*2018年の記事ですが、一部2021年に変更を加えております。
Microsoft Azure Tech Advent Calendar 2018の第16日目です!
https://qiita.com/advent-calendar/2018/microsoft-azure-tech
本記事では、AzureのクラウドHPCの中心であるCycleCloudについて、環境構築やシンプルなクラスター作成・ジョブ実行を行っていきます。
Azure CycleCloudとは?
Azure上で、HPCワークロードの実行・管理に必要なクラスターの管理機能を提供する、Azure上では無料で利用できるソリューションです。もともとMicrosoft社が買収したCycleComputing社が持っていたソリューションをAzureに最適化しています。PBS Pro, Slurmはじめ、HPC分野で一般的に利用されるスケジューラーがあらかじめ入ったクラスターをデフォルトのテンプレートからすぐに展開できるため、既存のHPC環境と同じ感覚でユーザーがクラウド環境を利用できることがポイントです。
またノードの構成・監視・オートスケール・権限管理なども提供するので、管理者はCycleCloudから一元的にAzureのリソースを管理できます。
https://azure.microsoft.com/ja-jp/features/azure-cyclecloud/
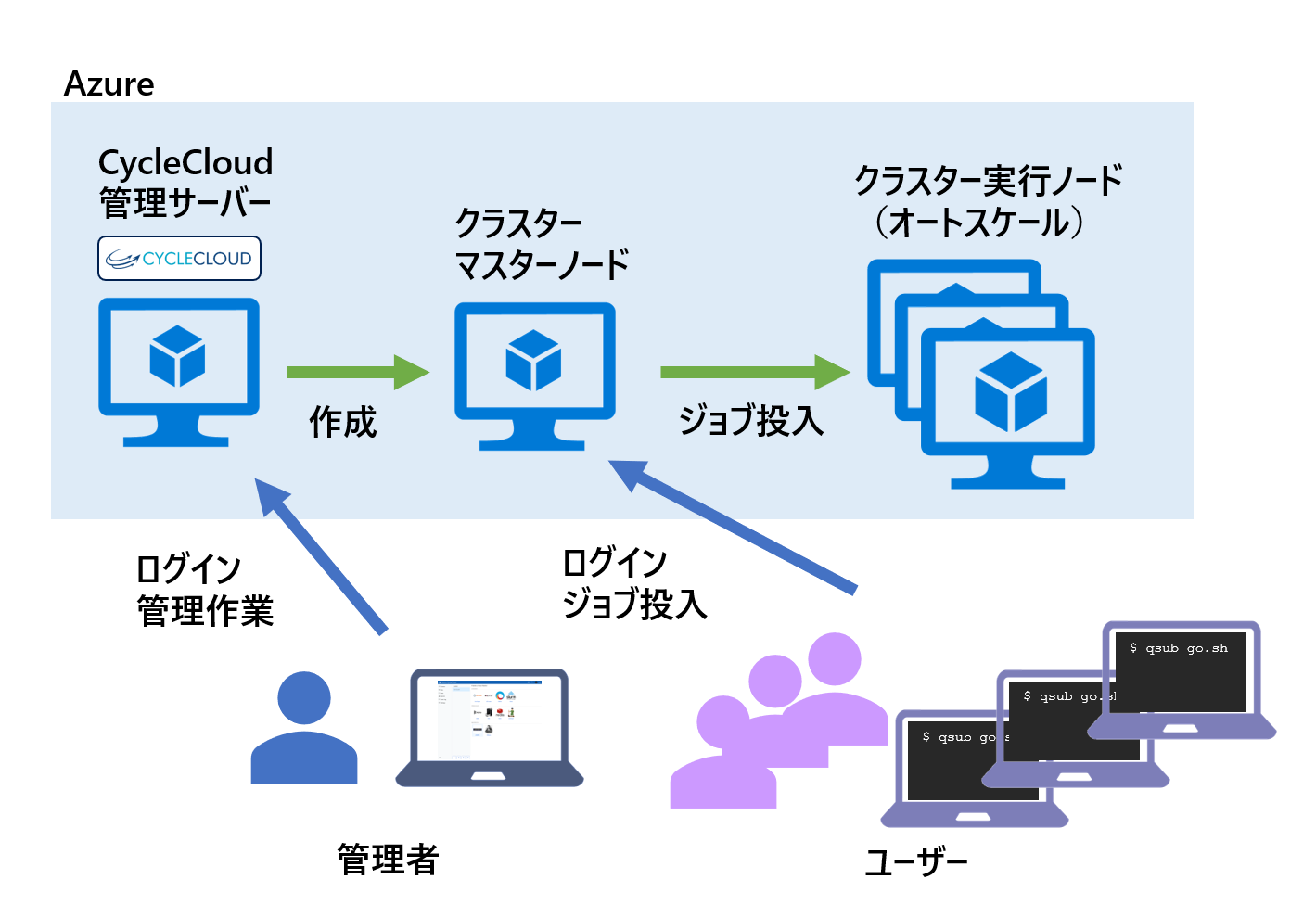
概要イメージ図
イメージ図は下記になります。1台管理サーバーが立ち、管理者は環境をすべてこの管理サーバーからコントロールします。計算用のクラスターは、ユーザーがログインして作業を行うマスターノードと実際にジョブの計算が行われる実行ノードに分かれます。裏側のAzureの仕組みとしては、管理サーバーとマスターノードは仮想マシン、実行ノードは仮想マシンスケールセットで構成されています。
そもそもクラウドHPC / Azure上でのHPCとは?
