はじめに
概要
前回のイラストで理解するが好評だったので、今回もイラストを使ってSQSの学習記録を記事にします。(本当は絵にして覚えたものにちょっと文字を足しただけ)
この記事で得られること
SQSがメッセージを配信する仕組みをイラストを交えながら理解できます。
概要を理解できれば公式ドキュメントも読みやすくなるはずです。
用語
まずはSQSに出てくる用語を見てみましょう。
-
メッセージ
- SQSが受け取るデータのこと
今回はニュース原稿

- SQSが受け取るデータのこと
-
キュー
- メッセージをためておく場所
今回は原稿を入れる箱

- メッセージをためておく場所
-
コンシューマ
- メッセージを処理するもの(Lambdaとか)
今回は原稿を読むキャスター

- メッセージを処理するもの(Lambdaとか)
-
プロデューサ
- メッセージを配信するもの(EC2上のアプリケーション, IoTデバイスなど)
今回は原稿を作るライター

- メッセージを配信するもの(EC2上のアプリケーション, IoTデバイスなど)
今回は原稿作成からキャスターが原稿を読むまでの流れに例えながら勉強していきたいと思います。
全体像
全体像としてはこんな感じです。

AWSのアイコンだとこんな感じです。
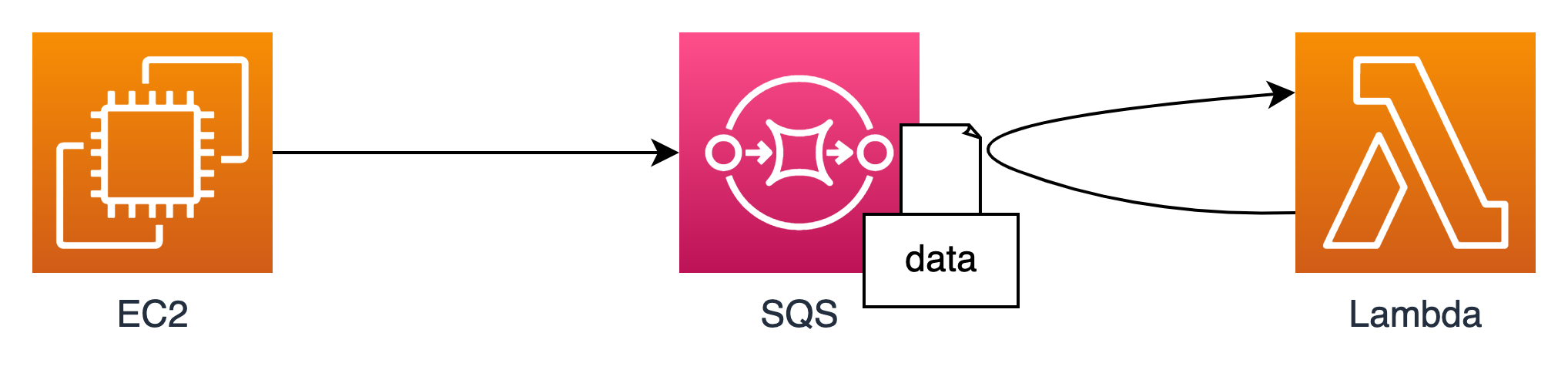
SQSは簡単にいうとアプリケーションが出力したデータを一時的にキューに保管しておく場所です。
この書き方だとストレージと勘違いしそうなので、原稿を読むまでの流れで例えると
SQSはキャスターが原稿を取りにくるまで一時的に原稿をおいておく「箱」です。
ストレージはキャスターが読み終えた原稿を保管しておく「倉庫」みたいな感じです。
どうでしょう、なんとなくイメージできましたか?
ではその具体的な内容を見ていきましょう!
キューの種類
まずはキューの種類から見ていきます
キューには2種類あります
- 標準キュー
- FIFOキュー
これは原稿(メッセージ)をどうやって箱(キュー)に入れるか、です。
標準キュー
標準キューはできた原稿からどんどん箱に入れていくという感じです。
順番や重複を気にせず高スループットを求められる際に使います
例えると、スポーツ実況では順番はある程度気にせず、スピード感が重要ですよね。
同じことを言っても気にする人はいないですよね

