はじめに
概要
DynamoDBのテーブルの用語やテーブルの検索方法がまっっったくわからなかったので、イラストをまじえながらいつでも見返せるように書いてみました。
この記事で得られること
DynamoDBのテーブルの基礎概念についてイラストで理解できます。
テーブルの操作はaws cliで行なっていますが、もちろんコンソール画面からもできます。
全体の概要を理解したいので、aws cliのコマンドについては軽く読み流してもらって大丈夫です。
用語
DynamoDBのテーブルには色々な用語があります
- テーブル
- パーティションキー
- ソートキー
- Item(項目)
- Attribute(属性)
- index
その他もろもろ…
何を言っているのかよく分かりませんね。
そこで、今回は私たちに馴染みのある「学校」をテーマにイラストを使って解説をしていきます。
みなさんは先生になった気持ちでどうすれば生徒たちの情報を管理できるのか見てください。
ではいってみましょう!
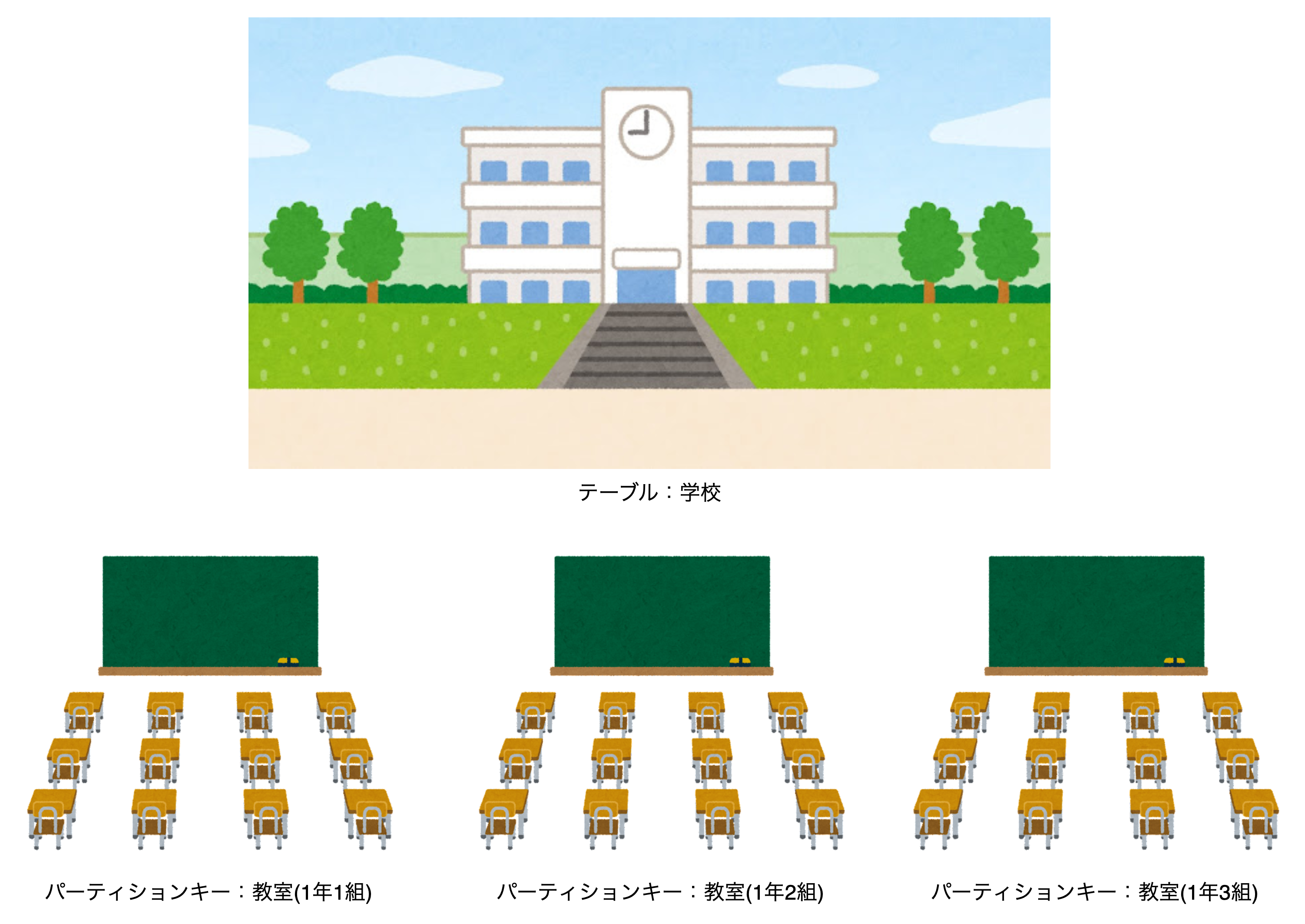
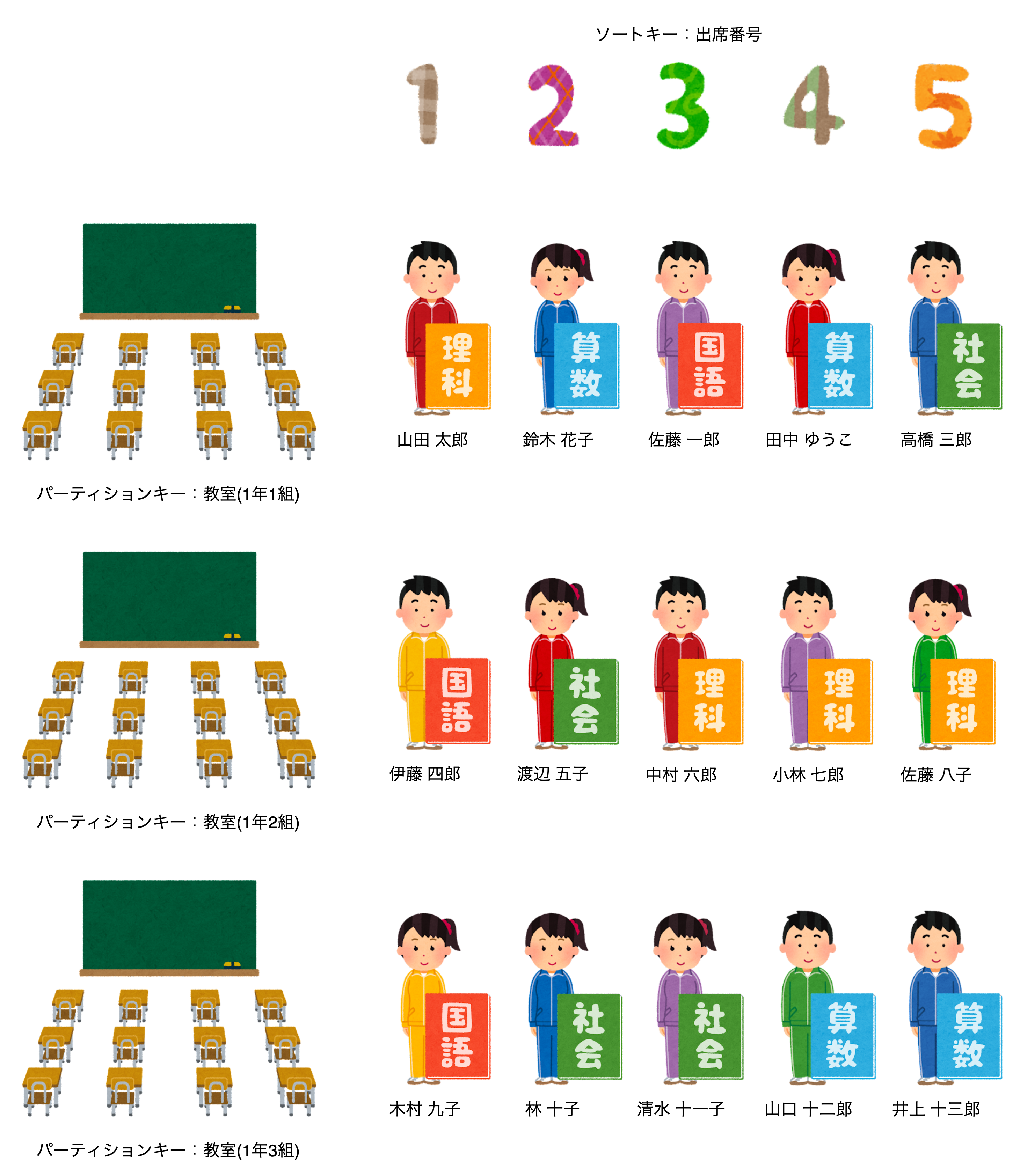
テーブル
まずはテーブル、これは一番大きい枠です。
学校で例えると「学校」そのものです。

パーティションキー
次にパーティションキーです。
今回は「教室」です。