オンプレミスのスーパーコンピュータなどで行ってきた計算をクラウドでオンデマンドで利用できるリソースを使って実行してしまおうというのがクラウドHPCです。
特にMicrosoftのパブリッククラウドであるAzureは、HPC用のコンピュート環境をはじめ、当初からHPC利用に投資をしてきています。
Azure上でのHPC用のコンピュート環境
CycleCloudはHPC環境の管理を最適化するものです。Azureのコンピュートリソースをユーザーや管理者に使いやすい形で提供することが目的ですが、実際にどのコンピュートリソースを使うかはユーザーの設定次第です。下記に、HPC利用におすすめな仮想マシンについて簡単にまとめます。
仮想マシン
Azureでは、仮想マシンはシリーズ(例: Aシリーズ、Bシリーズなど)と呼ばれる用途別のカタログから、自分のワークロードに合わせて最適なものを選べるようになっています。さらにシリーズの中でCPUのコア数や・メモリ容量・InfiniBandの有無(後述)などが異なるサイズ(A1, A2, A3など)を1つ選択して仮想マシンを作成します。シリーズ(一部シリーズまたぎには制限あり)、サイズは作成後にポータル画面から簡単に変更可能です。
特にH (HPCの頭文字ですね!)シリーズが最高水準のCPUを搭載し、InfiniBandを利用できるサイズもあるためHPC利用に最適です。またGPUを利用する場合は、NCシリーズ(NがGPUがつくシリーズ、特にNCはGPUを使ったComputingにフォーカスしたシリーズ)が最適です。
〇H系統シリーズ
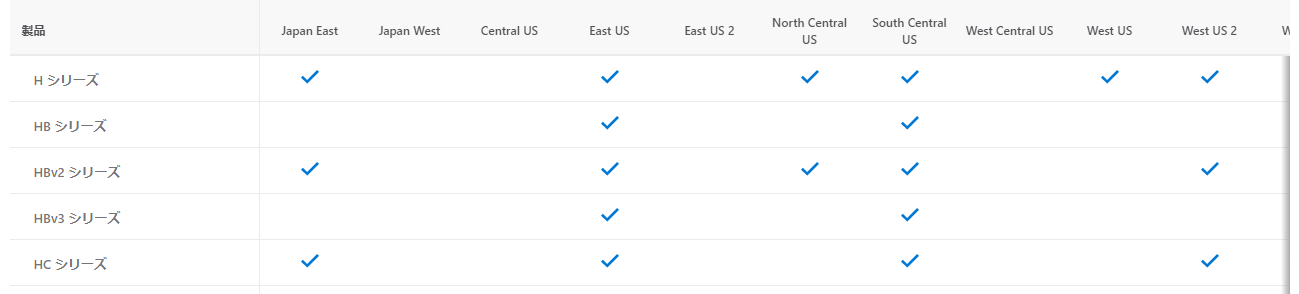
