをしないことが多いかすることが多いか
という点で異なっており、相互に支え合うことが重要になっている。
第2章 推薦システムのプロジェクト
推薦システムというものは、基本的にデータサイエンティストが参画することが多く、推薦システムのプロジェクトについてもデータサイエンティストに求められるスキルセットが求められる。そのスキルセットというものは以下のようなものがある。
- ビジネス力
- データサイエンス力
- データエンジニアリング力
以下、これらのことについて説明していく。
ビジネス力
そもそも推薦システムを導入した際にどのようなことを期待しているのかということを定義できることが大切である。仮にデータに関する様々なアルゴリズムが扱えても、間違った方向に努力した場合その能力や努力が無駄になってしまうため、それを避けられる能力が必要になる。逆に言えば、そのようなアルゴリズムが無くとも推薦システム自体いらなかったり、人気度の推薦だけで事足りることがある。
具体的には、推薦システムを導入する際にKGI(Key Goal Indicatorのことで、ビジネスのゴールを定量的に表したもの)、KPI(Key Performance Indicatorのことで、KGIを達成するために必要となる中間地点を定量的に定めたもの)を定めることが大切になっている。
私が思うに、やはりこのビジネス力というのが普段Kaggleなどでひたすら実装していたり、機械学習系の研究に没頭してる人々にとって難しいと思われる。というのも、私が実際に機械学習のプロジェクトに参加しているときに、KGI, KPIの設定をする場面がよく出てきた。KGIを決めるのはすぐに決まる、というよりビジネス寄りの方が決めるということが多いが、そこからKPIを決めるというのが難しい。ある程度技術選定をしたあとに軽くそれを動かしてみて、そこからKPIを決めろという指示が来たが、そもそもKGIの設定が非常に曖昧で、技術にそこまで触れておらずどれだけその技術でいけるかわからないのにKGIを設定しなければならない状態になって非常に困ったのである。
この経験から私は、技術者もそのプロダクトのゴールを見据えること、ビジネスサイドとエンジニアサイドを分けるのであればビジネスサイドとの連携を密にして方針をきちんと共有することがビジネス面で大切であると声を大にして言いたい。
データサイエンス力
前述のKPIから実際に実現可能な推薦システムに落とし込むという際にこのデータサイエンス力が必要になってくる。その際、まず王道と呼ばれるような手法を用いて試行錯誤しながら適宜ビジネスサイドとどのくらいできそうなのかを報告し、連携を取ることが大切になる。このときに用いる、データの性質や各推薦アルゴリズムの長所・短所などといった、俯瞰的なデータサイエンスの知見がデータサイエンス力であり、これにより試行錯誤の時間を短縮することができる。