学校(テーブル)の中にある教室(パーティションキー)ですね。
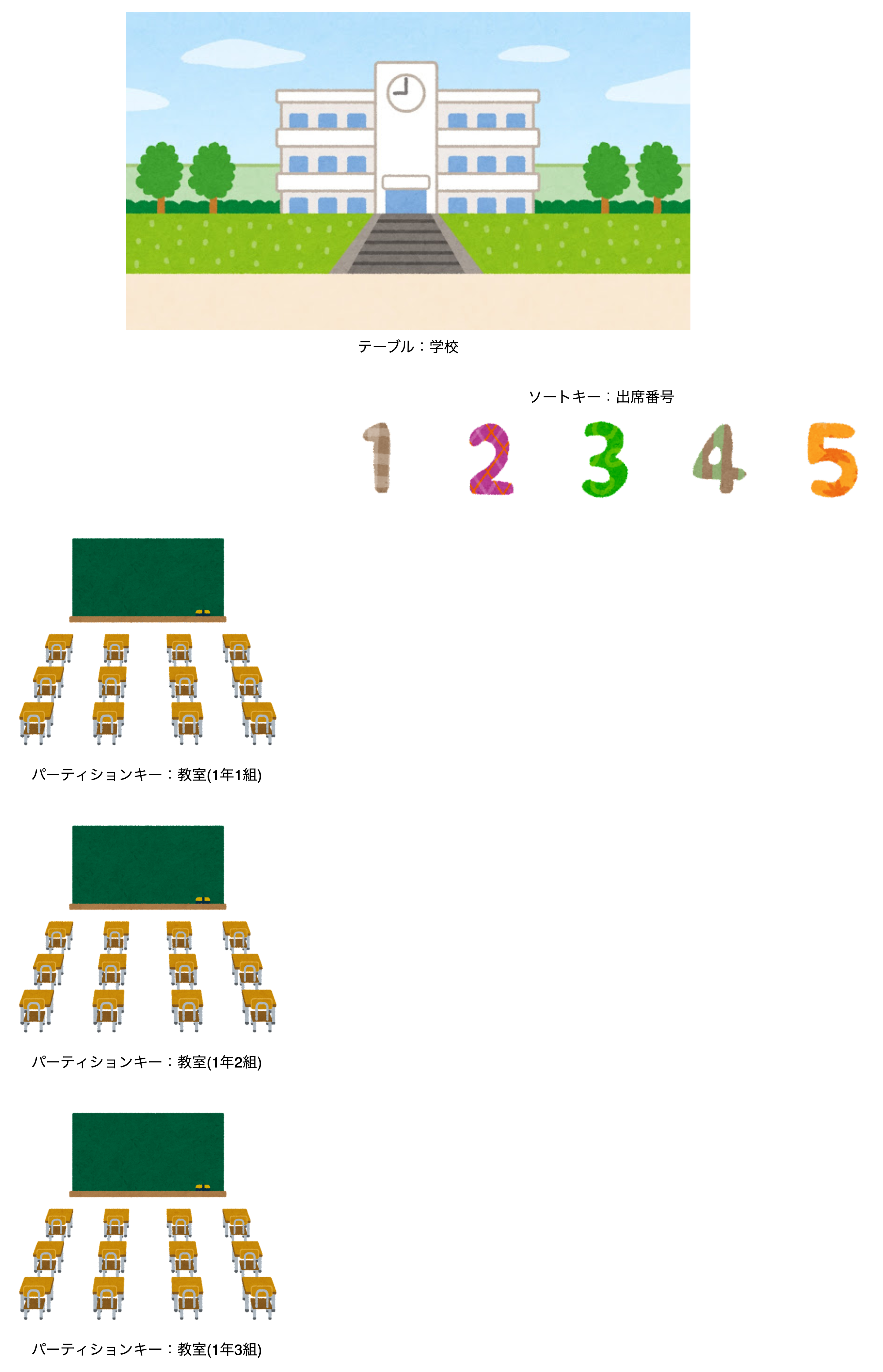
ソートキー
次はソートキーです。
今回のソートキーは「出席番号」です。
学校(テーブル)の中にある教室(パーティションキー)という単位で区切られた中の出席番号(ソートキー)です。
出席番号を使うことで、教室内で生徒を順番に並べることができますね。
このソートキーはあってもなくてもいいです。
生徒数が少ない学校では出席番号がなくても生徒の把握はできますよね。
逆に生徒数と教室が多くなると出席番号があると生徒の把握がしやすいですね。
Attribute(属性)
Attributeはパーティションキーとソートキー以外の情報です。
今回は教室(パーティションキー)の中の「生徒の名前」、「性別」といった情報です。

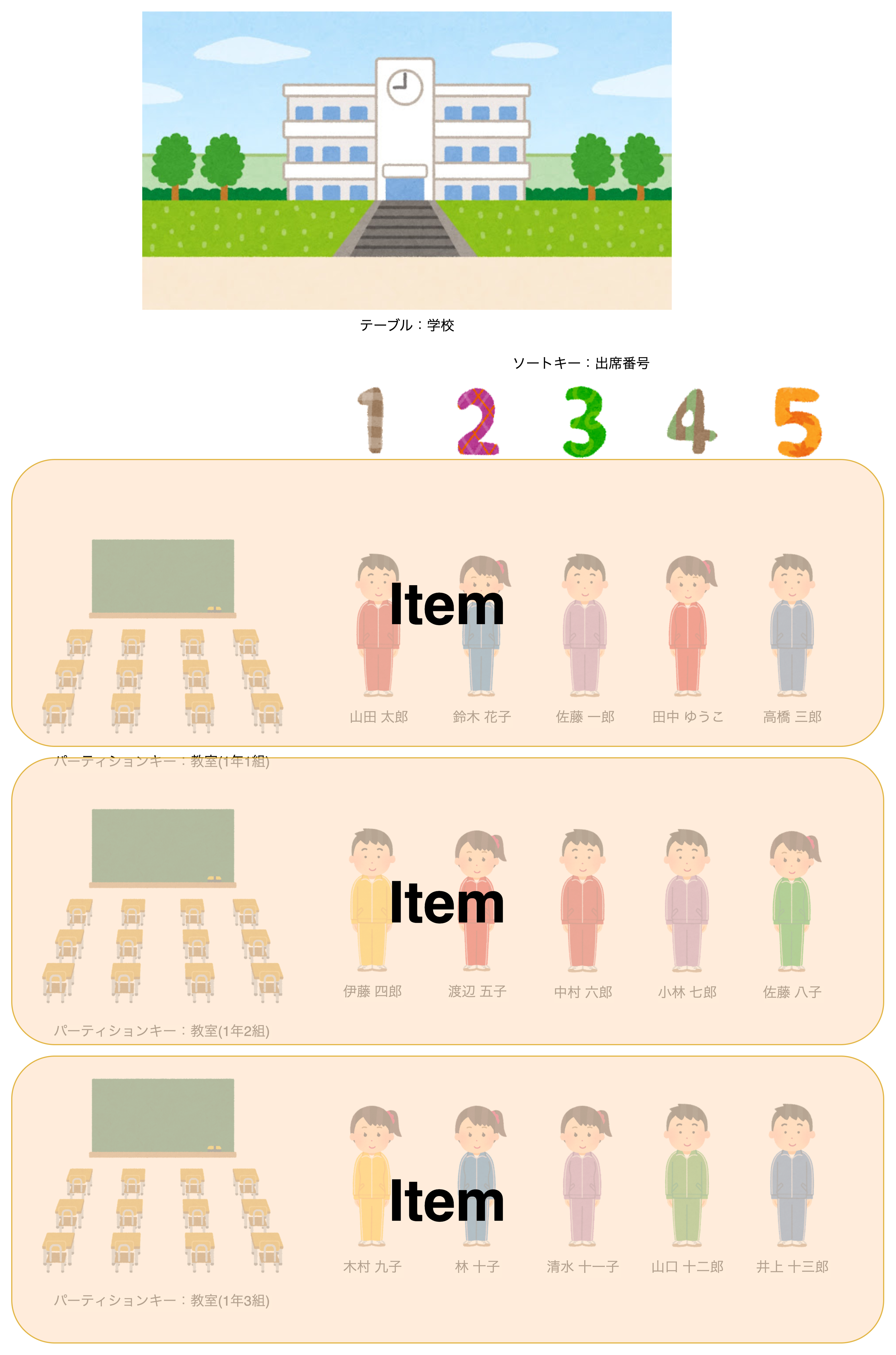
Item(項目)
Itemはパーティションキー毎に区切られたattributeの集まりです。
これにはパーティションキーやソートキーも含まれます
教室毎に生徒が分けられていますよね。
教室(パーティションキー)には出席番号(ソートキー)や生徒の名前(attribute)などが含まれています。このまとまりがItemです。
言葉だとちょっとイメージしずらいですが、イラストにするとこんな感じです。
index
