環境
- conda 4.7.5
- Python 3.6
- git
anacondaで仮想環境を構築
仮想環境を作るためにanaconda promptで以下を実行
conda create -n mask-rcnn python=3.6
conda activate mask-rcnn
これで、[mask-rcnn]という名前のpythonしか入っていない仮想環境が作られる。
そして、仮想環境内に入る
次に、必要なパッケージをインストールする。
パッケージのインストール
mask-rcnnに必要なパッケージをインストールしていないと、動かないのでインストール。
conda installとpip installを仮想環境で混ぜると壊れてしまうので
pipでインストールしていこうと思います。
condaでも出来ると思うけど
pip install astroid
pip install numpy scipy
pip install pillow scikit-image matplotlib imutils
pip install "IPython[all]"
pip install tensorflow
pip install keras h5py
pip install opencv-contrib-python
注意点としては、tensorflowについて、GPUを使うならtensorflow-gpuを使わないと認識してくれない
重たい処理をCPUですることになるので注意
mask-rcnnをgitでダウンロード
githubにあるMask_RCNNをダウンロードする
Mask_RCNN:https://github.com/matterport/Mask_RCNN
git clone https://github.com/matterport/Mask_RCNN.git
cd Mask_RCNN
python setup.py install
環境が構築できているか確認するために
$ python
>>>import mrcnn
>>>import cv2
これを実行してエラーが出なかったらOK
学習データについて
学習データが必要になる。
今回は以下のところからダウンロードして使う(mask_rcnn_balloon.h5)
https://github.com/matterport/Mask_RCNN/releases
ソースコード
$ tree
.
├── images
│ └──image.png
├── mask_rcnn_balloon.h5
└── maskrcnn.py
こんな感じの構造にしとく
imageに処理したい画像
maskrcnn.pyにプログラムを書いていく
maskrcnn.py
from mrcnn.config import Config
from mrcnn import model as modellib
from mrcnn import visualize
import numpy as np
import colorsys
import argparse
import imutils
import random
import cv2
import os
CLASS_NAMES =['BG', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign',
'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag',
'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', 'kite',
'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket',
'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana',
'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'dining table',
'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock',
'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush']
hsv = [(i / len(CLASS_NAMES), 1, 1.0) for i in range(len(CLASS_NAMES))]
COLORS = list(map(lambda c: colorsys.hsv_to_rgb(*c), hsv))
random.seed(42)
random.shuffle(COLORS)
class SimpleConfig(Config):
NAME = "coco_inference"
GPU_COUNT = 1
IMAGES_PER_GPU = 1
NUM_CLASSES = len(CLASS_NAMES)
config = SimpleConfig()
print("[INFO] loading Mask R-CNN model...")
model = modellib.MaskRCNN(mode="inference", config=config,
model_dir=os.getcwd())
# 学習データの指定
model.load_weights("mask_rcnn_balloon.h5", by_name=True)
# 自分が表示したい画像を指定する
image = cv2.imread("images/image.png")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = imutils.resize(image, width=512)
print("[INFO] making predictions with Mask R-CNN...")
# 学習データに画像を処理させる
r = model.detect([image], verbose=1)[0]
# rに処理データが格納される
'''
["rois"]:範囲の4点が格納されている
["class_ids"]:クラスID、0から80の数が入っている。画像に何が写っているかを教えてくれる。
["masks"]:ピクセル毎の範囲指定
'''
for i in range(0, r["rois"].shape[0]):
classID = r["class_ids"][i]
mask = r["masks"][:, :, i]
color = COLORS[classID][::-1]
image = visualize.apply_mask(image, mask, color, alpha=0.5)
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
for i in range(0, len(r["scores"])):
(startY, startX, endY, endX) = r["rois"][i]
classID = r["class_ids"][i]
label = CLASS_NAMES[classID]
score = r["scores"][i]
color = [int(c) for c in np.array(COLORS[classID]) * 255]
cv2.rectangle(image, (startX, startY), (endX, endY), color, 2)
text = "{}: {:.3f}".format(label, score)
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.putText(image, text, (startX, y), cv2.FONT_HERSHEY_SIMPLEX,
0.6, color, 2)
cv2.imshow("Output", image)
cv2.waitKey()
これで保存する。
point
image = cv2.imread("images/image.png")
ここで自分が処理したい画像をしてする
imagesの中にあるimage.pngの画像を指定している。
最後に仮想環境内で以下を実行すればOK
python maskrcnn.py
実行結果
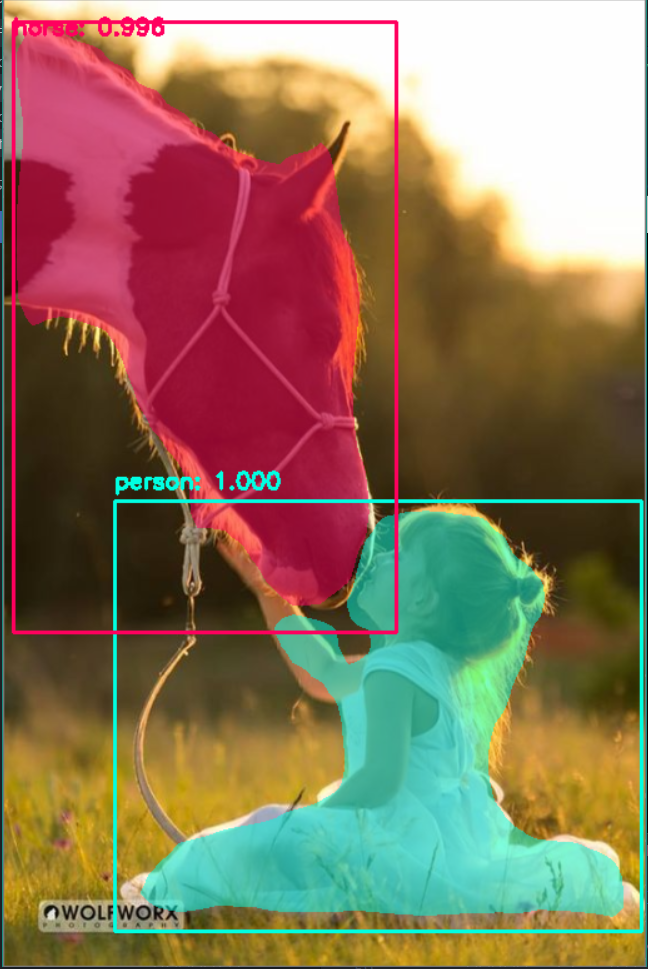 馬と人どちらも高い精度で認識してます
馬と人どちらも高い精度で認識してます
 犬と人複雑な姿勢だと認識が下がるみたいですね。
犬と人複雑な姿勢だと認識が下がるみたいですね。
こんな感じで実行結果がでると思います。
お疲れ様でした。