H系統の中には、H、HB、HCの3系統があります。Hシリーズは古いシリーズのため、HB(v1-v3) または HCシリーズをご検討ください。HB は AMD EPYC CPU, HC は Intel Xeon CPU を搭載したシリーズであり、どちらも Mellanox Infiniband が利用できるようになっています。特に、HB v2 と HB v3 はどちらも Mellonox HDR Infiniband が搭載されており、200Gbpsで通信が可能です。スペックは、公式ドキュメントにて詳細に情報提供されています。
また、2021年9月時点での日本と米国のリージョンの提供状況については下記になります。
〇N系統シリーズ
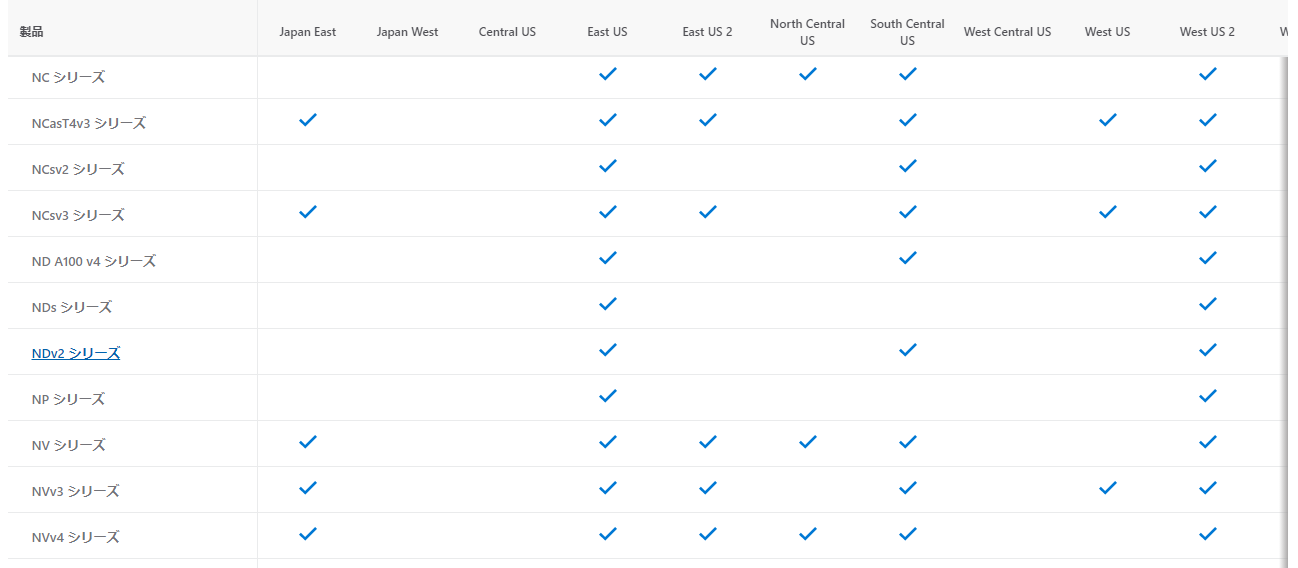
N系統の中には、NC、ND、NVの3つのシリーズがあり、それぞれコンピューティング、Deep Learning, 可視化に特化したものになっています。特に NC v3 と ND v2 は NVidia Tesla V100, ND A100 は Tesla A100, NCT4 は Tesla T4 の GPU を搭載しています。詳細は、公式ドキュメントをご参照ください。
また、2021年9月時点での日本と米国のリージョンの提供状況については下記になります。
*仮想マシン注意点
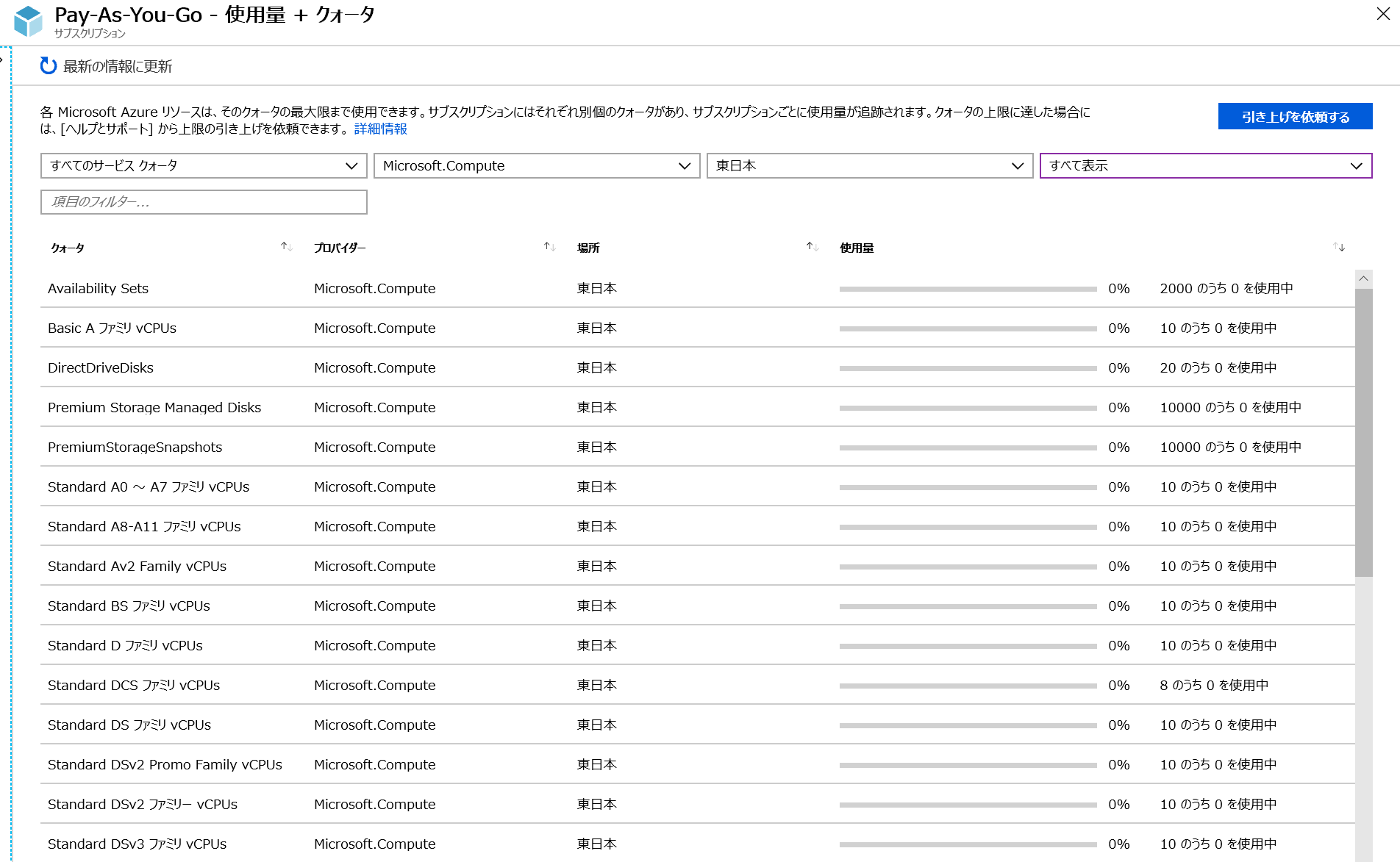
Azureでは予期せぬリソースの使い過ぎを防ぐため、サブスクリプションに対してクォータが設定されています。仮想マシンに関しては各リージョン、各シリーズに対して利用できるコア数が定義されています。これを上昇させるにはサービスリクエストをAzureポータルからあげていただく必要があります。
現時点でのクオータの値については、Azureポータルで、サブスクリプション > 使用量 + クォータから確認ができます。また、右上「引き上げを依頼する」からリクエストがあげられます。
CycleCloudを使ってみる