このデータサイエンス力に関して私はそこまで心配していない。というのも、一般にエンジニアは勤勉で技術に関して貪欲であることが多く、特に機械学習の領域ではKaggleのような実践の場が整備されているからである。
データエンジニアリング力
実際に推薦システムを組み込むときに、仮にその推薦システムがとても優秀だったとしてもその推薦システムが計算するのに時間がかかりすぎるというような場合、その推薦システムを使うことができなくなってしまう。そのようなことを防ぐために処理の並列化やデータベースの設計、チューニングを工夫するといったようなデータエンジニアリング力が大切になる。
このデータエンジニアリング力についても私は危惧していて、Kaggleなどでは自身のコンピュータ、それかクラウド上にデータを置いてコードをそのデータとともに走らせればよいだけであるため、推薦システムに使うような、データを処理して推薦リストを作成する演算を行ったものをデータベースに格納する、というような一連の処理のパイプラインを整備するというようなことがないからである。
推薦システムのプロジェクトの進め方
先程の3つのスキルを持っている人を揃えて、次にどのように推薦システムのプロジェクトを進めるかについて以下のような7つのプロセスに分解して説明する。なお、()内に上記にまとめた必要な力のうち、特に必要なものを記載する。
1. 課題定義(ビジネス力)
2. 仮説立案(ビジネス力)
3. データ設計・収集・加工(データエンジニアリング力)
4. アルゴリズム選定(データサイエンス力)
5. 学習・パラメータチューニング(データサイエンス力)
6. システム実装(データエンジニアリング力)
7. 評価、改善(ビジネス力)
1. 課題定義(ビジネス力)
まず「売上を2倍にしたい」「会員登録を2倍にしたい」といったようなそもそもの目的を明確化することから始まる。
次にその目標をKPI化していく。例えば、1ユーザーあたりの売上を2倍にするのか、ユーザー数自体を2倍にするのか、といったような感じである。
そこから出たKPIから、データやユーザーに対するヒアリングを用いて現状に対する課題を分析してまとめる。
2. 仮説立案(ビジネス力)
まず、その出た課題に対する、解決策、重要度、コストを算出し、そこからROIが高い施策から取り組む。(ROI : Return On Investmentの略で、ここでは費用対効果ともいえる)
3. データ設計・収集・加工(データエンジニアリング力)
推薦システムには第1章内の推薦システムの種類にもあるように
- ユーザー及びアイテムのコンテンツ情報
- ユーザーとアイテムのインタラクション情報
があり、これにあてはまる情報でどのようなデータが蓄積されているかを整理する。
4. アルゴリズム選定(データサイエンス力)
必要なデータや求められる予測精度などから今回必要なアルゴリズムを選ぶ。