indexは教室(パーティションキー)と出席番号(ソートキー)では並び替えが難しい時に、並び替えをしやすいようにパーティションキーとソートキーを選び直すことができます。
例えば、好きな色ごとに生徒を検索したい場合などです。
パーティションキーを好きな色に、ソートキーを生徒の名前にすることで、検索がしやすくなります。

indexにはグローバルセカンダリインデックス(GSI)とローカルセカンダリインデックス(LSI)という2種類のインデックスが存在します。
検索
これは用語とは少しズレるかもしれません。
学校で例えると校内放送で生徒を呼び出す時に使います。
呼び出し方には大きく分けていくつかの種類があります。
-
Get-Item
- 教室と任意の出席番号から生徒を呼び出す(一人だけ呼び出し)
例えば、1年1組 出席番号1番のひと〜という感じ

- 教室と任意の出席番号から生徒を呼び出す(一人だけ呼び出し)
-
Query
- 教室と任意の情報(属性)から生徒を呼び出す(まとめて呼び出し)
例えば、1年2組 出席番号3番以上のひと〜という感じ

- 教室と任意の情報(属性)から生徒を呼び出す(まとめて呼び出し)
-
Scan
- 学校(テーブル)内のデータを全て呼び出し
例えば学校(テーブル)の全校生徒グランドに集まって〜という感じ

- 学校(テーブル)内のデータを全て呼び出し
この検索で共通しているのは、教室(パーティションキー)とソートキーは常に固定であるという点です。