ここからは公式ドキュメントのチュートリアルに沿って、CycleCloudの環境の構築・ジョブの実行を行ってみます。今回は、CycleCloud 7 を利用します。
①CycleCloudのインストールとセットアップ
前提条件
・Azureのサブスクリプション
・SSHのキー
作業開始
CycleCloud仮想マシンやクラスターへのログインに必要な、SSHの鍵を作成します。
ssh-keygen -f ~/.ssh/id_rsa -N "" -b 4096
公開鍵を確認します。
cat ~/.ssh/id_rsa.pub
次に、Azure マーケットプレースから、CycleCloud を構成するリソース群を作成していきます。Portal の検索窓から CycleCloud と入力すると出てきます。
7.9を選び作成を押します。
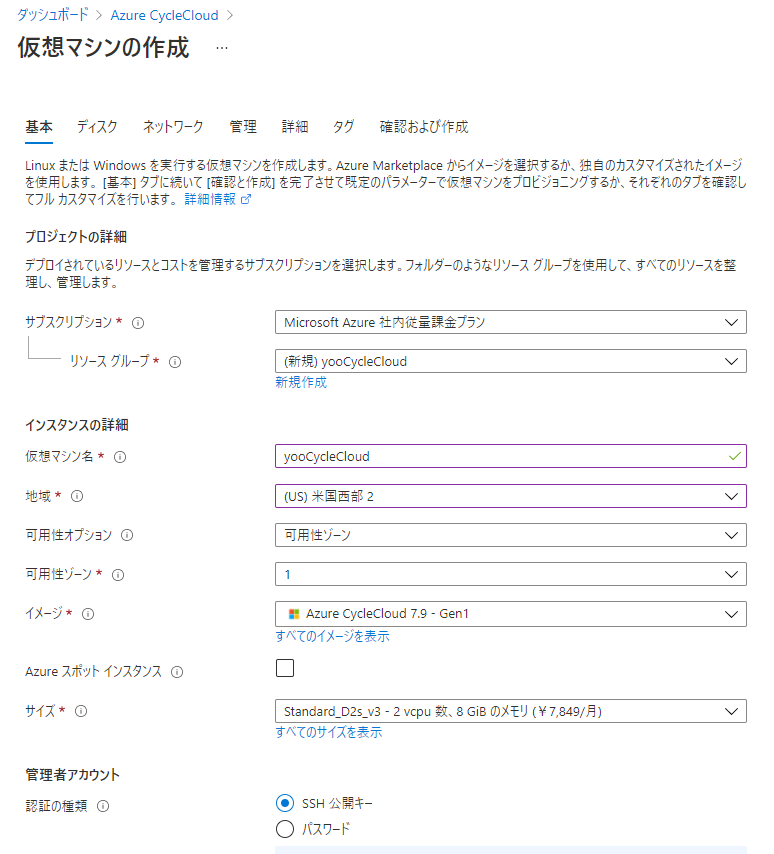
必要な項目を入力していきます。SSHの公開キーは先ほどのものを利用します。
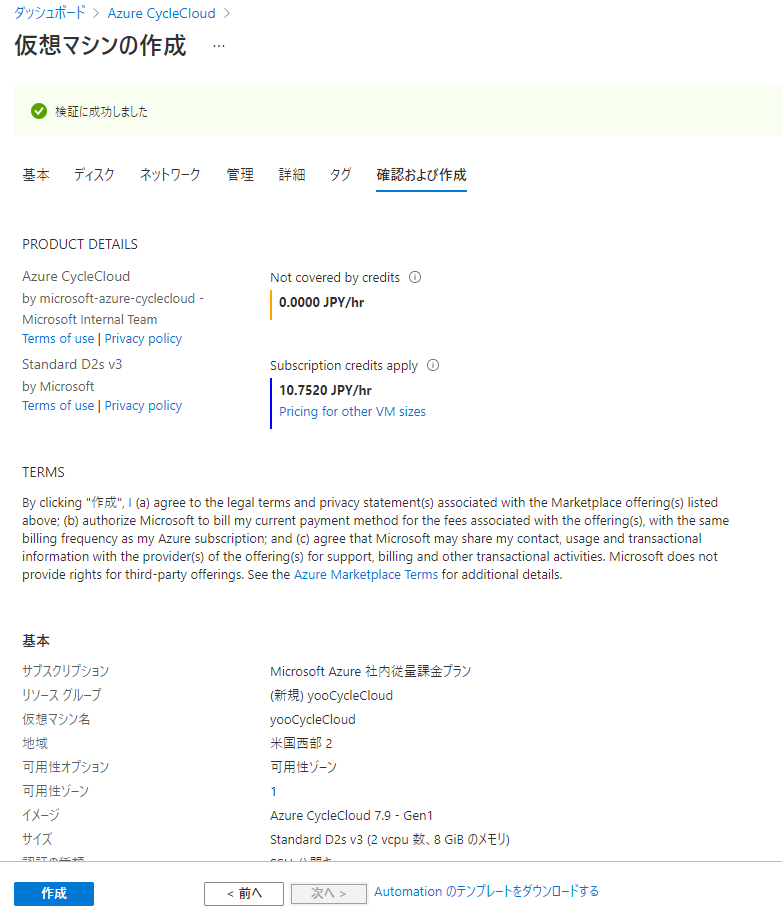
設定項目を入れ終わったら作成を押し、デプロイを待ちます。
作成が完了したら、DNS名を設定しておきます。

また、今回はCycleCloudが属するサブスクリプションに対する共同作成者権限を VM のマネージドIDにふっておきます。本来はカスタムロールが望ましいです。
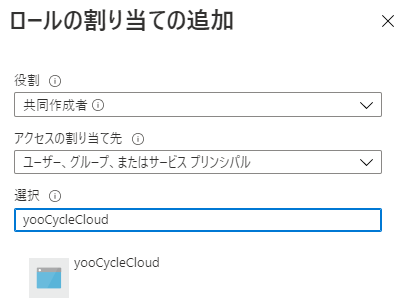
ブラウザから、https://<そのDNS名>でアクセスします。(自己署名証明書を利用しているため警告が出ますがスキップします。)
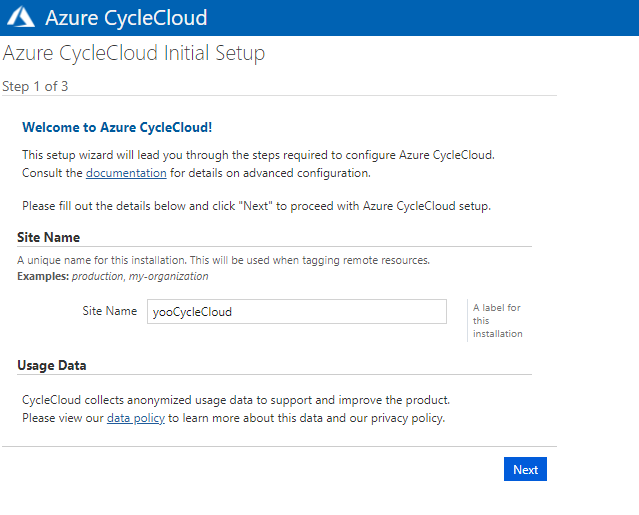
サイトの名前を入力します。
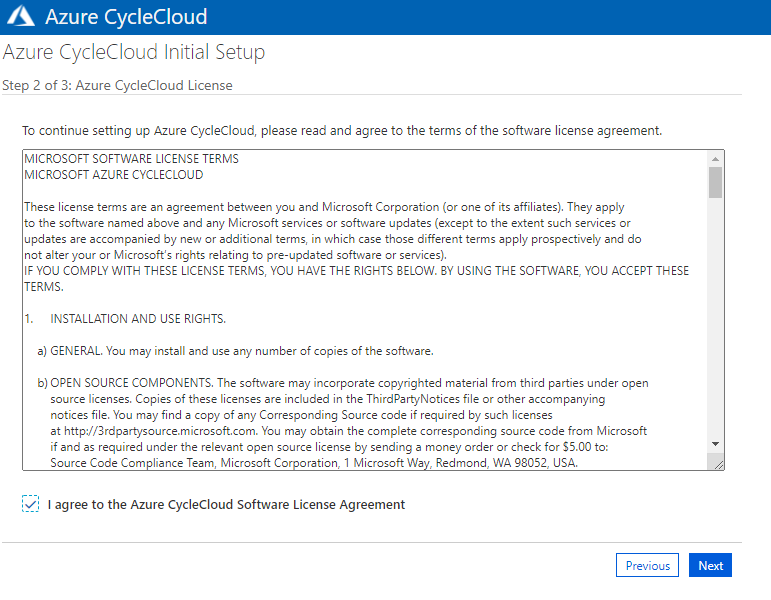