推薦システムにおいても普段の機械学習同様に少ないコストで一定の精度が出て、そこからコストをかけても精度の伸び幅が小さくなる。普段と同様にして、まずは簡単なアルゴリズムをベースラインとして実装することから始めるのが大切である。
5. 学習・パラメータチューニング(データサイエンス力)
実際のシステムに組み込む前に、過去のデータから推薦システムの学習やチューニングをすることで、オフラインで推薦システムの良さを実証する。
この際大切なのは、普段機械学習で使うようなRecallやPrecisionも大切であるが、データを入れた際にどのようなものが推薦されてそれがどれほど納得できるようなものかといった、実用的な指標も重要になっている。
6. システム実装(データエンジニアリング力)
オフラインで良い推薦システムが完成したら、これを実際に実システムに組み込む。 このときに実際にMLOps的なデータのパイプラインを設計して組むことになる。その際、1日1回、1週間1回というように決まったタイミングに推薦リストを更新してユーザーに提供するバッチ推薦、ユーザーの行動履歴を即座に反映したリアルタイム推薦のどちらかによってもシステムの構成が変わることに注意する。
7. 評価、改善(ビジネス力)
推薦システムをリリースして、そこで実際に効果があったかどうかを検証し、リリース後のユーザー行動を分析して当初の仮説の検証をする。実際に効果があったかについてについては、推薦システムのみを見るのではなく全体を見て悪影響が無いかを見るのが大切である。
第3章 推薦システムのUI/UX
UI/UXというものは、我々機械学習エンジニアにとってあまり考えたことがないかもしれないが、第1章の機械学習を種類分けするとインプット × プロセス × アウトプットという3つに分かれ、どれだけ良いインプットやプロセスがあったとしても、このアウトプットが無ければ推薦システムは完成しないのである。
ユーザーの目的から見たUI/UXの事例
どのようなものがあるかは実際どのようなものがあるか見たほうが早いので、早速事例を見ていくことにする。
ユーザーの目的ごとに4パターンに分け、それぞれの解説、実際使われているサービス、種類によっては弊社Ubiqで応用するとしたらどのような感じか、というように紹介していく。
適合アイテム発見とは、ユーザーが自身の目的を達成するためのアイテムを1つでもいいから発見する、という場合を指す。例えば、「東京駅周辺で中華料理店を探している」というような、ユーザーの好みに合ったアイテムを1つでもいいから発見する、ということが求められている。
この適合アイテム発見の例では、以下のように食べログがよい例であると考えられる。
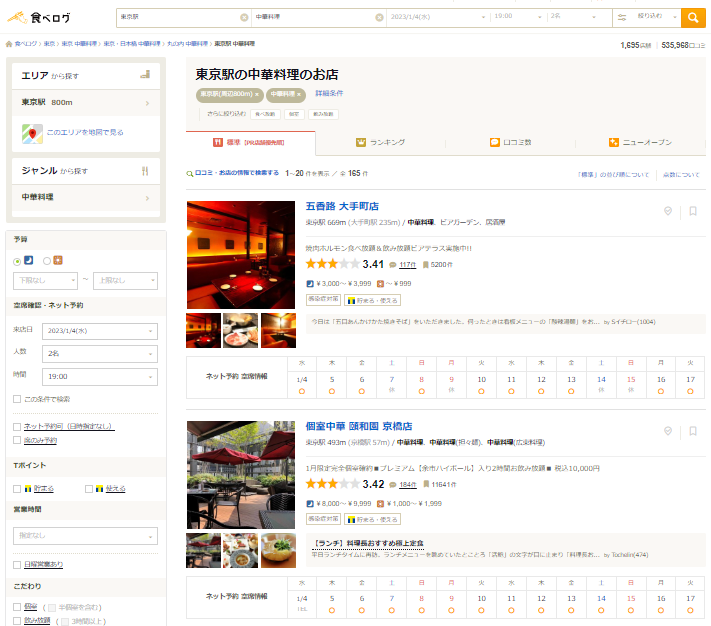
このように食べログでは、ユーザーの好みにあう可能性が高いものから順に表示されて、ユーザーがこの中から行きたいお店を選ぶことが容易になっている。