しかし、実際はパーティションキーを別の値にして検索をしたいこともあります。
例えば、好きな色で分けて、男女比を計算するなど。
そんな時に活躍するのが先ほど出てきたGSIです!
GSIを使うことで、パーティションキーとソートキーを任意の値(好きな色、性別など)に設定することができます。
今回は基本的にGSIを使った説明を行います。
GSIはテーブル作成後に任意のパーティションキーとソートキーでインデックスを作成します。
LSIはテーブル作成時にそのテーブルのパーティションキーと任意のソートキーでインデックスを作成します。
この情報だけだとLSIに利点が無いように思いますが、LSIはインデックスの容量やデータ読み書きの効率がGSIに比べて優れています。
そのため、特定のユースケースではLSIが使われることがあります。
テーブル操作
テーブルの作成
まずはテーブルの作成をしていきます。
$ aws dynamodb create-table \
--table-name School \
--attribute-definitions \
AttributeName=Classroom,AttributeType=S \
AttributeName=StudentNumber,AttributeType=N \
--key-schema \
AttributeName=Classroom,KeyType=HASH \
AttributeName=StudentNumber,KeyType=RANGE \
--provisioned-throughput \
ReadCapacityUnits=5,WriteCapacityUnits=5
ここでは学校(テーブル)を作成しています。
さらにその中に教室(パーティションキー)と出席番号(ソートキー)を定義していきます。
実際の教室(1年1組)や出席番号(1番)などはここでは作成していません、あくまでも「学校」の中に「教室」や「出席番号」があるよ!ということを定義しているだけです。
無事にテーブルが作成されるとアウトプットが返ってきます。
#output
{
"TableDescription": {
"AttributeDefinitions": [
{
"AttributeName": "Classroom",
"AttributeType": "S"
},
{
"AttributeName": "StudentNumber",
"AttributeType": "N"
}
],
"TableName": "School",
"KeySchema": [
{
"AttributeName": "Classroom",
"KeyType": "HASH"
},
{
"AttributeName": "StudentNumber",
"KeyType": "RANGE"
...