License Terms を読み同意します。
諸々入力します。SSHの公開キーはさきほどと同じものを入れます。
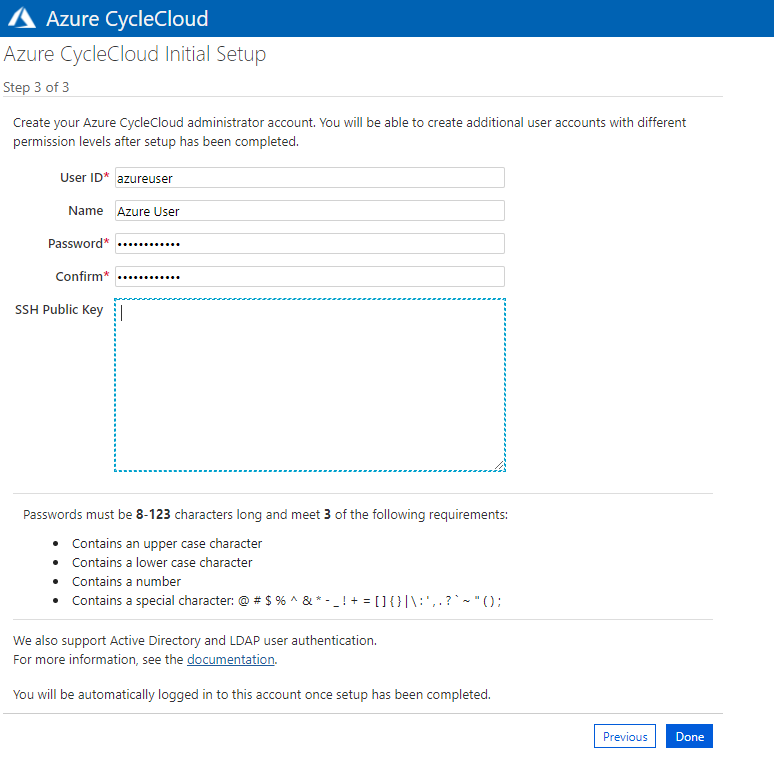
そうすると CycleCloud の画面が出てきますが、アカウント設定が無いというメッセージが表示されるので、Click here からアカウント構成に行きます。
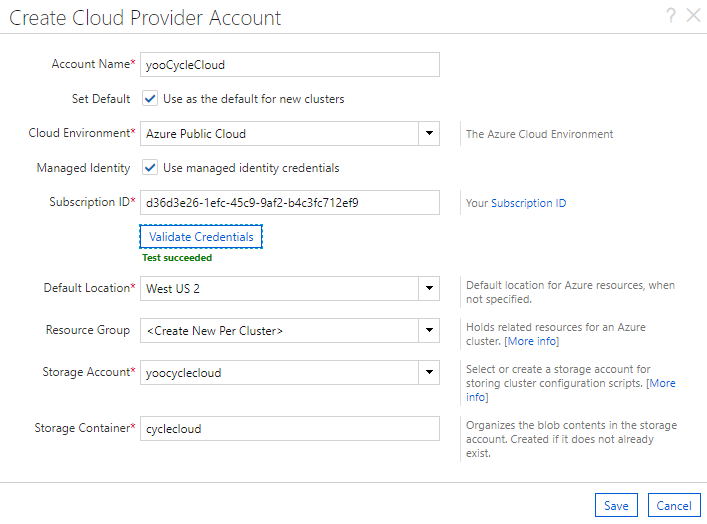
Create を押し、Managed Identity を設定します。
②CycleCloudでクラスターを作成する
次に実際にHPCユーザーが使うクラスターを作成していきます。
左上のメニューからClustersを選択すると、最初から使えるクラスターメニューが出てきます。

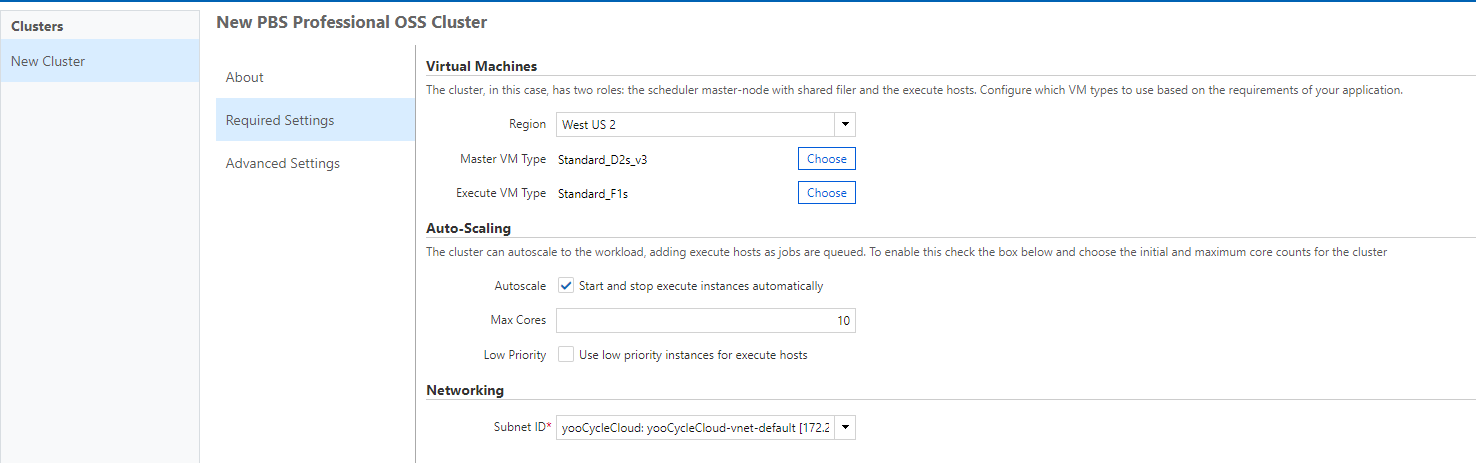
今回はSchedulersの中から、PBS Professional OSSを選択してみます。すると、クラスターの設定メニューが出てくるので、クラスター名やMaster VM(ユーザーが作業を行うノード)・Execute VM(実際に計算を行うノード)のサイズ設定が行えます。仮想ネットワークサブネットは、末尾が-computeとなっているものを選びます。また、オートスケール(今回は有にします。これによりジョブの投入・終了に合わせてノード数が自動変動します)や低優先度仮想マシン(最大80%引きで使えるが、データセンターの混み具合によってジョブ実行中にジョブが強制終了してノードが確保できなくなる可能性があるマシン)も設定可能です。
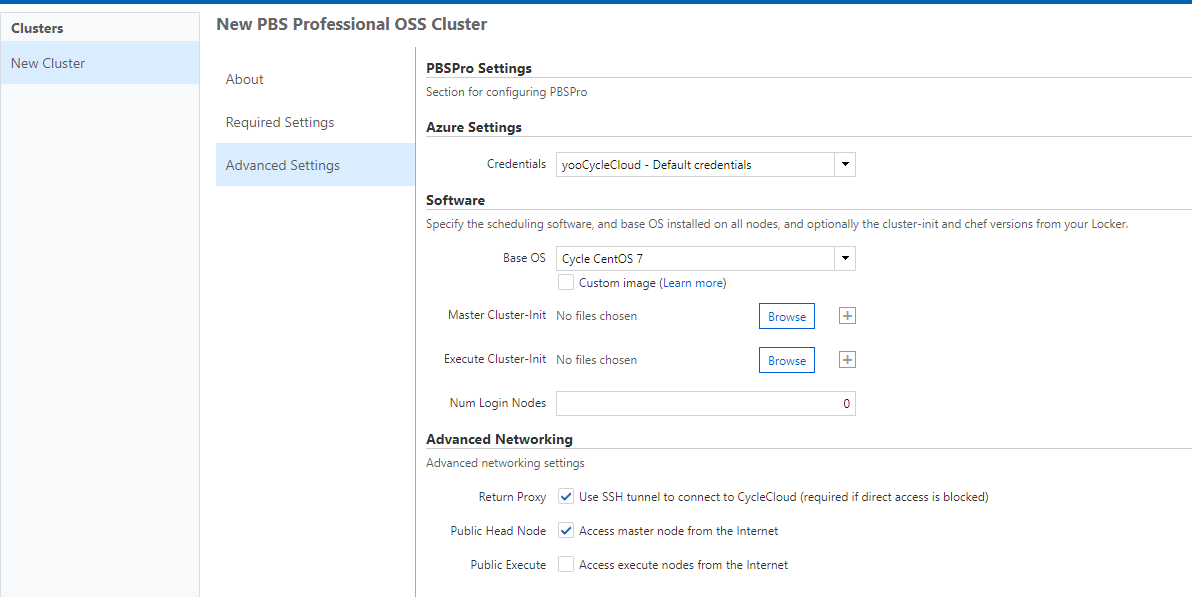