弊社のUbiqは、「クリエイターと、世界の見方を変えて行く」 をテーマとした、インスタ、TikTokチックな画像や動画をメインとした次世代メディアである。
そのUbiqについて考えたときに、Ubiqは検索システムを搭載しているが、そもそもユーザーが「1つでもいいから目的を好みに合ったアイテムを発見する」という適合アイテム発見の状態になることが考えつかないので、これに関しては注目しないことにする。
適合アイテム列挙は、ユーザーが自身の目的を達成するのに適合したアイテムをできるだけすべてサービス上で発見したい場合を指す。例えば、「予算20万円以内で東京駅付近の賃貸物件を探す」という目的が考えられる。これだけ見ると、適合アイテム発見と同じような気がしてしまうが、賃貸の例で考えると条件にあった物件をできるだけすべて表示させないと、あとからより良い物件を見つけてしまったときにどうしようもない後悔をユーザーに与えてしまうことに留意せねばならない。
以下のホームズの例を見ると、できるだけユーザーの条件をを直接反映できるように条件を無数に用意してあることがわかり、またそれによってユーザーが見るべき物件数も絞られて、条件に合うすべての物件を見ることが可能になっている。
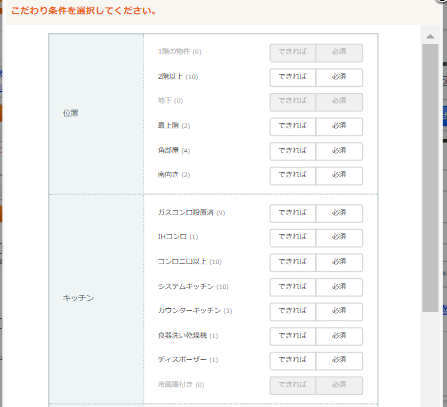
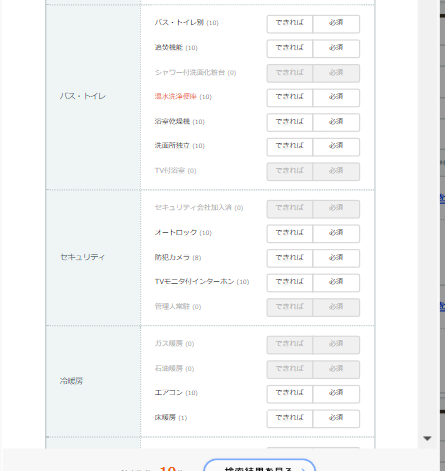
Ubiqについては、あるジャンルの投稿をできるだけすべて見なくてはならない状況が考えられないため、適合アイテム発見と同様に適合アイテム列挙についても割くべきリソースは無くてよいと考えられる。
アイテム系列消費は、閲覧したり消費したりしていく中で、推薦されたアイテムの系列全体から価値を享受することが目的である場合を指す。例えば、YouTube Musicの中で、あるジャンルの曲をまとめて自動でセットリストにして表示するというものがある。
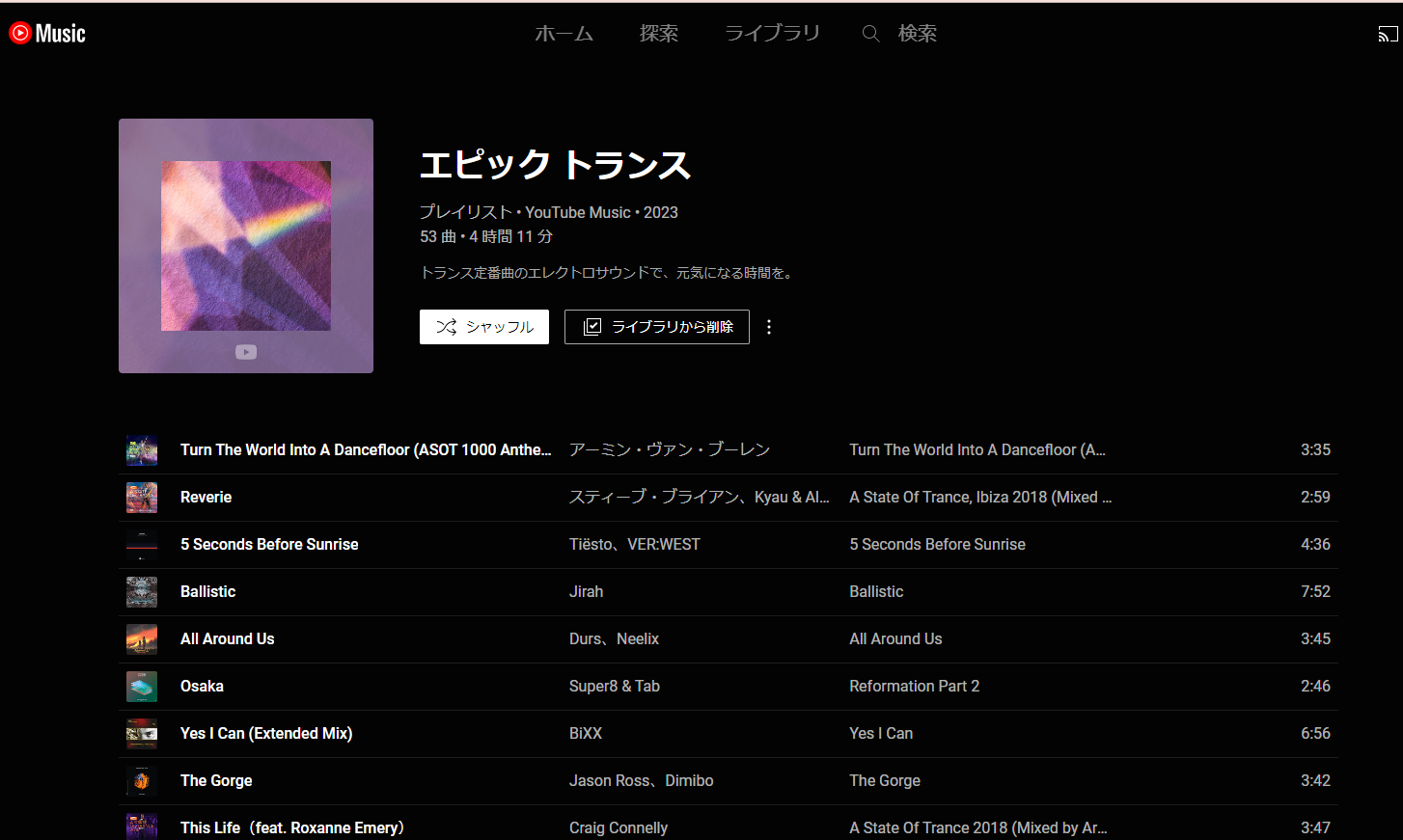
Ubiqについて考えると、アプリ内検索を使い検索にヒットしたアイテムをユーザーに提示し続けることで、ユーザーがUbiqを使う時間というものを延ばすことができると考えられる。
またそれだけでなく、「冬といえばコレ!」などといった様々なジャンルの投稿のセットをあらかじめトップページに並べておいて、その文面に興味を持ったユーザーが開きそのジャンルのセット内の投稿を次々ユーザーに見せることで、普段見ないような投稿をユーザーに推薦することができる。
ただ、このUbiqが先ほど挙げたYouTube Musicとは違う点は、YouTube Musicでは同じ曲を何回推薦してもよいのに対し、Ubiqでは同じ投稿を同じユーザーに推薦し続けるのはユーザーの満足度を下げることにつながることに注意する必要があることである。