データの追加
では次に教室や生徒を追加していきます

$ aws dynamodb put-item \
--table-name School \
--item '{
"Classroom": {"S": "1組"},
"StudentNumber": {"N": "1"},
"StudentName": {"M": {"LastName": {"S": "山田"}, "FirstName": {"S": "太郎"}}},
"Gender": {"S": "Male"},
"FavoriteColor": {"S": "Red"}
}'
...
これで、教室は1組、出席番号は1番、名前は山田太郎くん、男子、好きな色は赤色
という情報が登録できました。
一応確認してみましょう。
パーティションキーとソートキーを使って1組の出席番号1番を検索してみます。
$ aws dynamodb get-item \
--table-name School \
--key '{
"Classroom": {"S": "1組"},
"StudentNumber": {"N": "1"}
}'
#output
{
"Item": {
"StudentName": {
"M": {
"FirstName": {
"S": "太郎"
},
"LastName": {
"S": "山田"
}
}
},
"Gender": {
"S": "Male"
},
"StudentNumber": {
"N": "1"
},
"Classroom": {
"S": "1組"
},
"FavoriteColor": {
"S": "Red"
}
}
}
このように1組の出席番号1番の山田太郎くんのデータが取り出せました。
attributeの追加
では、ここに新たにattributeを追加してみましょう。
attributeを追加と書くと難しく聞こえるので、
今回は生徒たちが得意な教科を追加していきたいと思います。
先ほどの山田 太郎くんの得意教科は理科です。
ここでは、教科というattributeと、そこに理科という値を追加します。
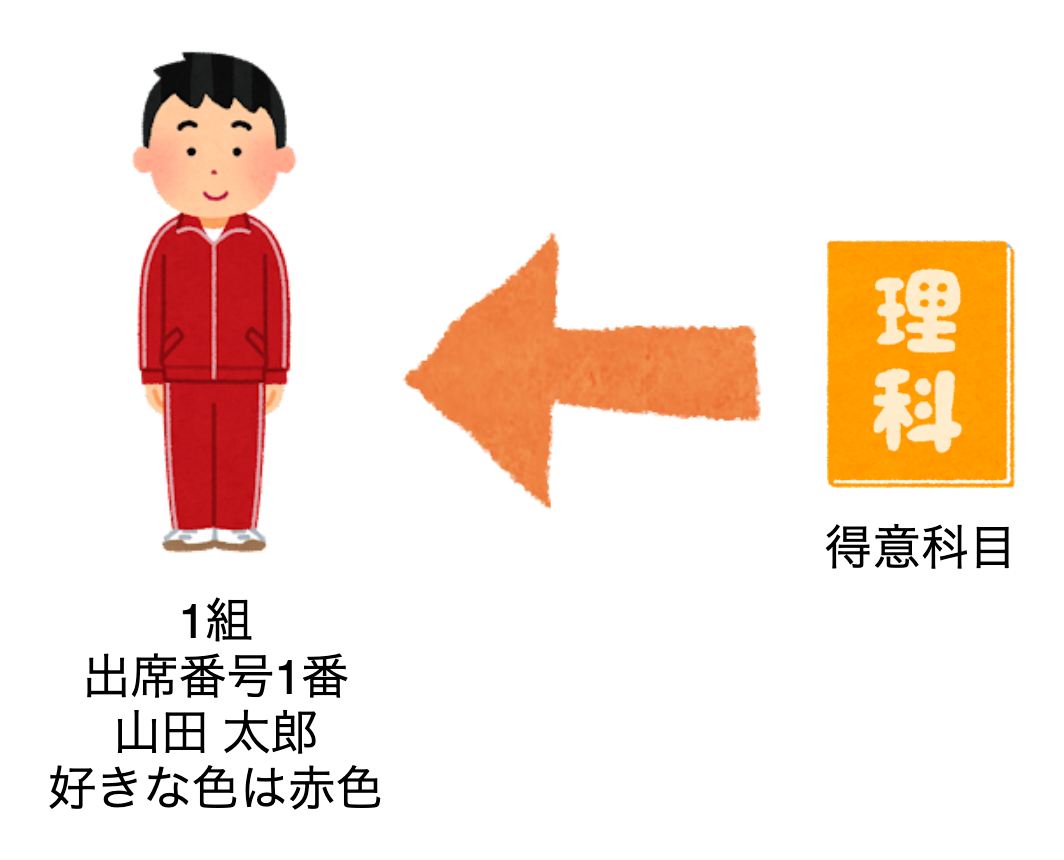
$ aws dynamodb update-item --table-name School \
--key '{"Classroom": {"S": "1組"}, "StudentNumber": {"N": "1"}}' \
--update-expression "SET Subject = :s" \