Advanced Settingsでは、ベースOSや各ノードにインストールするソフトウェアの設定などを行うことができます。ちなみに、デフォルトのCent OSのイメージは、仮想マシンサイズがRDMA (InfiniBand)対応している場合は、RDMAのドライバーが自動的に組み込まれます。
saveを押すとクラスターが作成されます。クラスター一覧から、作成したクラスターを選択します。
ここでStartを押すと、マスターVMが作成されます。Start後、Terminateを押すと仮想マシンがディスクも合わせて削除されます。マスターVMのShut Downを押すと、仮想マシンがDeallocateされます。
以上で、シンプルなクラスターの作成が終了です。ノードの台数管理(オートスケール設定時)や構成管理、死活監視などはすべてCycleCloudがサービスとして提供しています。
③クラスターに実際にジョブを投入する
PBS のクラスターには、デモ用のスクリプトが置いてあるので実行してみます。
まず、CycleCloud のクラスターの画面で、masterをクリックします。すると下にノードの情報が出てきます。ここでConnectをクリックすると、SSHに必要な情報が出てきます。これを使って、CloudShellからマスターノードにSSHでアクセスします。
ssh <ユーザー名>@<IPアドレス>
その後、lsするとdemoディレクトリが見えるので、demoに移動します。
ls
cd demo
ここには3つのスクリプトが置かれています。このうちユーザーが実行するのはrunpi.shというスクリプトです。ちなみにこれは、pi.pyで円周率を計算するスクリプトになっており、pi.shでPBSの設定を行い、runpi.shでqsubによるジョブ投入を行っています。
早速実行してみます。
./runpi.sh
また、ジョブの状態は qstat コマンドで確認可能です。
qstat -a
qstat -u <ユーザー名>