サービス内回遊は、ユーザーが利用しているサービス本来の目的を達成するためではなく、ただアイテムを閲覧すること自体が目的になっている状態を指す。例えば、Airbnbは本来観光用の宿泊施設や賃貸物件を探すためのサービスであるが、ただ単にサイト内で「どこに行ってみるとしたらこんな感じ」ということをユーザーが想像して楽しむという使い方にも対応している。それにより、実際に旅行の際にAirbnbをユーザーが想像のプラン通りに行ってみよう、ということでサービスを使ってもらうということが期待できる。
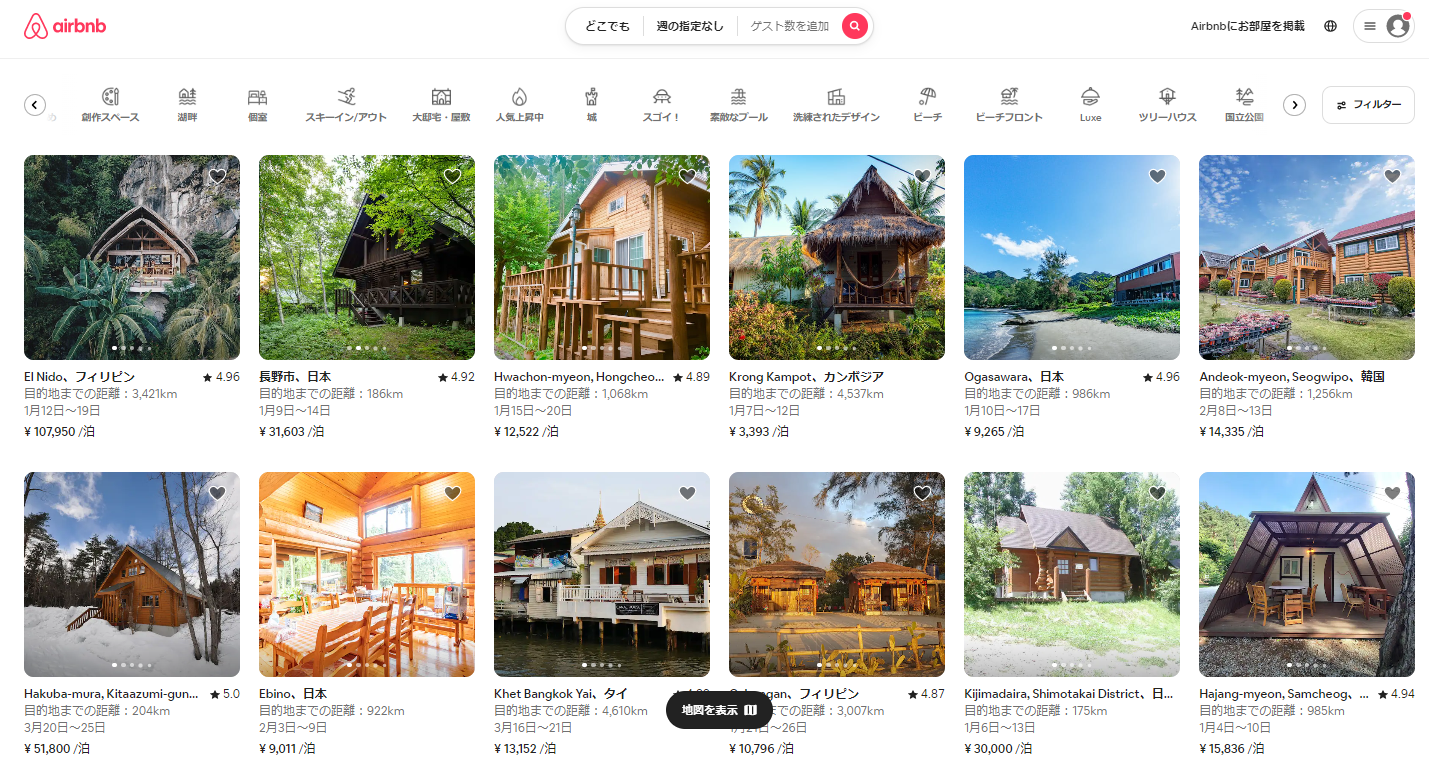
Ubiqでは、そもそもどのくらいサービス内で時間を過ごしてもらい、その間に広告を何回表示することができるか、といったようなサービス内回遊自体が本来の目的になっている。また、このようなサービス内回遊ではいかにユーザーの満足度を高めるかが重要になってくる。これらから考えると、Ubiqでは、なるべく多くのユーザーが興味を持つであろう投稿をまとめて簡単に閲覧できるようにしたり、ユーザーの興味を惹きやすいようなジャンルの投稿をまとめて表示できるようにするのがよいと考えられる。
サービス提供者側から見たUI/UX
先ほどまではユーザー側から見たUI/UXについて述べたが、次にサービス提供者の目的から考えたUI/UXについて述べていく。
新規・低利用頻度ユーザーに対しては、離脱して他のサービスに行ってしまう前に良い体験を提供するだけでなく悪い体験をさせないことが重要である。その際に、統計情報から選んだリストや専門家が選んだリストを推薦する概要推薦をすることが大事である。
Ubiqでは、投稿を統計情報や専門家の意見からまとめて見やすいところに配置するのがよいと考えられる。
ECサイトなどではサービスが提供するアイテムや広告がサービス提供者の利益を最優先しているのではないかと不信感を抱くことがあり、サービスの信頼性上昇のためにはそのような不信感を取り除くことが大事になっている。そのためには、利用者による評価を用いたり、サービスが利用者のためにより良い推薦をしようとしていることをアピールすることが大事になる。
利用頻度向上させたり、離脱ユーザーを復帰させたりするには通知サービスを使うのが最重要である。
Ubiqでも、いち早く通知サービスを導入しなくてはならない。この際に、頻繁に通知を送ってしまうと逆にユーザーがサービスを使わなくなってしまうので通知の頻度をよく考えなければならない。
ECサイトなどではアイテムをユーザーに同時購入してもらうことでより大きな利益を得ることができる。この際に大事になるのは関連アイテム推薦である。あるアイテムを買い物かごに入れた際に、他のユーザーがどのようなものを買っているかのようなものが例としてある。
Ubiqでは、ユーザーがある投稿を見た後に、同じ投稿を見た他のユーザーが次にどのようなものを見ているかなどを使って推薦するのがよいと考えられる。