ログの分析なんかでは、順序や重複は大した問題にならないことが多いので標準キューが向いてます。そもそもログ自体に日時とか書かれてますよね
FIFOキュー
FIFOキューは重複ダメゼッタイ!とうい原稿を綺麗に順番に箱に入れていく感じです。
順番や重複排除が重要なデータに使います。
声優さんが読む原稿がバラバラだったり、何度も同じセリフをいうようなアニメなんて見たくないですよね

オンラインショッピングサイトでの決済処理では重複は絶対にダメですね、そういったお金がかかわるような処理でFIFOキューが使われます
メッセージ識別子
次にメッセージに割り当てるIDについて見ていきます
これは原稿に番号を割り当てて管理をする仕組みです。
番号があれば、この原稿は読んだ、この原稿は読んでいないという管理ができます。
識別子には以下のようなものがあります
- メッセージID
- メッセージ重複排除ID(FIFOキューのみ)
メッセージID
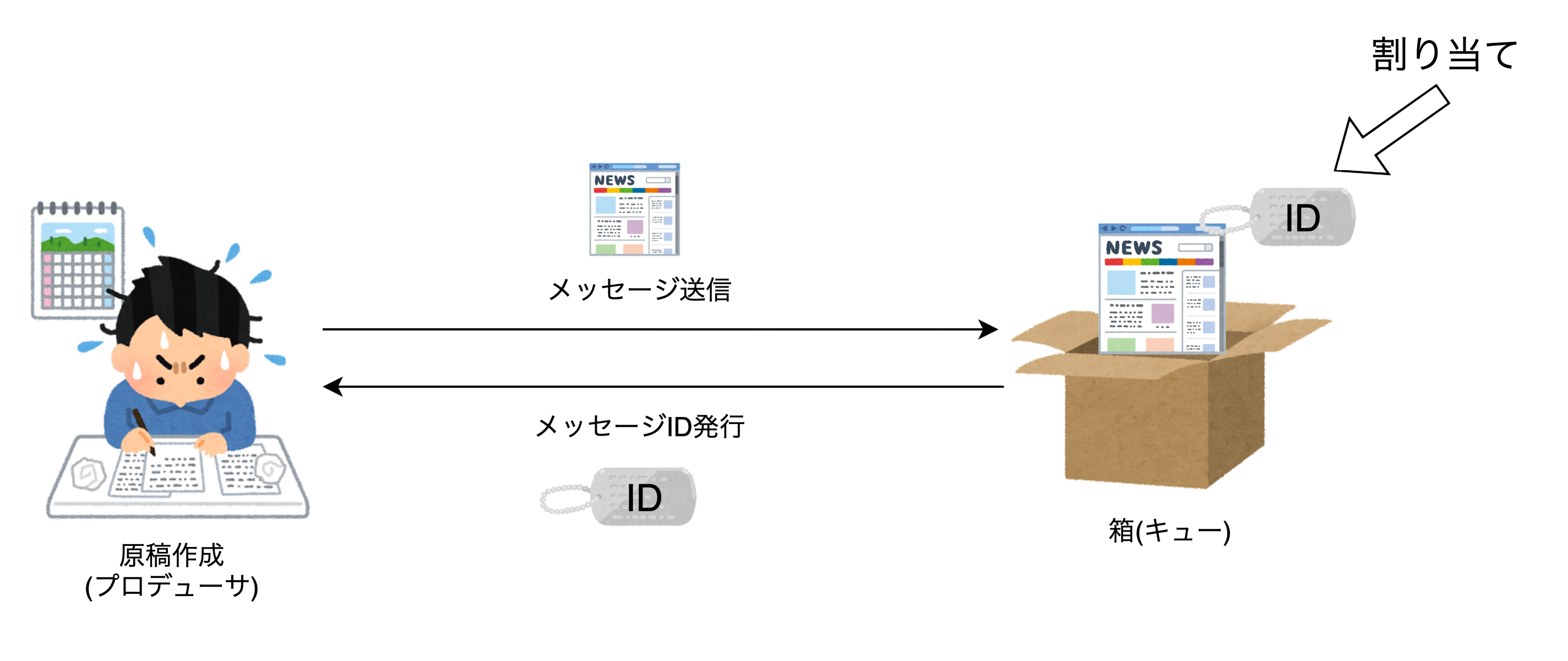
メッセージIDは箱(キュー)に原稿(メッセージ)が入った時、必ず原稿に割り当てられるIDです。
これはFIFOキューでも適用されます
またメッセージIDをプロデューサにレスポンスとして返すことで、メッセージを受け取ったことを知らせます。
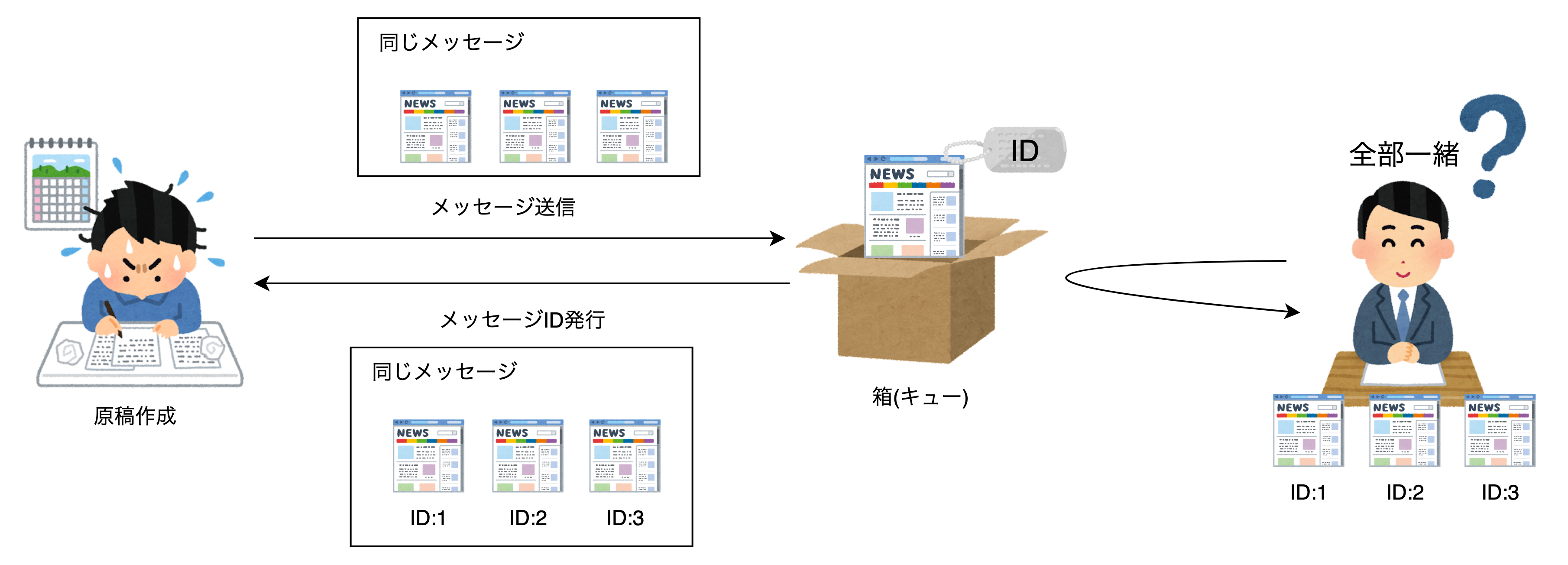
メッセージ重複排除ID
一方、メッセージ重複排除IDはFIFOキューのみに適用されます
FIFOキューは重複ダメゼッタイ!でしたね
そのため、箱に入れる原稿が重複しないようIDを割り当てることができます。