ジョブが投入されると、下記のようにジョブが投入されたことが確認できます。

ノードの状態はCycleCloudの管理画面からも確認ができます。
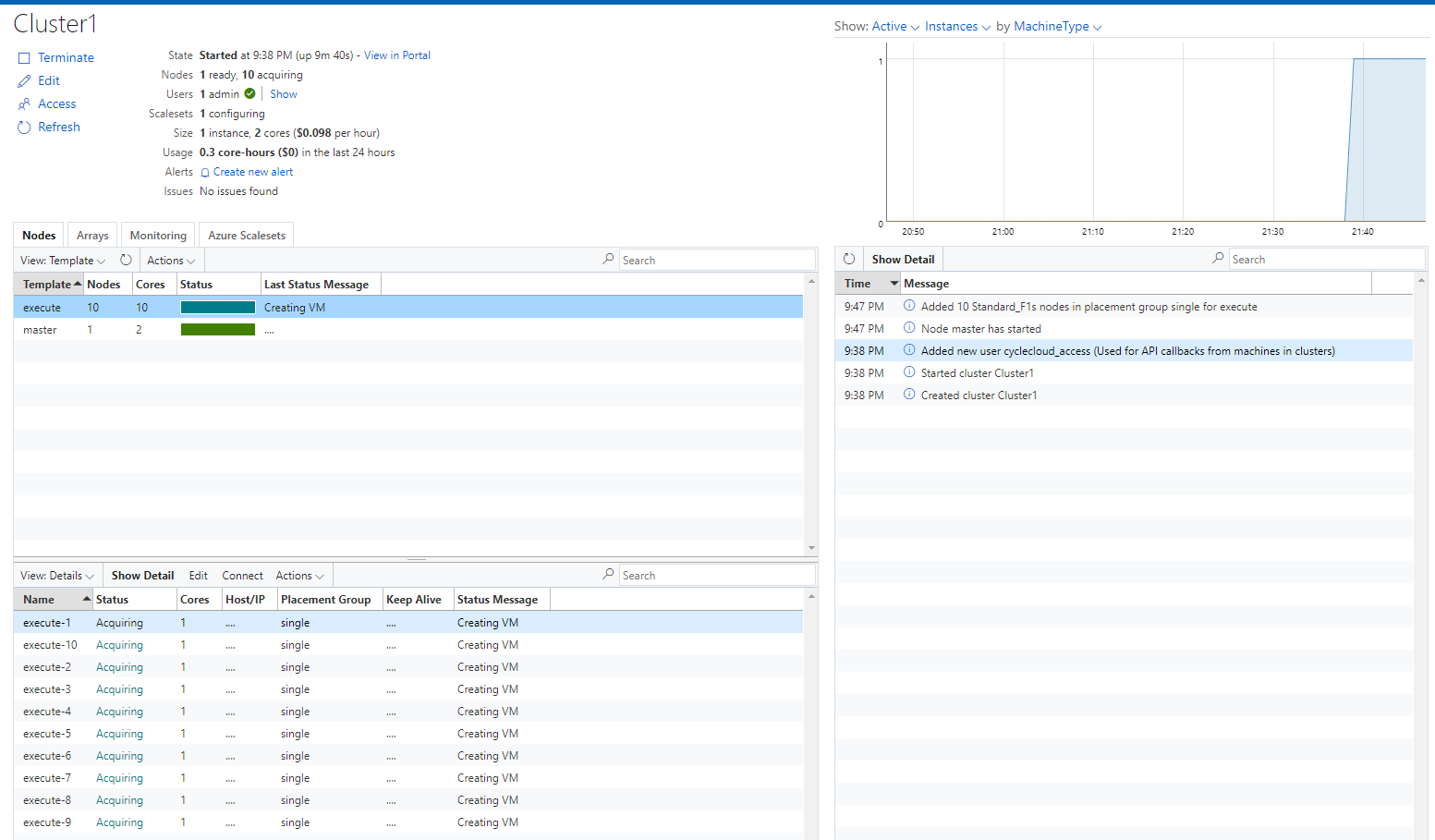
以上がCycleCloudでのジョブ実行の流れとなります。オートスケール設定の場合は、自動的にクラスターの実行ノードの数が0に戻ります。
④利用・テストなどの終了時の片づけ
以上が、CycleCloudにおける、環境構築・クラスター作成・ジョブ投入の一連の流れになります。
最後に、クラウドなので必要がなくなったものは削除すれば利用した分だけの支払いで済みます。Azureはリソースグループでリソースを一括管理するため、同じリソースグループに同じライフサイクルのオブジェクトを入れれば、リソースグループの削除で一括で削除が可能です。
リソースグループの削除用の Azure CLI コマンド
az group delete --name <リソースグループ名>
(余談)ほかのAzure上のHPC関連ソリューションとの違い
CycleCloudは下記サービスと比較して
・既存のスパコン・クラスターと変わらないユーザーエクスペリエンスをAzureのリソースを使って提供
・テンプレートを利用し、様々なワークロード(流体計算、構造計算、分子動力学計算など)に最適な環境をカスタマイズ可能
・HPC環境の管理者が容易にクラスターや利用者の権限管理を可能にするGUIを提供
という観点で強みがあります。
既存の方法をなるべく変えずに、簡単にクラウドにHPCワークロードを移行したい際に最適なソリューションです。
Azure Batch