新規ユーザーを増やすということも大事であるが、既に長くサービスを使ってくださっているユーザーを大切にすることもまた重要である。その方々のためには、パーソナライズという形で、よりその人に合ったサービスを提供することでロイヤリティを向上させることができる。
Ubiqでは、長く使えば使うほど利用履歴が溜まっていき、データ数が増えるため自動的により良い推薦サービスを提供できるゆえあまりここに関して考える必要はない。
その他各論
以降では、UI/UXに関連しうるトピックについて箇条書きでまとめていく。
- 類似度を使う際は、アイテム同士の関係性も考える必要がある。パソコンを買った人にまた似たようなパソコンを推薦しても買ってもらえる可能性は極めて低い
- ユーザーにとって目新しさというのは重要な観点ではあるが、ユーザーに興味が無ければ意味がない。そうではなくて、推薦するアイテムの多様性に注目することがある
- 推薦してはいけないアイテムというものも存在する。既に何回も推薦したアイテム、一度買った消耗品出ない商品、違法なアイテムなどがある。
- 推薦理由を提示することで推薦の効果、推薦の透明性、ユーザーの満足度を向上できる。
第4章 推薦アルゴリズムの概要
この章では、推薦システムにどのようなアルゴリズムがあるのかをまとめている。
この章は推薦システムの定義「複数の候補から価値のあるものを選び出し、意思決定を支援するシステム」の前半 「複数の候補から価値のあるものを選び出し」 に対応して、推薦システムの3つの構成要素「インプット × プロセス × アウトプット」の中の、「プロセス(推薦の計算)」 に対応する。
推薦アルゴリズムの分類と概要
推薦アルゴリズムは大きく分けると内容ベースフィルタリングと協調フィルタリングに分けられる。これらについてそれぞれまとめていく。
内容ベースフィルタリングは、ユーザーがどのようなアイテムを好むかというデータであるユーザープロファイルと、アイテムの様々な性質を表す特徴についてまとめたアイテム特徴の一致度を類似度としてこれをもとにアイテムをユーザーに推薦するアルゴリズムになっている。
ユーザープロファイルは、ユーザーの好むアイテムの特徴を並べたリストのようなものになっていて、例えば本を推薦する場合
ユーザー1
好きな作者:hoge田 hoge朗
好きなジャンル:ミステリー小説
好きな出版社:A社
ユーザー2
好きな作者:fuga田 fuga朗
好きなジャンル:自己啓発本
好きな出版社:B社
というようになり、これは、ユーザーの行動履歴、例えば購入履歴や視聴履歴をまとめ、ユーザーの好むアイテムの特徴(好きな作者、好きなジャンル、好きな出版社)を、それぞれ行動履歴の中から最も多く出現しているもので登録する間接指定型と、ユーザーに直接好きなアイテムの特徴を聞いてそれを直接ユーザーの好むアイテム特徴として登録する直接指定型がある。
アイテム特徴は、ユーザープロファイルと同じような形式の、アイテムの特徴を並べたリストになっていて、同じく本についてだと、
アイテム1
作者:hoge田 hoge朗