これは、SQSの「コンテンツに基づく重複削除」を有効にすることで、キューに登録されたメッセージの内容をハッシュ化してメッセージ重複排除IDとして扱うことができます。
また、図には書いていないですがメッセージIDも一緒に発行されています。
もちろん、任意のIDをつけたい場合はプロデューサ側で任意のIDを割り当てるプログラムを構築することもできます。
Q. メッセージIDも一意ならそれだけで重複排除できないの?
A. 複数の同じメッセージがキューに登録された時、メッセージIDだけではそれぞれに違うIDが割り当てられてしまう。
それではキュー内でメッセージの重複が発生してしまうのでダメ。
ポーリング
ポーリングとはコンシューマがキュー内のメッセージを取りに行くことです。
ちなみに、SQSはSQS自身がコンシューマにメッセージを送り出すのではなく、コンシューマがメッセージを取りにくるPULL型のサービスです。
例えると、箱に入っている原稿をキャスターが取りに行くことです。
これには2つ種類があります。
- ショートポーリング
- ロングポーリング
ショートポーリング
これはキャスターが原稿を取りにいって、箱に何も入ってなければすぐに帰る。という感じです。

ショートポーリングはとにかくレスポンスが早いです。行ったらすぐに帰ってきます。
一方で、メッセージがキューに入れられる頻度が少ないようなシステムでは、無駄に通信が増えてしまいコストの無駄になります。
ロングポーリング
これはニュースキャスターが原稿を取りにいき、箱に何も入っていなかったら、しばらく(最大20秒)箱に原稿が入るのを待ちます。
待っても原稿がこなければ帰ります。