Azure Batchは、バッチ処理などを、ジョブ・タスクを指定して、コンピュート環境をオンデマンドで利用することができます。特に、R Serverやレンダラー、Azure Data FactoryからAzure Batchに直接計算ジョブを送ることができるため、それらの用途では一番早く・簡単にAzureの計算リソースを利用できます。また、タスクの順番制御や並列処理などを複数ノードで詳細に制御できるため、複数のステップにわたるバッチ処理のコントロールにも適しています。
Azure ML
Azure Machine Learning Service の Azure ML Compute は特にディープラーニング用のクラスターをオンデマンドで利用するためのソリューションです。Azure Machine Learning Service はディープラーニングのモデル管理などもできるため、データサイエンティストの方などに最適です。
Cray in Azure
Cray in AzureはAzureのデータセンターに置かれたマネージドのCray社のXC/CSシリーズのスーパーコンピュータを利用できるサービスです。仮想マシンではなく、スーパーコンピュータのリソースを直接使う選択肢です。
参考資料
・公式ドキュメント
https://docs.microsoft.com/en-us/azure/cyclecloud/
・Big Compute: HPC および Batch
https://azure.microsoft.com/ja-jp/solutions/big-compute/
・クラウドで HPC ~ HPC 環境の構築から、アプリケーションの実行まで ~ (Azure Antenna資料)
https://qiita.com/AzureAntenna/items/39b401284bd169226efa
*本稿は、個人の見解に基づいた内容であり、所属する会社の公式見解ではありません。また、いかなる保証を与えるものでもありません。正式な情報は、各製品の販売元にご確認ください。