ジャンル:ミステリー小説
出版社:C社
アイテム2
作者:fuga田 fuga朗
ジャンル:ビジネス書
出版社:B社
というようになり、このアイテム特徴を登録するにはさまざまな方法がアイテムの種類によって考えられ、ただアイテムについている属性(タイトル、ジャンル、作者、出版社……)の他に、音楽や画像ならその音声や画像を解析したデータも用いることができる。
このユーザープロファイルとアイテム特徴からその類似度を求める。上の例だとユーザー1に対してはアイテム2よりもアイテム1の方が類似度が高く、ユーザー2に対してはアイテム1よりもアイテム2の方が類似度が高いことがわかる。
協調フィルタリングにおいても2種類に分けることができて、推薦のタイミングで利用するデータをすべて使い推論するメモリベース法と、あらかじめデータからモデルをつくっておいて推論時にその事前に作成してあるモデルを使って推論するモデルベース法に分けることができる。
メモリベース法には、推薦を受け取るユーザーと好みが似ているユーザーに注目して推薦を行うユーザー間型メモリベース法と、推薦を受け取るユーザーの好むアイテムに似ているアイテムに注目して推薦を行うアイテム間型メモリベース法がある。
ユーザー間型メモリベース法では、まず推薦を受け取るユーザーの行動履歴(視聴履歴や購入履歴)と似た行動履歴を持つユーザーを数人探し出す。次に、見つけ出した好みが似ているユーザーが好むアイテムを探して、それを推薦を受け取るユーザーに推薦する。
モデルベース法で使うモデルには、クラスタリングを使うモデル、回帰問題や分類問題として評価値を直接分類するモデル、トピックモデル(テキストに含まれるトピックを抽出するもの)を利用するもの、ユーザーとそのユーザーのアイテム評価の行列である評価値行列を行列分解するものなどが挙げられる。
一般にメモリベース法では、毎回ユーザーやアイテムを探して予測するため予測に時間がかかるが、常に最新のデータを反映させることができる。反対にモデルベース法では、モデルをあらかじめ作っているため予測に時間はかからないが、最新のデータを反映させるにはモデルを作り直す必要がある。
内容ベースフィルタリングと協調フィルタリングのどちらを使うか
内容ベースフィルタリングと協調フィルタリングについて、以下に述べる7つの観点から比較する。
多様性について、協調フィルタリングでは推薦を受けるユーザーが知らないアイテムを、そのユーザーに嗜好が似ているユーザーがいれば知ることができるが、内容ベースフィルタリングではユーザーが知らない作者やジャンルの情報が反映できない。
ドメイン知識を扱うコストについて、協調フィルタリングではアイテムやユーザーについての詳しい知識は不要であったが、内容ベースフィルタリングでは適切にドメイン知識を利用できないと良い推薦ができない。