ロングポーリングは、メッセージがたまにしか登録されないようなシステムに向いています。
しかし、その分レスポンスが遅くなります。
機能
可視性タイムアウト
可視性タイムアウトは、キューに登録されたメッセージがポーリングされると、そのメッセージを一時的に他のコンシューマから見えないようにする機能です。
例えると、箱に入った原稿を一人のニュースキャスターが読んでる間は他のキャスターはその原稿を読むことができなくする。という感じです。
これは、一つの原稿(メッセージ)を何人ものキャスター(コンシューマ)が同時に読む(処理する)ことを防ぐための仕組みです。
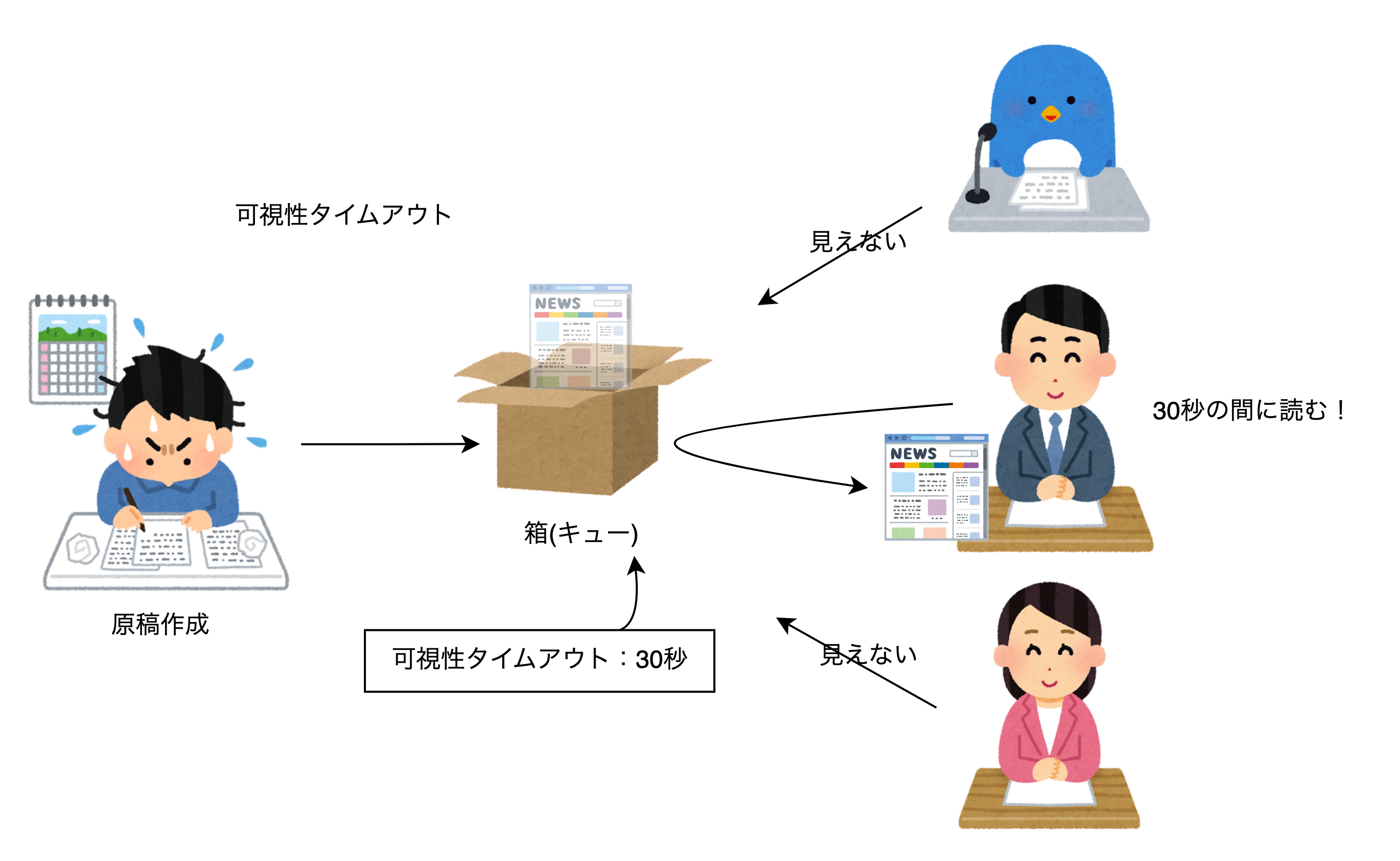
可視性タイムアウトはデフォルトでONになっており、30秒と設定されています。
コンシューマが処理をするのに時間がかかる場合は、可視性タイムアウトの時間を伸ばす必要があります。
注意点として、キューに登録されたメッセージはコンシューマで読み込むだけでは消えません。
そのためコンシューマ側で削除するプログラムを書く必要があります。
これをしないと、何度も同じメッセージが処理されることになります。
遅延キュー
遅延キューは少しの間、キューにメッセージを留めておく仕組みです。
キューに留めておくことで、コンシューマが処理するのを延期させることができます。
これは可視性タイムアウトとよく似ています。
重要なのは、そのタイミングです。
可視性タイムアウトは「メッセージを読み込んだ後」
遅延キューは「メッセージがキューに登録された時」
私はこの説明では全く理解できなかったので、簡単な例をあげます。
ライターは原稿が仕上がったけど、少ししてやっぱり内容をもう少し変えたいと思いました。
そんな時、箱に入れてすぐキャスターが原稿を取りにこられると困りますね。
そこで、一旦箱(キュー)に置いた原稿は15分間はキャスターが取りにこないようにしたいです。
そんな時、遅延キューを設定すればキャスターは箱に原稿を入れてから15分間は取りにくることができなくなります。