--expression-attribute-values '{":s": {"S": "理科"}}' \
--return-values UPDATED_NEW
これで1組の出席番号1番の山田 太郎くんにsubject(教科)というattributeと、その値として理科が追加されました。
一応確認しておきましょう。
$ aws dynamodb get-item \
--table-name School \
--key '{
"Classroom": {"S": "1組"},
"StudentNumber": {"N": "1"}
}'
1組の出席番号1番で検索をかけます。
#output
{
"Item": {
"Gender": {
"S": "Male"
},
"Classroom": {
"S": "1組"
},
"StudentName": {
"M": {
"FirstName": {
"S": "太郎"
},
"LastName": {
"S": "山田"
}
}
},
"StudentNumber": {
"N": "1"
},
"FavoriteColor": {
"S": "Red"
},
"Subject": { ←追加された項目
"S": "理科" ←追加された項目
}
}
}
ちゃんと追加されましたね。
このように、DynamoDB(NoSQL)では簡単にattributeを追加できる柔軟性があります。
他の生徒にも得意科目を追加します。
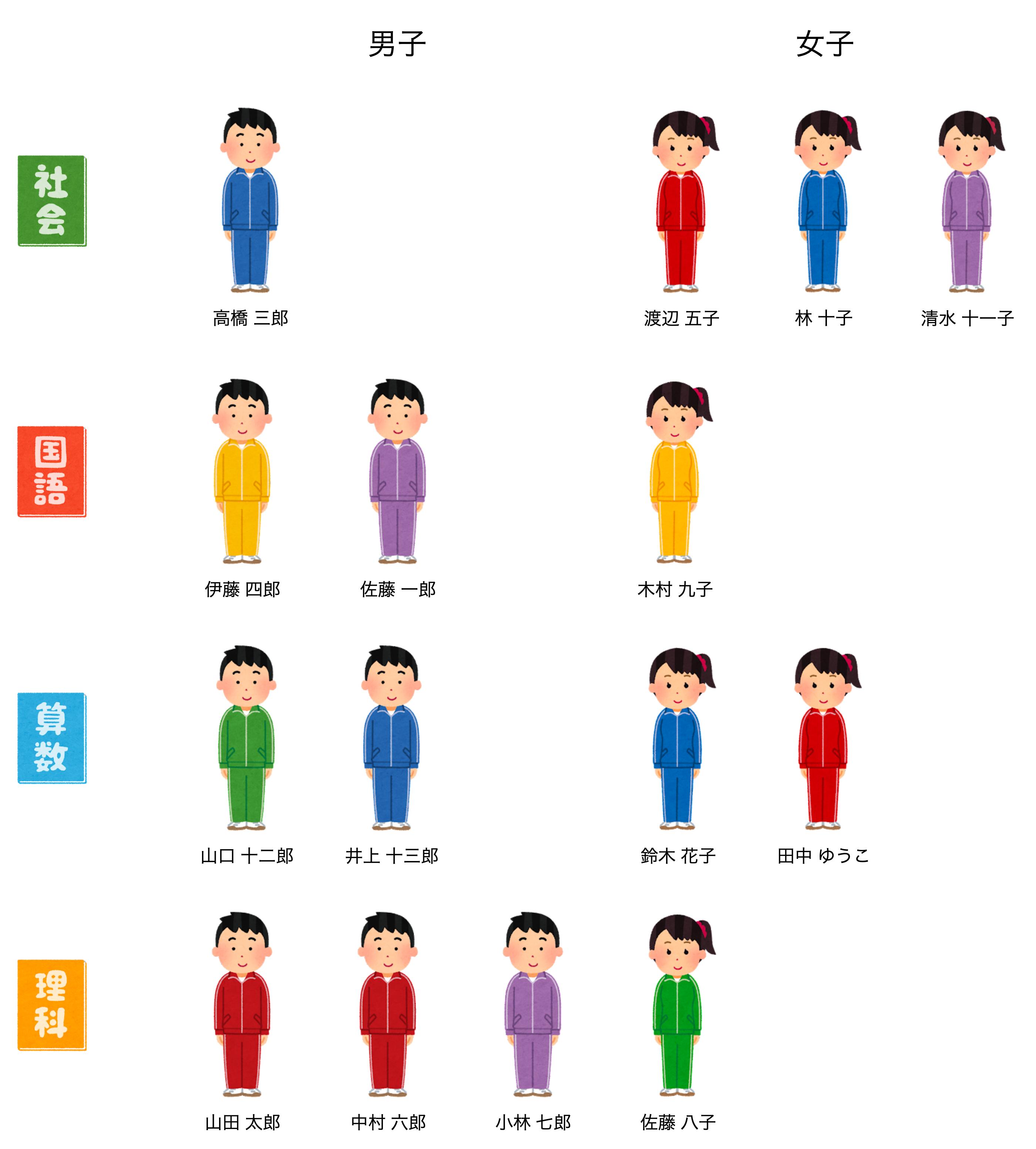
index
ではここで得意教科から男女ごとに生徒を分けてみたいと思います。
先ほどまでの教室から出席番号順に並べ替えるだけでは難しそうですね。
そこで、新たに得意教科(パーティションキー)で男女(Gender)毎に生徒を分けるGSIを作成していきます。
$ aws dynamodb update-table \
--table-name School \
--attribute-definitions AttributeName=Subject,AttributeType=S AttributeName=Gender,AttributeType=S \
--global-secondary-index-updates \
"[
{
\"Create\": {
\"IndexName\": \"SubjectGenderIndex\",
\"KeySchema\": [