コールドスタート問題(サービス内でのユーザーやアイテムに関する情報が少ない、特に新規ユーザーや新規アイテムについて適切に推薦を行うことが難しい問題)について、協調フィルタリングだと、このような場合に似ているユーザーやアイテムを見つけられなくなってしまう。内容ベースフィルタリングであれば、新規ユーザーに対してアイテムへの嗜好を入力してもらうことで解決できる(新規アイテムについても特徴を登録するだけなので問題ない)。
ユーザー数が少ないサービスにおける推薦についても、コールドスタート問題と同様に協調フィルタリングではなく、内容ベースフィルタリングを使う方がよい。
被覆率(サービス内のアイテムのうちユーザーに推薦することができるアイテムの割合)について、協調フィルタリングではユーザーから試されていないアイテム、評価されていないアイテムは推薦することができないが、内容ベースフィルタリングではどのアイテムも推薦できる。
アイテム特徴の活用について、協調フィルタリングでは同じ商品の色やサイズ違いでも全く違うものと捉えられるほどアイテム特徴を使うことができないが、内容ベースフィルタリングでは色違いの同じ服は推薦しないなど、アイテム特徴を活用して柔軟に推薦できる。
予測精度について、それぞれのアルゴリズムごとに得意不得意があるゆえ常にどうとは言えないが、一般に協調フィルタリングの方が内容ベースフィルタリングより高い精度が出ると言われている。
内容ベースフィルタリングか協調フィルタリングかということであるが、前提として、この2種類のアルゴリズムを適切に組み合わせたハイブリッドな方法を用いることが多い。
一般的な方針として、まずサービス内のデータ量で考えることが多い。データ量が少ないうちは内容ベースフィルタリングで、多くなってきたら協調フィルタリングに切り替えていくことが多い。
また、推薦システムの提供形態、多様性の観点からどちらを使うか決めることも考えられる。
嗜好データの特徴
嗜好データは、直接ユーザーから獲得する明示的獲得と、ユーザーの知らないところで得る暗黙的獲得がある。
明示的獲得ではデータ量が少ないが、データが正確で、未評価と不支持の区別が明確で、ユーザーがデータを渡したことを認知できる。
反対に暗黙的獲得ではデータ量が多いが、データが不正確で、未評価と不支持の区別が不明確で、ユーザーがデータを渡したことを認知できない。
嗜好データを扱う際、サービス内の殆どのユーザーとアイテム間の嗜好データは得られない、つまりデータがスパースであることに注意しなくてはならず、うまく嗜好データの獲得方法を設計するのが大事になる。
また、そのようにしてユーザーのレビューを得れたとしても、同じユーザーでも少し後に評価した場合に異なる評価値になる評価値の揺らぎ、サービス内で人気のあるものが表示されやすい人気バイアス、高い評価をつけがちな人がいたり低い評価をつけがちな人がいるユーザーによるバイアスがあり、それを考慮してアルゴリズムを選択する必要がある。
第5章 推薦アルゴリズムの詳細
この章については別の記事にまとめることにする。