SNSの投稿をすぐに世に出すのではなく、投稿ボタンを押した後の数分間、吟味する時間を与える。
やっぱり違うと思えば削除すればいい。
そんな使い方ができるのではないかと思います。
デッドレターキュー(DLQ)
デッドレターキュー(DLQ)はコンシューマで数回処理をしたけれど、処理ができなかったメッセージが入るキューです。
箱(キュー)に原稿が入っているけど、原稿が英語で書かれていて英語を読めるキャスターがいない。
そんな時、読まれなかった原稿はDLQへ入ります。
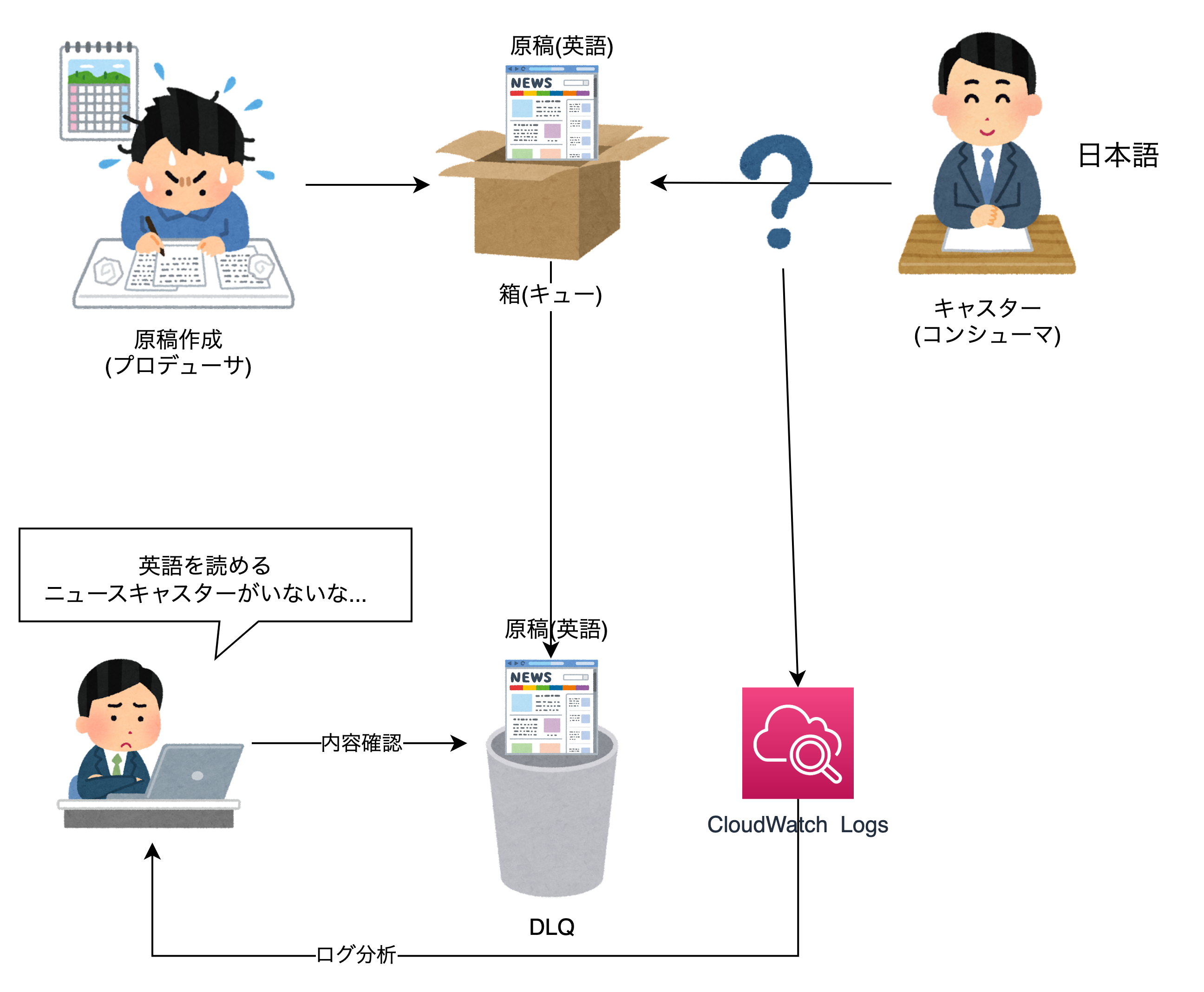
このDLQに格納されたメッセージを見て、なぜ処理ができなかったのかを分析します。
そしてその対策ができたら再度メッセージを元のキュー(他のキューも可)に戻します。
ちなみに、DLQにメッセージが格納されるとそれを通知する仕組みが必要です。
もちろん手動でも確認できますが面倒です。
【Cloudwatch アラーム】
メトリクスを監視して通知
【SNS】
DLQにデータが移行したことをトリガーに通知
DLQを元のキューに戻してもメッセージはDLQに残ります。
削除しないとコストがかかるので注意しましょう。
まとめ
所感
設定は色々ありますが、やっていることは単純なのでしっかりドキュメントを読めば理解できると感じました。
AWSの資格試験でSQSの問題が出てくる度にドキュメントを読み返していたので、これでしばらくは読み返さなくても思い出せると思います。