{\"AttributeName\":\"Subject\",\"KeyType\":\"HASH\"},
{\"AttributeName\":\"Gender\",\"KeyType\":\"RANGE\"}
],
\"Projection\":{
\"ProjectionType\":\"INCLUDE\",
\"NonKeyAttributes\":[\"StudentName\"]
},
\"ProvisionedThroughput\": {
\"ReadCapacityUnits\": 10,
\"WriteCapacityUnits\": 5
}
}
}
]"
これでGSIが作成されました。
イメージはこんな感じです。
では、queryで理科が得意な女子を検索してみましょう。
$ aws dynamodb query --table-name School\
--index-name SubjectGenderIndex \
--key-condition-expression "Subject = :v_subject AND Gender = :v_gender" \
--expression-attribute-values '{":v_subject":{"S":"理科"}, ":v_gender":{"S":"Female"}}'
#output
{
"Items": [
{
"StudentName": {
"M": {
"FirstName": {
"S": "八子"
},
"LastName": {
"S": "佐藤"
}
}
},
"Gender": {
"S": "Female"
},
"StudentNumber": {
"N": "5"
},
"Classroom": {
"S": "2組"
},
"Subject": {
"S": "理科"
}
}
],
"Count": 1,
"ScannedCount": 1,
"ConsumedCapacity": null
}
見事に理科が得意な佐藤八子さんを呼び出すことができました!

このようにGSIを使うことで、テーブルを作成した後からでもいろいろな方向から検索することができます。
まとめ
所感
いかがでしたでしょうか、私はテキストと無機質なテーブルを用いた説明では全然理解できませんでしたが、イラストにすることでなんとなく全体像を掴むことができました。
RDBに似ている部分もありますが、全く違う部分もあります。
RDBならどうかな?という考えを一度捨てることで徐々に理解が深まりました。